
一、引言
之前的文章中介绍了字节的大规模 LLM 训练管理系统 ByteRobust 以及 Meta 针对 10 万 GPU 超大规模场景的 FT-HSDP,也借机回顾了笔者之前介绍过的大规模 AI 集群中的常见问题和运维实践。本文继续介绍阿里的 Aegis 故障诊断系统,相对而言,ByteRobust 和 FT-HSDP 主要针对的是内部少量大规模的训练场景,非常适合定制化、侵入性的优化;而 Aegis 可以实现轻量化、低侵入,非常适合拥有大量不同用户的公有云场景。
对应的论文:Evolution of Aegis: Fault Diagnosis for AI Model Training Service in Production | USENIX [1]
相关工作可以参考笔者之前的文章:
二、摘要
传统云计算和 AI 模型训练在计算范式上存在显著差异,导致传统的诊断系统并不适用于精准定位 AI 模型训练云场景中的故障。为此,阿里云推出专为 AI 模型训练设计的故障诊断系统 Aegis,并分享了该系统的研发动机、架构设计及迭代演进过程中的实践经验。
Aegis 以易部署性为核心原则。第一阶段,增强现有已有诊断系统;经过数月迭代演进,第二阶段定制了集合通信库,无需修改用户代码即可在运行时精细化定位故障。除故障定位外,还进一步支持性能退化处理与交付前故障检测能力。
Aegis 在作者生产环境的训练云服务中部署运行一年。实践表明,可以将诊断过程造成的闲置时间减少 97% 以上,训练任务重启次数降低 84%,性能退化现象减少 71%。
三、背景
3.1 模型训练引入的挑战
如下图 Figure 1 所示,作者分析了生产环境中最大训练集群(包含 O(1K) 节点 & O(10K) GPU)在过去十周的故障修复工单。该训练集群每周发生 100-230 次关键故障,其频率显著高于常规云计算数据中心。
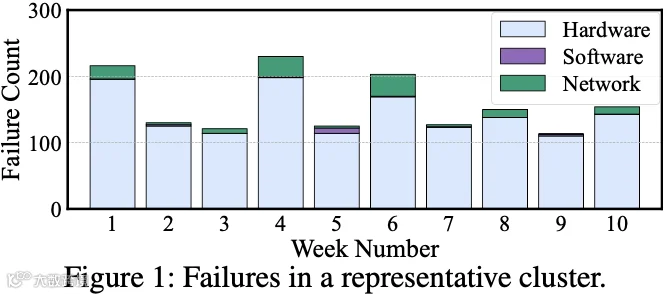
GPU 故障率高:高端 GPU(如 A100 & H100)的故障率远超传统计算硬件。统计数据显示,A100 的平均故障时间在 400 天左右,而 H100 的平均故障间隔时间更短,只有 200 天左右。如下图 Figure 2 所示,在数千卡的训练中,45.6% 的故障源于 GPU 相关因素(包括 GPU execution error、GPU driver error、GPU memory error、CUDA error、NVLink error 及 GPU ECC error)。
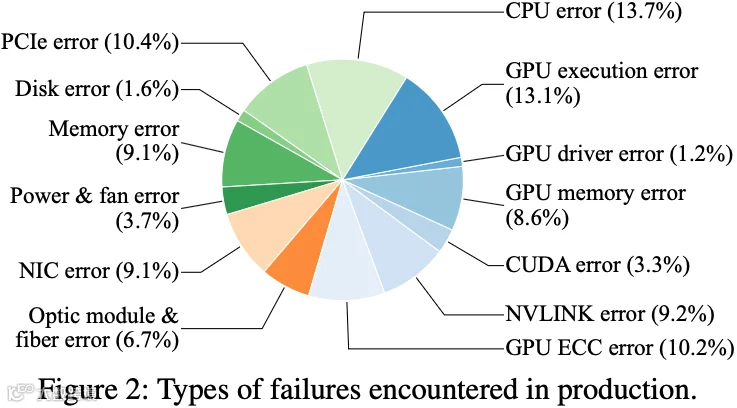
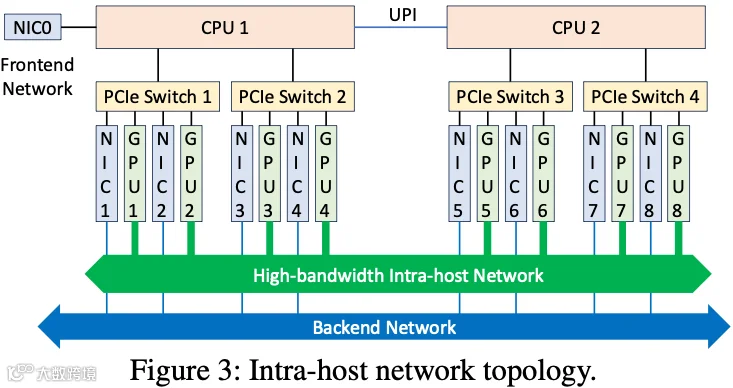
复杂的机内网络拓扑结构:如下图 Figure 3 所示,作者训练集群中的每个节点 8 个 GPU、8 个 NIC,通过 PCIe 实现互联。同一节点内的 GPU 还利用 NVLink + NVSwitch 进行 GPU 间通信,虽然提升了性能,但也引入了更复杂的转发路径和更高的故障率。作者的运维经验显示,9.2% 的问题与 NVLink 故障有关,另有 10.4% 的性能异常由 PCIe error 导致。
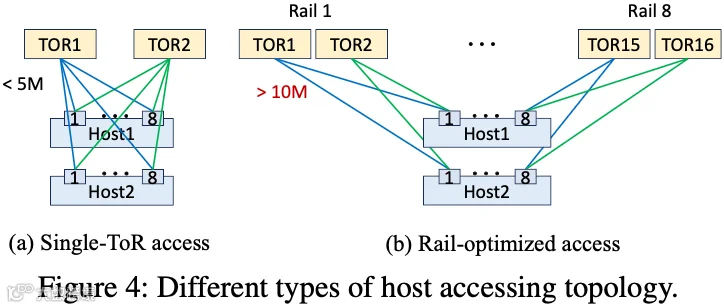
大规模模型训练集群中更多链路故障:为充分利用机内网络提供的高带宽,AI 训练集群构建时通常会采用轨道优化网络。如下图 Figure 4 所示,相较于单 ToR 拓扑,轨道优链路距离更长,通常需要使用光模块和光纤来克服铜缆的距离限制。然而,光模块和光纤故障率比较高。作者生产统计数据显示,光模块和光纤的故障率比 DAC 高出 1.2x∼10x,具体数值因供应商和链路速率而异。此外,阿里在 Alibaba HPN: A Data Center Network for Large Language Model Training [2] 中提出 双上联、双平面架构,当双 ToR 链路中的一条发生故障时,整个训练任务可能不会崩溃,但可能遭遇严重的性能下降。
同步训练故障传播:在传统的通用云计算场景中,故障通常仅影响若干特定节点,且存在明确的故障定位指标(例如,特定五元组连接出现较高的 RPC 完成时延)。相比之下,由于 AI 模型训练广泛采用同步训练模式,模型训练中的故障会从单点(如节点或链路)扩散到整个集群,导致根本原因非常隐蔽,可能难以快速定位。比如链路异常时,可能多数节点同时出现 NCCL Timeout 错误。
3.2 当前系统的局限性
传统云计算网络诊断体系通过被动监控、主动探测与逐跳分析的组合,在通用云计算场景下能够高效定位网络故障:
网络监控与分析系统:能够自动识别故障节点并执行隔离操作。
RDMA Pingmesh:能够主动探测网络状态,诊断连接性异常与高延迟问题。
带内网络诊断系统:能够追踪数据包在每台交换机中的转发状态。
但其通常以单路径、单请求为中心的设计假设,难以应对模型训练中高度耦合、级联放大的故障特性,从而在训练生产环境中产生大量误报并缺乏自动化根因定位能力。
现有的训练专用系统要么依赖耗时离线测试、要么对客户代码高度侵入,无法满足云计算场景同时要求在线性、低侵入性、可扩展性与训练语义感知能力的要求。
基于离线基准测试的诊断(如 SuperBench: Improving Cloud AI Infrastructure Reliability with Proactive Validation [3]):
主要方案:构建综合测试组件,比如计算、通信、端到端训练的基准测试,集群上线前之前,发现潜在问题。
主要问题:只能覆盖上线前阶段,事后诊断代价过高,资源浪费严重。
基于运行时代码监控的诊断(如 [2402.15627] MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs [4]):
主要方案:完全基于运行时,通过监控“关键代码段”中的 CUDA Event 执行情况进行诊断。
主要问题:只适用于自研模型、自用集群这种可以对训练代码进行修改、侵入的场景。
四、Aegis 方案
4.1 方案概览
Aegis 的核心目标:在不修改用户代码的前提下,诊断服务运行时故障的根源。需注意的是,在生产环境中,当故障发生时最紧迫的任务是及时定位引发此故障或性能下降的具体设备。随后,可以隔离该设备并继续训练流程([2509.16293] Robust LLM Training Infrastructure at ByteDance [6]:快速隔离 > 精确定位)。根本原因分析将在设备隔离后离线进行,Aegis 中暂未涉及。
如下图 Figure 6 展示了 Aegis 的系统概览。Aegis 主要聚焦两类异常:
针对训练故障,Aegis 经历了两个阶段的演进:
第一阶段,整合训练日志中的错误信息,构建了面向训练场景的运行时诊断流程;同时,针对运行时诊断无法处理的复杂案例,设计了全面的离线诊断保障机制。
在实际运行中发现,有相当数量的故障案例需依赖离线诊断,导致 GPU 利用率未达预期。因此,推进 Aegis 第二阶段:通过定制 CCL 来获取更丰富的训练场景信息,实现训练流程感知诊断。
针对性能下降,基于先前经验,同步设计了指标关联诊断与增强型流程感知退化诊断。为持续优化用户体验,新增了“Pre-online”流程,在集群交付用户前执行高效的健康状态检查。
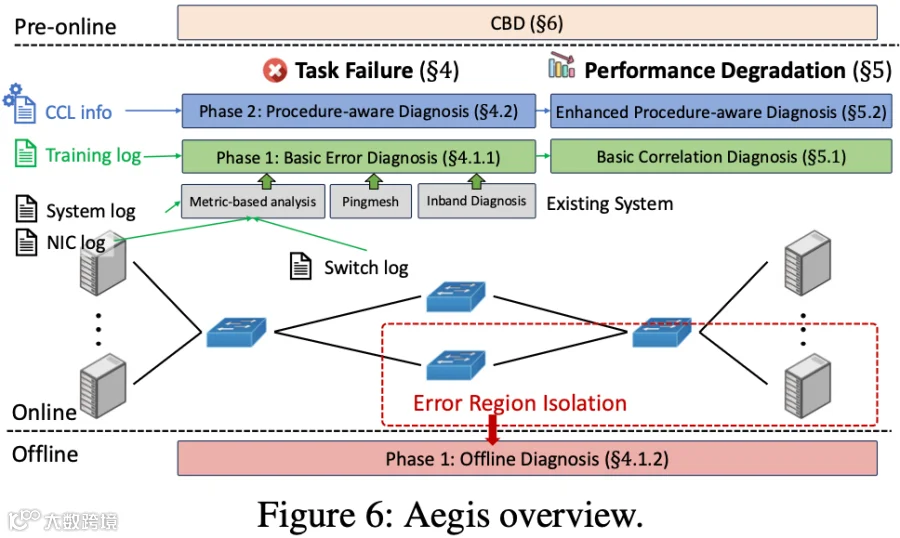
4.2 任务异常诊断
4.2.1 阶段一:增强传统诊断系统
4.2.1.1 基础错误诊断
首先是完善诊断指标,判定当前问题源自是主机还是网络。
收集多种数据源(dmesg、训练日志、CCL 日志、NIC 和 Switch 日志以及定制计数器),筛选各节点和交换机的 Error 和 Warning 日志,分析异常报告与实际故障之间的时序关联性。总结出了一系列关键错误类型,并据此构建了初始的自动化任务故障诊断系统。
训练中 Error 日志很多,但并非所有 Error 必然导致任务失败或性能衰减,比如 XID 48/94/95 会直接引发故障,而 XID 92/63/64 仅提示 HBM 异常,并不触发故障。为此,作者直接聚焦于会导致任务故障的关键错误,检测到此类问题直接隔离对应节点。对应 CriticalError():
硬件故障:双比特 ECC Error、链路中断、GPU/NVLink/NIC 设备丢失、风扇异常、电源故障等。
不可恢复的软件故障:GPU/NIC 驱动错误等。
无法容忍的性能恶化:GPU 过热/降频、节点过热等。
并非所有关键错误都能指向明确的位置,还有许多错误并不指向特定节点。一个广泛存在的问题是网络连接异常(比如 connection reset by peer)。这里故障会触发 NCCL 错误处理,导致训练线程退出。为此,作者还构建了一个分布式错误列表来记录这些错误:DistError()。
基于以上经验,改进了故障诊断流程,具体如下图 Algorithm 1 所示:
若某个节点遇到 CriticalError(),直接隔离并重启任务。
若 DistError() 仅出现在 2 个节点,隔离这 2 个节点并重启任务。
若 DistError() 仅出现在超过 2 个节点,RootDiag() 会分析上报错误信息,以判断是否能按源地址或目标地址进行聚类。
若 GPU Gj 是故障的根本原因,则从 Gj 发出的连接和指向 Gj 的连接会首先崩溃。因此 RootDiag() 可精准定位故障 Gj。
若错误分布无明显规律,则很可能存在系统性问题,例如网络或配置故障。为此开发了 ConfigCheck() 和 NetDiag() 以进行深度诊断。
ConfigCheck() 通过维护检查清单及对应脚本来识别各类配置错误。
NetDiag() 基于现有 DCN 诊断系统构建。
若上述流程仍无法定位故障根源,则需隔离本次训练任务涉及的所有节点并进行离线诊断。

经验总结:优先排查节点侧关键故障是最高效的诊断路径。在大规模模型训练中,节点侧问题易被误判为网络故障。实践数据显示,71% 的分布式故障实际与网络无关。
4.2.1.2 离线故障诊断
在完成全部诊断流程后,部分问题仍无法通过现有运行时信息直接判定,为此设计了一套离线故障定位机制。该机制对当前训练任务中使用的所有可疑节点进行隔离诊断,在确保每个节点无异常后,该节点将立即恢复在线服务。
并行化离线故障定位:为加速离线定位,设计了并行化方案以最大化效率。在离线定位过程中,所有节点需完成包括 CPU、GPU、PCIe 及 NVLink 压力测试在内的一系列自检流程。此阶段完全并行化,若单机自检发现问题,将被标记为故障状态;若单节点测试未检测到异常,则需进一步执行多节点故障诊断。
多主机故障诊断:选取与 SuperBench 相似的典型模型,同时纳入更多新的典型模型(如 MoE 模型与多模态模型)。随后将集群划分为若干子集,在不同子集上独立训练参考模型,最终精确定位故障节点。当确认集群的某个子集运行正常后,这些节点将立即释放回资源池,从而最大限度减少资源浪费。
拓扑感知的并行定位:在并行定位过程中,不同子集的划分至关重要。由于网络在不同节点间共享,若不加区分地分割节点,可能导致并行训练任务争用相同的网络链路。为此,节点并非均匀划分至不同子集,而是依据节点在物理网络拓扑中的位置将其划分为两个子集,分别统计不同 Pod 与 ToR 组,由此,在并行诊断期间,不同诊断任务产生的流量不会在网络中相互干扰。
4.2.2 阶段二:流程感知诊断
通过上述诊断系统可以在故障定位方面取得显著改进,但仍然有许多需要触发离线诊断才能最终确定根本原因。全在线诊断的主要难点在于缺乏精确信息。因此,需增强在线任务监控能力以提供更具价值的运行时信息。须考虑若干实际约束条件:
高置信度:进行精确定位需要详细输出数据,且由于不同案例的根源各异,诊断所需数据也存在差异,因此选择合适指标以实现高置信度诊断至关重要。
最小化客户修改:作为模型训练云服务提供商,在生产环境中对客户代码或训练框架进行大规模修改并不可行。理想解决方案应对客户完全透明。
低开销:新增信息采集与处理流程应引入最小化开销,以避免影响主体训练任务。
经综合考量,作者对 CCL 进行了定制:
首先,在主流训练框架(如 Megatron 和 DeepSpeed)中,集合通信是模块化组件,可独立替换。通过替换 CCL,能够在无需修改用户模型代码的前提下收集定制化诊断信息。
此外,集合通信位于计算与通信的边界。可提供精确运行时信息,能够清晰反映节点侧处理时间(计算)与网络侧处理时间(通信),这些信息对于故障设备的定位至关重要。
信息收集:在训练过程中,定制的 CCL 会记录每个 GPU(Gj)中每个通信算子(Ci)的若干统计指标:
集合通信启动次数(CLi,j)记录 Gj 启动 Ci 的次数。
工作发起次数(WRi,j)记录 Gj 在 Ci 中发起的工作请求数量。
工作完成次数(WCi,j)记录 Gj 在 Ci 中完成的工作请求数量。
如下图 Figure 7a 所示,所有 GPU 以同步方式交替执行计算与集合通信。正常情况下,不同 Gj 的 CLi,j 会在每次迭代中保持同步增长。
场景一:计算故障。若计算阶段发生故障,如下图 Figure 7b 所示,Gn(这里 n=2)将无法启动后续 Ci(这里 i=1)。将导致同一集合通信中的所有其他工作进程在 Ci 处停滞,并因 CCL Timeout 而崩溃。此时,同组内 CLi,n < CLi, j ≠n,由此可判定 Gn 为故障根源。
场景二:通信故障。若故障发生在通信阶段,则 Ci 中特定工作请求的传输将失败,导致该组所有 GPU 遭遇 CCL Timeout(如下图 Figure 7c 所示)。更详细的统计量 WRi, j 与 WCi, j 用于进一步诊断:正常 GPU 中 WRi, j = WCi, j。若 WRi,n < WCi,n(这里 n=1),则表明 Gn 与故障根源相关。将进一步对涉及异常工作请求的所有源地址与目标地址执行 NetDiag() 诊断。
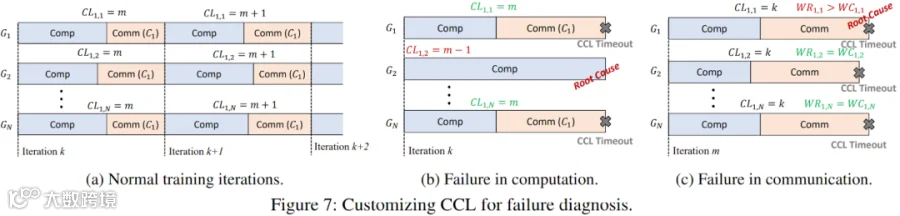
局限性:需要保证:(1) 诊断系统能够无缝部署到不同镜像和模型训练任务中;(2) 在不同环境部署的解决方案应输出相同的诊断信息,以实现稳定的诊断性能。因此,需要基于所有 CCL 发布版本提供相应的定制化版本。
4.3 性能退化诊断
除了训练任务完全失败的情况外,某些设备异常虽不会导致整个训练崩溃,却可能引发显著的性能下降。
4.3.1 基础关联诊断
关键指标选择:多数性能下降由单一设备异常引发,可通过两类指标进行识别:
异常运行指标:旨在直接反映特定组件是否处于异常运行状态。例如,数据包重传率指标表示每秒重传的数据包数量。正常情况下该指标应始终为 0,而较高的重传率则表明网络存在异常行为。
性能指标:用于反映特定组件的执行效率。单个组件的异常将导致整体性能下降,例如,实际 Tensor-FLOPS 指标表示每秒完成的 Tensor 浮点计算数量。
为此,选取了 20 多项指标,包括:
异常值分析器:单纯使用静态阈值难以适应多样化的训练场景,若仅为每个独立指标设置阈值,将导致大量误判。考虑到少量节点异常会导致整体性能下降,而性能下降通常伴随某些指标的异常变化,这些异常可指示根本原因。因此,设计了一种基于 Z-Score 的异常值分析器(Z-Score: Meaning and Formula [5]),适用于不同指标。针对每个选定指标,异常值分析器计算时间段 T 内的平均值 λ 与标准差 δ。若单个节点的指标值持续 T 时间高于 λ+2δ 阈值,则该节点被判定为异常节点。生产环境中 T 设定为十分钟。实践中,异常节点产生的数值通常与其他节点存在显著差异,使得 λ+2δ 成为生产环境中既简洁又有效的诊断阈值。
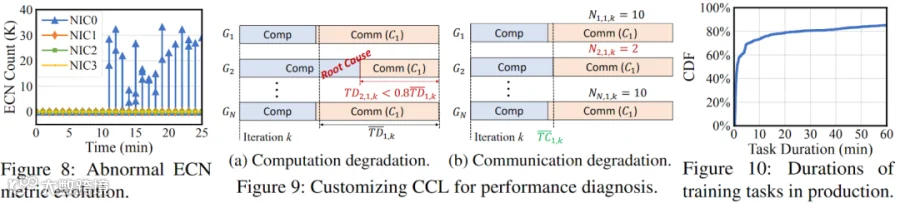
案例研究:使用一个生产环境中的案例进一步说明跨节点关联诊断的运行机制。在一个大型 LLM 预训练中,如下图 Figure 8 所示,某 NIC 的 ECN 统计值从零激增至每秒 10-30 K。与此同时,模型训练团队报告训练迭代时间增加了 26%。由于该异常 NIC 的 ECN 指标已超过 λ+2δ 阈值,关联诊断机制立即识别出这一异常状况。根本原因在于连接该 NIC 的某条链路存在静默丢包现象,导致所有流量通过另一条链路转发至该 NIC,从而在最后一跳引发网络拥塞,最终拖慢整个训练迭代过程。隔离包含异常 NIC 的节点并重启训练任务后,训练性能恢复正常。
局限性:该关联诊断方法适用于部分节点出现显著异常指标导致的性能下降场景。然而实际情况并非总是如此。当性能下降发生时,时常出现所有节点的多项指标同时变化的情况,此时难以准确定位根本原因。因此需要获取更多信息并设计新机制来解决这类复杂案例。
4.3.2 过程感知诊断增强
通过定制 CCL 可以获取更多辅助退化诊断的信息。作者在每次迭代 Ik 中为每个 GPU(Gj)的每个集合算子(Ci)额外记录以下统计量:
Ik 中 Ci 在 Gj 上的持续时间为 TDi,j,k。
Ik 中 Ci 的平均持续时间为 TDi,k。
Ik 中 Ci 在 Gj 上最近 L(实践中 L=5)次工作请求的网络吞吐量为 Ni,j,k。
Ik 中 Ci 的平均网络吞吐量为 Ni,k。
如上图 Figure 9a 展示了计算退化场景,其中异常延长的计算时间是性能退化的根源。由于每个集合操作的末端均保持同步,可以利用通信时长反推计算时间。若 TDi,j,k < α*TDi,k(实践中 α=0.8),则 Gj 是计算退化的根本原因。
如上图 Figure 9b 展示了通信退化场景,其中通信时长异常是性能退化的主因。若 Ni,j,k > β*Ni,k(实践中 β=1.5),则判定存在通信退化。此处采用松弛阈值以抵抗可能由临时网络拥塞引起的噪声干扰。
基于这些信息可以筛选出直接遭受退化的 GPU 集合 G,该集合将进一步用于确定通信退化的根源节点(源端或目的端)。
4.4 交付前的问题解决
通过对所有失败任务的运行时长进行分析,可以看出,如上图 Figure 10 所示,73% 的任务在前 10 分钟内失败,表明许多任务在初始化过程中就已失败(通常初始化阶段需要 5-10 分钟)。
通过分析初始化阶段发生的所有失败案例,发现主要有两方面原因:
频繁的组件更新:训练框架、CCL、容器网络、网卡驱动及交换机等组件更新频繁。为维持整体服务稳定,作者未采用高频的更新策略。
关键更新(含漏洞修复与安全加固)合并后按周发布。
其他更新按月发布。
即便如此,更新仍会引发生产环境中的大量故障。
使用后故障:若节点在上次使用后出现故障,将在新训练任务的初始化阶段触发失败。这一问题在云环境中尤为棘手:
节点是从共享资源池动态分配,使得故障复现极为困难。
此外,一旦节点交付给客户,云服务商无法随意对其进行诊断检测,进一步增加了问题排查的难度。
为解决上述问题,引入了交付前检查(CBD)流程,在资源正式交付给客户前执行,具有两大核心优势。
首先,此检查流程被置于资源交付的最终环节,因此不会干扰现有工作流。
其次,通过在完整环境部署后进行验证,能发现更多潜在问题。例如,在物理主机上执行的连通性测试会遗漏容器网络中因路由配置错误导致的连接故障,这类问题仅在容器完全创建后才能被检测到。
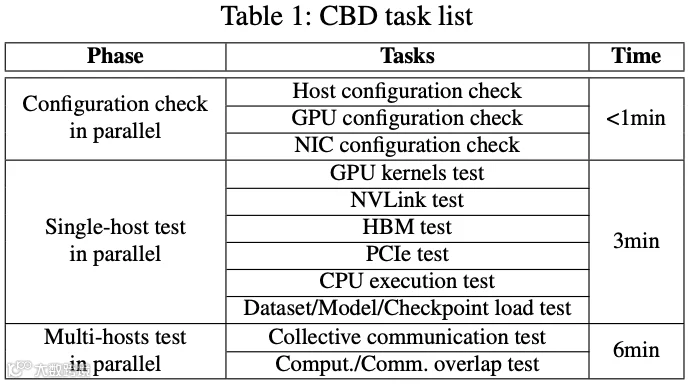
CBD 也存在一个局限性:由于 CBD 需在环境完全就绪后启动,必须处于交付流程的末段,也意味着 CBD 必须保持高效运行以避免影响用户体验。综合考虑这些因素,设计了一套 CBD 操作方案,如下图 Table 1 所示。CBD 完整执行时长控制在 10 分钟以内。若 CBD 过程中出现大规模设备故障(达到设定阈值),系统将自动回滚近期更新以防止服务中断扩散。
随着 CBD 的部署,在最终交付前拦截了 1%-2% 的问题节点。若未能及时检测到这些异常节点,将直接导致训练任务失败。鉴于其显著效益,已将 CBD 列为交付流程中的强制性环节。
五、生产环境评估:Aegis 系统实践
Aegis 系统的首个版本于 2023 年 9 月上线,随即成为后续所有训练服务交付中最核心的基础组件之一。该系统为数十个大规模训练集群提供超过一年的服务。
5.1 训练稳定性演进
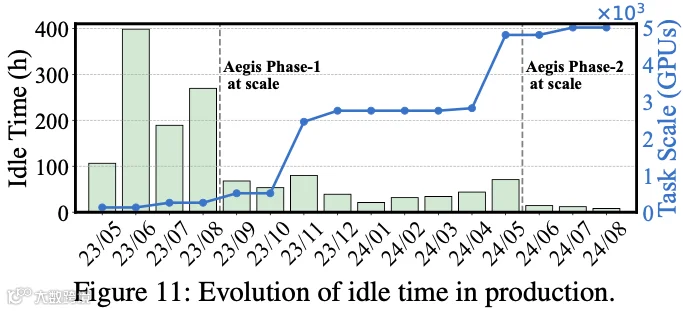
如下图 Figure 11 所示,折线记录了内部模型训练团队承担的训练任务规模——在过去 16 个月内增长超过 40 倍。柱状图表示因故障诊断等待导致的月度累计训练任务闲置时间。
Aegis 第一阶段上线后,次月训练集群闲置时间(集群无任务运行的持续时间)降低 71%。2023 年 11 月出现的闲置时间上升,源于训练规模激增 4 倍所引发的若干意外边界案例问题,这些问题消耗了大量诊断时间并影响闲置指标。
2024 年 6 月部署 Aegis 第二阶段,直接促成训练闲置时间减少 91%,这主要得益于更多故障无需离线诊断即可自主解决。
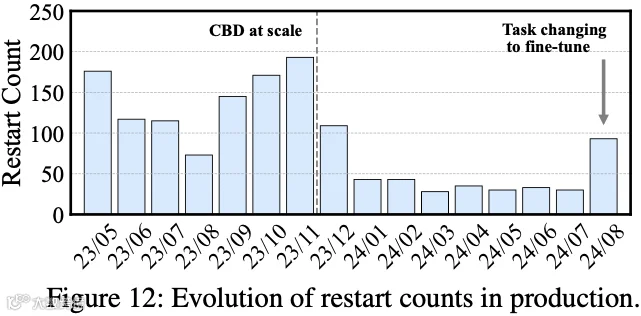
如下图 Figure 12 展示了训练任务的重启次数统计:
2023 年 11 月训练任务规模的扩大同时引发了更多训练重启现象,并在初始化阶段出现大量故障。为此,加速推进 CBD 系统的开发,并于 2023 年 12 月将其投入线上服务。此举使次月重启次数降低 44.8%。通过持续处理更多案例并优化检查清单,最终使重启次数减少 84.6%。
需注意的是,2024 年 8 月重启次数出现上升,其原因是模型训练团队将任务从预训练切换至微调阶段,引入了计划内的实验与测试环节。
5.2 运行时故障诊断
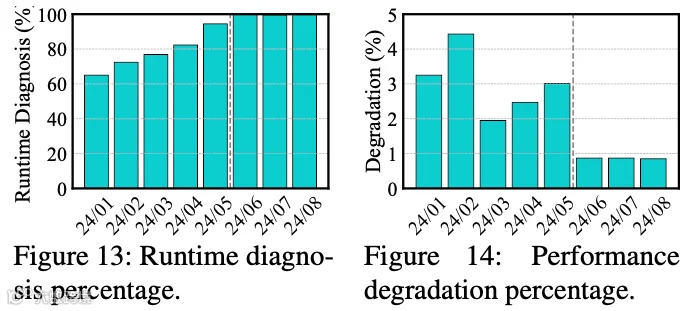
如下图 Figure 13 所示,展示了运行时(而非离线状态下)被诊断出的故障案例数量。随着 Aegis 系统第二阶段的部署,运行时诊断比例逐渐趋近 100%。意味着训练任务几乎都能从所有类型的故障中自动恢复,无需人工干预。
5.3 性能退化处理
为量化 Aegis 系统性能退化诊断的效能,作者与模型训练团队深度协作,获取了所有训练任务的迭代时间记录。如下图 Figure 14 所示,Aegis 系统的性能退化诊断功能于 2024 年 6 月部署,该功能将性能退化现象显著降低了 71%。
六、参考链接
https://www.usenix.org/conference/nsdi25/presentation/dong
https://ennanzhai.github.io/pub/sigcomm24-hpn.pdf
https://www.usenix.org/system/files/atc24-xiong.pdf
https://arxiv.org/abs/2402.15627
https://www.investopedia.com/terms/z/zscore.asp
https://arxiv.org/abs/2509.16293