
上一周,我收到一条消息。
发消息的是一个大四女生,她说自己的论文被导师退回来了。
原因不是格式问题,不是引用不规范,而是——
"AIGC检测率81%,重新写。"
她跟我说,那篇论文她写了将近三个月。田野调查、问卷回收、数据清洗、反复修改。她几乎没有用AI生成任何段落,顶多让ChatGPT帮她润了几句话的措辞。
81%。
我问她:你自己测过吗,没改之前是多少?
她说:没测过,以为不会有问题。
这个对话让我觉得有必要认真写这篇文章。
不是因为这件事罕见,而是因为它太普遍了,但几乎没有人真正讲清楚过。
检测工具在解一道错误的方程
先从一个根本性的问题说起。
AIGC检测工具,到底在做什么?
很多人以为,它在做"溯源"——追踪这段文字是不是某个AI模型输出的。
但这在技术上根本不可能实现。
ChatGPT、Claude、文心一言,这些模型不会在输出文本里留下"数字水印",不会有任何可以被追踪的元数据。一段文字生成之后,从技术层面看,它和任何人类打出来的文字没有任何物理区别。
所以,检测工具能做的只有一件事:
用统计模型,判断这段文字的语言分布,是否更接近AI语料库的输出特征。
换句话说,它给出的不是"这是AI写的",而是"这看起来像AI写的"。
这两件事,差得很远。
一个是事实判断,一个是概率估计。
但几乎所有检测报告的呈现方式,都在有意无意地模糊这个区别。
困惑度:那个决定你命运的指标
AIGC检测的核心技术指标,叫做困惑度(Perplexity)。
它来自语言模型的基本原理:一个模型在预测下一个词时,如果"不怎么意外",困惑度就低;如果下一个词很出乎意料,困惑度就高。
AI生成的文本,因为本质上是"选最可能出现的词",所以困惑度天然偏低——句子流畅、可预测、几乎没有"惊喜"。
检测工具就用这个指标来反推:困惑度低的文本,大概率是AI生成的。
这个逻辑,在大多数情况下是有效的。
但它有一个致命的漏洞:
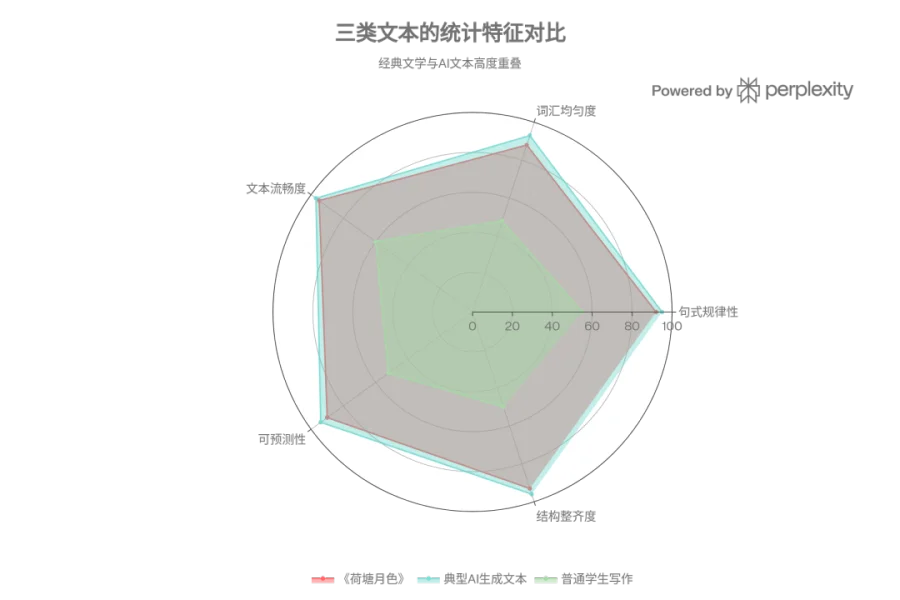
优秀的写作,本身就是低困惑度的。
经过反复打磨的句子,用词精准,逻辑顺畅,节奏稳定。好文章之所以好读,恰恰是因为它"顺"——读者不需要停下来重新理解,下一句几乎是自然而然的延伸。
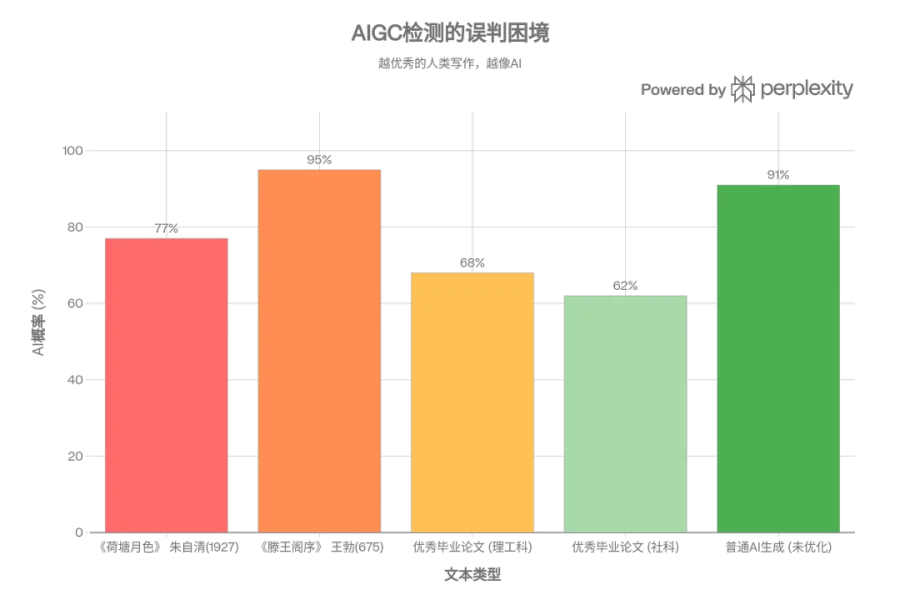
《荷塘月色》就是最极端的证明。
那些被选进教科书、被无数人背诵的句子,节奏、词汇、句式都经过了极度的打磨和筛选。放到统计模型里,它们的困惑度低得惊人。
于是检测工具给出了77%的AI概率。
那篇文章写于1927年,距离第一台通用计算机诞生还有将近二十年。
一个没人愿意说透的结构性矛盾
这里有一个更深层的问题,但很少有人把它说清楚。
现代大型语言模型的训练语料,包含了大量人类历史上的优秀文本——经典文学、学术论文、新闻报道、技术文档。
AI是学人类写作写出来的。
它写得像人,是因为它的"老师"就是人类最好的那批文字。
然后,检测工具拿着"AI的写作特征"反过来判断人类——
结果就出现了这种黑色幽默:
人类最优秀的写作 → 训练了AI → AI学会了优秀写作的规律 → 检测工具把"优秀写作规律"标记为AI特征 → 人类优秀写作被判定为AI
这不是工具的bug,而是这个技术路线根本性的逻辑悖论。
你越认真写,越精打细磨,越可能触发这个悖论。
而对于大学生来说,这个悖论最容易在两类论文里爆发:
一是理工科实验报告类论文。方法论要规范,数据描述要精确,结论要逻辑严密。这些要求写出来的文字,天然符合AI语料的统计分布——结构整齐、术语密度高、主动歧义极少。
二是社科类文献综述。大量引用、概念界定、横向对比,这类写作模式本来就要求高度规范化。规范本身,就是触发检测的导火索。
检测报告在告诉你什么,又在隐瞒什么
值得认真看的,不只是那个总分。
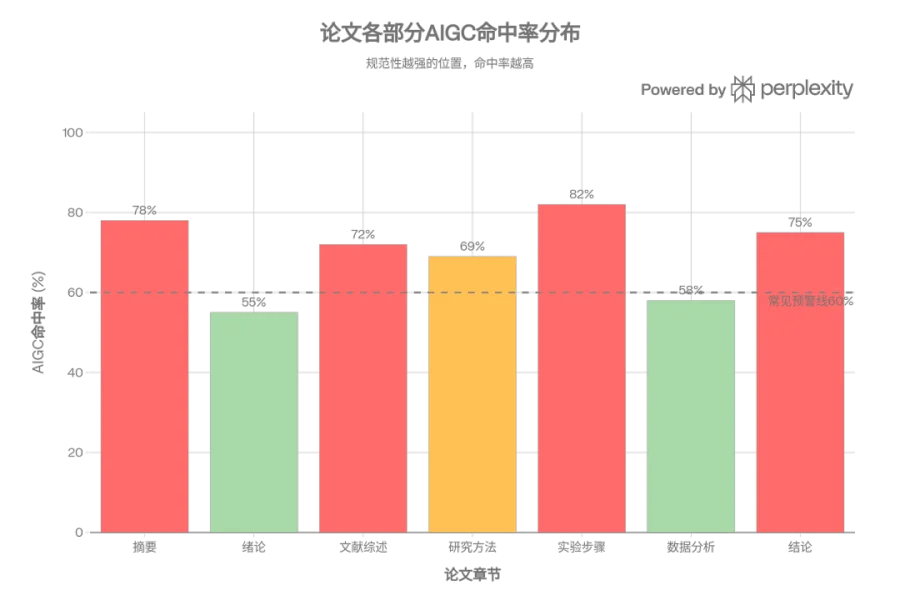
主流的AIGC检测报告,一般会标注高风险段落,并给出局部的疑似AI比例。
如果你把报告拿来仔细分析,会发现一个规律:高风险段落往往集中在论文的特定位置。
-
摘要和结论,因为结构最规范,通常是检测命中率最高的地方 -
文献综述的引用转述段落,因为需要"客观陈述他人观点",往往措辞非常中性和规整 -
实验步骤的描述段落,因为精确性要求导致句式高度统一
这些位置被标记,不代表你在这里用了AI,而是代表这些位置的写作规范本身触发了统计模型。
理解这一点,才能有针对性地处理,而不是把整篇文章打乱重写。
现在有些工具开始往这个方向走,比如 Reduce AIGC(ai.reduceaigc.com)——它支持直接上传知网、维普的检测报告,基于报告里的高风险标注定点处理,而不是无差别改写全文 。对理工科论文来说,这个逻辑尤其重要:你不需要把专业表述改成口语,你需要的是在保留专业度的前提下,打破那些触发检测的统计规律。降AI,但不能降专业度,这才是对的方向 。
那我们该怎么对待这个工具?
我的判断是:AIGC检测值得参考,但不值得敬畏。
它能做到的事情,是在明显的AI堆砌文本里,提供一个有效的过滤信号。如果一篇论文通篇都是AI直接生成、没有任何个人加工,检测工具大概率能发现。
但它做不到的事情同样明显:它无法区分"写得很好的人类文字"和"AI生成文字"。
在这个判断能力缺失的地方,把工具结论当成最终裁决,就是在用一把精度不足的尺子,做一件需要精确测量的事。
学校和老师可以用它作为参考,但不应该把它当成证据。
学生可以用它做自检,但不应该让它决定你的写作风格。
如果为了降低AIGC率,你开始刻意加错别字、拆分整句、用口语替换术语——那不叫"通过检测",那叫"为了讨好机器而破坏自己的论文"。
最后
那个被退稿的女生,后来找我聊了很久。
她最终没有重写论文。
她做的事情是:打印出检测报告,把每一个高风险段落单独看,找出那些"太过平整"的句子,加入更多她自己田野调查里真实采集到的细节和表述——那些非常具体的、只有当事人才能写出来的内容。
两周后,她重新提交。
AIGC率:19%。
论文没有变差,反而因为加入了更多实证细节,变得更扎实了。
这大概才是面对AIGC检测最好的姿态:
不是绕过它,而是用它倒逼自己,把那些"太完美"的表达,替换成只有你自己才能写出来的东西。
工具是工具。
判断,还得是人。