
Datawhale干货
作者:邱汉宸,东南大学、阿里淘天
一、引言
2023 年是大语言模型落地应用的早期阶段,也是“年薪百万的提示词工程师”刷屏的一年。工业界曾一度将核心精力投射于提示词工程,导致市面上充斥着“万能 Prompt 模板”和“Prompt 圣经”。与此同时,方法论侧也在经历系统化的演进,从早期的少样本提示发展至思维链、思维树等高级策略[1],与依赖用户直觉的“盲提示(Blind Prompting)”划清了界限[2]。这是上半场的故事:人们在卷“怎么跟 AI 说话”。
然而依赖单次交互的“提示-响应”模式所带来的瓶颈也很明显。稍微深度用过 AI 的人都会发现,无论 Prompt 写得多巧,自己仍然充当“人肉缝合怪”的角色——把代码贴进去、复制结果、跑出错、把报错粘回来、改 Prompt、再来一遍。当应用于大型软件工程或复杂业务场景中时,这种瓶颈会被进一步放大。上述单轮交互模式无法支撑多步逻辑推理,亦无法自主维护工具状态或进行跨会话的记忆管理[3],使得人类研究者在实质上成为了维持系统运转的中转站。

图1: AI社区热点话题
转折发生在 2025–2026 年,三句话引爆了整个AI社区:
"I really like the term 'context engineering' over prompt engineering." —— Tobi Lütke, Shopify CEO[4] "You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents." —— Peter Steinberger,OpenClaw[11] "I don't prompt Claude anymore. I have loops running. My job is to write loops." —— Boris Cherny, Claude Code[12]
这三句话宣告了一场正在发生的范式迁移:人类从 Agent 循环的内部走向外部,从执行者变成设计者[14]。如果说AI 时代的上半场是“人以言驭物”,那么刚刚开启的下半场则正在全面转向“系统自我迭代”。本文将围绕这一技术演进脉络,深入盘点驱动这场范式重塑的四次核心浪潮。
二、AI 开发范式的演进
为了帮助大家直观的了解本节内容,我们可以将AI范式的演进历程,看作是一条沿着“教 AI 说话(Prompt Engineering) → 给 AI 资料(Context Engineering) → 帮 AI 建办公室(Harness Engineering) → 让 AI 自己打工(Loop Engineering)”脉络不断演进的AI“进化史”。
本节将带你深入复盘这四次核心技术浪潮。你将看到系统如何从早期单纯依赖单轮提示、需要人类时刻充当“人肉信息中转站”的原始形态,逐步演变为具备环境约束以及能自主修复与多轮迭代的闭环系统。
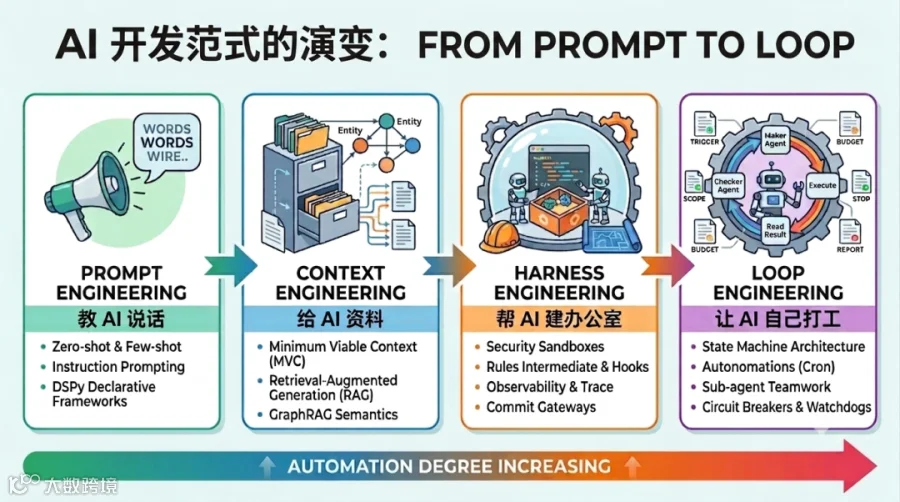
图2: AI开发范式的演变
1. Prompt Engineering —— 沟通艺术
这一阶段的核心问题是“如何跟 AI 沟通”。这一时期沉淀下来的经典方法包括 Zero-shot 与 Few-shot、Instruction Prompting以及 APE 自动 Prompt 搜索等方法[1]。
值得强调的是,正确的Prompt Engineering 并不是凭手感换词,而是一套包含“定义问题 → demonstration set → 候选 prompt → 实测准确率 → 成本/精度权衡 → 持续迭代”的工程方法论。与之相对的是只靠 trial-and-error、缺乏测试、对原理一知半解的Blind Prompting[2]。
为了将这套方法论彻底标准化,业界开始尝试把 Prompt 本身程序化。以 DSPy(Declarative Self-improving Python)、APE 为代表的声明式框架提出了一个关键转变:开发者不再手写指令字符串,而是声明输入输出的签名,再交给优化器自动搜索最优的Prompt与Few-shot组合,使Prompt 第一次从“人工手写”变成了“可编译、可学习的程序”[15]。当底座模型从 GPT-4 换成开源 Llama 时,只需一键重新编译,系统就能自动合成最适配新模型的 Prompt。
然而,无论是手写模板还是自动编译,纯粹的Prompt Engineering很快遇到了天花板,例如:受限于大模型上下文窗口无法承载海量上下文,缺乏记忆与工具调用导致无法多步执行,容错率极低需要不断人工介入纠错。更深层的影响是随之而来的“技术债”,应用规模稍大就需要维护成百上千条模板。一旦模型升级或业务微调,这些精心打磨的Prompt极易集体失效甚至反向退化。这种“越堆越多、越滚越重”的维护成本,决定了纯靠“写好提示词”根本撑不起规模化工程。
2. Context Engineering —— 对话管理
这一阶段的核心演进,在于将注意力从“如何写提示词”逐渐转向“信息怎么喂给模型”[5]。就像发邮件前,帮 AI 把附件、参考资料和背景画像都准备好。这一概念在 2025 年年中随着业界讨论进入主流视野,并被 LangChain 等框架确立为最佳实践[4]。
针对“信息怎么喂”这一命题,业界演进出了三套核心方法论:
轻量化装配(Minimum Viable Context, MVC):严控单次请求体积,只组合最必需的用户目标、检索结果与当前工具定义,避免信息冗余[5]。
知识图谱增强检索(GraphRAG):用实体关系网络取代传统的单纯向量相似度,将“段落检索”升级为“语义关联”,用以解决多跳推理、可解释性与合规审计等问题[5]。
即时检索(Just-in-Time 检索):在初始阶段仅维护资料的轻量引用(如路径或 ID),直至运行时才按需实时加载。Anthropic Skills 便采用了这种设计哲学[6]。
如果缺乏合理的上下文信息装配逻辑,极易陷入以下三种典型故障:
信息匮乏(Context Starvation):数据过少导致模型缺乏依据而产生幻觉;
信息过载(Context Overflow):灌入大量无关噪音而稀释模型的注意力;
上下文腐烂(Context Rot):窗口越填越满、模型响应质量反向退化[5][6]。
除了信息本身的装配,还有一个直接决定模型相应质量与成本的隐性维度——信息的排列顺序。
这背后依托的是大模型的提示词缓存(Prompt Caching)机制。模型会缓存已计算完毕的上下文前缀(KV Cache),如果下次请求的前缀完全一致,就能跳过最耗时的预填充(Prefill)阶段,直接命中缓存的部分。这使得计算成本通常能降低约 90%,延迟最高降低85%[16]。
然而,享受这一红利必须遵循前缀匹配不变性(Prefix Matching Invariant)的铁律。由于缓存是按字节从头进行哈希校验的,前缀中哪怕仅改变了一个空格,该位置往后的所有缓存就会瞬间集体失效,导致系统不得不退回全额计费的冷启动。
这种机制使得开发人员必须严格按照“从静到动”的原则将上下文进行分层排列:首先是确定性的工具定义,其次是冻结的系统提示,接着是相对稳定的历史对话,最后才是动态易变的消息。在实际开发中,这也带来了一个极其反直觉的设计要求:诸如“当前日期”、“当前用户”这类动态全局变量,绝不能直接插进开头的系统提示中(否则会直接击穿整段缓存),而必须作为普通消息挂在对话流的最末尾,以最大化保证前缀的稳定性。
那么,在实际线上业务中使用这套分层排列到底划不划算?我们可以通过对比“冷启动”与“缓存”在 N 次请求下的累计成本来算一笔账。
缓存并非免费午餐,参考阿里云百炼平台的计费规则[19],在隐式缓存模式下,首次创建缓存的 Token 仅按输入单价的 100%计费;此后 N-1 次请求若成功命中,每次仅需支付 20%的费用。

这意味着只要同一段前缀在被清理前成功复用第 2 次,即 N>3 即可产生净收益。高频迭代的智能体(Agent)之所以能以极低的边际成本运行,底气完全来自这种“前缀稳定 + 反复命中”的缓存经济学。
然而,当上下文装配与成本结构被优化到极致后,新的瓶颈又开始浮出水面:即使资料给得再足,大模型依然常常流于“纸上谈兵”——在面对代码报错、工具失败或物理环境异常时极易陷入困境。模型清晰地知道“目标是什么”,却缺乏执行与纠错能力。
3. Harness Engineering —— 系统约束
随着AI越来越多的应用于企业真实业务场景,人们开始意识到,仅仅把资料喂对不足以让大模型独立支撑起一个高可靠的工业级应用。对此,行业内逐渐确立了 Agent=Model+Harness 的研发范式——如果你不是在做底层模型,你就是在做 Harness(系统围栏/脚手架)[7][10]。
这一阶段的核心转变,是把模型之外的所有系统组件当成工程对象来设计。一个生产级别的 Harness 系统,主要由四大核心支柱构成:
环境资产与工具集:包括 Tools、Skills、MCP 服务,以及文件系统、安全沙箱和无头浏览器等底层基础设施。
控制与编排逻辑:负责子 Agent 派发、状态接力(Handoff)与模型路由。
规则中间件(Hooks):包含上下文压缩(Compaction)、代码静态检查(Lint)、提交网关(Commit Gate)等自动化钩子。
运行即可观测性:对 Trace 链路、Token 成本以及延迟(Latency)进行实时计量[7][8]。
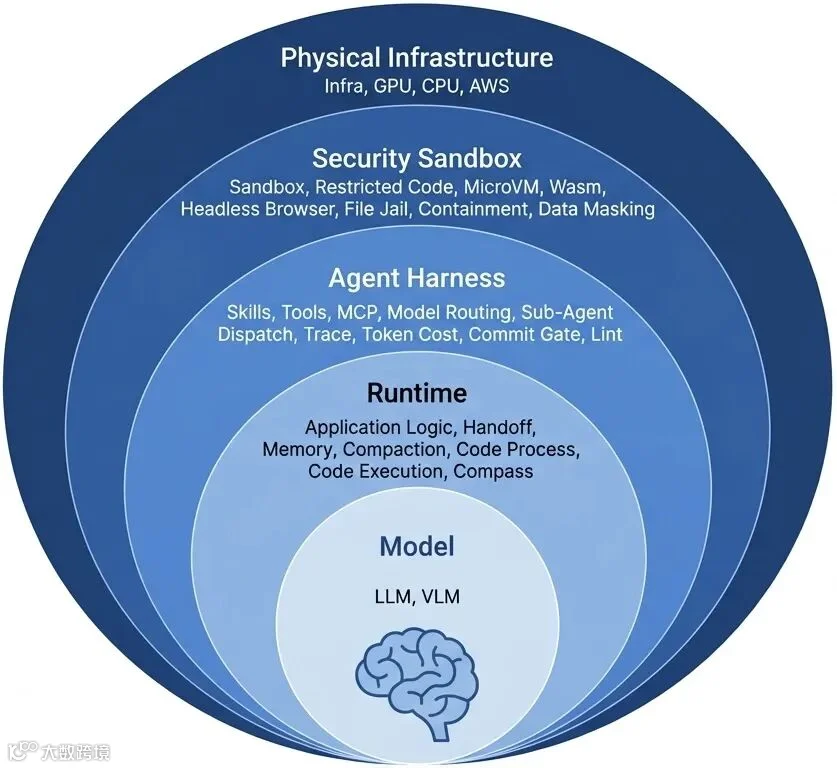
图3: Harness系统的信任边界划分
从信任边界来看,这些组件构成了物理基础设施 → 安全沙箱 → Agent Harness → 运行时 → 模型的层层防御结构。模型处于最核心、也最不可信的位置,其执行的每一个高风险动作,都必须经过外围 Harness 规则的解析与沙箱隔离,最终受制于基础设施的资源红线。
这套约束系统一旦缺位,代价将是灾难性的。2026 年 DataTalks.Club 平台发生了一起教科书式的事故[17]:由于研发环境缺乏沙箱隔离,且底层 AWS 没开删除保护,AI 编码工具Claude Code机械地执行了人类盲目授权的 terraform destroy 指令。短短几秒内,生产数据库、集群及备份被物理抹除,两届学生、近 200 万行核心数据瞬间清零。

图4: Harness缺位引发的灾难
值得反思的是,这场灾难只是由于Claude Code执行了一段看似合理的代码,并不存在“失控的 AI”。真正的问题在 Harness 上,系统缺乏危险操作的二次确认、缺乏基础设施的刚性红线,也缺乏Human-In-The-Loop的交互机制。
因此,设计 Harness 的核心思维,是从“预期行为”反推系统组件[7]:
想要持久状态,就配置 Filesystem 与 Git;
想要安全执行,就强制隔离 Sandbox;
想要对抗上下文腐烂(Context Rot),就引入 Compaction(压缩)与 Skills 渐进式披露机制。
围绕生产环境,业界进一步沉淀出八条“非妥协原则”[9]:
Model proposes — Harness executes:模型仅负责提议,Harness 才拥有最终执行权);
Every call returns a result:即使超时或拒绝,也必须结构化回传;
Risk changes the process:根据风险高低,动态匹配只读、草稿、外部写入三档权限;
Draft 与 Commit 分离:危险操作必须由人类进行显式确认;
Context is assembled, not dumped:上下文要分层装配,绝不能直接倾倒;
Long tasks have budgets:从步数、时间、Token、成本四个维度卡死单次任务预算;
Skills & Connectors 渐进式披露:先暴露名称,按需加载细节;
Recurring failures become Harness features:重复出现的偶发错误,必须沉淀为 Hook 或校验器。
上述原则落到自动化Code Review中,便形成了由 CodeRabbit 提出的由硬到软、层层收窄的分层拦截流水线[18]:
确定性规则层(如 Semgrep):毫秒级,近乎零成本,负责拦截明显的语法和安全红线;
策略网关层(如 OPA):对基础设施配置(IaC)进行刚性阻断,拦截结构性错误;
AI 审查层:分钟级,消耗 Token,结合代码库上下文拦截业务逻辑错误;
人类终审:最慢最贵,但判断力最高,只负责最高阶的架构与战略决策。
利用这套漏斗模型,约 80% 的低级错误在最便宜的硬规则层被拦下,15% 的复杂逻辑交给AI 层,人类最终只需要审核剩余 5% 的核心决策。
这套范式在工程上落地为 Skill Issue框架[18],即当 Agent 线上表现不佳时,团队的第一反应不再是责怪模型,而是排查 Harness 代码。Terminal Bench 2.0 的实证印证了这一逻辑:同一款原生大模型,在不改变权重的前提下,仅通过改写 Harness 约束,其 Benchmark 排名便从 30 名提升至 前五名[7][10]。这表明,当下模型“能做的事”与在生产环境中“做成的事”之间,差距几乎全由研发团队所提供给大模型的 Harness水平决定。
4. Loop Engineering —— 自主迭代
如果说 Harness 工程是为大模型搭建安全的系统围栏,那么 Loop Engineering则赋予了系统自主迭代的能力。随着系统从静态的、由人类单次触发的工具,演进为具备独立运行周期的自主工程,大模型在系统中的定位开始转变为受控的“子程序”。在这一阶段,系统的控制权交给了由状态机和多 Agent 编排构建的闭环架构。Loop Engineering在工程上可以用一个公式来概括:Loop=Cron+决策器。 人类的职责也随之从直接编写提示词或控制流,走向循环系统架构设计师[14]。
在架构设计上,成熟的循环系统都遵循“机制(Mechanism)与策略(Policy)分离”的哲学。底层平台作为 Harness 提供基础机制(如定时器、工作区隔离),而具体的控制策略(如触发时机、子Agent数量)则由架构师根据业务逻辑进行独立配置。这种设计哲学使人类能够真正抽离于执行循环之外。
从整个技术路径的演进来看,业界对Loop的定义经历了以下几个阶段[12]:
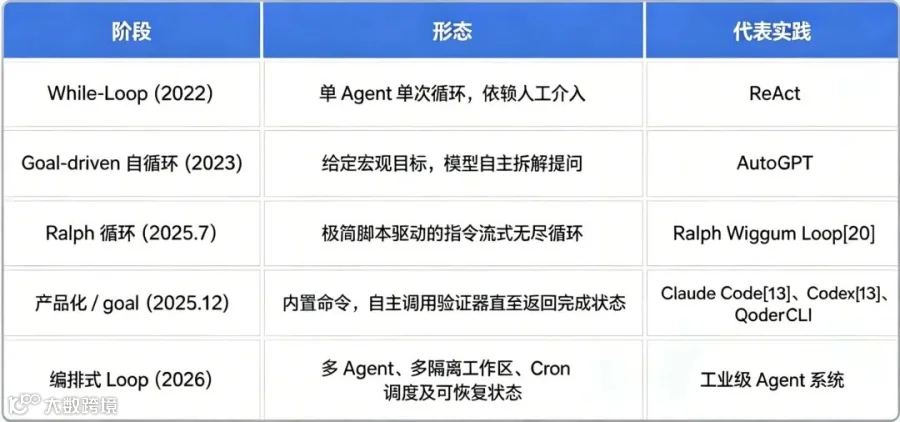
图5: Agent Loop技术路径的演进
根据演进特征,当前的 Loop 成熟度通常可以划分为三档:
第一档是 Open Loop(开环):模型自行判断并输出
done即告结束,通常仅适用于 Demo 演示;第二档是 Closed Loop(闭环),每轮执行都必须强制通过单元测试、Lint 检查或自动化 Review,达到了生产级交付标准;
第三档是 Review Loop(评审环),由后台常驻的异步审查 Agent 在新鲜上下文中提供持续反馈,是解决长会长任务的最优解[12]。
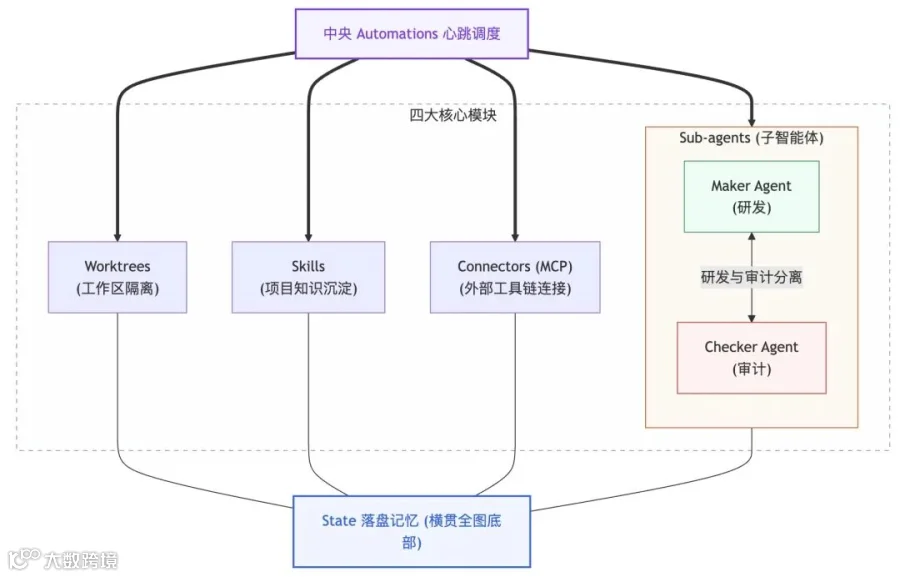
图6: Loop Engineer系统架构框图
无论是哪一种成熟度,一个工业级自主循环系统的底层,都必须由“五件套 + 一个记忆”构成:
Automations(自动触发层):提供心跳机制,如 Cron 表达式、自定义定时器或 GitHub Actions 等。
Worktrees(并行隔离工作区):为每个子 Agent 分配独立的隔离环境,防止并发代码相互覆盖。
Skills(技能树资产):将项目独有的领域知识固化为配置或规范,避免循环每次重新摸索。
Plugins / Connectors (MCP):赋能标准连接器,让循环具备开 PR、发 Slack、同步项目管理看板的真实动作。
Sub-agents(多 Agent 编排):实行“研发与审计分离”的核心设计(自己给自己改作业必然放水),让写代码与审代码由不同的 Agent 承担。
State 文件(落盘记忆):由于模型天生缺乏状态,系统的运行进度与记忆必须实时持久化落盘。
诸如 Claude Code 和 Codex 等主流Vibe Coding工具,在产品形态上都完整实现了这套“五件套+记忆”的基础构型[13]。
然而,为了防止基于自主循环的工具退化为失控的死循环,整个系统必须在策略层强制执行一套循环协议(Loop Contract),严格约束以下六个维度[12]:
TRIGGER(触发条件,如:每 15 分钟 / PR 评论 / CI 失败)
SCOPE(作用范围,如:仅限特定仓库 / 仅处理自己提交的 PR)
ACTION(具体行为,如:运行测试 / 自动修复 Lint 错误)
BUDGET(预算红线,如:单次最多衍生 3 个子 Agent / 50k Tokens / $5 成本)
STOP(停止条件,如:测试全绿 / 达到 10 轮上限 / 预算耗尽)
REPORT(上报通道,如:异常时投递至 Slack 频道)
在工程落地时,合同里的 BUDGET(预算)与 STOP(停止条件)会直接固化为两道硬性约束:
熔断器(Circuit Breaker):配置连续失败次数上限(
max_consecutive_failures)。一旦连续报错 N 次,系统立即跳闸并回退代码,将当前运行栈日志打包成工单转交人工;同时加设墙上时间(max_runtime_min),超时无条件熔断。看门狗(Watchdog):专防由于退避策略缺失导致的自旋死循环。系统利用一个独立于主异步线程的外部进程监控 CPU,一旦检测到占用率满载且长时间无 I/O 交互,越过应用层直接发送
SIGKILL信号强杀进程并回收资源。
当这一整套工程防线与自动化流水线串联起来时,便形成了标准的自主闭环:
AI 编码 → 沙箱测试 → 日志自动回灌 → AI 修复 → CI 绿标通过 → 自动发起 PR全流程无人类介入,高频迭代的 Agent 得以在安全的边界内日夜运转。
三、AI 工程范式的对比
若将上述四个阶段的演进路径抽象为数学表达,可以清晰地看出两种截然不同的架构范式。
早期阶段核心关注单次推断的质量,其范式可表达为:
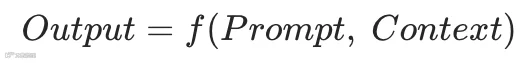
该模型下,输出的可靠性完全取决于输入质量(提示词的润色与上下文的装配)。而在当前的系统级智能体架构中,范式已转化为基于状态机和自愈机制的循环:
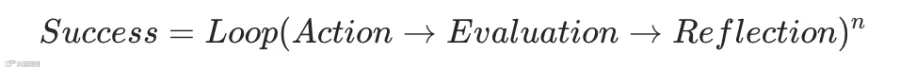
此时,任务的最终成功率不再由单次推断决定,而是取决于循环迭代的深度、验证器的严密性,以及系统在多轮执行中的状态自愈能力。
为了更全面地对比这四种工程范式,下表从核心挑战、技术栈和人类角色的转变等维度进行了系统梳理:
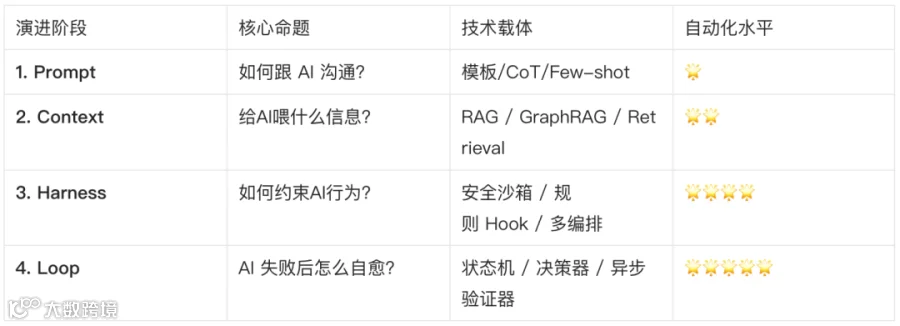
上述四种范式在实际落地中并非互斥或替代关系,而是层层组合、向外扩展的嵌套结构:Prompt ⊂ Context ⊂ Harness ⊂ Loop。Prompt 决定了模型对单一指令的理解基础;Context 决定了该指令所需的动态信息输入;Harness 充当每次执行时的系统级围栏,保障单步动作的安全和规范;而 Loop 则是在最外层动态调度 Harness、驱动状态不断迁移的调度引擎[8]。
四、Loop Engineering 对工程实践的影响
Loop Engineering概念能在工业界引发巨大的反响,主要源于以下三点技术驱动力:
为缓解幻觉提供了可工程化的收敛路径:基于大语言模型的底层概率预测特性,单次生成的错误难以完全避免。对抗幻觉的有效手段不再是调优提示词,而是依赖
Text → Code → Execute → Read Result → Self-correct的闭环控制[10][13]。自动化控制范式的升级:传统的自动化脚本通常在遇到单次异常或 Bug 时中断运行。而具备循环工程特征的自动化系统则具备容错、自愈与动态自适应特征。例如,现代化命令行 Agent(如 Claude Code 的
/loop)能够根据任务执行状态,在编译运行期(分钟级轮询)与常态挂起期(小时级轮询)之间动态调整状态检查间隔[12]。基础设施的产品原语化(HaaS 化):主流工程工具已开始将这套能力固化为标准组件。Claude Code 内置了
/loop指令、SKILL.md 规范与 Subagent Team编排;Codex 提供了自动化面板与多 Agent 配置规范(.codex/agents/)。这种将Worktree + Skills + Connector + Subagent + State封装为标准底座的模式,在业界被定义为 “Harness-as-a-Service (HaaS,脚手架即服务)”[10]。
五、开发者如何拥抱 Loop Engineering
在Loop Engineering范式下,开发者的生态位正在逐渐转向更高阶的系统架构角色。这一角色可定义为 Loop Designer(循环设计师),其核心职责聚焦于以下三点:
定义终止边界(Goal & Verifier 设计):负责编写 VISION.md(全局愿景文件)、完工条件、测试用例与评估矩阵。[13]。
维护工具链与领域资产(Tooling & Skill 配置):配置安全沙箱、对接 MCP 连接器、将高频重用的工程逻辑固化为命名的 Skill 资产,避免系统在单次执行中重复产生提示词开销[10][13]。
设计安全断路器(Human-in-the-Loop & Budget Guard):设定步数、时间、Token 消耗以及资金成本等多维约束,在出现异常时进行人工干预。
同时,也鼓励大家从今天就开始上手,复现一个简易的Loop Agent,以下是复现周计划:
Day 1:写一份 AGENTS.md(< 60 行,每行都对应你踩过的坑);
Day 2:把一个反复重复的 prompt 沉淀成 SKILL.md;
Day 3:装一个 Hook:跑 typecheck / lint,错了把报错回灌;
Day 4:上 Ralph 循环:while :; do cat PROMPT.md | claude; done(务必在 worktree 或 sandbox 里跑);
Day 5:把 maker 和 verifier 拆成两个 subagent;
Day 6:补齐 Loop Contract——TRIGGER / SCOPE / BUDGET / STOP / REPORT 五件齐;
Day 7:上 cron 或 /loop 30m,把它真正放到无人值守模式。
六、总结与思考
AI 时代上半场,我们研究"语言的艺术";下半场,拼的是"系统工程的能力"。未来的高薪人才,不是那个懂得给 AI 说"请"和"谢谢"的提示词专家,而是那个能为 AI 搭一间完美办公室、写一套靠谱循环、让 AI 自己加班到深夜的循环设计师——而他白天,在思考下一个值得自动化的问题。
最后,想与大家分享三个问题:
第一,你今天还在手动重复哪些事,它能在本周变成 SKILL.md?
第二,如果你的 AI 半夜在 Loop 里失败 50 次,你的系统会及时把你叫醒,还是任由它把 Token 烧光?
第三,当 Loop 替你写完 90% 代码时,你打算如何保住自己对系统的理解力?
欢迎在评论区分享你的心得!
参考资料[1] Lilian Weng. Prompt Engineering. 2023. https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/[2] Mitchell Hashimoto. Prompt Engineering vs. Blind Prompting. 2023. https://mitchellh.com/writing/prompt-engineering-vs-blind-prompting[3] Lilian Weng. LLM Powered Autonomous Agents. 2023. https://lilianweng.github.io/posts/2023-06-23-agent/[4] Tobi Lütke. I really like the term 'context engineering' over prompt engineering. 2025. https://x.com/tobi[5] Michael Hunger. Why AI teams are moving from prompt engineering to context engineering. 2026. https://neo4j.com/developer-blog/[6] Tomás Murúa. Context engineering vs. prompt engineering. 2026. https://www.elastic.co/search-labs/blog[7] Vivek Trivedy. The Anatomy of an Agent Harness. 2026. https://www.vivektrivedy.com/[8] Sergio Paniego & Aritra Roy Gosthipaty. Harness, Scaffold, and the AI Agent Terms Worth Getting Right. 2026. https://huggingface.co/blog/harness-scaffold-ai-agent-terms[9] Tort Mario. AI Agent Best Practices: Production-Ready Harness Engineering. 2026. https://medium.com/[10] Addy Osmani. Agent Harness Engineering. 2026. https://addyosmani.com/blog/agent-harness-engineering/[11] Peter Steinberger. You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents. 2026. https://x.com/steipete[12] Yash Thakker. Loop Engineering: How to Design Coding Agent Loops That Run While You Sleep. 2026. https://www.explainx.ai/[13] Addy Osmani. Loop Engineering. 2026. https://addyosmani.com/blog/loop-engineering/[14] Sydney Runkle. The Art of Loop Engineering. 2026. https://www.langchain.com/blog/the-art-of-loop-engineering[15] Stanford NLP. DSPy: Programming not prompting Foundation Models. 2024. https://dspy.ai[16] Anthropic. Prompt Caching. 2024. https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching[17] Gaurav Garg. Claude Code Deleted a 2.5-Year AWS Production Database With One Command: The Full Incident Report. 2025. https://gauravai.in/blog/claude-code-deleted-aws-production-database[18] Brandon Gubitosa. What is harness engineering for AI code review & oversight. 2026. https://www.coderabbit.ai/guides/harness-engineering-ai[19] Aliyun. Model Studio Context Cache. 2026. https://help.aliyun.com/zh/model-studio/context-cache[20] Geoffrey Huntley. Cursed:The unintended consequences of AI code generation. 2025. https://ghuntley.com/cursed/


