
DeepSeek V4 之后,美国的复盘对象从模型参数一路追到了模型背后的人。
6 月 15 日,斯坦福大学胡佛研究所和人类中心人工智能研究院(HAI)更新了一份白皮书,题为《Update: DeepSeek AI and the Great Talent Competition》。这份报告追踪 DeepSeek 七篇核心论文背后 356 名研究和工程贡献者的职业轨迹,试图回答一个比模型榜单更底层的问题:DeepSeek 的前沿模型,到底是谁做出来的?
这次更新和 V4 直接相关。2025 年的首份报告只分析了 DeepSeek 前五篇基础论文,今年新增了两篇:DeepSeek V3.2 和 DeepSeek V4。这里的“七篇论文”有明确清单,报告把 DeepSeek 从 2024 年 1 月的开源 LLM,一路追到 2026 年 4 月的 V4 预览版本。

先看这 7 篇论文:V4 是新增样本里的最后一块
白皮书用论文作者网络来观察 DeepSeek,而不是用公司员工名单来观察 DeepSeek。这个口径很重要,因为它看见的是“谁参与了模型和系统论文”,不是 DeepSeek 公司所有岗位。
报告纳入的七篇论文大致是这一条线:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
白皮书 Appendix B 还给了每篇论文的纳入作者数。V3.2 对应 212 名研究和工程作者,另有 51 名数据标注、商务与合规贡献者不计入这次人才分析;V4 对应 270 名研究和工程作者,另有 48 名商务与合规贡献者被排除。这个细节很关键,它说明报告不是简单数署名,而是在尽量把口径收回到研发贡献者。

这条时间线让 DeepSeek 的故事变得更具体。V2 解决稀疏 MoE 和 KV cache,V3 把大规模 MoE 训练成本推到台前,R1 把强化学习推理能力打成全球事件,V3.2 继续往高效率推理、Agentic 任务和竞赛级推理推进,V4 则把长上下文能力推到百万 token 场景。所以,白皮书真正看的,是一条连续两年多的论文序列。作者网络从 223 人扩到 356 人,意味着 DeepSeek 的研发系统被放在更长的模型演进线上重新观察。
这份研究怎么做:从论文作者到机构履历
方法上,报告先确定七篇论文里的研究和工程贡献者,再把这 356 名作者拿去和 OpenAlex 数据库对齐。OpenAlex 在这里提供的是学术发表、引用指标和机构归属历史。报告作者在 2026 年 4 月查询这些资料,并把可追踪记录向前追到 1989 年。
356 人里,有 282 人可以建立可用的 OpenAlex 档案;其中 271 人有机构归属记录。报告随后用 Python 映射每个人完整的机构历史,观察他们是否在中国、美国或其他国家学习、工作、发表,最后再统计跨境流动路径。
这里还有一个容易被忽略的口径变化。上一版报告统计了每篇论文里的所有署名贡献者;今年的更新版把范围收窄到研究和工程团队。对于明确区分角色的论文,数据标注、商务、合规等贡献者被排除在外。对于没有区分角色的论文,所有列出的贡献者会被纳入。
282 个可用档案之外,还有 75 名作者没有被 OpenAlex 解析出来。白皮书把这个缺口的一部分归因于第七篇论文发布时间很近:Paper 7 在 2026 年 4 月中旬发布,其中 66 人只出现在 V4 这一篇论文里,另有 6 人只出现在 V3.2 和 V4 两篇论文里,尚未被 OpenAlex 完整索引。

报告从 DeepSeek 七篇论文出发,结合 OpenAlex 档案追踪作者的发表、引用和机构归属历史。这个方法决定了后面的所有数字都不能被读成“DeepSeek 全公司人数”。它更像一张论文研发网络图:谁在论文上出现,出现了几次,是否一直参与,是否有美国机构经历,是否完全沿着中国本土机构成长。
356 人背后:核心没变,外围涨得很快
白皮书里最先跳出来的一组数字,是作者池扩张。2025 年报告覆盖五篇论文,今年扩展到七篇论文。按可比口径计算,DeepSeek 研究和工程贡献者从 215 人增长到 356 人,一年内扩张 57%。最近两篇论文净增 141 名新贡献者,同期离开 33 人,大致是“进四个,走一个”的速度。但这并不意味着 DeepSeek 是一个松散的大拼盘。报告把作者按参与论文数量拆开后,结构很清楚:
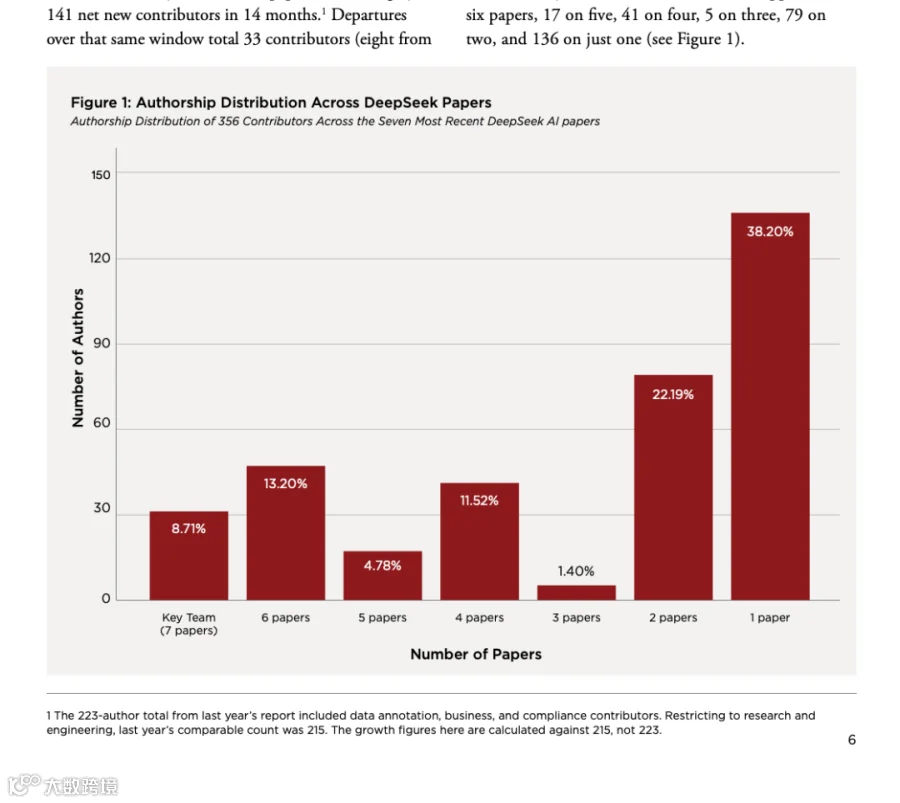
31 位研究者出现在全部七篇论文上,报告把他们称为 Key Team。另有 47 人出现在六篇论文上。这两层构成了稳定主干。
另一边,136 人只出现在一篇论文上,79 人出现在两篇论文上。也就是说,DeepSeek 同时存在两种力量:一条长期在场的核心线,一条围绕新模型、新系统、新任务迅速补进来的贡献者线。
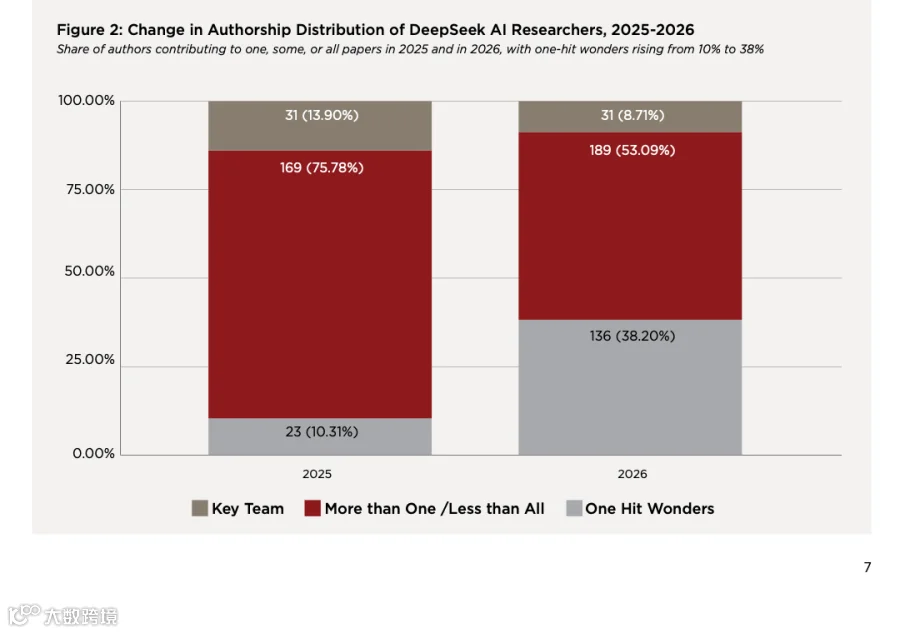
2026 年“一篇论文贡献者”从 23 人增至 136 人,Key Team 仍保持 31 人。这里真正值得看的,是 356 人背后的分层结构。核心 31 人保持不变,说明技术路线没有频繁断裂;一篇论文贡献者大幅增加,说明 DeepSeek 能把外部或边缘任务能力快速接到主线研发里。
53.5%:中国本土人才管线已经进入核心层
白皮书最容易引发讨论的数字,是 53.5%。
在 271 位有机构归属记录的研究者中,145 人在可追踪履历里从未与中国以外机构产生关联,占 53.5%。这个比例和 2025 年报告里的 55.2% 接近,说明它不是一次样本波动。
这改写了一个常见解释:DeepSeek 的能力不能只解释为“海外训练后回流”。这条线当然存在,但它已经不是全部。更关键的是核心层,31 位 Key Team 成员中,有 10 人没有任何中国以外机构经历。换句话说,一个能在推理任务上对标 OpenAI o1、又继续演进到 V3.2 和 V4 的模型序列里,三分之一长期核心贡献者是在中国本土教育和研究体系中成长起来的。
报告还列出了本土机构网络的扩张。中国科学院及其 170 个下属机构关联研究者从 53 人增长到 104 人,覆盖整个作者池约 37%;清华从 16 人增长到 46 人;浙江大学从 8 人增长到 25 人;北京大学从 21 人增长到 29 人。东南大学、北航、兰州大学等去年还不显眼的节点,也在今年的网络里迅速抬头。
这部分比“某几个天才做出模型”的说法更重要。前沿模型背后不只有个人能力,还有学校、研究院、实验室、工程任务和论文产出之间的长期连接。
美国仍然重要,但不一定留得住
报告没有把美国写成无关变量。恰恰相反,80 位 DeepSeek 研究者有美国机构经历,他们平均引用数达到 4108 次,是作者池里学术履历最强的一组。变化在于,美国机构经历不等于最终留在美国。
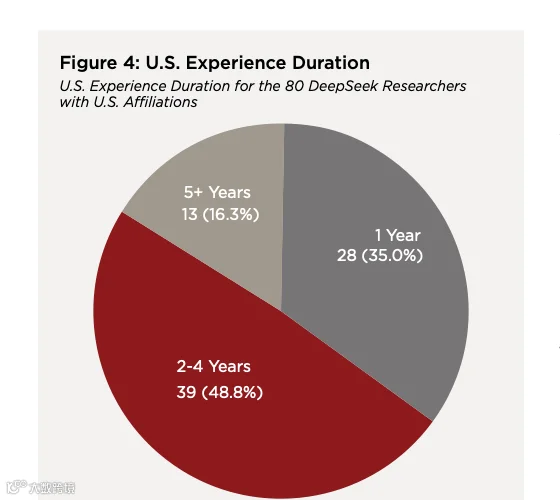
80 位有美国机构经历的 DeepSeek 研究者中,35% 只有 1 年美国经历,48.8% 有 2 到 4 年,16.3% 有 5 年以上。
2025 年报告里,很多美国相关研究者看起来只有一年美国经历,像是短暂停留。但今年扩展数据后,图景变得更复杂:近一半人在美国待过 2 到 4 年,13 人有 5 年以上美国机构经历。这说明美国仍然是全球 AI 人才链条里的重要训练场。可问题是,训练场不一定是终点。
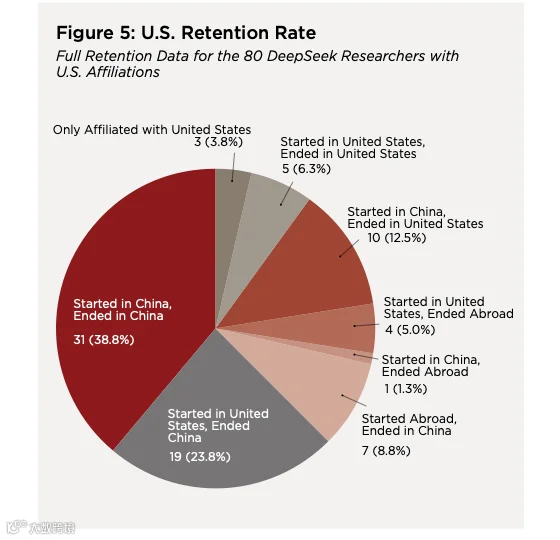
80 位有美国机构经历的研究者中,最常见路径是“中国 -> 美国 -> 中国”,占 38.8%。
报告提到,13 位长期美国机构经历者累计在美国机构度过 119 年以上,其中多数后来回到中国。更广义的 80 位美国关联研究者里,最常见路径是“中国 -> 美国 -> 中国”,占 38.8%;第二大路径是“美国起点 -> 中国终点”,占 23.8%;“中国 -> 美国 -> 留在美国”只有 12.5%。
这不是一句“人才回流”就能讲完的事。美国仍然训练出强研究者,但中国正在提供另一个能继续做前沿模型的位置。
DeepSeek 也不是“低经验年轻团队”
全体 282 位有 OpenAlex 档案的作者,平均引用数为 1763.85,中位引用数为 681。31 位 Key Team 平均引用数为 2470.65,中位引用数为 1200。80 位有美国机构经历者平均引用数更高,达到 4108.5。
这些数字说明,DeepSeek 的作者网络并不低经验。它更像一个混合结构:有年轻工程师,有长期研究积累,有本土培养路径,也有美国和其他国际机构经历。
这里也能解释为什么 V4 这么重要。V4 把百万 token 上下文、混合注意力架构、mHC、Muon optimizer、32T tokens 预训练和长上下文推理效率放在同一个报告摘要里。这样的模型演进,更接近持续组织工程。
美国面对的是两道题
把白皮书里的数字拆开,美国现在面对的是两道不同的题。
第一道题是留住美国训练过的人。80 位有美国机构经历的 DeepSeek 研究者,是整个作者池里学术成就最高的一组;但其中大量研究者最终回到中国或以中国机构为终点。签证、绿卡、博士后和 STEM 研究者长期路径,都会进入这个问题。
第二道题更难:如何面对中国本土人才梯队。145 位有机构记录的研究者从未与中国以外机构产生关联,31 位 Key Team 里也有 10 人从未离开中国。对这部分人,美国的签证政策、出口管制和高校准入政策都很难直接发挥作用。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
这也是 DeepSeek 会被美国持续研究的原因。它已经是一份人才系统样本。
最后看这张人才账本
V4 之后再看 DeepSeek,问题会从“模型多强、价格多低、上下文多长”,继续延伸到模型背后的组织和人才。斯坦福 HAI 与胡佛研究所这份更新版白皮书,把 DeepSeek 拆成一张人才账本:七篇论文、356 名研究和工程贡献者、282 份可用学术档案、271 条机构归属记录、31 位长期核心成员、145 位纯本土机构路径研究者、80 位美国机构经历研究者。
它有稳定核心,也有快速扩张的外围;有本土培养,也有海外经历;有年轻工程能力,也有长期学术积累;有 R1 带来的全球关注,也有 V3.2 和 V4 继续推进的长上下文、推理和 Agentic 任务能力。
参考链接
-
Hoover Institution / Stanford HAI 白皮书《Update: DeepSeek AI and the Great Talent Competition》:https://hoover-s3-website.s3.us-west-2.amazonaws.com/s3fs-public/research/docs/WhitePaper_Hoover_HAI_DeepSeek_FINAL%203.pdf