

随着FDA批准的AI医疗设备突破1000款、ChatGPT等生成式AI开始“看片问诊”,一个被忽视的问题浮出水面:这些看过千万张病历的AI,会不会像人一样“记住”某些患者的隐私?
这篇发表于Nature、题为《Disparate privacy risks from medical AI》的论文,首次用“患者级别”的显微镜审视了这个问题——结果发现,聚合数据里的“安全”可能是假象,而弱势群体正在承受不成比例的隐私风险。
为了便于大家理解论文内容,我们借助AMiner Research Labs的“播客生成”功能生成双人对讲播客,将难懂的“卡壳点”以深入浅出的方式娓娓道来。请点击下方收听。
(由 AMiner 「Research Labs」「播客」工具生成)
(由 AMiner「AI 阅读」一键生成论文网页辅助整理)
Paper
主要作者
这篇论文来自慕尼黑工业大学(TUM)、慕尼黑机器学习中心、帝国理工学院及波茨坦大学的跨学科团队。
Moritz A. Knolle为论文第一作者兼通讯作者(moritz.knolle@tum.de),就职于慕尼黑工业大学AI医疗与医学讲席教授组及慕尼黑工业大学医院。
Ben Glocker与 Daniel Rueckert贡献相等。
Georgios Kaissis就职于波茨坦大学哈索·普拉特纳数字工程研究所。
(图源:AMiner 人才画像)
Paper
研究背景:医疗AI隐私风险的“盲区”
医疗AI正在全球医院快速落地——它能读X光、辨肿瘤、预测住院风险,有望改善全球高质量诊断的可及性。但训练这些“AI医生”需要海量真实病历,而病历里藏着患者的年龄、疾病,甚至基因序列等敏感信息,这些都可能因为隐私攻击而遭到泄漏。
问题是:“如果有人在AI得到预测结果里‘套话’,能不能反推出某位患者的病历被它‘看过’”?这就是成员推断攻击(MIA):攻击者只通过模型的预测接口(比如输入一张X光,得到“78%肺炎概率”),就能猜中这张片子是否在训练集里出现过。对普通人这或许无所谓,但对罕见病患者,“你的数据被用于训练某款AI”本身就泄露了你患病的秘密。
现有隐私评估存在盲区,过去的研究只算“平均成功率”——把成千上万患者的风险混在一起求平均。好比说“某城市平均收入1万元”,掩盖了有人月入十万、有人只有三千的事实。
这种“平均叙事”存在三大致命缺陷:
聚合性——以往研究仅量化跨所有记录的聚合攻击成功率,掩盖个体风险;
平均化——风险在记录间被隐式平均,忽略患者常贡献多条相似记录的事实;
低分辨率——标准评估协议使用单一目标模型,无法反映个体记录或患者的攻击脆弱性。
近年来虽有突破:Carlini等人提出从第一原理出发的似然比攻击(LiRA),Zarifzadeh等人开发了低成本的鲁棒MIA(RMIA),但这些方法仍主要报告聚合成功率。Kulynych等人虽发现成员推断攻击的差异性脆弱性,但未深入到患者级别。
核心挑战始终未解:如何在患者级别精确量化医疗AI模型的隐私风险,识别高风险个体和群体,并开发可验证的缓解策略?
简而言之,精确到“患者个体”层面。

(由AMiner 「AI 阅读」一键生成论文网页辅助整理)
Paper
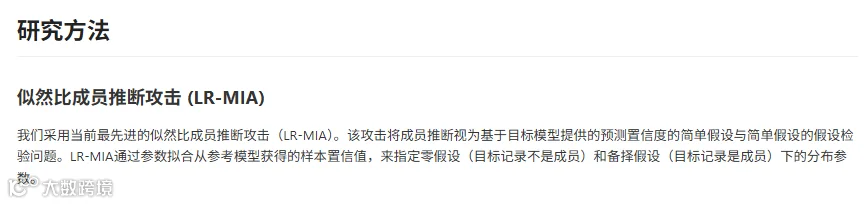
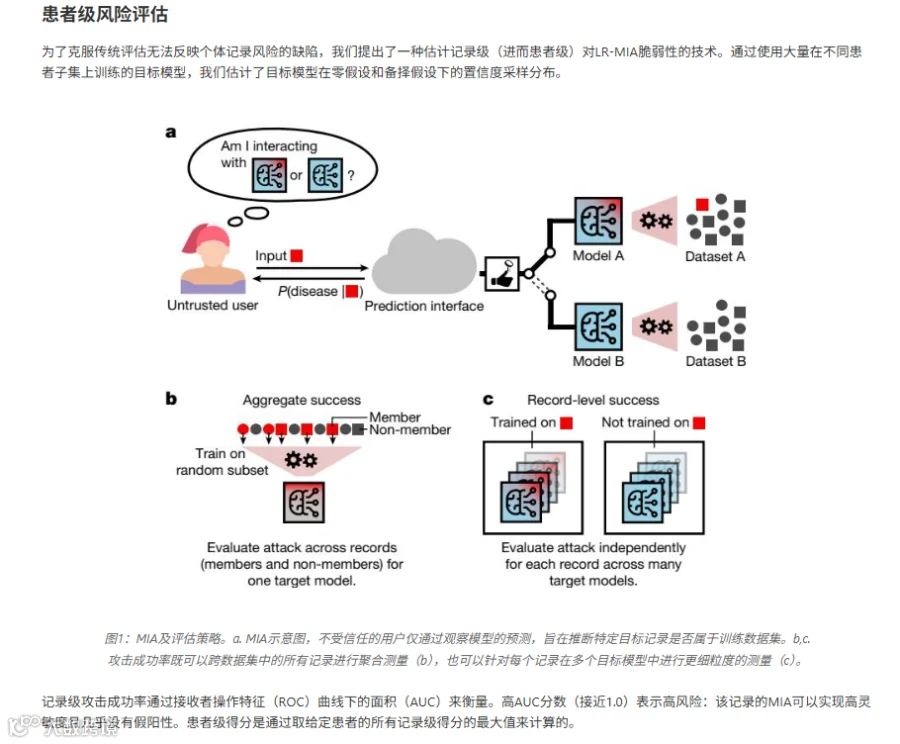
方法:似然比成员推断攻击+患者级别评估框架
研究团队设计了一套“患者级别测谎”方案,核心思路很像测谎仪:如果AI对某张片子的预测“过于自信”,那它很可能之前“见过”这张片子。
具体怎么做?
第一步:批量拷问AI
训练200个“克隆AI”,每个只在随机一半患者的数据上学习。对于目标患者A,有的克隆学过A的数据,有的没学过。 第二步:观察反应差异
给所有克隆看同一张片子,记录它们的“自信程度”(预测置信度)。学过A的克隆通常更自信——这就是“记忆痕迹”。
第三步:量化风险
用统计学方法算出:仅凭预测结果的差异,攻击者猜中“A被训练过”的概率有多高(AUC分数)。AUC=0.5是瞎猜,AUC=1.0是百发百中。
为什么选择这个方法?
传统评估只用1个AI测一次,只能得到“平均风险”。而200个克隆的“众测”能画出每个患者的专属风险曲线——就像体检报告里的个人指标,而非人口平均寿命。
(由AMiner 「AI 阅读」一键生成论文网页辅助整理)
Paper
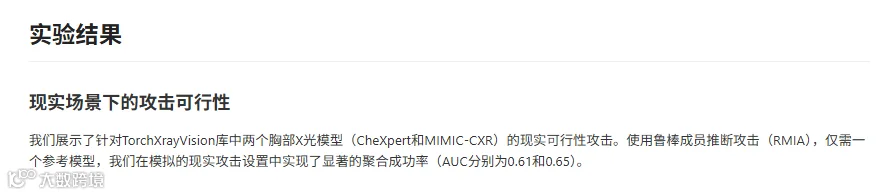
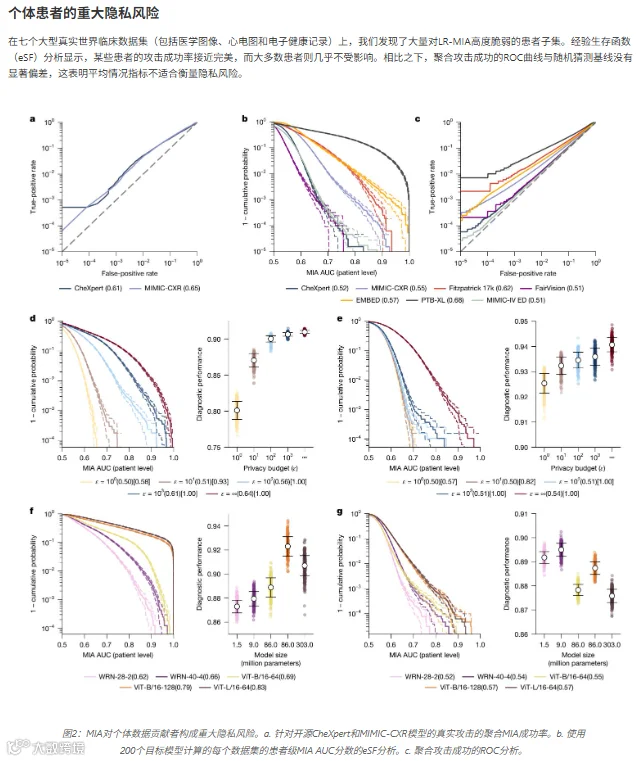
实验发现:医疗AI隐私风险的隐藏叙事
“平均安全”是最大谎言
论文测试了7个真实医疗数据集(涵盖X光、皮肤镜、心电图、电子病历等)。结果发现:
聚合视角:攻击成功率仅略高于抛硬币(AUC 0.51-0.68),似乎很安全;
个体视角:每个数据集都有一小撮患者的AUC逼近1.0——意味着攻击者可以几乎零误判地确认他们的病历被AI训练过。
这就像说“飞机事故率极低”,但对坠机乘客而言,死亡率是100%。平均指标对个体毫无意义。
AI越“聪明”,你越危险
团队训练了从WRN-28-2(150万参数)到ViT-L/16-64(3.03亿参数)的系列模型,发现MIA成功率(聚合和患者级别)随模型容量增加而增加。
对于Fitzpatrick 17k数据集,高脆弱性患者的相对比例随模型增大而数量级增长:WRN-28-2为0,WRN-40-4为万分之一,ViT-B/16-64为千分之一,ViT-B/16-128为十分之一。CheXpert数据集呈现类似趋势,尽管攻击成功率总体较低。
这证实了隐私风险与模型性能之间存在不可避免的权衡,特别是对于罕见疾病。模型越大、性能越好,越容易对某些“特殊病例”形成肌肉记忆。
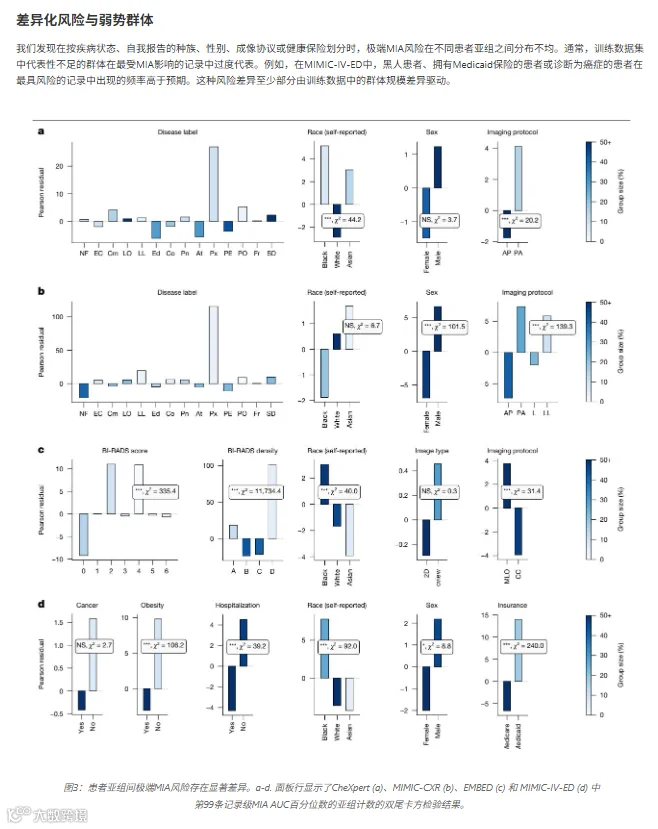
弱势群体被“精准狙击”
团队按疾病、种族、性别、保险类型等分组,检查“最脆弱的1%记录”中各群体的占比。结果发现了系统性不公:
MIMIC-IV-ED:黑人患者(+31%)、Medicaid保险患者(+126%)、癌症诊断患者(+18%)的高风险记录比预期更多;
EMBED:BI-RADS-4(可疑恶性肿瘤)记录高风险比例比预期高1,179%;BI-RADS-A(几乎全脂肪)和BI-RADS-D(极度致密)分别高90%和755%。
训练数据里越"少见"的群体,越容易被AI“记住”。这形成了一个恶性循环:弱势群体本就数据少→AI对他们诊断不准→他们更不愿贡献数据→数据更少→隐私风险更高。
差分隐私是“解药”,但“剂量”要够
团队测试了给AI训练加“隐私噪声”(差分隐私/DP)的效果。发现:
隐私预算ε越小(保护越强),患者风险整体下降;
但记录级保护不够:即使ε=1(强保护),部分患者仍超标;
必须升级到“患者级保护”:把同一个人的所有记录视为一个整体保护单元。
好消息是:近期研究表明,强隐私保护下模型性能损失可以很小——安全和准确并非不可兼得,关键看怎么做。
残缺信息也能“套出话”
更可怕的是,攻击者不需要完整病历。团队模拟了“信息不全”的攻击场景:
只知道年龄、性别、主诉、生命体征(急诊场景的基本信息)→ 部分患者仍被精准锁定;
只有心电图的一条导联信号(而非12条)→ 风险虽降,但高危患者依然高危。
这意味着,医院泄露的哪怕是最基础的脱敏数据,也可能成为拼图的一角。

(由AMiner 「AI 阅读」一键生成论文网页辅助整理)
Paper
结论:给医疗AI隐私“体检”的全新标准

(由AMiner 「AI 阅读」一键生成论文网页辅助整理)
Knolle等人的工作标志着医疗AI隐私审计从“聚合评估、平均风险”向“患者级别、个体风险”的范式转变,通俗来说,就是相当于给医疗AI隐私评估换了一套“体检标准”——从“群体平均指标”转向“每个人的心电图”。
它不仅彻底颠覆了“平均安全”的舒适幻觉,敲响了“大模型崇拜”的警钟,更将隐私风险与算法公平问题直接挂钩。黑人患者、Medicaid医保持有者、罕见疾病患者之所以面临更高攻击成功率,根源在于训练数据中的代表性不足。
这一框架不仅回答了“医疗AI隐私风险有多大”,更指明了“哪些患者群体最需要加强隐私保护”。解锁医疗AI的全部潜力,归根结底取决于患者是否愿意托付自己的数据。而这份信任的建立,不能只靠“平均来看很安全”的安慰剂来维持,而需要可验证、可审计、对每个人都成立的隐私保障。