1.1 大模型特点
自从GPT-3.5的横空出世,人工智能真正走进了大众视野。凭借强大的对话理解与生成能力,它不仅让普通用户首次体验到“类人”交互的流畅与智能,更迅速渗透至电商、营销、客服等商业场景。
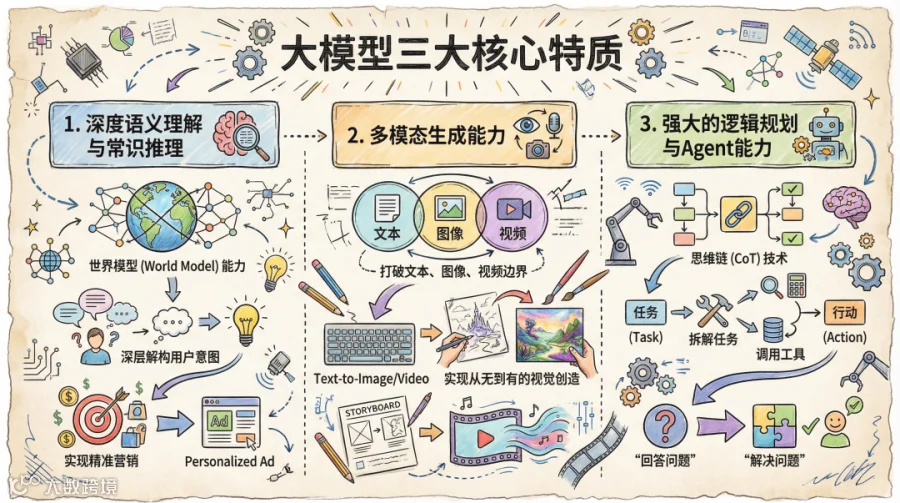
而站在商业化平台的视角下,大模型带来的不仅是参数量指数级膨胀(从亿级迈向万亿级),更具备以下三个对商业化至关重要的核心特质:
传统NLP模型多基于关键词匹配或浅层语义向量,往往难以捕捉复杂的上下文和潜台词。大模型通过海量数据预训练,压缩了人类世界的知识,具备了“涌现”能力。它不仅能理解“长裙”是商品,还能推理出“海边度假”场景下用户对“波西米亚风长裙”的潜在需求。这种对用户意图(Intent)的深层解构能力,是精准营销的基石。
1.1.2 多模态生成能力(Native Multimodality):
大模型正在快速打破文本、图像、视频的边界。从Text-to-Text的文案生成,到Text-to-Image/Video的视觉创造,大模型不再是简单的素材搬运工,而是具备了从无到有的创造力。对于电商而言,这意味着商品不再只是静态的SKU数据,而是可以被实时渲染、动态生成的鲜活内容。
1.1.3 强大的逻辑规划与Agent能力(Reasoning & Planning):
这是大模型区别于以往BERT等模型的最大亮点。通过CoT(思维链)技术,大模型具备了拆解复杂任务、调用外部工具(API)并执行决策的能力。这使得AI不仅能“回答问题”,更能“解决问题”,为广告投放的自动化和智能化提供了操作系统的雏形。
1.2 大模型在商业化平台落地
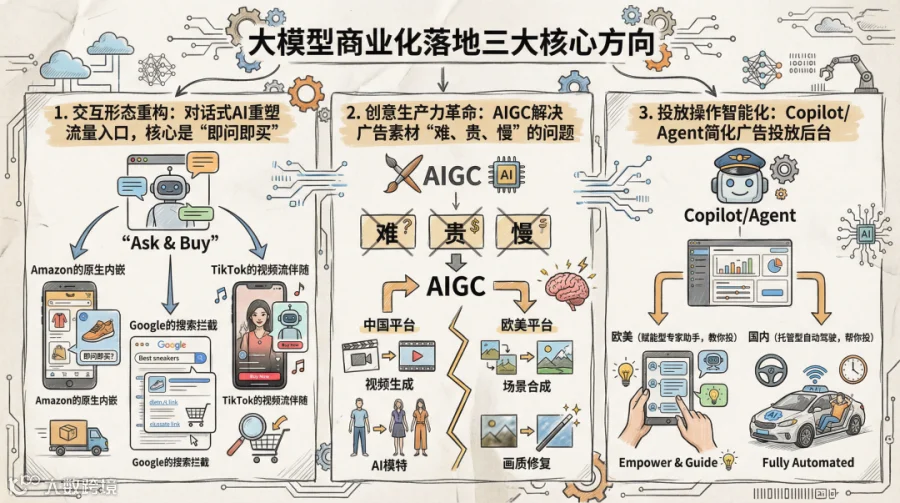
基于上述特质,商业化平台的业务架构正在发生深刻变革。目前主要聚焦于三大核心演进方向,我们可以将其总结为:交互形态重构、创意生产力革命、以及投放操作智能化。其中,对话式广告重塑了“场”的形态,而AIGC解决了“供”的问题(素材产能),Copilot解决了“效”的问题(人效与决策质量)。
方向一:交互形态重构
这是商业化流量入口的终极之战。当用户不再搜索关键词,而是向AI提问时,广告该如何被精准召回和计费,是首要考虑的问题。
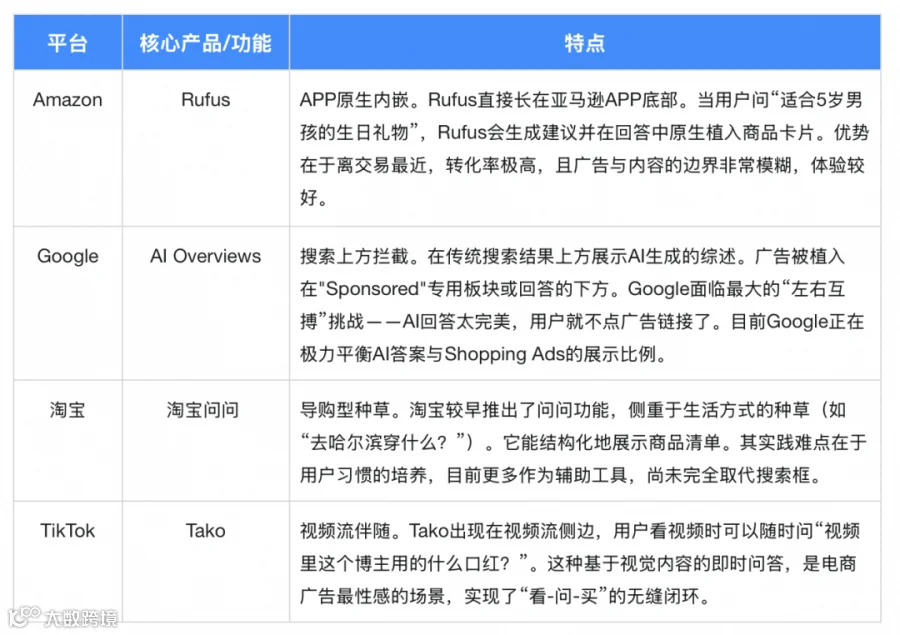
综合来看:Amazon的Rufus目前看来最具杀伤力,因为它掌握了最精准的交易意图和库存数据。Google则处于防御姿态,试图在守住搜索广告底盘的同时引入AI。TikTok的Tako如果全面铺开,将是非标品(服饰、美妆)的最强杀器。
方向二:创意生产力革命
目前这是商业化最成熟、落地最广泛的领域。各家平台都在解决“素材制作难、贵、慢”的问题,但侧重点不同。

综合来看:中国平台(字节、阿里)在视频化和虚拟人方面走在全球前列,更激进地追求“替代人工拍摄”;而欧美平台(Amazon、Google)更保守,侧重于“辅助修图”和“背景合成”,严守商品一致性的底线。
方向三:投放操作智能化
这一层的核心是降低门槛。大模型正在把复杂的广告后台(Ads Manager)变成一个对话框。

综合来看:Google和Amazon正在努力让AI“教会”商家怎么投(赋能型);而淘天和字节更倾向于让AI“直接帮”商家投(托管型)。前者适合成熟市场的精细化运营,后者适合追求效率的中小商家。
1.3 大模型在Lazada广告平台落地方向
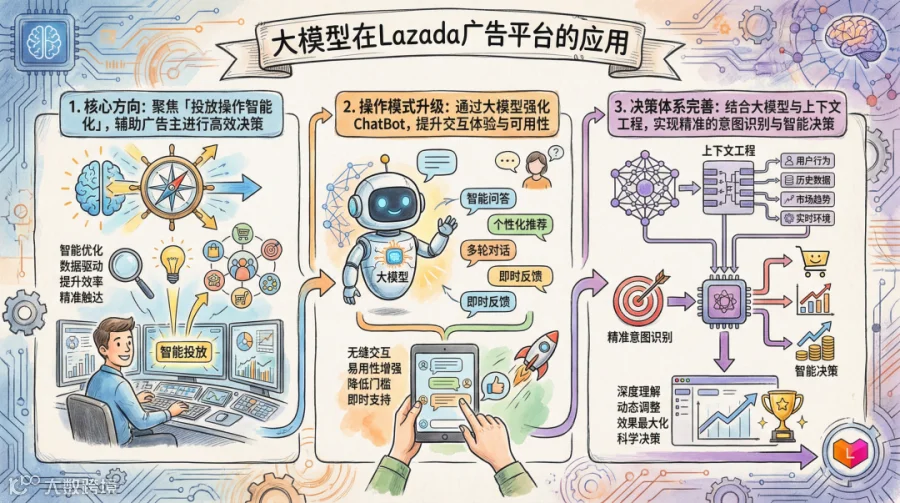
针对于「交互形态重构」部分,因其重心是在C端用户侧发力,且对于广告侧计费收入存在较大的影响,所以当前Lazada商业化并未在此方向上投入较多。
而至于「创意生产力革命」部分,在当前Lazada效果广告场景中,虽然大部分的商品创意素材是基于黑盒化的智能创意+优选的模式承接,但基于广告风控的要求,且平台和品牌广告主对于商品素材一致性的诉求较为强烈,所以在B端商家侧的发力也有限。
所以,抛开以上两个方向外,当前Lazada商业化平台,更多探索的都是「投放操作智能化」的落地场景。不同于Google和Amazon的赋能型产品,也不同于淘天和字节的托管型产品,Lazada在搭建的时候,对于不同场景均进行了探索、尝试和融合,特别是在辅助广告主投放决策的场景。而通过在Lazada商业化平台中引入大模型,我们希望实现:
二、整体方案
当然,无论是「操作模式升级」,还是「决策体系完善」,当大模型需要融入到现有的商业化平台架构中,其核心要解决三大根本性痛点:
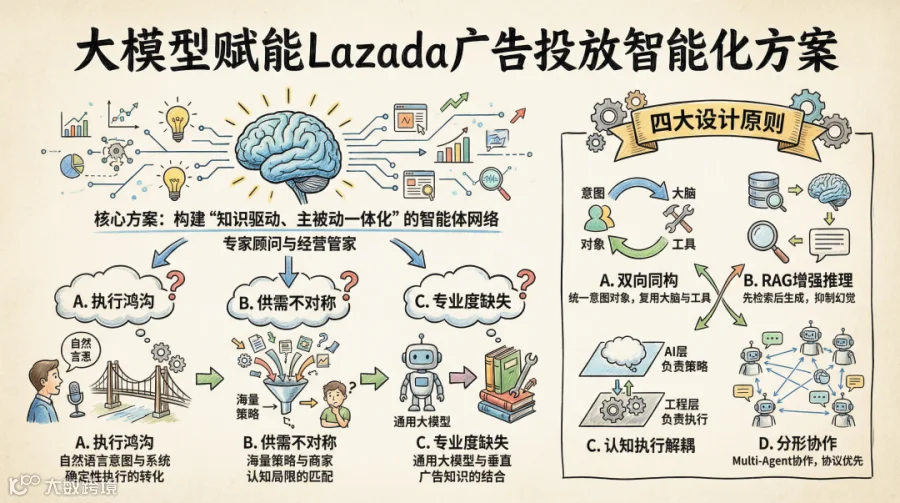
2.1 设计原则
为了能够高效解决上述痛点,同时也兼顾到现有广告平台的架构升级兼容性,为后续类似的「投放操作智能化」能力扩展性提供支持,整体架构设计遵循如下设计原则:
首先,为了实现系统的统一性与复用性,我们确立了双向同构原则。这意味着,无论是用户在Chat界面发起的显式提问,还是系统后台捕捉到的隐式行为信号,在架构内部都会被转化为统一的“意图对象”进行处理。基于这种同构设计,系统能够实现底层能力的深度复用,确保无论是主动交互还是被动触发,都共用同一套推理大脑、同一套基于RAG的知识库以及同一套原子工具库,从而极大降低了系统的维护成本与复杂度。
其次,为了保证决策的专业度与准确性,我们坚持检索增强的认知推理(RAG First)。在AI模型进行任何推理或生成建议之前,系统必须优先检索相关的“业务知识”,例如当前的流量竞争环境或相似商家的成功案例。这种“知识前置”的机制确保了所有的策略建议都有据可依,通过将生成内容与RAG检索到的事实进行严格对齐,有效抑制了大模型潜在的幻觉问题,提升了商业决策的可信度。
第三,为了平衡AI的创造性与工程的严谨性,我们采用了认知与执行的协同解耦策略。在这一体系下,AI层专注于处理概率性的任务,如复杂的意图理解与策略生成;而工程层则负责承接确定性的任务,包括原子工具的调用与状态管理。这种分层设计既保留了AI的灵活性,又通过工程手段保障了执行层面的安全与稳定。
最后,为了保障架构的弹性与扩展性,我们遵循分形协作与协议优先的设计思路。摒弃了单一大模型控制一切的僵化模式,我们转而采用Multi-Agent(多智能体)的协作模式,让不同的Agent各司其职。同时,引入MCP(模型上下文协议)作为统一的连接标准,实现了异构工程系统(如各类广告中台)与AI之间的标准化互联。这不仅解决了新老系统的兼容难题,更为架构未来的横向扩展提供了标准化的接口支撑。
2.2 流程设计
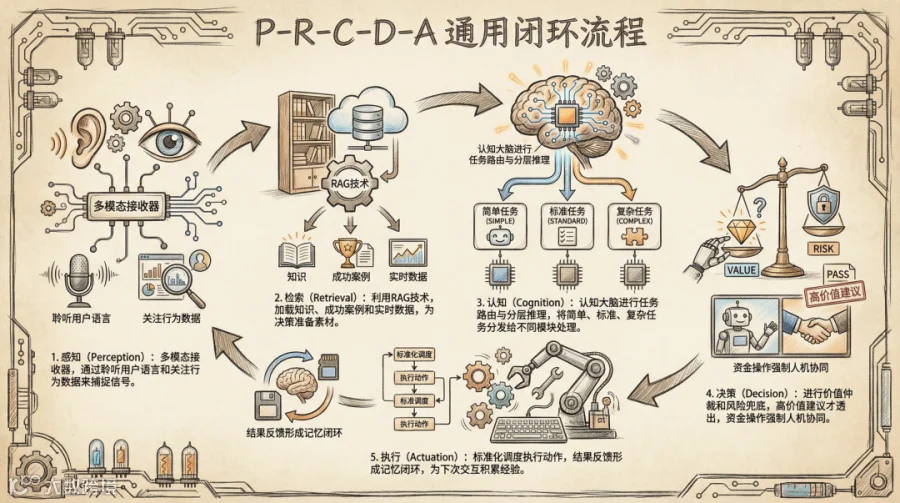
基于上述设计原则,我们将“显式提问”和“隐式需求”两部分的业务流,抽象为P-R-C-D-A (Perception - Retrieval - Cognition - Decision - Actuation) 通用闭环流程:
整个流程始于感知(Perception)。在这个阶段,系统作为一个多模态接收器入口:在 Copilot 交互中,它专注聆听用户的自然语言输入;而在需要主动干预的场景下,它则会在后台持续关注用户的行为流与经营数据上下文。
一旦捕捉到信号,系统随即进入检索(Retrieval)环节,利用 RAG 技术迅速完成知识与记忆的加载。这不仅意味着根据当前意图调取相关的帮助文档和平台规则,系统还会参考“相似成功商家”的配置案例(即少样本学习),并利用 MCP 获取实时的账户余额或计划状态,为后续判断备好素材。
有了充足的信息,认知(Cognition)大脑便开始运作,对任务进行动态路由与分层推理。针对查余额这类简单任务,直接交由 MCP Tools 处理;若是涉及新人起量等标准流程,则调用 Skills 库中的 SOP;而面对投放诊断等复杂难题,则会智能分发给专门的 Sub-Agents 去深度解决。
在真正付诸行动前,必须经过严谨的决策(Decision)。系统首先会进行价值仲裁,只有当 AI 建议的潜在价值显著高于用户当前操作的价值时,才会主动在界面上透出建议。同时,为了兜底风险,所有涉及资金的操作都内置了安全护栏,强制触发“人机协同(Human-in-the-loop)”机制,必须经由人工确认。
最后是执行(Actuation),所有的动作指令通过能力中心进行标准化调度,执行结果会被实时反馈回系统上下文,从而形成记忆闭环,为下一次交互积累经验。
2.3 架构设计
基于前述业务流的抽象,整体架构采用总线式设计。该架构的核心设计理念在于实现“中枢编排”与“底层能力”的严格解耦,确保系统在灵活响应复杂业务的同时,能够便捷地接入各类新工具。
统一交互网关作为系统的入口,部署了 Chat Adaptor 以处理所有对话请求,确保能够以流式输出(Streaming)提供即时反馈。同时,为实现 AI 建议与现有业务流程(BP)的无缝融合,系统设计了 Smart Slot Renderer,负责在界面的特定“槽位”动态渲染 AI 建议卡片。
请求进入内部后,交由智能编排中枢处理。该模块作为系统的大脑,主要由三部分协作完成:首先,Context Manager 负责维护全局 Session,融合当前任务的短期记忆与商家画像的长期记忆;接着,Knowledge Router 分析当前意图,判断所需补充的背景信息,向向量库发起查询并将结果拼接入 Prompt;最后,Planner 负责对任务进行拆解,并决定下一步的能力调用策略。
统一能力注册中心承接 Planner 发出的指令,作为系统的“武器库”,为适应不同复杂度的业务需求,将能力调用抽象为三种模式:
底层的知识与数据中台支撑上述逻辑运转。其中,Vector Database 用于存储帮助文档、优秀案例等非结构化知识的 Embedding;Knowledge Graph 维护商品、人群、渠道间的结构化关联;实时经营指标则由底层的 Data Services 提供。
为实现模块间的标准化串联,通用协议连接层引入了 MCP 协议。底层的广告服务与数据服务被封装为独立的 MCP Servers,从而实现“模型无关性”——无论上层接入何种大模型,均可通过统一标准读取资源(Resources)或调用工具(Tools)。
上述架构构建于现有的基础设施层之上,复用了原有的数据平台、广告中台服务及模型服务集群,以确保基础设施的稳定性与资产的高效复用。
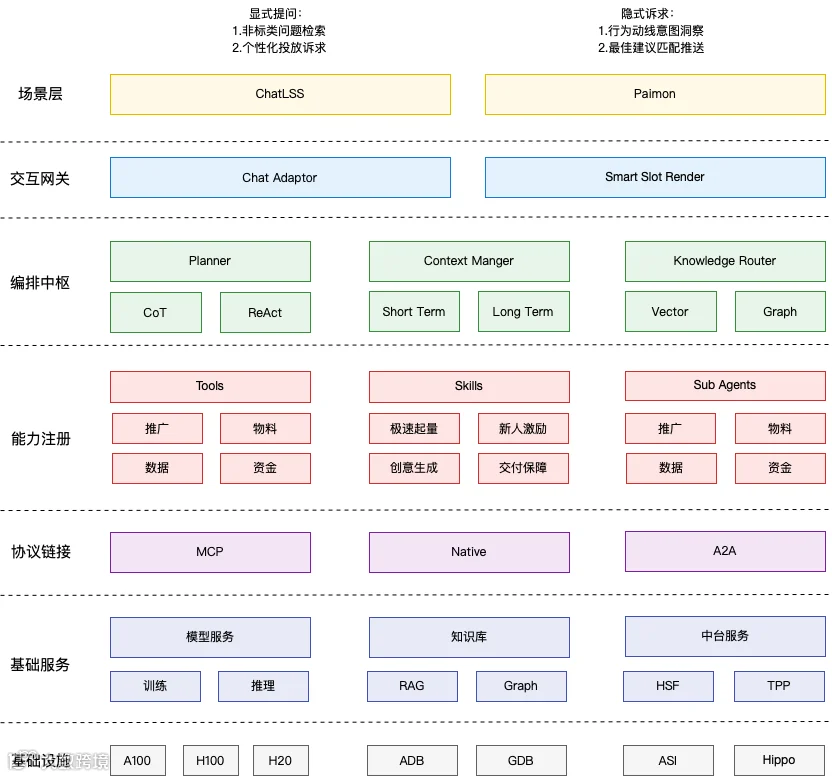
这套架构方案通过引入Sub-Agents实现了业务复杂度的分治,通过RAG注入解决了大模型“不懂业务”的问题,通过 MCP 实现了新老系统的平滑连接,通过Skills固化了专家经验。它成功地将“响应式”与“预测性”统一在同一个智能内核之下,标志着广告系统从“功能堆砌”向“自主经营”的跨越,为商家提供了一个具备行业记忆、能够深度思考、并且执行严谨的AI经营伙伴。
2.4 建设成果
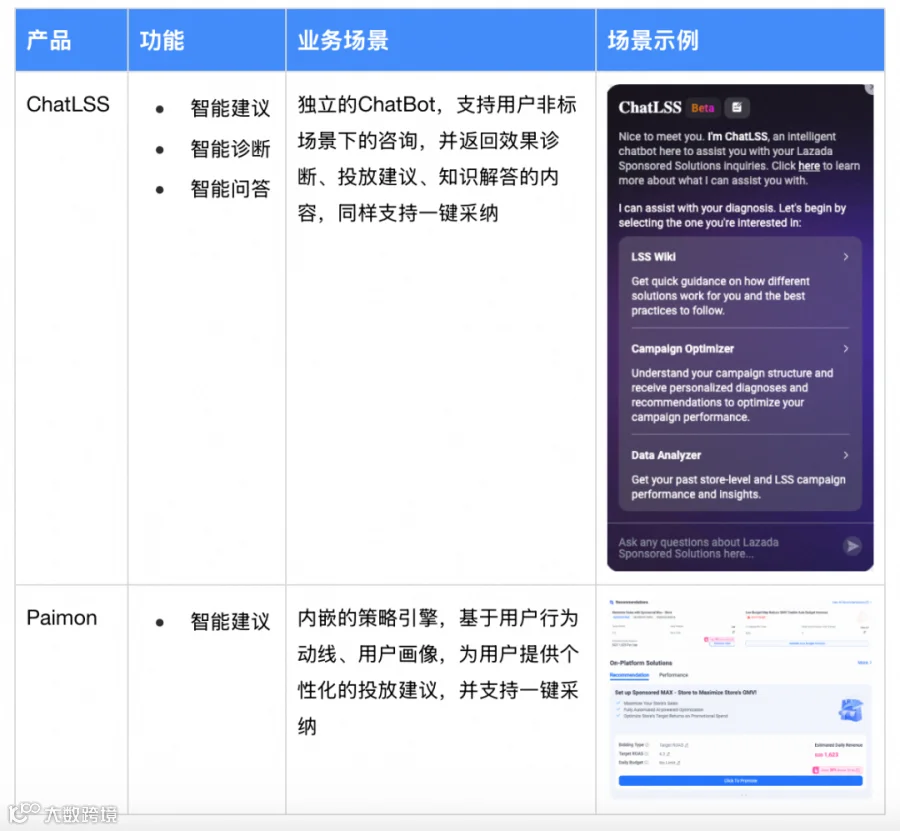
在上述的架构设计下,我们在过去两年成功落地了ChatLSS和Paimon两款面向B端广告主的「投放操作智能化」产品,其取得的核心成果如下:
三、落地场景
诚然,上述系统的落地,并非是一蹴而就的,在相关系统的搭建过程中,以交互形态为分隔,其核心面临的痛点和要解决的问题还是存在着一定的差异:
3.1 ChatLSS:交互范式重构
对于在商业化平台中接入ChatBot形式,绝非简单的接入一个大模型接口,而是一场对交互范式和系统底层服务能力的重构。
3.1.1 核心痛点
核心痛点并非模型不够聪明,而是商业经营的严肃性与大语言模型(LLM)的概率性之间的矛盾。具体表现为:
3.1.2 设计原则
针对上述痛点,架构设计必须遵循以下三大原则:
3.1.3 系统流程
为解决因LLM引入带来的响应延时过长以及不确定性,我们采用了Workflow+ReAct相结合的模式,来保障系统高频问题输出稳定性的同时,进一步提升非标问题的回答准确性。系统流程如下:
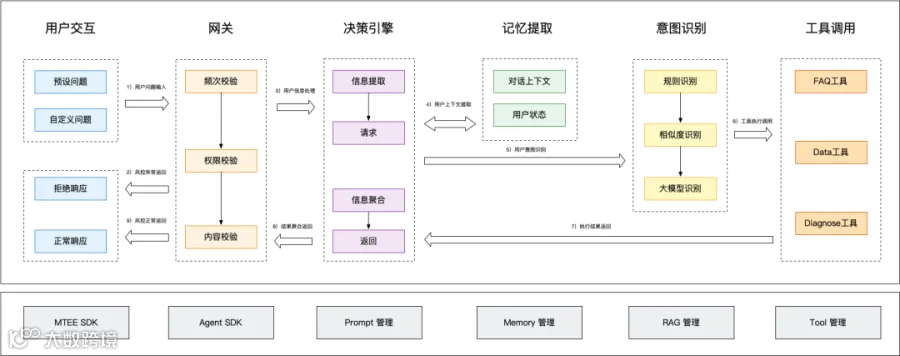
针对于用户交互流程的分析,我们将整体业务流程拆分为了6个阶段,从而保障整体业务流程严格遵循“输入—安检—决策—理解—执行—输出”的闭环逻辑,具体流程如下:
3.1.3.1 用户交互
这是系统与外界沟通的门户。业务流程始于用户的输入,同时也终于系统的响应。
-
预设问题:针对高频场景,系统在BP侧展示快捷引导入口,用户点击即可发送,减少交互成本。 -
自定义问题:用户通过文本框输入自定义问题,这是系统主要解决的非标准化流程。
-
正常响应:经过完整处理链路后,系统返回相应的问题回答。 -
拒绝响应:当请求未能通过安全校验或触犯风控规则时,系统将直接拦截并返回拒绝提示,不再消耗后续计算资源。
3.1.3.2网关
在请求进入核心处理流程之前,必须经过严格的“网关”。这一流程由底层的风控SDK提供支持,确保系统的稳定性与合规性。
3.1.3.3 决策引擎
这是整个Agent的中枢神经,负责调度各个组件。
-
信息提取:决策引擎首先解析用户的原始请求,结合当前时间、当前站点、当前语言等元数据,构建标准化的Prompt输入对象。 -
请求分发:引擎根据初步判断,向“记忆模块”发起请求,获取决策所需的上下文信息后,连通上述的Prompt信息,发送到“意图识别模块”,用于识别用户意图。
- 信息聚合:在后续环节(工具执行)完成后,决策引擎负责将所有返回的碎片化信息进行格式化组装。
- 返回处理:最终生成的答案再次经过后置风控(防止模型幻觉输出有害信息)后,推送到用户交互层。
3.1.3.4 记忆提取
为了让AI具备“连贯性”,业务流程中必须包含记忆的读写。此环节由底层的Memory管理模块支持。
3.1.3.5 意图识别
这是业务流程中最具策略性的环节,采用了“漏斗式”的三级识别机制,旨在平衡响应速度与处理能力:
3.1.3.6 工具调用
当意图识别判断需要执行具体操作时,业务流程进入执行阶段。此环节由Tool管理模块驱动。
3.1.4 核心模块
尽管通过完整的流程设计,系统能够有效承接相应的业务闭环流程。但真正落地阶段还是会有诸多问题,譬如高昂的成本、记忆容量的限制、任务拆解和调整的挑战、以及输出结果的可靠性等。
3.1.4.1 PARSER框架
PARSER(Parallel Agent with Replan, State, Execution and Reflection)框架,是用来解决传统Agent在垂直领域落地时面临的高耗时(RT)与规划不稳定的矛盾,其核心为:
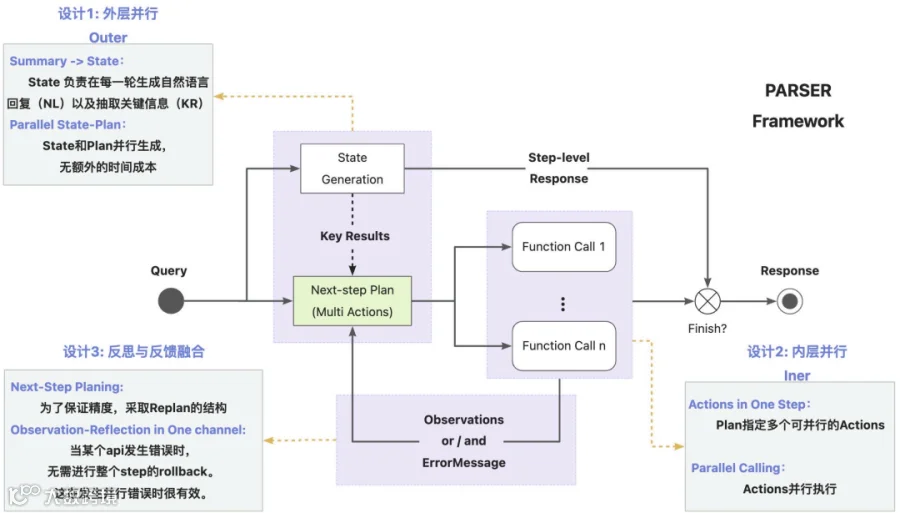
3.1.4.2 双重状态管理与模块化设计
在Agent的执行链路中,PARSER对状态的管理进行了细腻的解耦处理:
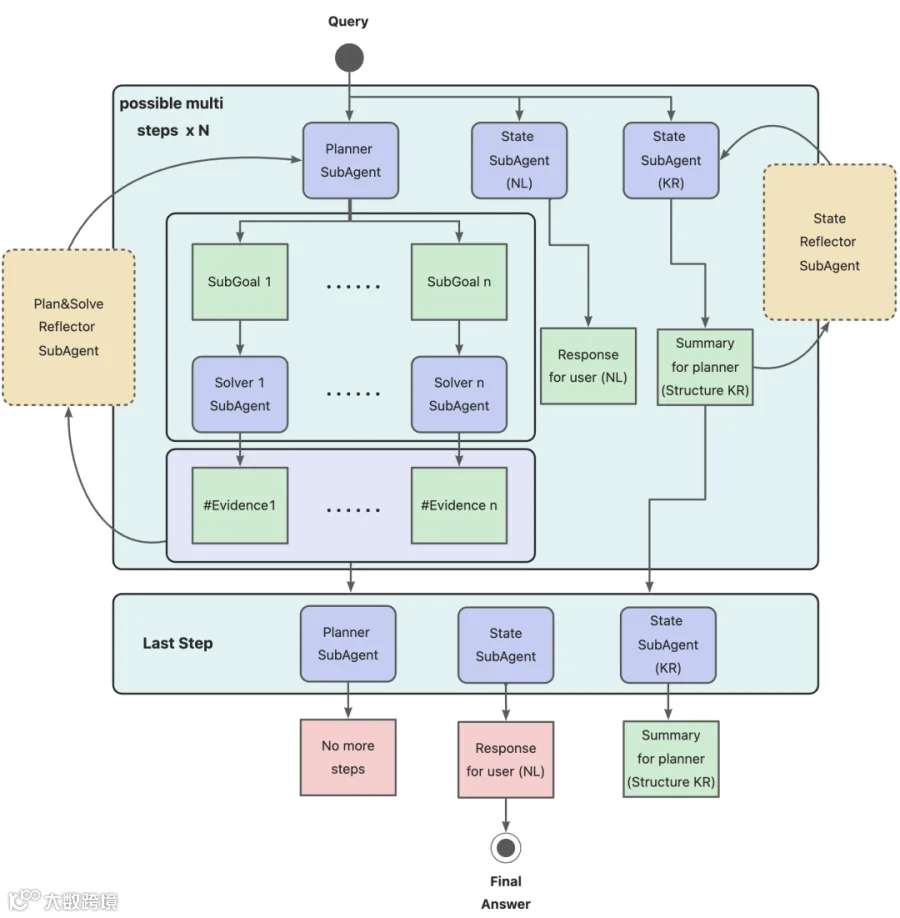
3.1.4.3 多维度Agent性能评估体系
同时,为了区别于传统的单点问答评估,该设计提出了一套全方位的Agent量化指标,为模型的迭代指明了方向:
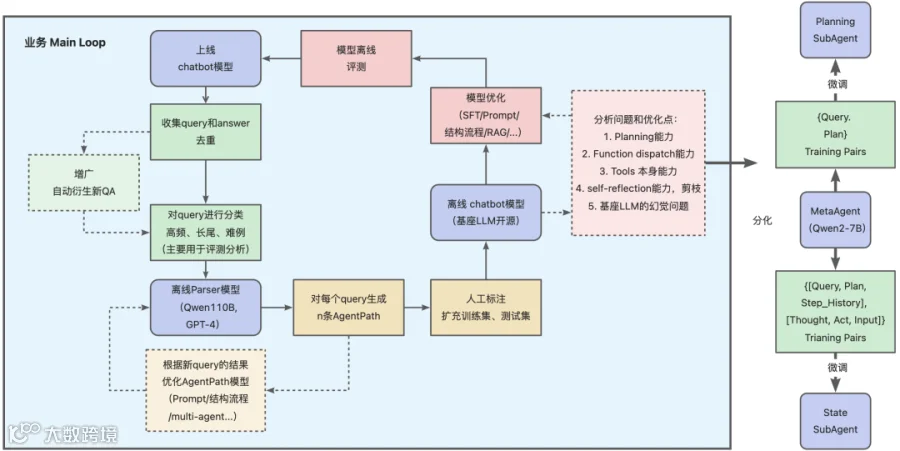
3.1.5 架构总结
这套架构升级方案的核心逻辑在于“解耦”与“封装”。我们不推翻原有的广告引擎,而是用大模型构建一个“超级业务员”(Agent)。它听得懂人话(交互层),脑子清楚(编排层),并且手握操作系统的权限(工具层),最终实现从“人找功能”到“功能找人”的跨越。
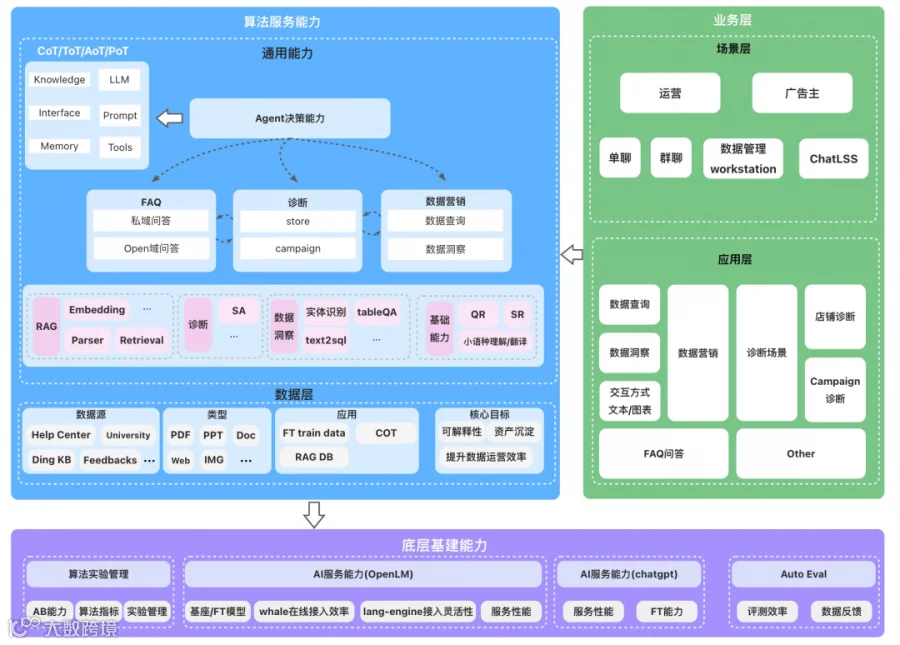
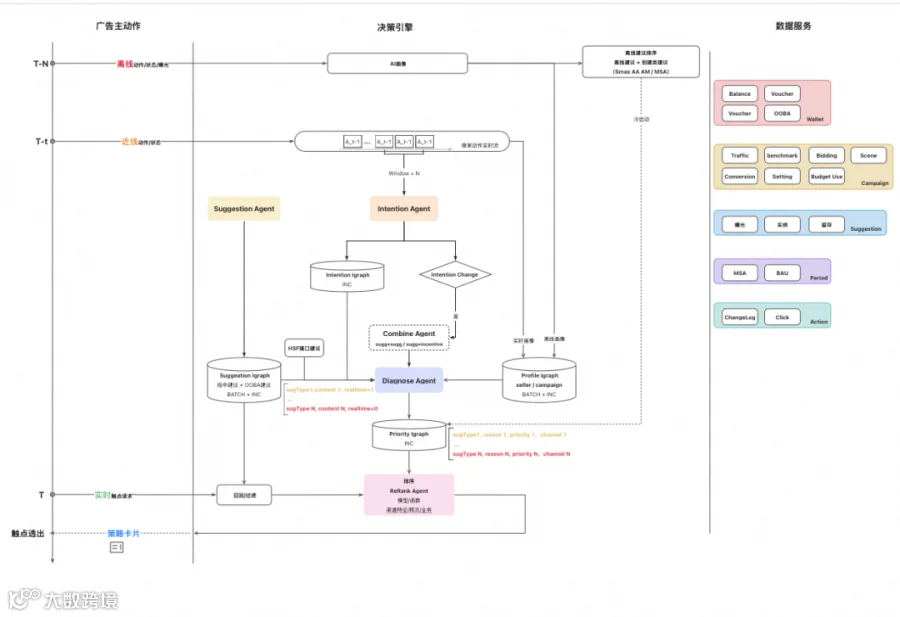
3.2 Paimon:基于场景的预测性干预
而对于Paimon来说,这种模式不再依赖用户主动发起对话(Chat),而是将AI的决策能力“无感”地融入到用户的工作流(Workflow)中。我们将这种模式定义为“基于场景的预测性干预”。它比ChatBot更进一步,从“人找服务”彻底转变为“服务找人”。
3.2.1 核心痛点
在这种非对话模式下,我们试图解决的核心痛点与ChatBot完全不同:
3.2.2 设计原则
为了解决上述痛点,架构设计需遵循以下原则:
3.2.3 系统流程
为解决当前基于静态的召回排序范式,我们有效整合了LLM,并完善了相应的上下文信息,来保障动态决策模式的升级落地。我们将整体框架进行了一版升级,系统流程如下:
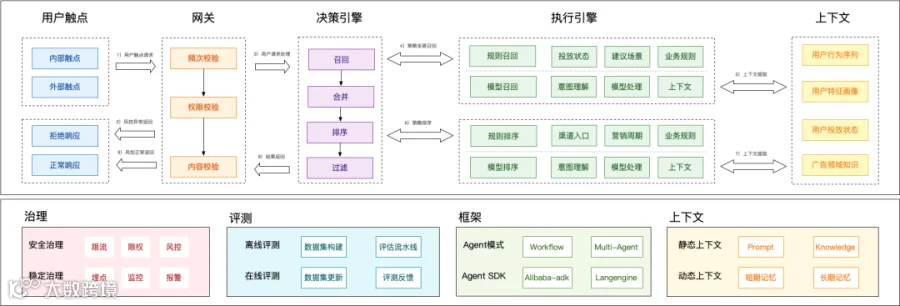
针对于用户交互流程的分析,我们将整体业务流程拆分为了6个阶段,并融入到了以下5个关键模块:
3.2.3.1 用户触点
当前所有策略的展示,均始于用户触点的触发,这是整个业务流程的流量入口。
3.2.3.2 网关
在策略请求进入核心计算逻辑之前,必须经过前置校验,这一步由网关负责,主要处理非业务逻辑的通用校验,保障系统稳定性。
3.2.3.3 决策引擎
这是系统的核心决策模块,负责整体业务逻辑的处理。该阶段采用“召回-合并-排序-过滤”的标准推荐系统范式。
3.2.3.4 执行引擎与上下文层
决策引擎的每一步(特别是 召回和排序)都强依赖于右侧的执行引擎和上下文数据。
-
规则召回:基于用户实时投放状态,以及算法场景获取到的建议,基于业务规则召回相应的策略候选集; -
模型召回:结合用户上下文,进行用户实时意图判断后,进一步增量召回相关策略及建议值、建议理由;
-
规则排序:基于触点入口,以及当前的投放周期,基于业务规则对于召回的策略候选集进行重排; - 模型排序:结合用户上下文,进行用户实时意图判断后,结合大模型对于召回策略候选集进行重排;
-
在决策过程中,特别是在模型召回和模型排序的场景下,会实时从上下文中心拉取数据。 -
用户侧数据:包括用户行为序列(最近浏览了什么、点击了什么)、用户特征画像(年龄、性别、兴趣标签)。 -
业务侧数据:包括用户投放状态(是否是新客、是否在白名单)以及广告领域知识(特定促销策略、广告产品差异)。
-
执行引擎不仅是查库,还包含实时推理的部分(可通过近线方式解耦)。例如,利用大模型(LLM)进行意图理解,分析用户行为序列的深层含义;或进行模型处理,实时生成个性化建议值和推荐理由。
3.2.3.5 输出
经过以上计算和筛选后,决策引擎输出最终结果列表。
3.2.4 核心模块
基于上述流程设计,系统核心在于离线和在线流程的结合,通过流程编排叠加ReAct架构,落地最终AI Agent设计。整体分为:
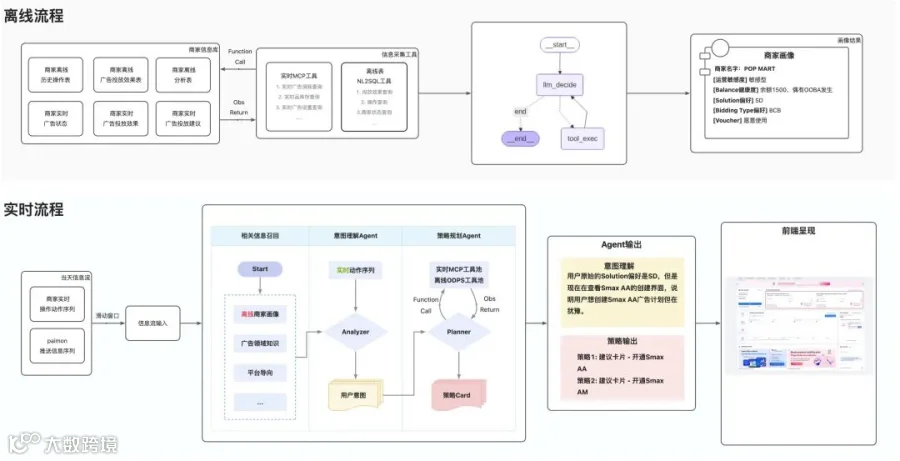
3.2.4.1 离线流程:商家画像Agent
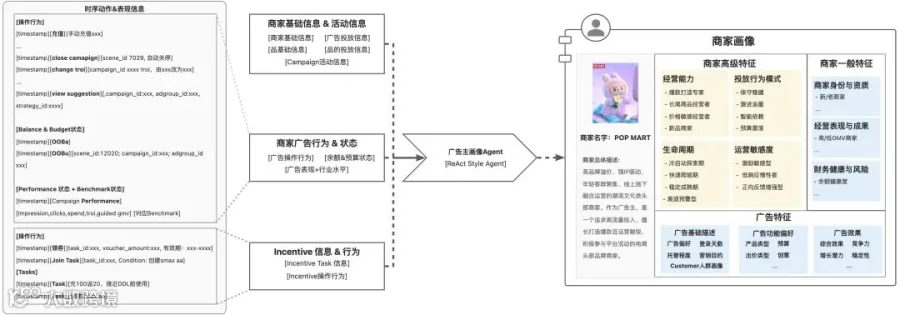
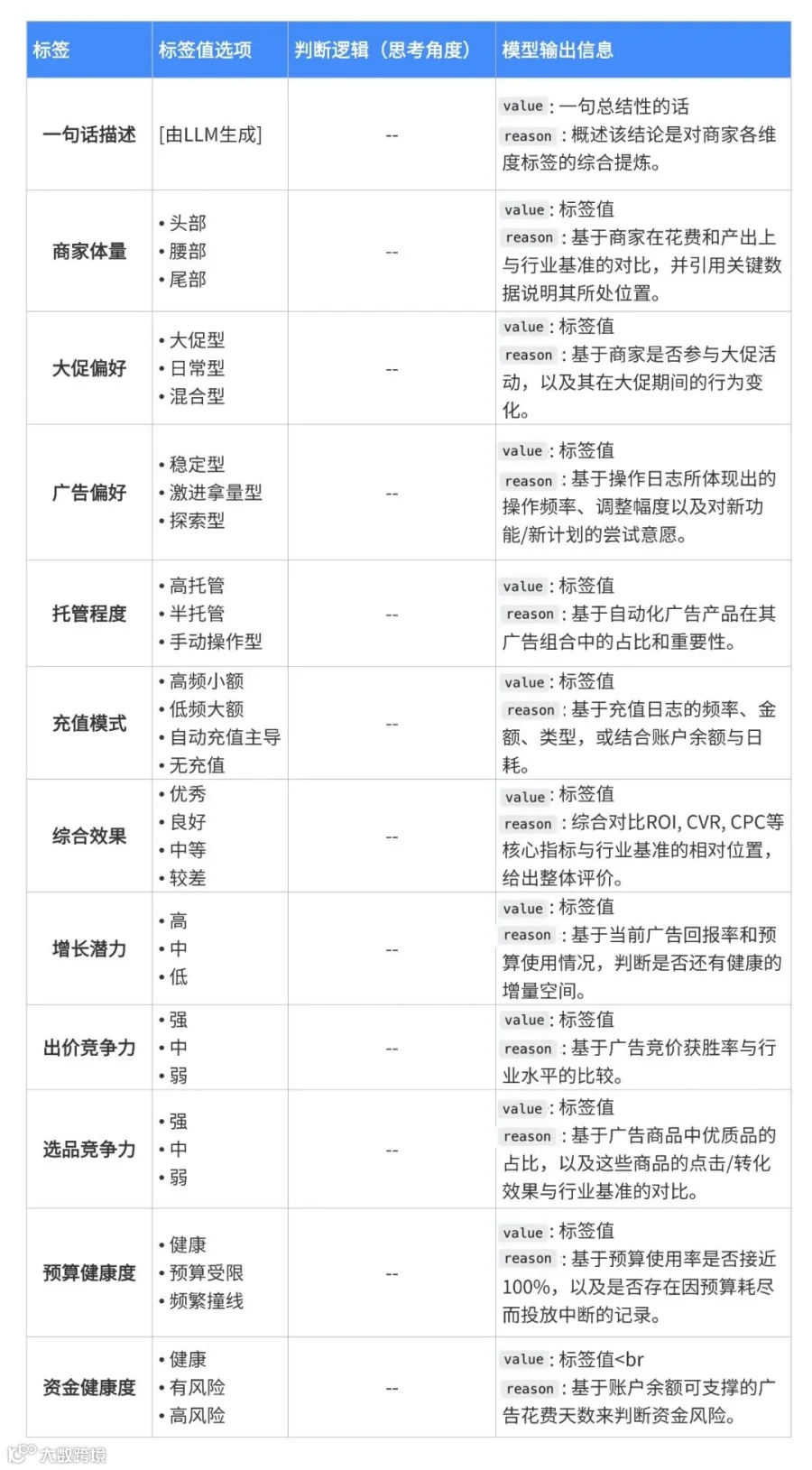
我们实现了一个ReAct Agent进行深度的广告主画像分析,目标是下钻更多信息,抽象出更高级的特征。广告主画像会包含这些维度:
3.2.4.2 在线流程:意图理解&策略生成Agent
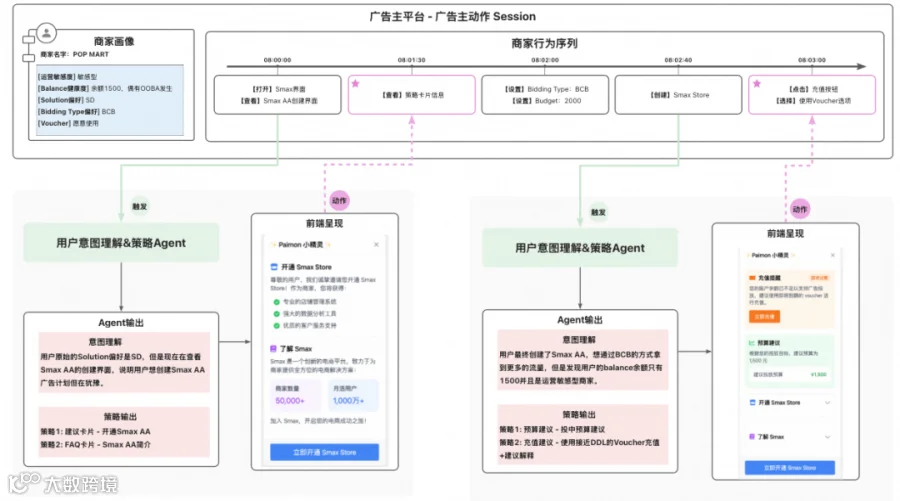
在用户的关键动作时触发Agent分析,端到端实现策略和信息的召回排序过程,生成实时个性化信息流。
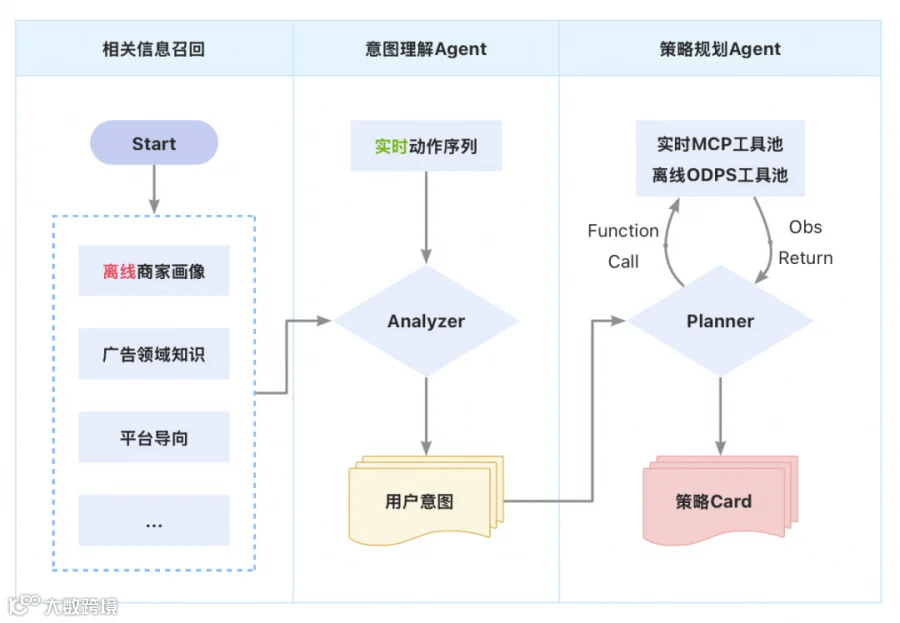
构建一个面向广告场景的意图理解Agent,基于商家画像、平台运营导向、广告领域知识以及商家实时行为序列,动态识别并预测商家在营销活动中的潜在意图,实现精细化策略推荐与自动化投放优化。
整体技术栈融合了上下文工程(Context Engineering)、检索增强生成(RAG)与多源信息融合等技术,构建一个具备强语义理解能力与实时响应能力的意图理解Agent。
构建一个以 ReAct 框架为核心的智能策略卡片Agent,根据上游实时输出的商家营销意图,通过多轮自主规划,动态调用平台能力组件(MCP),逐步获取所需数据、策略卡片模版等信息,并最终生成结构化的策略建议卡片,实现从“意图感知”到“策略生成”的端到端自动化决策闭环。
3.2.5 架构总结
此模式下的技术升级,其核心变革在于驱动了系统交互与决策逻辑的根本性演进。首先,系统实现了从“同步响应”向“异步预判”的跨越。通过利用大模型在后台闲时对全量商家画像进行深度处理,系统成功将繁重的“思考”过程前置,不再依赖用户的实时触发。其次,分发机制从传统的“硬规则”升级为“模型排序”。通过引入推荐算法,有效解决了 B 端产品因功能堆砌而导致的“找不到、用不好”难题,从而实现了界面呈现与策略透出的千人千面。
总体而言,这套架构不仅让大模型能够以“润物细无声”的方式辅助商家经营,更代表了目前电商广告平台从单一“工具”向综合“解决方案”转型的最高阶形态。
四、总结展望
在过去的两个财年,我们在「投放操作智能化」这个大方向下,通过ChatLSS和Paimon的建设,分别在操作模式升级上、以及决策体系完善上,都进行了非常积极探索,并且效果明显。特别是Paimon的建设上,虽然探索开始的时间较晚,但是对于业务带来的效果和影响却是非常显著的。
当然除了带来的增量业务效果外,我们对于AI Agent该如何引入到现有的工程系统中,也开始有了体系化的理解和实践经验:通过双向同构原则的遵循,统一交互意图并复用业务内核;并且以知识库信息优先,以业务实据驱动推理,抑制幻觉;通过认知与执行解耦,由AI生成策略、工程保障执行;最终通过多智能体与MCP协议,实现异构系统的标准化互联与弹性扩展。
4.1 演进方向
在下一阶段,我们会进一步在Paimon的建设上投入更多的精力,整体工作会围绕两部分展开:
4.1.1 生成式策略
通过在大促期间增量召回策略的落地验证该模式的有效性,在接下来会将更多高质量的算法建议,通过增量召回的模式,更加及时准确地召回并推送给用户,从而进一步提升建议策略的采纳率。
除此之外,对于之前和触点绑定的规则排序逻辑,也会通过模型排序和价值打分进行进一步评估量化,从而将B端入口整体重构为生成式策略召回入口。