
今天看到知乎热榜里那条问题时,我第一反应不是“Opus 4.7 强不强”。
而是另一个更别扭的问题。
2026 年 4 月 16 日, Anthropic 对外发布 Claude Opus 4.7。 The Verge 当天援引 Anthropic 的说法,给它下的定义很明确:这是目前 最强的“公开可用”模型,复杂软件工程、图像分析、指令跟随、文档和幻灯片生成都比 Opus 4.6 更强,价格却维持在和 Opus 4.6 一样的 $5 / 百万输入 token、$25 / 百万输出 token。
看着像一次很标准的旗舰升级。
但这套叙事太顺了,顺得有点假。
但把时间线往前拨九天,味道就全变了。
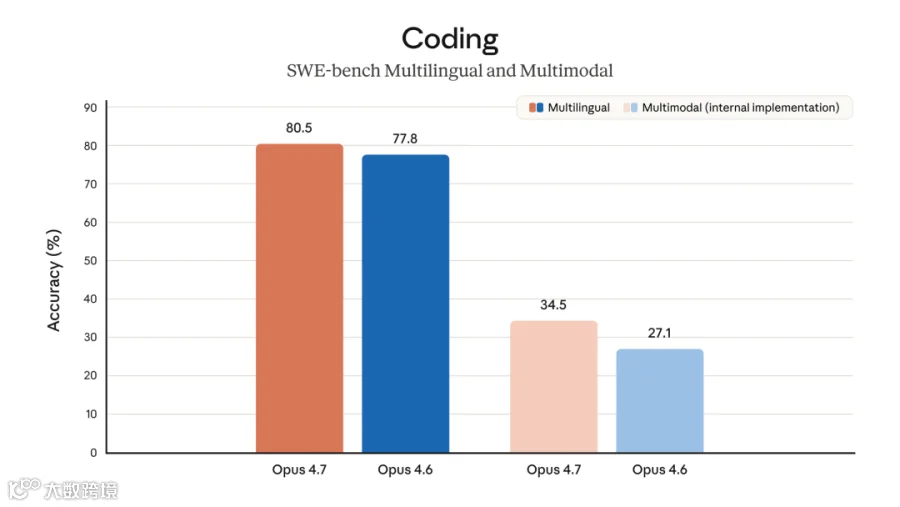
2026 年 4 月 7 日, Anthropic 刚刚宣布 Project Glasswing,同时把 Claude Mythos Preview 放进一个更小、更硬的圈子里。官方页面直接写明, AWS 、 Apple 、 Google 、 JPMorgan Chase 、 Microsoft 、 NVIDIA 这些伙伴会优先拿到 Mythos Preview ,用它做防御性安全工作; Anthropic 还承诺了 1 亿美元 的 usage credits 。更狠的是, Anthropic 自己承认, Mythos Preview 在多项关键评测上全面压过 Opus 4.6,像 SWE-bench Pro 是 77.8% vs 53.4%,Terminal-Bench 2.0 是 82.0% vs 65.4%。
这就不是单纯的“新模型上线”了。
这像什么?像一家俱乐部突然把最贵的酒留在内场,只把口感更稳、风险更低、还能大规模卖的那一层放到大厅。
问题也跟着出来了:Anthropic 现在公开卖的,已经不一定是它手里最强的能力;它公开卖的,更像是它愿意让大多数人接触到的最强能力。

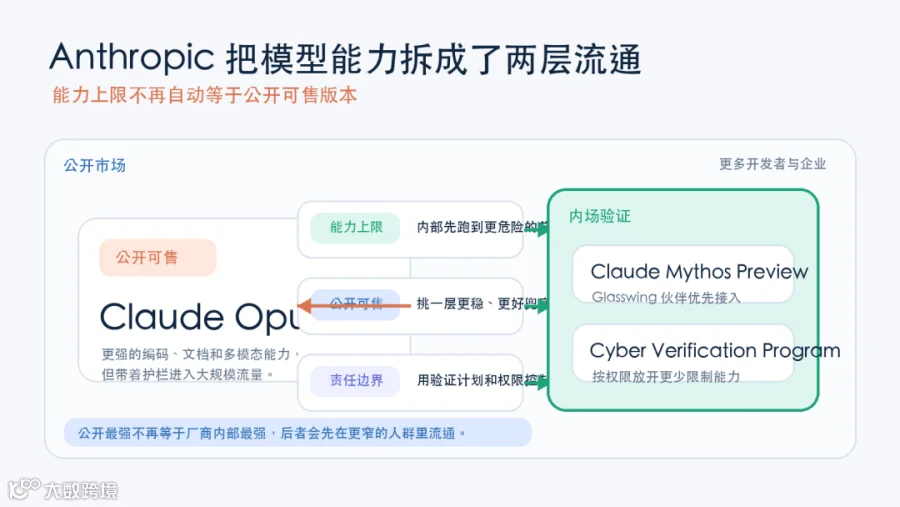
这次发布最关键的,不是模型更强,而是“公开版”和“内场版”第一次被明确拆开
过去大家聊模型更新,习惯默认一件事:新发出来的旗舰,大概率就是公司当前最强那一档。
OpenAI 这样干过, Google 这样干过, Anthropic 之前大体也是这个节奏。你看到一个新名字上线,脑子里的默认翻译通常是:“好,榜单又刷新了。”不对,准确说,是公开榜单又刷新了。
这次不一样。
The Verge 在 4 月 16 日 的报道里提到, Anthropic 在 Opus 4.7 的系统卡里直接承认,它并没有推进 Anthropic 的 capability frontier,因为更早公布的 Mythos Preview 在“所有相关评测”上都拿到了更高结果。更微妙的是, Anthropic 还说过一句很硬的话:他们会把 Mythos Preview 的发布控制在有限范围,先在能力更弱的模型上测试新的网络安全防护;Opus 4.7 就是第一层试验田。
这句话挺冷的。也挺不舒服。
它等于把模型商业化里原本混在一起的三件事,强行拆开了。
第一层,能力上限。谁最会写代码,最会找漏洞,最会长时间自主跑复杂任务。
第二层,公开可售。谁能放进 API 、文档、产品页、销售流程里,大范围给客户用。
第三层,安全阉割和责任边界。哪类能力要被压下去,哪类人可以申请更少限制,出了事由谁兜底。
以前这三层经常捆着卖。现在, Anthropic 开始明着分层卖了。
Mythos 被锁进 Glasswing 后, Opus 4.7 更像一张公开售卖的“安全门票”
如果只看发布文案,很多人会把 Opus 4.7 当成一台更能打的通用旗舰。这当然没错,但只说到这里,其实有点浅。
因为 Project Glasswing 的官方说明写得非常直白: Anthropic 观察到的新模型,已经在网络安全场景里展示出足以改变行业节奏的能力,所以才要和一批关键基础设施伙伴一起,先做防御性实验,再决定怎么往外放。
红队技术说明甚至更吓人。
red.anthropic.com 在 4 月 7 日 的文章里写到, Mythos Preview 在测试中已经能发现并利用主流操作系统和浏览器里的高危漏洞,还能在一些场景里把已知漏洞串成完整 exploit 。那篇文章里最刺眼的一句,不是分数,不是榜单,而是一个事实:Anthropic 没有专门把它训练成“网络安全模型”,这些能力是从通用代码、推理和自主性里顺带长出来的。
这就麻烦了。
因为一旦公司内部已经知道自己摸到了更危险的一层,公开版本的每一次升级,逻辑都会变。它不再只是“把最强模型卖给更多客户”,而会变成“在不把风险一起放出去的前提下,卖一个尽量强、但仍可控的版本”。说白了,先把最锋利的那部分包起来,再谈规模化。
Opus 4.7 在这个位置上,角色很清楚。
它不是 Mythos 的平替。也不是过渡款那么简单。它更像一张公开售卖的安全门票,一边给企业客户继续交付高级编码和多模态能力,一边替 Anthropic 在真实流量里验证防护策略、权限边界和审核机制。
:::callout
Opus 4.7 更像一个“可大规模出售的受控最强”,而 Mythos 才是 Anthropic 现在真正不敢完全公开铺开的能力上限。
:::
这件事对开发者和企业更现实的影响,是以后不能只看榜一了
这才是我觉得今天这个热点真正该写给从业者看的地方。
过去很多团队选模型,习惯先问一句:现在谁第一?
这个问题以后会越来越不够用。甚至有点过时。
因为你眼前能买到的第一,未必是厂商内部真正的第一;你现在能接到的能力,也未必等于厂商实验室里已经跑通的能力。模型市场正在从“公开榜单竞争”,慢慢滑向另一种更难描述的竞争:谁更敢放,谁更会控,谁能把最危险的边界画得让监管、客户和自己都还能睡得着。 这会让很多只盯排行榜的团队后面吃闷亏。
这会带来三个很现实的变化。
第一,评测榜单的解释方式要变。以后看到榜首,你得先问一句:这是公开版榜首,还是内部版榜首?是完整能力,还是带护栏能力?口径一乱,横向比较就很容易失真。
第二,企业采购逻辑会变。很多大客户未必最想买“绝对最强”,他们更可能愿意买“合规、稳定、责任链明确的次强”。说白了,采购真正怕的不是模型少做两分题,怕的是模型在灰区里多做两步。多那两步,出了事,场面会很难看。
第三,产品路线会变。能拿到验证计划、白名单、合作项目、研究预览资格的团队,未来接触前沿能力的时间差会越来越大。以前大家差的是 prompt 水平、工程接入、数据闭环。后面可能还要多一层,差的是你能不能进内场。
这就很现实了。也有点烦。
因为“人人都能调用最前沿模型”的神话,正在被厂商自己亲手拆掉。
接下来真正要盯的,不是 Opus 4.7 会不会赢,而是谁开始定义“谁配用更强的模型”
如果这条线继续往前走,我觉得后面有三件事要比参数表更值得盯。
第一,Cyber Verification Program 会怎么落。谁能申请,审核标准是什么,放开的到底是调用权限、工具权限,还是更少的能力压制。这个机制一旦成型,它就不只是安全措施,而会变成新的能力分发闸机。
第二, Anthropic 会不会把这种“内场最强 + 大厅次强”的分层做成长期制度。要是真这样,别家大模型公司大概率也会跟。没有谁会在知道风险更高的前提下,还把全部能力一口气公开摊开卖。
第三,开发者社区会不会开始重新定义“最新模型”。以后“最新”可能不只指发布日期,还要指公开状态、权限等级、是否带护栏、是否在特定行业白名单内。一个名字,背后可能对应好几层不同的实际能力。我本来想说这只是命名问题,不对,这是能力分发问题。
我不急着夸 Claude Opus 4.7 这次升级有多漂亮。
我更在意另一件事: Anthropic 已经提前示范了一种新秩序。
厂商手里最强的模型,不一定先卖给所有人。
先拿到的,可能是最能承担风险的人。
后拿到的,可能才是大多数用户。
这不是发布节奏变化。
更准确地说,这是前沿模型开始按权限分层流通了。
参考链接
参考链接
[1] The Verge | Anthropic releases a new Opus model amid Mythos Preview buzz: https://www.theverge.com/ai-artificial-intelligence/913184/anthropic-claude-opus-4-7-cybersecurity
[2] Anthropic | Project Glasswing: Securing critical software for the AI era: https://www.anthropic.com/glasswing
[3] Anthropic RED | Assessing Claude Mythos Preview’s cybersecurity capabilities: https://red.anthropic.com/2026/mythos-preview/