
近日,海豚智声(Dolphin AI)自主研发的全球首个超声大模型测评基准 U2-BENCH 正式获人工智能顶级学术会议 ICLR 2026 录用。
此次入选不仅代表了国际 AI 学术界对海豚智声在医疗大模型领域科研实力的权威认可,更标志着由中国企业制定的超声 AI 评测标准走向世界舞台,填补了该领域系统性评测体系的空白。作为超声 AI 赛道的引领者,海豚智声始终致力于通过技术创新定义行业高度。今天,我们将深度解读这一开启医疗大模型新赛道的重磅成果。
01
医疗AI的深水区:从通用视觉到超声专业理解
超声成像(Ultrasound)作为全球医疗中应用最广泛的影像手段之一,在妇产科、急诊及心脏病学等场景中具有不可替代的地位。然而,与 CT / MRI 等模态相比,超声影像的自动理解长期面临更高门槛:
操作依赖性强:超声影像受操作者手法影响,质量波动大、伪影多。
空间关系复杂:不同于 CT/MRI 的静态切片,超声呈现的是动态的、具有强空间上下文关系的结构。
评测体系缺失:虽然通用视觉大模型(LVLMs)如 GPT-4V、Gemini表现惊人,其在超声这一高专业度场景下的能力,长期缺乏系统、可复现的评估体系。
在此背景下,U2-BENCH被提出,作为首个系统性评估LVLMs在超声领域能力的深度基准,涵盖了分类、检测、回归及文本生成四大任务维度。
02
核心设计:全谱系解剖覆盖与临床启发式任务
U2-BENCH的核心价值在于其高度的临床相关性和严密的构建流程:
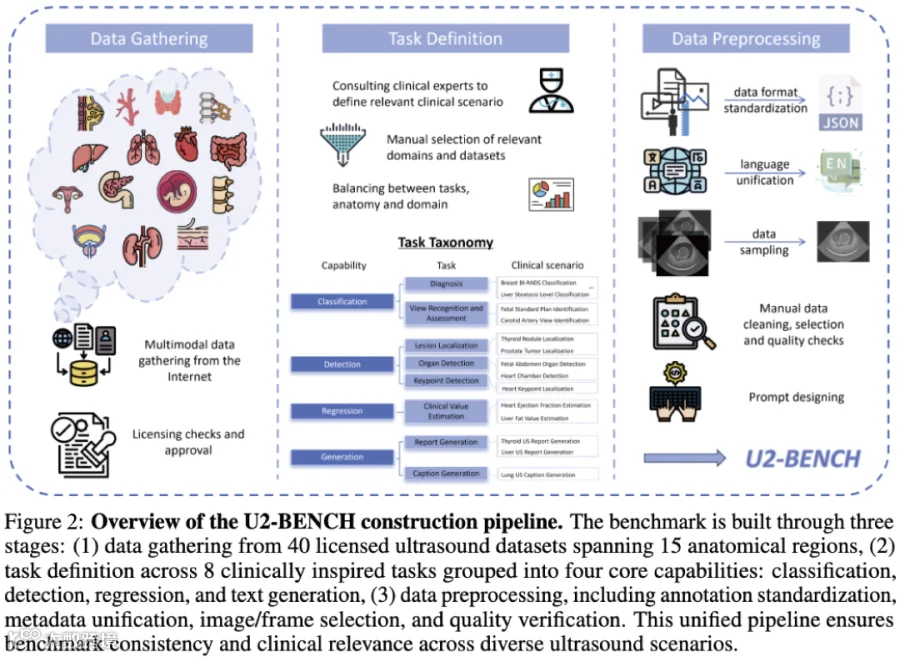
2.1 超大规模、多来源的真实临床数据
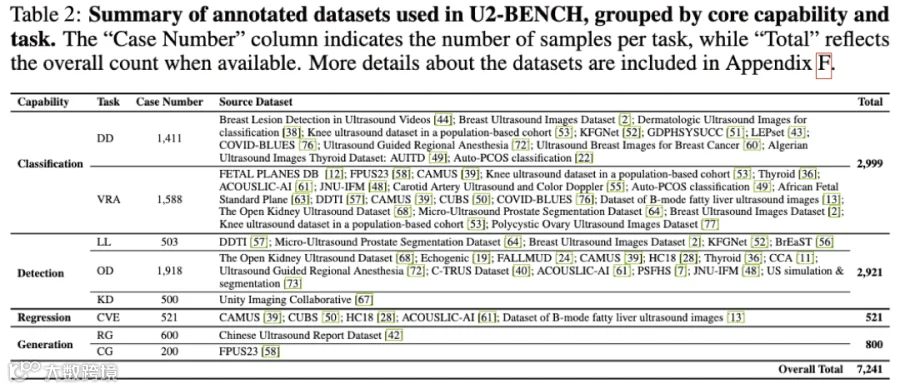
广度覆盖:汇集了来自 40 个授权数据集的 7,241 个案例,跨越 15 个解剖区域(如胎儿、心脏、乳腺、甲状腺等)。
深度场景:涵盖 50 个临床应用场景,确保了评估结果能真实反映模型在医疗一线的能力。
2.2 四级能力分解,八项临床任务
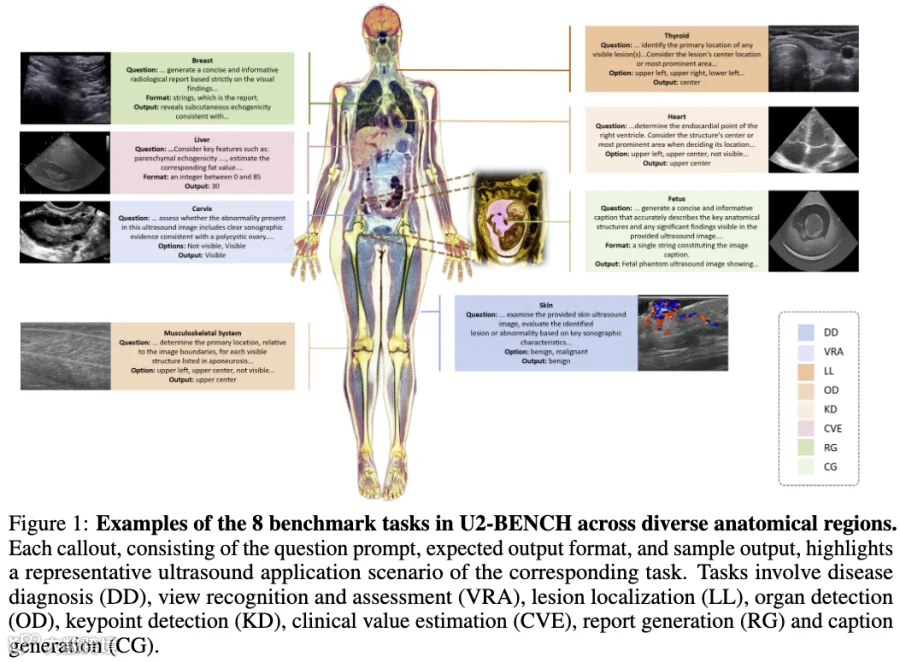
U2-BENCH 将“超声理解”拆解为四个能力层级、八项具体任务:
分类任务:疾病诊断(DD)、标准切面识别与质量评估(VRA)。
检测任务:病灶定位(LL)、器官检测(OD)、关键点检测(KD)。
回归任务:临床数值估计(CVE,如射血分数、脂肪肝百分比)。
生成任务:结构化报告生成(RG)、解剖描述生成(CG)。
03
实验验证:SOTA 模型的能力边界
U2-BENCH上系统评测了23个领先视觉语言模型(包括 GPT-5, Gemini 2.5, Dolphin-V1 等)进行了大规模评测:
3.1 闭源模型依然领先,但仍有巨大空间
榜首表现:Dolphin-V1 以 0.5835 的总分(U2-Score)位列第一,大幅领先于 GPT-5(0.3250)和 Gemini-2.5-Pro(0.2968)。
开源对比:开源模型中 DeepSeek-VL2 表现最强,但在复杂推理上与闭源顶尖模型仍有代差。
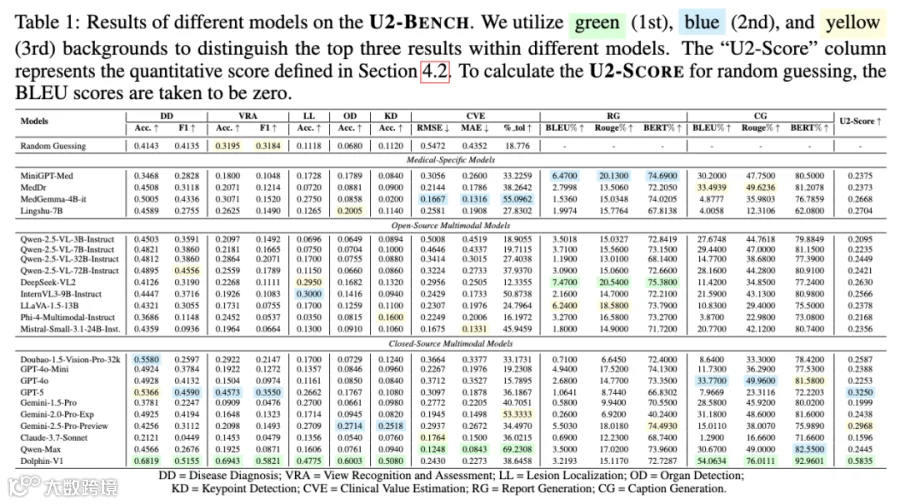
3.2 任务难度的代差:识别容易,推理极难
分类 vs. 空间推理:模型在疾病诊断(DD)等图像级分类上表现尚可,但在空间位置相关的检测(KD/OD)和回归(CVE)任务上表现堪忧。
报告生成的挑战:模型生成的语言质量虽然不错,但在医疗准确性和结构化合规性(RG)上仍存在严重缺陷。
3.3 关键结论:规模不是唯一解
缩放定律的平台期:在Qwen家族的对比中发现,模型参数量从 3B 到 72B 带来了稳步提升,但在某些空间推理任务上提升并不显著,暗示了超声专项训练比单纯扩大参数更有效。
04
总结与展望
全球首个超声大模型测评基准U2-BENCH的建立表明超声AI正在从“单一任务的小模型”转向“全能理解的大模型”。同时实验也揭示了当前 LVLMs 在空间推理和临床逻辑上的短板。
未来,U2-BENCH 将扩展至:
动态视频理解:从单帧走向实时扫查序列。
长程具身感知:结合机械臂等硬件实现自动化、闭环的超声扫描与决策。
