
Blackwell 架构
-
Blackwell 产品均采用双倍光刻极限尺寸的裸片,将两颗芯片通过 10TB/s 的片间互联技术连接成一块统一的 GPU。 -
第二代Transformer引擎将定制的第5代Blackwell Tensor Core技术,可实现混合精度计算,动态调整算力,并且与TensorRT-LLM 和 NeMo框架的创新结合,加速LLM和MoE的推理和训练。Blackwell Ultra Tensor Core可实现 2 倍的注意力层加速和1.5倍的 AI 计算FLOPS。 -
GPU间通信采用NVLink,单个NVLink支持1.8TB/s带宽,NVLink 交换机芯片可在一个有 72 个 GPU 的 NVLink 域 (NVL72) 中实现 130TB/s 的 GPU 带宽,并通过SHARP技术对 FP8 支持实现4倍于原来的带宽效率。 -
一种新的数据表述格式Microscaling Precision。


Jetson Thor芯片

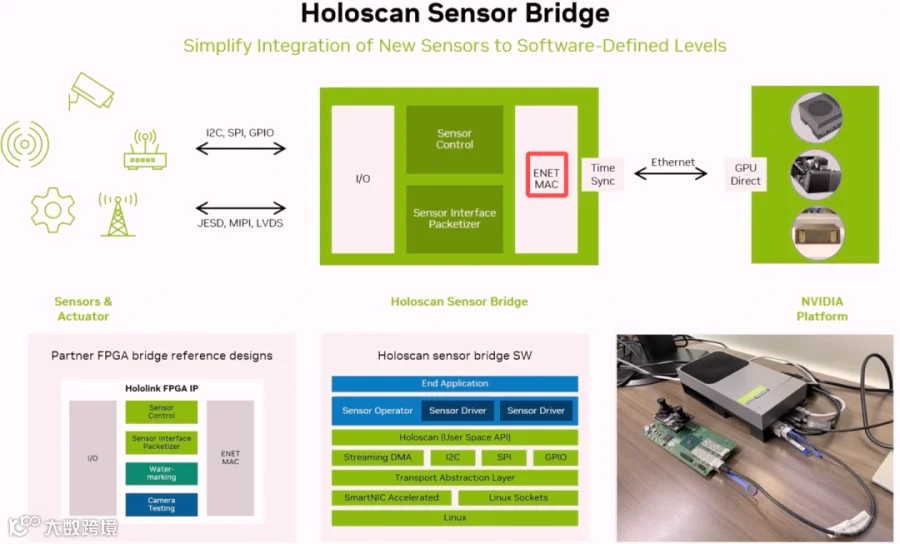
对无人车、机器人这类场景,实时推理的一个关键挑战是传感器数据从CPU拷贝到GPU的过程存在大量延时。为此,Thor设计了Holoscan高保真传感器桥接器,提供一种低延时的实现方式,将传感器数据导入GPU显存。有上图可以看出,Holoscan技术是在FPGA上运行UDP协议,通过网口对接各种型号的GPU算力单元,不需要CPU参与,从而节省一次CPU数据拷贝。由于使用ETH接口,扩展性很好,后端可以接入各种计算单元。nvidia官方公布的数据,对于USB的camera,有5倍的性能提升。
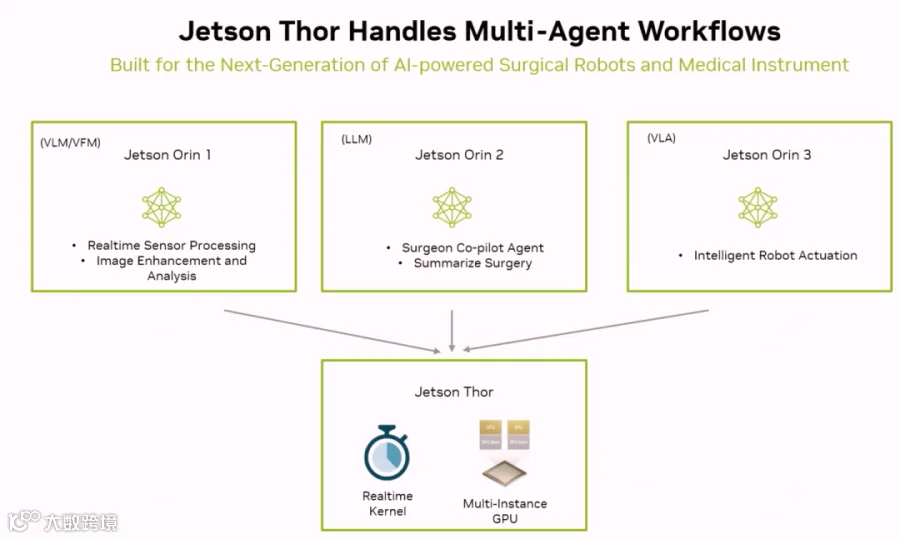
Jetson Thor 支持 MIG(Multi-Instance GPU),可把一颗 GPU 切分成多个相互隔离的实例,像多块小 GPU一样并行运行。这样能同时跑不同 AI 模型/Agent(如 VLM 感知、LLM 助手、VLA 控制),在同一设备上实现低延迟的多任务协作。
Jetson AI Lab是Jetson 上做生成式 AI/机器人推理的教程 + 现成容器 + 社区工程集合站,与每月定期更新的NGC 不太一样,Jetson AI Lab会提供最新的信息,可以随时更新,社区支持的推理框架vLLM、SGlang等,容器都可以在这上面下载。
物理AI 布局
如今,物理AI正成为现实——它指通过模型理解物理世界规律,并智能互动的技术。在物理AI新时代,核心挑战是:如何构建高智能模型,并将其部署到数据产生的边缘端,实现实时响应。但解决问题的路径并非从边缘开始,而是从云端起步。
第一步是用英伟达DGX系统训练基础大模型(OEM模型)。有了基础模型后,再通过仿真技术优化:既能生成更多数据提升性能,也能微调模型,或用于测试验证。关键是,我们会先构建虚拟环境(比如Omniverse),在模型实际部署到机器人前,充分验证其有效性。
验证完成后,模型会被带到物理世界的边缘设备(如Jetson)上运行。英伟达与全球软件、AI及机器人开发者合作,加速从开发到部署的全流程技术栈落地。
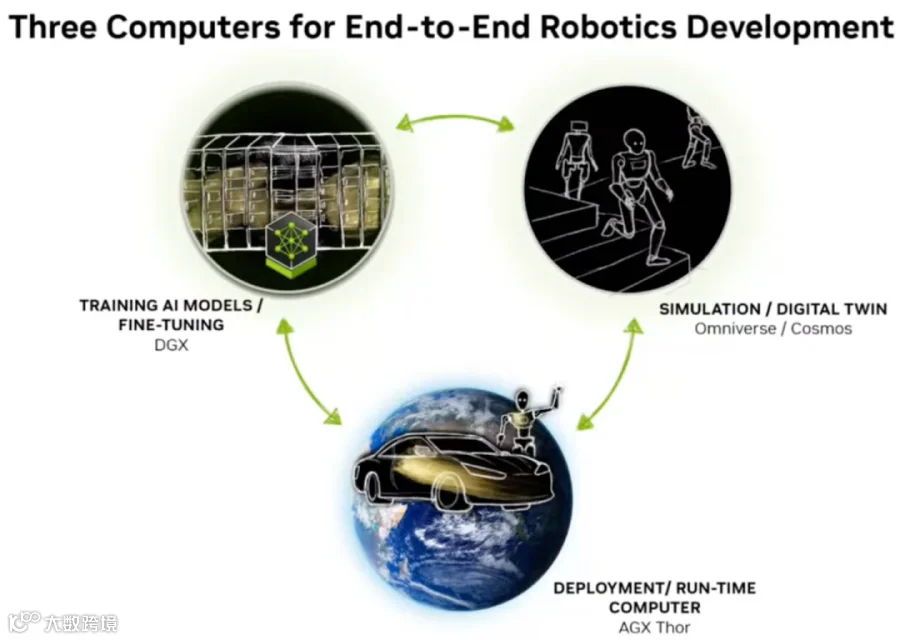
从上图看出,英伟达提供了三大计算平台方案解决物理AI问题,分别是DGX、OVX、AGX。其中DGX用于训练模型,OVX结合Omniverse,提供高保真的仿真能力,将训练好的模型在其中完整功能验证,AGX作为边缘计算节点,将模型部署到实际生产环境中。

总结
-
Blackwell 架构:双裸片一体化 + NVLink/NVLink Switch 高带宽互联,配合新 Transformer 引擎与 Tensor Core,加速 LLM/MoE 的训练与推理。 -
Jetson Thor 落地边缘实时推理:T5000 级算力与 273GB/s 带宽支撑端侧大模型;Holoscan 直入显存降低传感器延迟;MIG 支持多模型/多 Agent 并行。 -
物理 AI 三平台闭环:云端 DGX 训练基础模型,OVX+Omniverse 做仿真验证与数据生成,边缘 AGX/Jetson 部署到真实环境;Jetson Software Stack/AI Lab 串起从开发到落地的全流程。