

▐ 摘要
随着大型语言模型(LLMs)的快速发展,高资源语言(如英语、中文)的性能已接近饱和,但由于训练数据有限、机器翻译噪声和不稳定的跨语言对齐,中低资源语言(例如东南亚国家中的泰语、部分菲律宾语;南亚国家巴基斯坦的乌尔都语等)的性能仍然显著较低。提高大模型在中低资源语言表征上的检索和推理性能,能够有效提升系统对这些国家用户搜索意图识别和广告召回的能力。
为此,我们引入一种大型语言模型的语言鲁棒锚定系统(LiRA,Linguistic Robust Anchoring),这是一个训练框架,能够在低资源条件下稳健地改进跨语言表示,同时联合增强检索和推理能力。LiRA包含两个模块:(i) Arca(锚定表示组合架构),通过基于锚点的对齐和多智能体协同编码,将低资源语言锚定到英语语义空间,在共享嵌入空间中保持几何稳定性;(ii) LaSR(语言耦合语义推理器),在Arca的多语言表示基础上添加一个具有语言感知能力的轻量级推理头,并引入局部Lipschitz连续性从理论上提供优化界限,通过一致性正则化统一训练目标,从而增强跨语言理解、检索和推理的鲁棒性。
我们还构建并发布了一个覆盖五个东南亚语言和两个南亚语言的多语言广告商品检索数据集Laz-Retrieval。在低资源基准测试(跨语言检索、语义相似度和推理)上的实验表明,在少样本和噪声放大设置下,我们的模型在公开数据集和广告商品检索数据集上取得了一致的性能提升和高度的鲁棒性;消融实验证实了Arca和LaSR两个模块的贡献。
论文:Toward Robust Multilingual Adaptation of LLMs for Low-Resource Languages
作者:Haolin Li*, Haipeng Zhang*, Mang Li, Yaohua Wang, Lijie Wen, Yu Zhang, Biqing Huang (*Equal Contribution)
论文地址:https://arxiv.org/abs/2510.14466
1. 背景
- 概览:本项目旨在提升跨语言检索系统的性能与稳定性,重点解决低资源语种条件下的检索准确率不足、翻译噪声引入偏差以及评测体系不统一等问题。项目围绕跨语言语义对齐、翻译质量建模、鲁棒性诊断等方向展开,从而构建一个可扩展、可解释且稳定的跨语言检索框架。
- 业务目标:Lazada业务场景中,东南亚用户对非英语内容的多语言检索需求激增,但现有系统在低资源语种(如泰国、越南等)上与高资源语种有域差,且对查询集合的翻译噪声导致关键内容漏检。本任务通过轻量化语义对齐模型与动态翻译质量校准机制,在保障检索速度的前提下将低资源语种召回率提升,支撑电商平台等业务在东南亚语种场景的精准内容分发与用户体验优化。
- 学术目标:在跨语言信息检索领域,现有研究多聚焦高资源语种对(如英-中),而低资源语种因平行语料稀缺、语言结构差异大导致语义对齐失效,且传统基于翻译的检索范式易受翻译噪声干扰。本任务提出融合多粒度语义对齐与翻译质量感知的联合建模框架,通过设计可微分的鲁棒性诊断模块量化翻译偏差影响,并构建统一的多语言评测基准(涵盖nDCG@k与Recall@k等指标),为低资源跨语言检索提供理论可解释性与方法论创新。
2. 方案:语言鲁棒锚定框架LiRA
2.1 总体方案
2.1.1 目标
LiRA框架的核心目标是解决大型语言模型(LLMs)在低资源语言上性能显著落后于高资源语言的根本问题。具体而言,我们的方案旨在通过理论保证的表示对齐,实现三个关键目标:(1)将低资源语言的语义表示稳健地锚定到英语语义空间,克服预训练数据长尾分布带来的偏差;(2)在保持共享嵌入空间几何稳定性的同时,减少机器翻译引入的语义漂移和噪声;(3)通过统一的训练目标,同步增强跨语言检索、语义相似度计算和复杂推理任务的性能。与现有方法不同,LiRA不仅关注经验性能提升,还建立了严格的理论基础,为表示的完整性和下游任务的稳定性提供可证明的保证,确保模型在实际应用场景中具备鲁棒的跨语言能力。
2.1.2. 总体框架
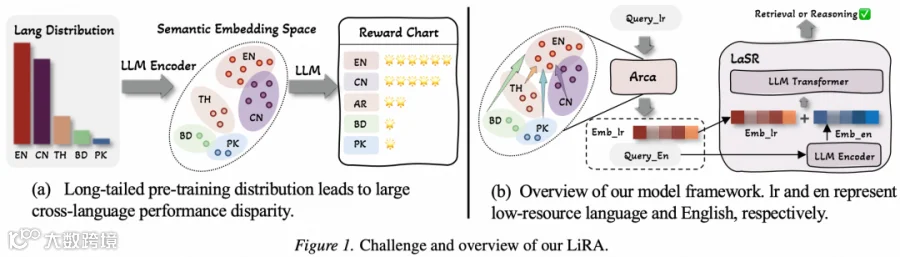
LiRA采用双模块协同架构,如图1b所示,将复杂的跨语言适应问题分解为表示锚定与语义推理两个互补阶段。第一阶段Arca(锚定表示组合架构)负责语义空间对齐:给定一个低资源语言输入 ,Arca通过双路径表示机制处理信息——锚定路径 直接将低资源语言映射到英语语义空间,而翻译路径 处理其英语翻译 。这两个路径通过critic-actor交互机制和特征锚定技术实现几何一致性,其中Translation Critic评估候选翻译的语义/情感/语用质量,Embedding Critic监督特征空间对齐,而Actor模型融合两类批评信号进行最优决策。第二阶段LaSR(语言耦合语义推理器)在此基础上增强推理能力:它将多语言编码器产生的 与英语编码器产生的 通过轻量级Transformer融合,生成统一的语义表示。为确保训练稳定性,LaSR引入两个FIFO队列机制——CorrQueue用于小批量下的相关性目标优化,DocQueue支持带语言内负例的列表式nDCG优化。这种分层架构设计使LiRA能够同时继承LLMs在英语上的强大能力,并有效地将其迁移至低资源语言,实现跨语言性能的全面提升。
2.2 理论基础
2.2.1 前置定义
设定:令 表示低资源语言(LRL)句子空间, 表示英语句子空间。对于任意输入 ,翻译器 生成 ,而 表示与 语义分布完全匹配的完美翻译。我们考虑两条表示路径:锚定映射 将LRL句子直接嵌入到"英语"语义空间,英语编码器 处理英语句子。我们将两条路径拼接为跨语言表示 ,由下游评分器 用于检索或推理任务。我们的目标是证明 的忠诚度并提供可量化的误差边界。
假设1 (语义锚定):对所有 ,锚定路径与翻译路径之间的不匹配是有界的:
假设2 (翻译保真度):令 为潜在语义变量,条件分布为 和 。翻译器 以 的KL散度保持语义:
定义1 (RKHS表示):令 表示英语句子编码器。我们将 建模为语义分布 在由正定核 诱导的RKHS 中的核均值嵌入(KME):
该核嵌入将任何概率测度 映射到由 指定的RKHS中(即 )。对于有界输入,核满足 ,其中 为常数。
定义2 (数据局部Lipschitz连续性):在有限离散域上,任何编码器都具有(局部)Lipschitz常数。具体而言,在数据集 上,我们在 处(邻域半径 )定义数据局部Lipschitz常数:
其中 表示基于token编辑距离的邻域(实验中通常使用 )。我们还报告经验 -分位数 ,其中 是分位数级别; 是 在 上的 -分位数。
2.2.2 核心理论与证明
定理 (表示偏差):在假设1-2和定义1-2下,令 为最优英语表示, 为框架输出,则: