
十轮迭代,一台机器跑 32 小时,没人插手。Harness从一个裸种子出发,自己长成了一个超过所有手工设计版本和自动化基线的配置。更意外的是,冻住之后直接换基准、换模型,收益还在。
不只是模型的事
Coding agent的表现不全靠底层模型。同一个模型,外面那层壳不一样,任务完成率差十几个点很正常。
这层壳包括系统提示词、工具定义、中间件、长期记忆、技能库、子智能体配置。论文里叫Harness。它管的是模型怎么感知环境、怎么调工具、怎么控制上下文、怎么从错误里恢复。Shell超时设几秒,工具返回什么格式,中间件在哪个节点做检查。这些细节影响的不是一两分,是整条链路能不能跑通。
目前几乎所有Harness都是人手调的。 开发者翻trajectory,找重复出现的失败模式,手动改prompt、改工具、改中间件。底层模型一周一个版本,手工调参根本跟不上。
直觉上这事该自动化。但现有方案基本只动一个组件,绝大多数只调prompt,少数改skill或playbook。同时动全部组件、端到端优化整个Harness,没人做过。
不是不想。两个结构性问题一直卡着。 第一,trajectory太长太乱,一次rollout百万级token,有效信号沉在噪音里。第二,Harness各组件紧耦合,改prompt以外的东西容易出错,出了错也不知道是哪个改动引起的。
复旦大学、北大和上海奇骥智峰的研究团队在 Agentic Harness Engineering(AHE) 这篇论文里给出了一个完整的闭环方案。他们的判断很直接:瓶颈不是智能体能力,是可观测性。
三根支柱
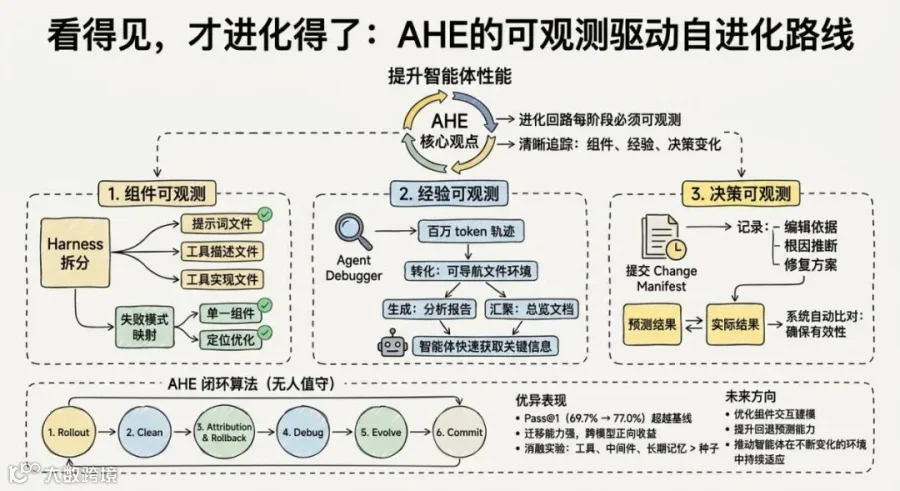
AHE的设计围绕一条原则:进化回路里每个阶段都必须可观测。 组件什么样,能追踪。经验怎么来,能下钻。每个编辑做了什么预测、有没有兑现,能验证。
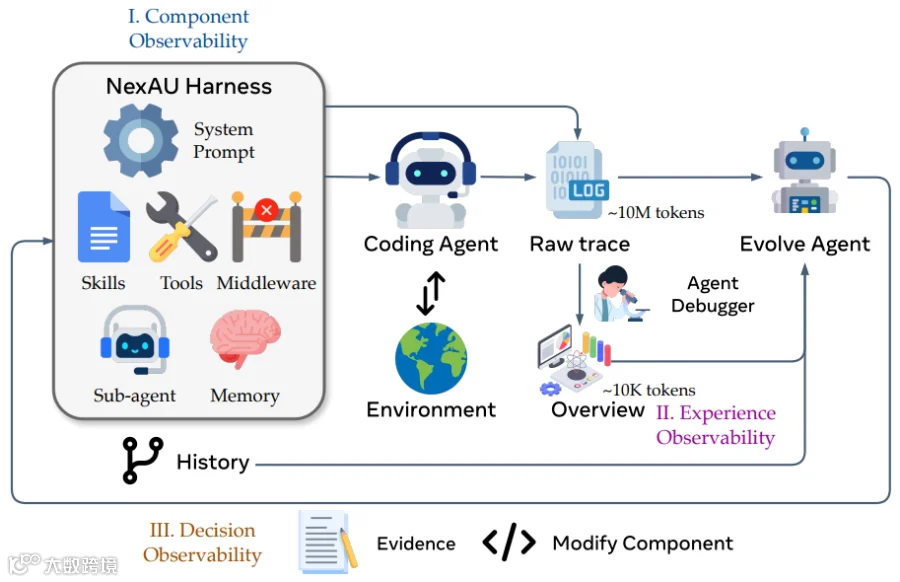
图1 AHE流程将三个可观测连接成一个loop
组件可观测:Harness拆成文件
AHE跑在NexAU框架上。这个框架把Harness的七个组件类型全暴露成独立文件:系统提示词、工具描述、工具实现、中间件、技能、子智能体配置、长期记忆。组件松耦合,加一个中间件不用改prompt,加一个skill不用碰任何工具。
这个设计意味着:每个失败模式能干净地映射到单一组件类。 进化智能体有了清晰的动作空间,每次 pass@1 的变化能定位到一个文件,不散在几百行非结构化的prompt文本里。每个逻辑编辑就是git仓库里一个commit,diff和回滚都免费附送。
种子Harness用得极其克制:只有一个shell执行工具,没有中间件,没有技能,没有子智能体,没有长期记忆。 论文刻意从"裸"种子出发。种子如果已经高度调优,就没法判断gains来自进化还是来自种子本身。
经验可观测:百万token压成可读证据
一次rollout,一个任务的轨迹动辄上百万token。原样丢给进化智能体,读不完,读完也抓不住重点。
AHE的解法叫Agent Debugger:不直接读原始轨迹。先把轨迹转成一个可导航的文件环境,每条消息一个文件,再用一个debugger智能体去探索每个失败任务或成功模式的根因。每个任务产一份分析报告,所有报告再汇聚成基准级总览文档。
原始轨迹也保留着,进化智能体需要验证某个判断时能下钻细查。这套分层就是给经验数据加索引:总览 → 任务报告 → 原始消息。 不用每次从头啃百万token。
决策可观测:每个编辑都是一份可证伪的合同
这层是AHE最独特的设计。
每次编辑,进化智能体必须提交change manifest:写上编辑依据的失败证据、推断的根因、针对性的修复方案,还有一份自我声明的预测,列出预期哪些任务会被修复、哪些有回退风险。
下一轮跑完,系统自动比对预测和实际的任务级结果变化,得出每个编辑的判决。预测对,编辑保留;预测错,文件级回滚。
这套机制把编辑从"我觉得这样改有帮助"扭成了"我预测这样改能修好任务 A 和 B,可能破坏任务 C,下轮见分晓"。它堵死了编辑智能体自我合理化的后路。 不看理由写得好不好,看结果对不对。
整条闭环算法只有六步:rollout、clean、attribution & rollback、debug、evolve、commit。每轮产生新轨迹,先归因上一轮编辑、回滚被驳回的,再做轨迹蒸馏,再编辑和提交。全程无人值守。
实验结果
主结果:跑赢所有基线
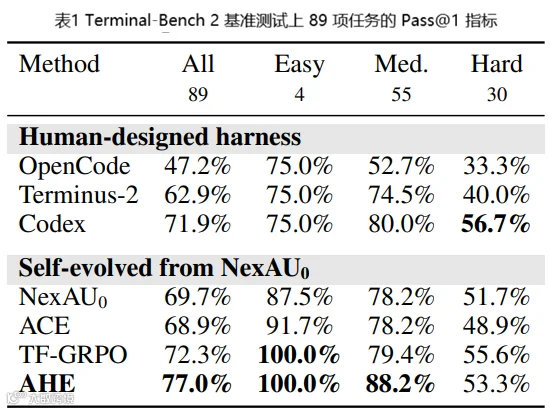
Terminal-Bench 2,89个任务(4 easy / 55 medium / 30 hard),从裸NexAU种子出发。十轮AHE进化,pass@1 从 69.7% 拉到 77.0%。 跑赢了三个手工设计的Harness(OpenCode 47.2%、Terminus-2 62.9%、Codex 71.9%)和两个自进化基线(ACE 68.9%、TF-GRPO 72.3%)。
按难度拆:Easy和Medium满分或接近满分(100% / 88.2%)。唯一的例外是Hard,AHE的 53.3% 略低于Codex的 56.7%。论文追了原因,不是缺能力,是组件间干扰。只把 AHE 的长期记忆单换到种子Harness上,Hard已经超了Codex。全组件堆叠时中等难度的优化权重压过了难任务的配置。
ACE和TF-GRPO的差距来自漏层:ACE蒸馏的是自然语言playbook,TF-GRPO强化的是工具调用序列,两者都只动prompt 层。 工具、中间件、长期记忆这些它们不碰的组件,恰好是AHE最大的gains来源。
迁移:跨基准、跨模型都有效
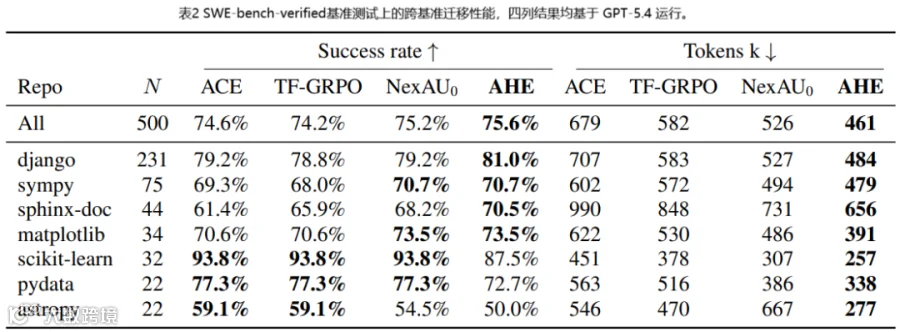
SWE-bench-verified上,AHE的Harness不做任何重新进化直接评估。最高总成功率 75.6%,token消耗比种子少 12%。 ACE和TF-GRPO反而总成功率退到种子以下,token消耗还涨了 11% 到 29%。原因不复杂:它们蒸馏的playbook和trajectory偏好直接贴prompt里,每轮推理都带着,换了任务面就只剩开销没有收益。
跨模型迁移更有说服力。用GPT-5.4 high进化的Harness,不调整直接装到五个不同基础的模型上,全部正向收益。 deepseek-v4-flash +10.1pp,qwen-3.6-plus +6.3pp,gemini-3.1-flash-lite +5.1pp,GPT-5.4同家族 +2.3 到 +7.3pp。跨家族gains大于同家族。 离饱和越远的基座模型,越需要AHE固化在工具、中间件和长期记忆里的协调模式。
组件消融:系统 prompt 是唯一倒退的
把AHE进化的四个组件分别单独换到种子上:
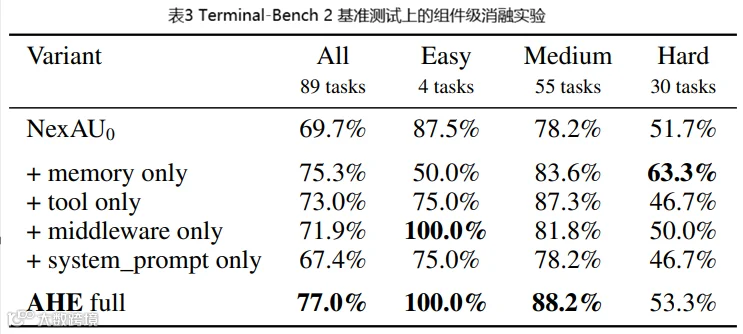
工具、中间件、长期记忆各自单独就超过种子,系统prompt单独用反而倒退。 长期记忆在Hard上单干到 63.3%,甚至超过全量AHE的 53.3%。说明它在难任务上的额外验证步骤,被其他组件叠加后变成了冗余。三个正贡献组件的单独gains加起来是 +11.1pp,全量只有 +7.3pp:组件非加性交互,叠在一起有天花板。
几个值得接着想的问题
evolution operating point的耦合。 AHE的step budget和timeout是按 GPT-5.4 high校的。同家族跨reasoning tier的收益非单调:medium +2.3,high +7.3,xhigh +2.3。一部分gains被timeout吃掉了。换基座模型跑进化需要重新标定操作点。论文把这事记在了limitation里。
组件交互的建模缺位。 三个组件单独都有正收益,叠起来天花板就到了。进化智能体目前是盲叠,不知道哪些组件在对冲、哪些在协同。interaction-aware evolution被论文列future work,是这个方向最值得盯的下一个问题。
回退预测能力缺失是硬伤。 如果进化循环只能看到"修好了什么"而看不到"弄坏了什么",靠更多迭代硬堆 pass@1 的代价就是不可控的质量波动。论文把regression foresight标为"最清晰的发展方向"。一个能预判编辑风险的机制,可能比再多做几轮进化更重要。
最后
AHE和传统的"换个更好的prompt"或者"加强RL"不是同一个思路。它把Harness本身当成一个能持续进化的适应层,编码经验沉淀在工具、中间件和长期记忆这些结构化组件里,而不是锁在prompt的散装文本里。
模型在进步,Harness也应该跟着进步。 Harness的进步可以不依赖同一个人、同一台机器、同一段手动改prompt的流程。
AHE给出的答案是:把Harness做成闭环,让每一轮编辑都对下一轮结果负责。
PS:
最后,做个小小的推荐,目前正在进行的两个项目:
Agent Insight:openEuler孵化的项目,旨在让每一个Agent 都可被观测、可被评估、可自我进化。
Skill Radar:给Agent Skills技术画一张”活地图”,追踪Skills技术,让Agent能力进化有迹可循。
如果你对Agent Insight感兴趣,欢迎参与进来,一起把它变得更好~~
🔗 仓库地址:https://atomgit.com/openeuler/agent-insight
更多Agentic AI技术前沿分享,欢迎扫描下方二维码进入技术交流群(或者添加群助手ID:qstarsky 邀请您进群交流)

往期回顾
往期回顾
从Skill Insight到Agent Insight:一次以Harness为中心的演进
评测挂了?先别判死刑,可能是评测Agent走错了路
Agent评测
相关链接
-
• 论文:https://arxiv.org/pdf/2604.25850 -
• 代码:https://github.com/china-qijizhifeng/agentic-harness-engineering -
• Agent Insight:https://atomgit.com/openeuler/agent-insight