

全球具身智能基准评测

MolmoSpaces 是由美国艾伦人工智能研究院发起的全球具身智能基准评测平台,聚焦机器人在真实家居场景中的核心操作能力,由于机制公正严苛,已成为国际公认的机器人操作能力试金石。
该平台采用“零样本”原则,不得在评测数据上做任何微调,而是直接在 DROID 平台上执行语言指令;同时每条任务都预先固定了场景布局、机器人初始位姿、物体摆放与相机参数,并以平均成功率作为统一排名指标,确保结果可复现、可横向比较。
在最新公布的 MolmoSpaces Combined 子任务排名中,中国电信人工智能研究院(TeleAI)创新研发的强化学习原生 VLA 基础模型 PRTS 位列全球第三名,超越了英伟达自研的标杆级世界动作模型 DreamZero。
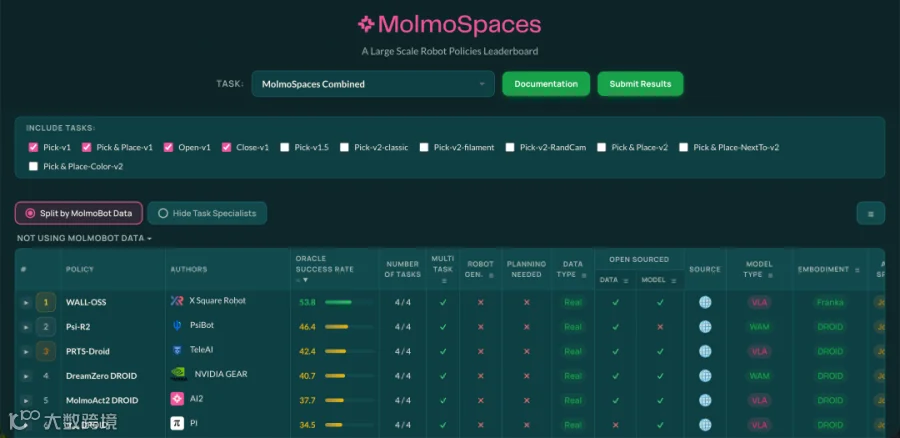
(点击查看大图)

PRTS 是 TeleAI 推出的全新 VLA 基础模型,由中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授带领具身智能团队创新研发,首次将对比强化学习系统集成到 VLA 预训练阶段,让机器人真正理解并掌控任务进程,在长时复杂操作中保持精准。
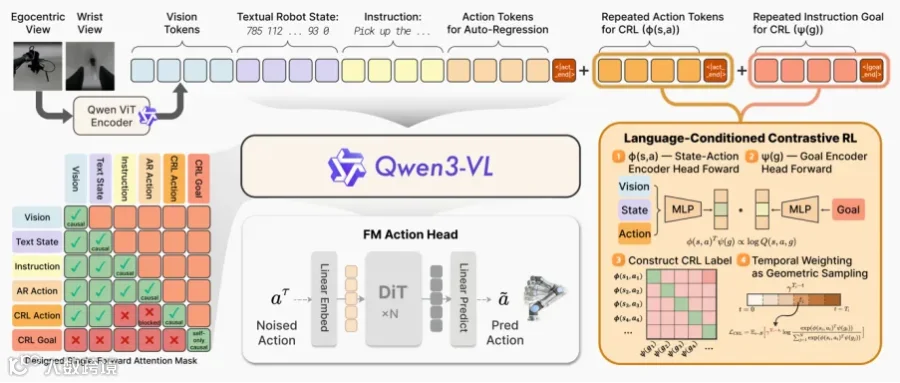
一直以来,业界对于 VLA 存在担忧:VLM/LLM 的表征偏重“静态理解+推理”,而对动作执行中最关键的时间维度先验不足,这让 VLA 在操作任务中,总是缺少一种隐式的未来预测能力,显得“看不清”动作的后果。
通俗来讲,就是担心 VLA 只会“看当下”,不懂“算未来”。
举个例子,比如让机器人抓杯子,它能看到杯子在哪,但不知道:应该抓到什么程度停下?这一步运动完,下一步会发生什么?离完成任务还差多远?
(视频:搭载PRTS的机器人操作功夫茶)
而PRTS 的核心突破就是:
给 VLM 强化“时间认知”能力,让表征空间天然具备“时序感知”先验。
TeleAI 没有走“预测未来视频”的复杂路线,而是用更轻巧、更高效的方式,补齐 VLA 最缺乏的能力。它不依赖显式生成未来帧或未来状态,而是让模型在每一步决策时都能稳定权衡当前一步对下一步的深层影响。
给模型植入“时间感”
PRTS 不做“显式预测”未来画面,而是让模型在决策时,天然携带时间权重。每动一步,都会自动权衡对下一步及最终目标有什么影响。就像人类做事,心里有一张“进度表”,知道离目标还有多远。
不堆复杂度,数据效率拉满
相对于靠“预测未来”的热门路线 WAM 规模大、延迟高,PRTS 做到了轻量高效。它只用了约 5000 小时训练数据,而很多头部路线则动辄需要上万小时。PRTS 用更少的数据,带来更好的效果,真正实现高效通用。
强化学习原生,零样本更稳
依托强化学习“面向未来”的天然优势,PRTS 让模型学会判断当前状态离成功还有多远、什么时候该推进、什么时候该停下,在严苛的零样本评测里,稳定输出,成功率高。
相关工作

Y. Zhang, J. Zhao, C. Fan, F. Yan, T. Li, X. Wu, Q. Weng, X. Li, W. Zhang, C. Zhang, C. Bai, and X. Li*, “PRTS: A Primitive Reasoning and Tasking System via Contrastive Representations”, arXiv:2604.27472, https://rhodes-team-prts.github.io/.
J. Shao and X. Li*, "AI Flow at the Network Edge", IEEE Network, vol. 40, no. 1, pp. 330-336, Jan. 2026, doi: 10.1109/MNET.2025.3541208.
H. An, W. Hu, S. Huang, S. Huang, R. Li, Y. Liang, J. Shao, Y. Song, Z. Wang, C. Yuan, C. Zhang, H. Zhang, W. Zhuang, X. Li*. "AI Flow: Perspectives, Scenarios, and Approaches", Vicinagearth 3, 1 (2026).
