
一、背景
最近大家都在期待 DeepSeek V4 模型的发布,也在推测 DeepSeek V4 模型的结构,比如是否会是 mHC、Engram、DSA 等方案的融合,也许农历新年即可见分晓。本文中,我们也简单梳理一下其他模型结构改进方面的相关工作,重点介绍 NVIDIA 的 LatentMoE 和 Meituan 的 Zero Computation Expert 和 Short-Connection 方案。
相关工作可以参考我们之前的文章:
二、NVIDIA Nemotron-3
2.1 Nemotron-3 模型概览
Nemotron-3 模型包含 3 个模型,Nano、Super 和 Ultra。其模型采用了混合 Mamba-Transformer MoE 结构,如下图为 Nano-30B-A3B 的结构:
大部分 Attention 层是 Mamba-2,部分层穿插传统的 Softmax Attention。
最小的 Nano 采用标准的细粒度 MoE,Super 和 Ultra 采用了 LatentMoE。
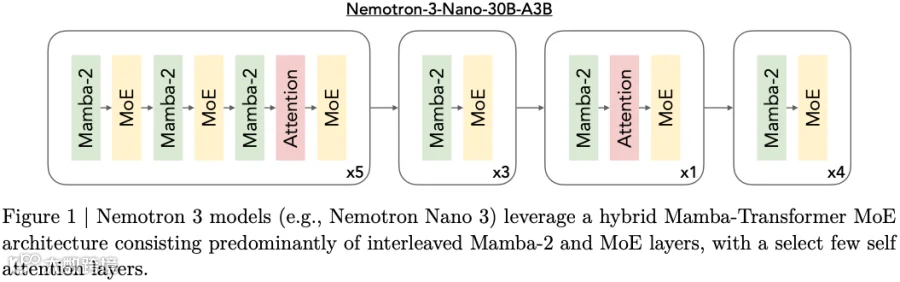
对应的论文为:[2512.20856] NVIDIA Nemotron 3: Efficient and Open Intelligence
2.2 LatentMoE
Transformer 模型在 Inference 部署中通常会有两种场景:
Latency 优先,常见的 Online 场景,通常会导致无法达到足够的 Batch Size,MoE 部分的 Memory Bound 问题非常严重,优化的重点是增加算术强度。
Throughout 优先,常见的 Batch Inference 场景,通常 Batch Size 可以足够大,MoE 部分 Token 分发到专家以及结果聚合的的 All2All 通信可能成为瓶颈,优化的重点是降低通信量。
为了在不损害 Inference 吞吐和时延的前提下提升模型质量,作者采用了 LatentMoE 架构:为提升每字节精度,缩小了路由 Expert 输入维度 d 以降低通信和内存开销,并将节约的算力资源重新投入非线性预算与 Expert 多样性中——通过同步扩展 Expert 数 N 和每 Token 激活的 Top-K Expert 数量实现。
如下图 Figure 3a 所示为标准的 MoE 架构,包含 4 个路由 Expert,每 Token 激活 2 个 Expert。如下图 Figure 3b 为 LatentMoE 架构:
每个 Token Embedding 首先从原始 Hidden 维度 d 投影(down-proj)到更小的隐空间维度 ℓ < d。
然后,对处于该隐空间的扩展 Expert 集中进行路由计算(Expert 的维度从 d x m 变成 ℓ x m,为了利用节省的参数和带宽,将 Expert 数从 N 提升到 N′=N*d/ℓ,每个 Token 激活 Expert 数也从 K 增加到 K′=K·d/ℓ)。
最终,聚合后再重新投影(up-proj)回 Hidden 维度 d。
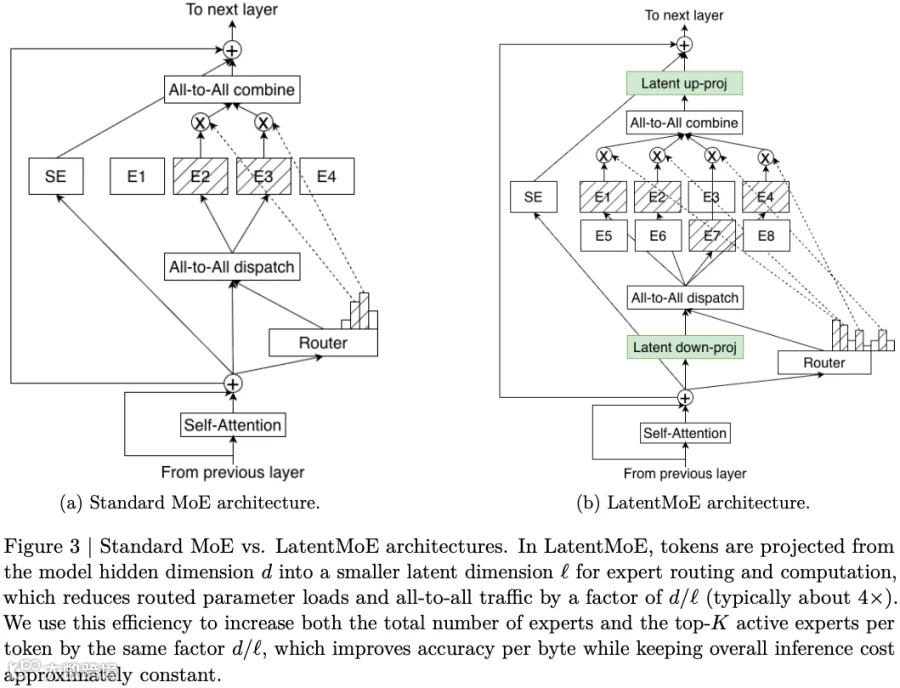
如果只是投影到隐空间,确实可以帮助降低 All2All 通信量,但是 Expert 总容量以及激活 Expert 容量也会相应降低,导致模型表征能力的下降。此时有 3 种改进方式:
只增加激活 Expert 数量:比如 Expert 总量不变,但是激活的 Expert 增加到 K′=K·d/ℓ。
每个 Token 的激活参数量与标准 MoE 模型相当,相应的 All2All 通信量也相当。
MoE 的算术强度明显增加,有利于提升 Inference 性能。
模型总参数量依然明显降低,可能影响模型精度。
只增加总 Expert 数量:比如激活 Expert 数量不变,但是总的 Expert 数量增加到 N′=N*d/ℓ。
与标准 MoE 模型相比, All2All 通信量明显降低。
MoE 的算术强度明显降低,不利于 Inference 性能。
模型总参数量不变,但激活参数量明显降低,依然可能影响模型精度。
同时增加总 Expert 和激活 Expert 数量,K′=K·d/ℓ 和 N′=N*d/ℓ。
总参数量和激活参数量基本不变,但 Expert 粒度更细,组合数更多,效果可能更好。
All2All 通信量基本不变。
MoE 的算术强度基本不变。
除此之外,也可以从 Expert 的另一个维度切分,也就是早期控制 Expert 的数量和粒度的方式,比如同参数量下可以是 64 个 Expert,每个 Token 激活 4 个 Expert;还可以是 256 个 Expert,每个 Token 激活 16 个 Expert。这种方式最大的代价是 All2All 通信量线性增加 4 倍。
综合上述因素,NVIDIA 在 Nemotron-3 中选择了同时增加总 Expert 和激活 Expert 数量,K′=K·d/ℓ 和 N′=N*d/ℓ 的方式。隐空间维度的降低有效抵消了总 Expert 和激活 Expert 增加带来的开销,从而在相近的计算和通信预算下实现更优的模型质量。
PS:在 Nemotron-3 的最小模型 Nano 中并没有采用 LatentMoE,推测是对于一个 W30A3 的 MoE 模型,128 个 Expert,Hidden 维度 2688,Expert 已经足够小,再进一步切分,Expert 过小不太适合 Inference 优化。
2.3 评估
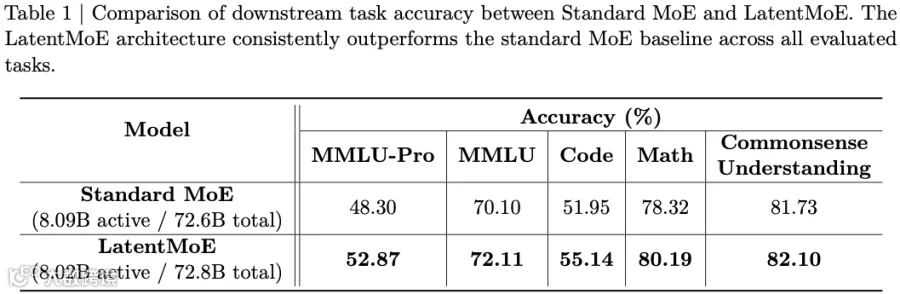
如下图 Table1 对比了标准 MoE 与 LatentMoE 的下游任务性能,其中 Code 项综合了 HumanEval、HumanEval+、MBPP 与 MBPP+ 的平均值;Math 项综合了 GSM8K CoT 与 MATH-500 的平均值;Commonsense Understanding 综合了 RACE、ARC-Challenge、HellaSwag 与 Winogrande 的平均值。两个模型都是 8B 左右激活参数,73B 左右总参数量,并使用相同的超参在 1T Token 上训练。实验结果表明,LatentMoE 在所有评估任务中均优于标准 MoE 基线模型。其中:
Standard MoE:Hidden 维度 d=4096,128 个总专家,激活 6 个。
LatentMoE:隐空间维度 ℓ=1024,512 个总专家,激活 22 个。
三、Meituan LongCat-Flash
3.1 LongCat 模型概览
Meituan 的 LongCat 大模型也做了很多架构上的修改,比如引入了 Zero-Expert、Shortcut、模型增长、Two Chunk MoE 等,除此之外也在 Attention 部分使用了 MLA。这些新技术的引进也确保了 LongCat 模型极快的生成速度。
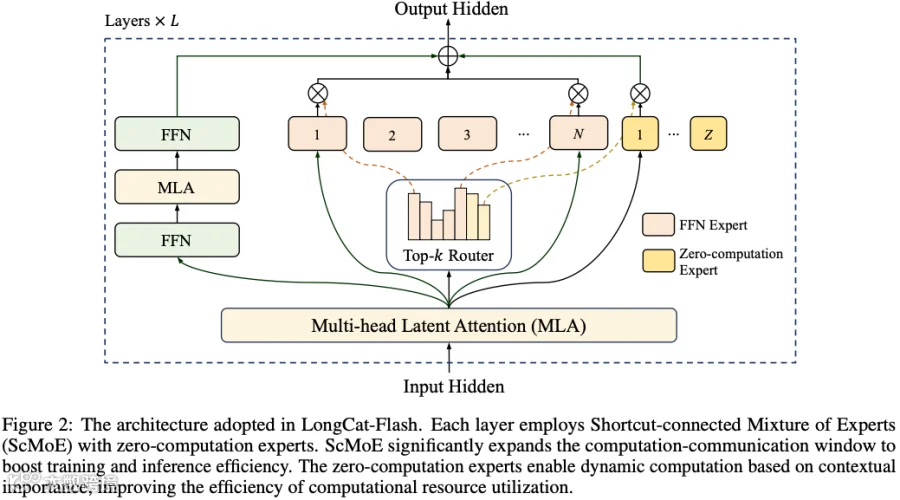
对应的论文为:[2509.01322] LongCat-Flash Technical Report。
3.2 Zero Computation Expert
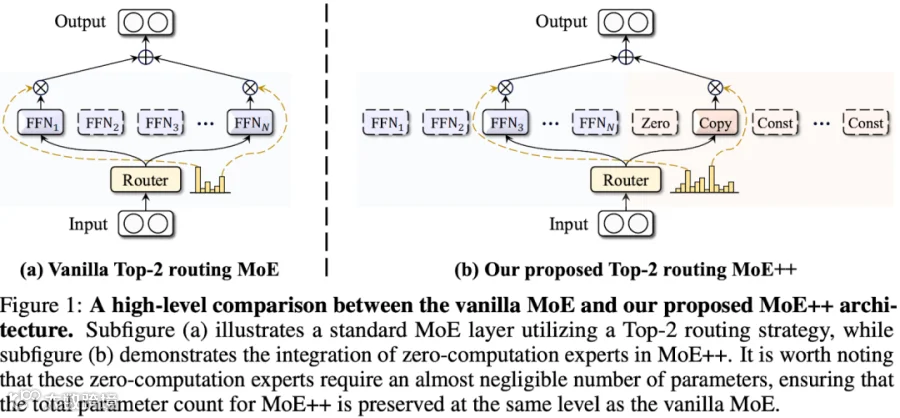
出自论文 [2410.07348] MoE++: Accelerating Mixture-of-Experts Methods with Zero-Computation Experts,如下图 Figure 1 所示,传统的 MoE 方法通常对所有 Token 激活固定数量的 Expert(例如 Top-2 FFN)。然而,实际上 Token 的难度是不一样的:
简单 Token(如标点符号)可能不需要复杂的计算。
困难 Token 可能需要更多的计算资源。
不匹配的 Token 可能完全不需要当前的 MoE 层处理。
传统的“一刀切”不仅造成计算浪费,还限制了模型性能。为此,MoE++ 中作者引入了异构 Expert 系统,设计了 3 种零计算专家,它们的参数量极小,几乎不会消耗计算资源:
Zero Expert (丢弃):输出全 0 向量。相当于丢弃该层输入。
Copy Expert (跳过):输出等于输入(恒等映射)。相当于 Residual Connection,允许 Token 跳过当前层。
Constant Expert (替换):用一个可学习的向量替换输入。允许用极小的代价对 Token 进行简单调整。
如下图所示,在 LongCat 中 Zero Expert 的效果似乎不是非常明显,其理论激活参数量为 18.6B - 31.3B,而实际平均每个 Token 要激活 27B,只减少了 10% 左右:

PS:Zero Expert 除了可以减少计算资源外也可以减少 All2All 通信开销。
3.3 Shortcut-connected Expert Parallelism
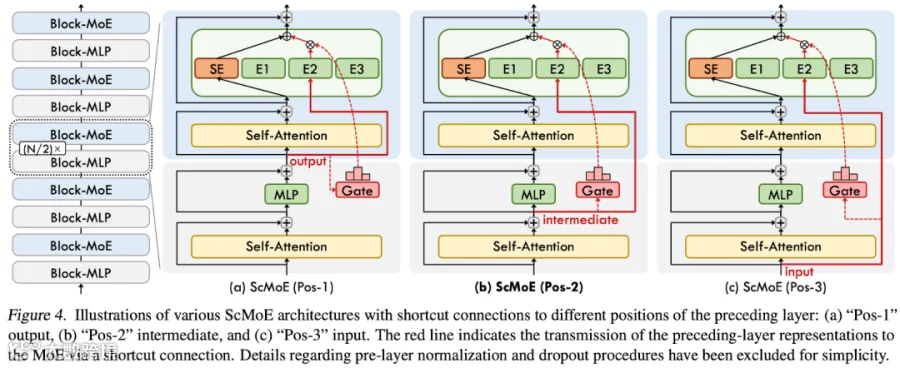
出自论文 [2404.05019] Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts,如下图 Figure 4 所示,ScMoE 的核心思想是通过 Shortcut Connection 解耦通信和计算的依赖关系。其包含两个流:
Shared Expert 流:处理 当前层的输入,由一个共享的 MLP(Shared Expert)处理。这部分是纯计算,不涉及跨卡通信。
MoE 流:处理上一层的输入(通过 Shortcut 获取)。使用 Gating 路由到远程 Expert。这部分涉及 All2All 通信。
合并:两个流的结果最后相加,作为当前层的输出。
All2All 通信 Overlap:这样做的好处是 MoE 流的 All2All 通信可以与 Shared Expert 流的计算完全并行执行。
如下图 Figure 9 所示,由于这种特殊的结构,LongCat 的 Inference 阶段在 Single Batch 中即可以实现 All2All 通信的 Overlap,规避了 Two Batch Overlap 方案的复杂性以及 MoE 算术强度降低的问题:
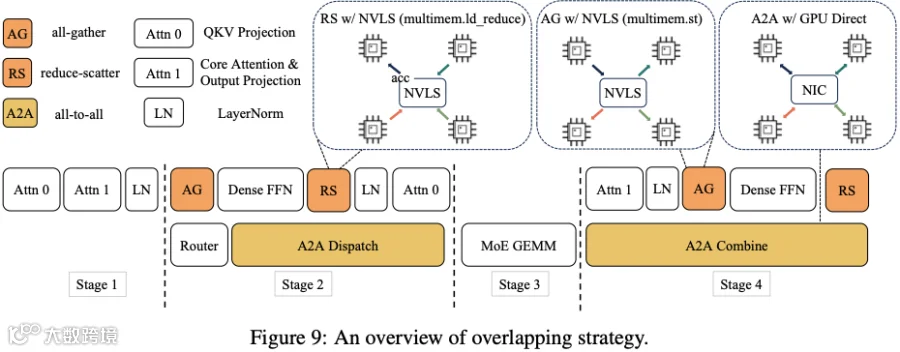
PS:这种方式也可能是因为其预训练的后向网络带宽比较低,只有 200Gbps,相应的通信瓶颈比较明显,Shortcut Connection 的方式可以尽可能规避其影响。
3.4 评估
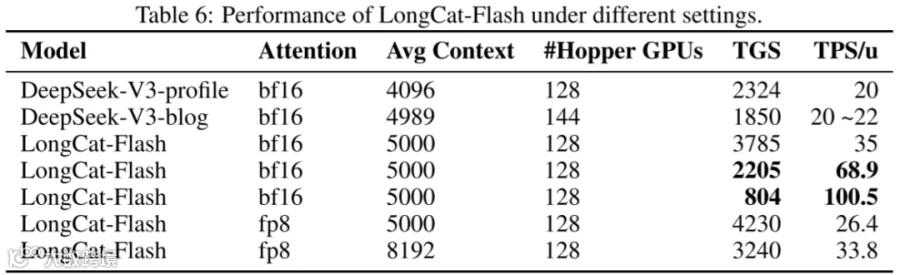
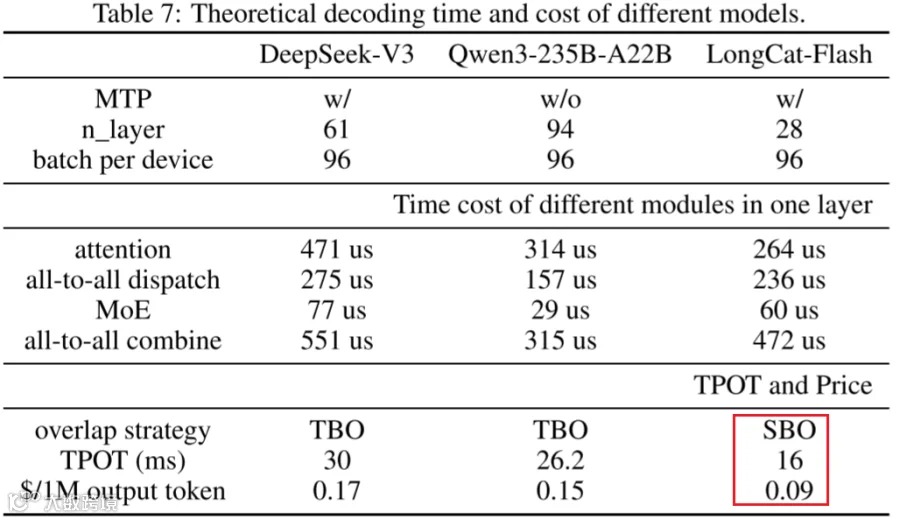
如下图 Table 6 和 Table 7 所示,可以看出 LongCat-Flash 在 Inference 性能方面具有比较明显的优势:
四、参考链接
https://arxiv.org/abs/2512.20856
https://arxiv.org/abs/2509.01322
https://arxiv.org/abs/2410.07348
https://arxiv.org/abs/2404.05019