
责编 | 梦依丹
极致的推理延迟、极高的吞吐量、极大的模型规模……在大模型工程化的战场上,这曾是一个被公认为‘不可能’的三角。
回望 2025 年,DeepSeek-V3 技术报告为大家揭示了超大规模模型推理的新一代范式。通过 MLA 架构将 KV Cache 压缩 93%,配合 MTP(多 Token 预测) 技术大幅提升访存效率,全球开发者见证了万亿参数模型在大规模并发下实现“高吞吐、低延迟”的工程突破。
然而,站在 2026 年的当下,依靠 FP8 精度和基础架构已难以满足爆发式的即时响应需求。在大规模真实并发的洪流前,每一毫秒的延迟缩减,都直接挂钩着数以亿计的算力成本与集群效能。
正是在这种“性能即生命”的行业背景下,🚀2026 线上黑客松:AMD E2E Model Speedrun 全球挑战赛正式拉开帷幕!
AMD 联手 GPU MODE,豪掷 110 万美元发起这场全球竞速。
寻找那些能徒手拆解底层逻辑、将 AMD 旗舰算力的每一滴潜能都榨取出来的顶级开发者。


预选赛——入围即拿 1 万美金
本次大赛采用“预选赛 + 端到端决赛大考”的双阶段赛制,每个阶段都设立了令人心动的重磅奖励。
该阶段前 10 名优胜者将获得 1 万美金,并拿到决赛入场券
-
MXFP4 MoE:1500 分 -
MLA Decode:1250 分 -
MXFP4 GEMM:1000 分
-
唯快不破:基于测试用例的绝对运行时间进行排名,计算所有基准用例的几何平均值; -
准入门槛:作品性能必须超越官方基线(Baseline)且排在前 20 名方可计分,未入前 20 者得分为零; -
积分公式:单项得分 = 最大分值 × [1 - (排名分值/20)],排名按顺序对应分值 0, 1, 2...19; -
先到先得:总分为三项内核得分之和。若遇平局,以提交时间最早的内核为准;
-
权威复现:总分最高的前十名需经主办方独立复现结果后,正式确定决赛席位。

决赛大考: 晋级选手将瓜分 100 万美元现金大奖!
预选赛排名前 10 的顶尖团队将获得 AMD 旗舰级算力集群的操控权,开启为期一月的端到端模型性能极限压榨。
决赛大考共分为两条赛道,分别是 DeepSeek-R1-0528 (FP4+MTP) 与 Kimi K2.5 1T (FP4)。参赛选手可以同时开启双线作战,多维度压榨旗舰算力潜能,赢取总计 100 万美元的决赛大奖。
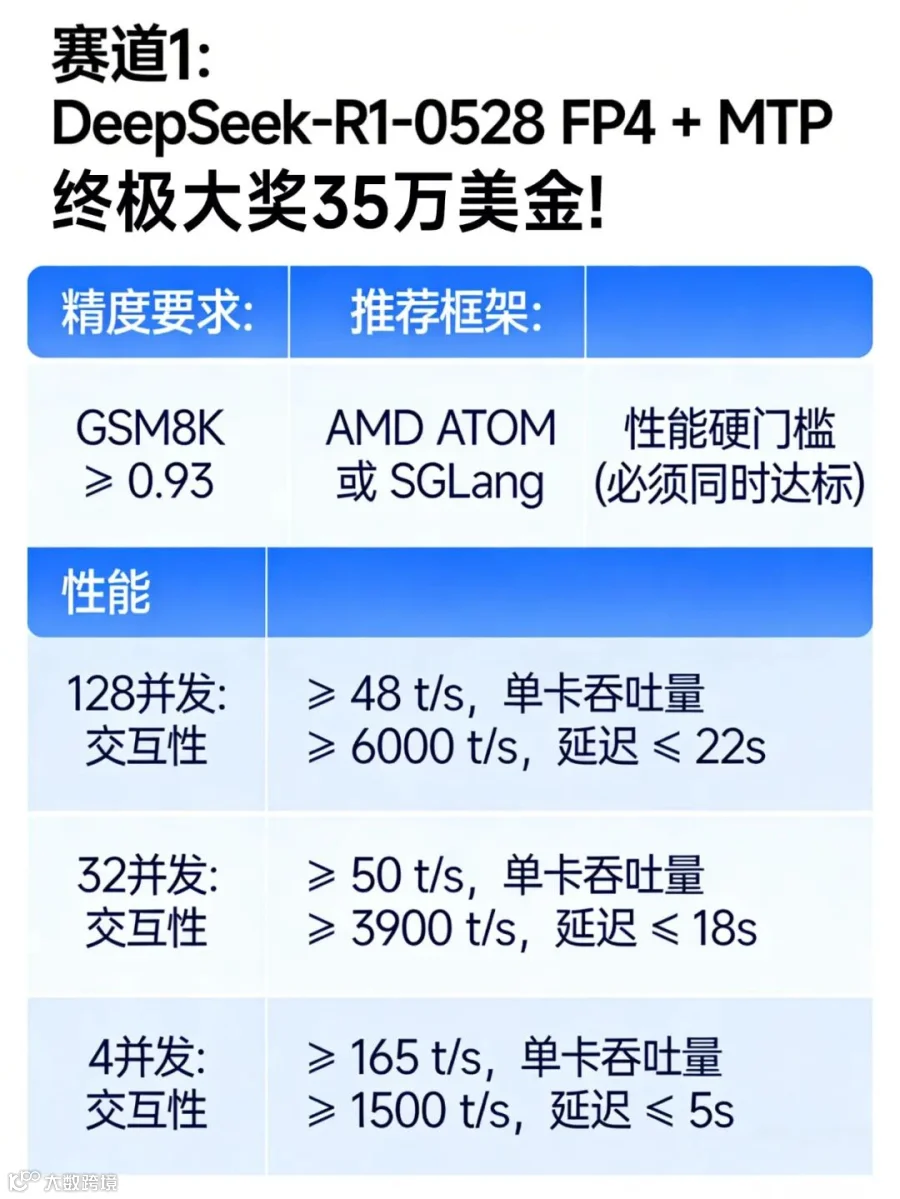
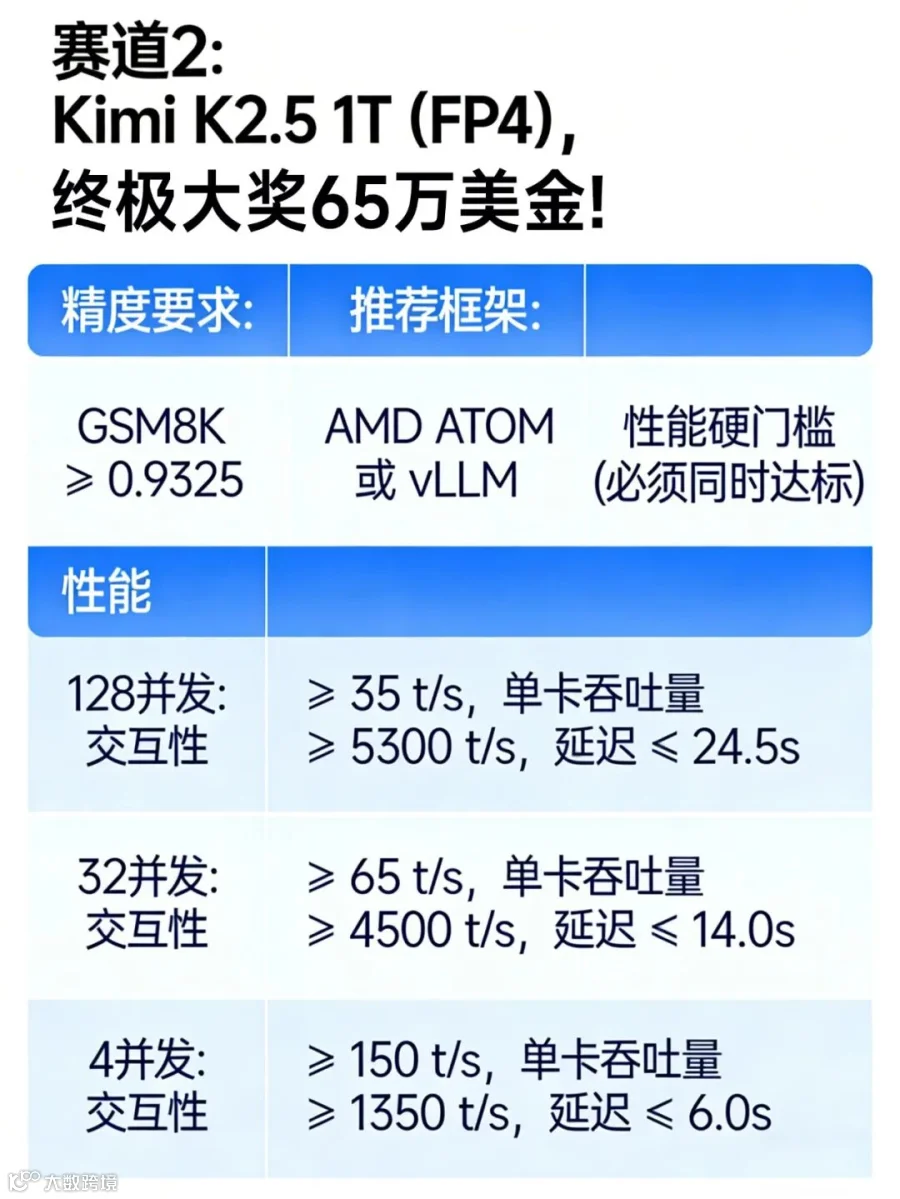
-
多维评估:在 Input 8K / Output 1K 的标准测试负载下,综合考量每 GPU 总 Token 吞吐量、交互性(Interactivity)以及端到端延迟(E2E Latency); -
算力分配:支持最大 TP/EP = 8 的 8 卡节点配置,开发者可根据显存与通信效率自由调优配置; -
结果为王:每个并发等级将根据吞吐量(权重 60%)与交互性(权重 40%)进行排名赋分,三大并发等级得分之和即为决赛总分。

