
周末,咱们简单聊聊。
最近,我拿到了小米 MiMo-V2.5-Pro UltraSpeed 模式的内测资格。
我先什么都不说,你直接来看下面这段我录的实测视频,全程没有加速。
再说一遍,从头到尾全程都没有加速。
说真的,我现在已经很少被 AI 惊艳到了,但这个东西让我久违的眼前一亮。
当时盯着屏幕看的我,不知道说了多少个卧槽出来。。。
最主要是,我觉得这件事的重要性,大多数人还没意识到,包括很多天天在使用 AI 的人。
先用一句话说下,这个 UltraSpeed 是干啥的。
就是让万亿参数大模型的输出速度,首次冲过了每秒 1000 tokens。
你应该已经知道了,token 的中文名是词元,简单理解就是大模型吐字的最小单位,几个字母,或者一两个汉字。
咱们平时用的那些主流模型,输出速度普遍在每秒几十到一百出头个 token。
1000 tokens/s,意味着比你习惯的那个速度,快了整整一个数量级。
而且注意前面的定语,万亿参数,这是大模型里的旗舰排量。
让巨无霸跑出超跑的圈速,这事儿直觉上是违反物理学的。
行业里正常的逻辑是,要么大而慢,要么小而快,鱼和熊掌选一个。
但小米说,我全都要。
毕竟在速度这条赛道上,小米在纽北那条赛道上已经证明了多次。
实力不可小觑。
1
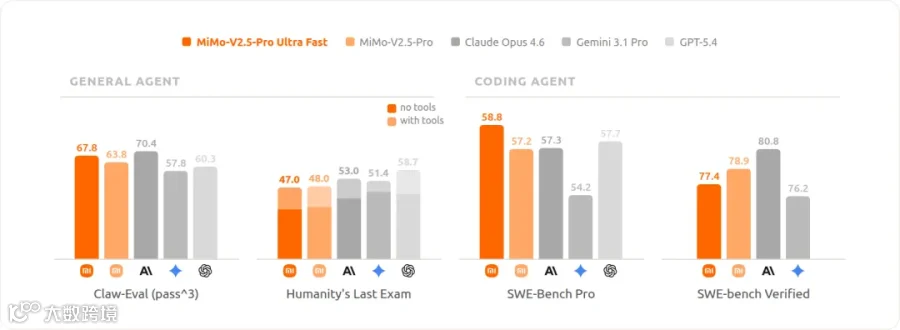
再来看上面实测的细节数据。
首次响应用时 0.83s,总计输出 12874 个 token,总用时 12.4s,平均输出 1016 tokens/s。

峰值甚至飙到了 1157。

0.83s 是什么概念?
以往,我们可能都习惯了问完问题后,出现那个思考中的转圈圈。
但现在你话音刚落,它就已经思考完开始动笔了。
总用时 12.4s 是什么概念?
可能连你起身倒杯咖啡,上趟厕所的时间,都可以直接被省略掉。
最离谱的是,平均输出 1016 tokens/s,全程速度都拉的很满。
你可能会问,即然这么猛,价格是不是也贵的离谱?
价格是 MiMo-V2.5-Pro 的 3 倍,但速度是 10 倍。
而且这才刚开始,价格只会越来越便宜。
2
但是我很好奇,小米凭啥能做到呢?
所以我去翻了翻技术方案细节,发现这 1000 tokens/s 不只是一个黑科技,是三套技术紧密组合出来的。
一听技术细节,你可能会担心听不懂,咱们用大白话来讲。
第一套,FP4 量化。
模型参数的精度,你可以理解成行李的体积,精度越高行李越大,搬运就越慢。
万亿参数用传统的精度跑,光是在显存里搬运数据,就能把速度拖死。
FP4 干的事儿,就是给行李抽成真空,体积直接压掉一大截。
但重要的是,不是无脑全压。
被子可以抽成真空,电脑和相机镜头不行,一压就废了。
Mimo 只压了模型里占参数大头,有最抗压的那部分,MoE 专家模块。
其他部分保留原有精度,整个过程用量化感知训练来做,让模型在训练时就适应了被压缩的状态。
官方给的对比数据是,压完之后,模型能力和原版基本持平。
模型的体重减了一大半,但是脑子还是那个脑子。
可以说是非常 6 了。
3
第二个,DFlash 投机解码,我觉得是整套系统里最妙的设计。
大模型生成文字,原本是一个字一个字往外蹦的。
每个字都要全模型走一遍,又慢又贵。
行业里早就有个偷懒方案,雇个小模型当实习生,先把后面几个字猜出来。
大模型只负责审稿,对的收下,错的打回。
这就比纯写快得多了。
但传统方案有个死结,实习生也是一个字一个字憋的,憋快了准出错,憋准了又太慢。
两头堵。
DFlash 反着来,不让实习生一个字一个字的猜了,让他一把就猜出来后面的一整块。
然后一口气交卷,大模型扫一眼,整块验收。
实测在写代码的场景里,实习生交上来的活儿,大约八成都可以直接通过。
速度这就上来了。
4
第三个,TileRT 推理系统。
前面两个是算法层面的减重和抢跑,TileRT 管的是最底层的事。
让这条产线别停下来。
打个比方,一条计算流水线,传统推理系统是怎么干活儿的?
做完一道工序,停机,启动下一道,等数据搬到位,再开工。
平时这点停顿无所谓,工序本身要跑好几秒,开关机那点时间可以忽略不计。
但当速度被拉到 1000 tokens/s,单道工序的耗时被压到了微秒级。
这时候每一次停机,启动,等数据的开关机动作,本身就和干活一样长了。
产线大部分时间不是在生产,是在切换。
这种被切换撕碎的空档,专门有个词叫执行间隙。
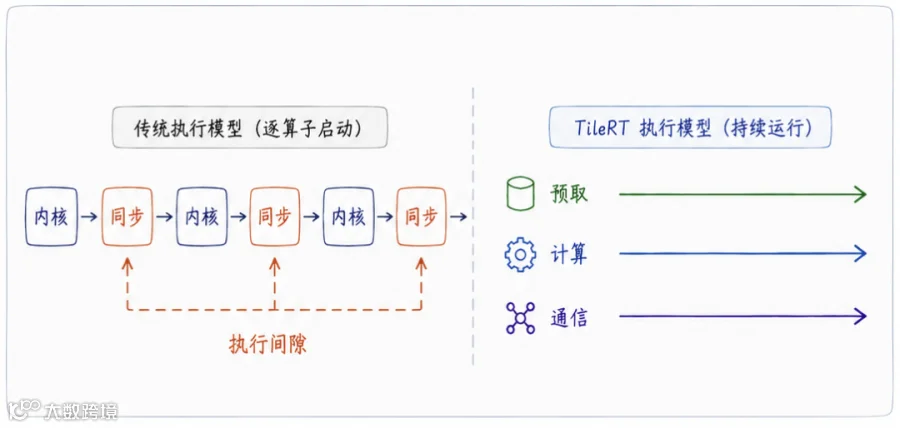
它才是这个速度档位下真正的敌人。
TileRT 的第一招,是让整条流水线常驻在 GPU 里持续流转,不停机,不换班。
这道工序还在算,下一批料的数据已经沿着管道提前送到了工位边上,算完无缝衔接,中间没有那个致命的空档。
第二招更狠,叫异构流水线协作,简单说就是给流水线重新分工。
GPU 里成千上万的计算单元,传统玩法是大家步调一致地齐步走。
搬运的,计算的,通信的,挤在同一个节拍里。
TileRT 把它们拆开,专门一批负责搬数据,一批负责算,一批负责通信,各干各的,又严丝合缝地咬在一起。
一台原本整整齐齐一起动的机器,被改造成了一个永不停转,各司其职的精密车间。
到这个尺度,你会发现一件事。
那些平时根本不会被人提起的小动作,在毫秒级运行时都无所谓,可一旦压到微秒级,它们居然也成了拖后腿的瓶颈。
快到极致的时候,每一个平时不起眼的环节,都得被重新设计一遍。
减重,抢跑,不熄火。
三件事不是各干各的,是 MiMo 模型团队和 TileRT 系统团队深度共创,协同进化。
最后组合在一起,巨无霸才能跑出超跑的圈速。
5
好了,终于到了聊这件事我认为最牛的地方。
行业里追极致速度的玩家,过去基本都走专用硬件路线。
自研芯片,定制架构,为了快,专门修一条磁悬浮。
效果是猛,但代价是整个生态都得搬家,门槛高到劝退绝大多数人。
那种快,只是少数人的快。
而 MiMo 这次,是在一个标准的 8 卡通用 GPU 节点上跑出来的。
没有定制芯片,没有专属赛道,就是市面上最常规的硬件。
靠模型和推理系统互相迁就,协同设计,硬生生在万亿参数上,调校出了专用硬件级别的速度。
别人是为了圈速去修专属赛道,它是把一台满载的巨无霸重型车,开上普通公路,跑出了赛道成绩。
更令人敬佩的是,MiMo 把 FP4 量化权重和 DFlash 模型参数,直接开源到了 HuggingFace。
圈速跑完了,调校手册也一并摊开了。
让大家都能沿着这条路线复现,改进,再继续往前推进。
快,第一次变成了一个可以被继承的东西。
尾声
在万亿参数这个尺度上,速度过了某条线,整个玩法就彻底变了。
第一,速度开始变成智能。
以前你问模型一个难题,等十秒才得到一个答案,对不对还得看运气。
现在同样这十秒,它能在后台能并行跑几十条推理路径,互相验证纠错,把经过验证质量更高的那条答案交给你。
时间一秒没多,但答案的质量变高了。
第二,AI 编程生产力提升。
AI 写代码的瓶颈,是 Agent 跑长程任务时,推理太慢了。
大部分时候都需要你等它,心流也直接断了。
现在速度拉起来之后,生产效率自然会翻倍。
第三,万亿模型介入实时决策的闭环。
量化交易的信号,支付的反欺诈,流畅的实时对话。
这些以毫秒计的场景,过去只能二选一,小模型够快不够聪明,旗舰够聪明又挤不进时间窗口。
而 1000 tokens/s,第一次把旗舰级的脑子,塞进了毫秒级的窗口。
再往前一步,落到手术辅助,医疗影像这种地方,分量就完全不一样了。
AI 每提前一秒完成病灶分析,留给医生的处置空间就多一分。
到这一步,速度就不是效率指标,是和死神抢时间的筹码。
说到底,人们对快的执念,并非是什么技术审美,是对时间的在乎。
机器每快一秒,人就多赢回一秒,就可以有更多时间,去做那些机器永远替代不了的事。
这,才是技术进步的意义。
既然你看到这里了,如果觉得不错,请帮我一键三连,转发给你的朋友,这真的对我很重要。
另外如果想第一时间收到推送,请将本公众号加个星标🌟
谢谢你看我的文章,祝你有财安康,我们下期见。