

最近 Google Research 发现了一条简单粗暴提示词技巧。
想要让Gemini、GPT-4o、Claude 或者 DeepSeek 这些主流模型表现得更好,只要把输入问题重复一遍,即直接复制粘贴一下,就能在非推理任务上提升准确率,最高甚至能提升 76 个百分点。
为什么人类做复读机就能提高大模型的准确性?↓
https://arxiv.org/pdf/2512.14982
答主@AI解码师
跟人是一样的,别人跟你说了一大段话,还没完全听完就开始答复,结果对面又重复了一遍,你发现之前答的是错的,是不是都有过这个经历。
展开说说。
先说说什么是因果盲区?
现在市面上的 LLM,不管是 Gemini、GPT 还是 Claude,底层都是因果语言模型(causal LM)。这类模型处理输入的时候,是从左往右一个 token 一个 token 读的。关键来了:每个 token 只能「看到」它前面的 token,看不到后面的。
什么意思?
举个例子。假设你给模型一个 prompt:
以下是50个人名:张三、李四、王五……(省略47个)……请问第25个人名是谁?
模型在读到「张三」的时候,它根本不知道你后面要问「第 25 个是谁」。它读到第 25 个名字的时候,也不知道这个名字对你有什么特殊意义。等它终于读到问题」请问第 25 个人名是谁」的时候,前面那 50 个名字的信息早就在注意力机制里被稀释了。
这就是因果盲区——模型在处理前面内容时,对后面的任务要求一无所知。

那为什么复制粘贴一遍就能解决?
当你把整个 prompt 重复一次,变成的时候,情况就不一样了。
第二遍 prompt 出现时,模型已经完整读过第一遍的所有内容。这时候,第二遍里的每一个 token 都能「看到」第一遍的全部信息。问题和选项之间的对齐问题,被物理层面解决了。
说白了,就是是在用最笨的方式,强行让模型把该看的信息都看一遍。
在做一些信息提取的项目时,其实无意中用过类似的方法。
当时有个任务是从一段很长的对话记录里提取关键实体。一开始模型老是漏掉对话后半段的信息,我试了各种 prompt 技巧都不太行。后来我把对话内容在 prompt 里放了两遍,效果立刻好了一大截。
当时我还以为是」强调」起了作用,现在看来,本质上就是在弥补因果盲区。

但这个方法也不是万能的。
第一,只对「非推理任务」有效。
论文里明确说了,对于需要 Chain-of-Thought 的推理任务,重复 prompt 的效果很一般。为什么?因为推理任务本身就要求模型「think step by step」,模型在生成推理链的时候会自己复述问题、检视条件,相当于内部已经做了类似的重复操作。
第二,prompt 太长的时候要小心。
重复意味着输入长度翻倍。虽然论文说这部分工作集中在 prefill 阶段,可以高度并行化,对生成阶段的延迟影响不大。但如果你的 prompt 本身就很长,prefill 阶段的压力还是会上去的。论文里提到 Claude 系列在处理超长 prompt 时就出现了延迟上升。
第三,不能修复 prompt 本身的问题。
如果你的指令本身就写得稀烂,重复一遍只会让模型更坚定地执行错误的理解。重复只是增强上下文覆盖,不会自动纠正内容质量。
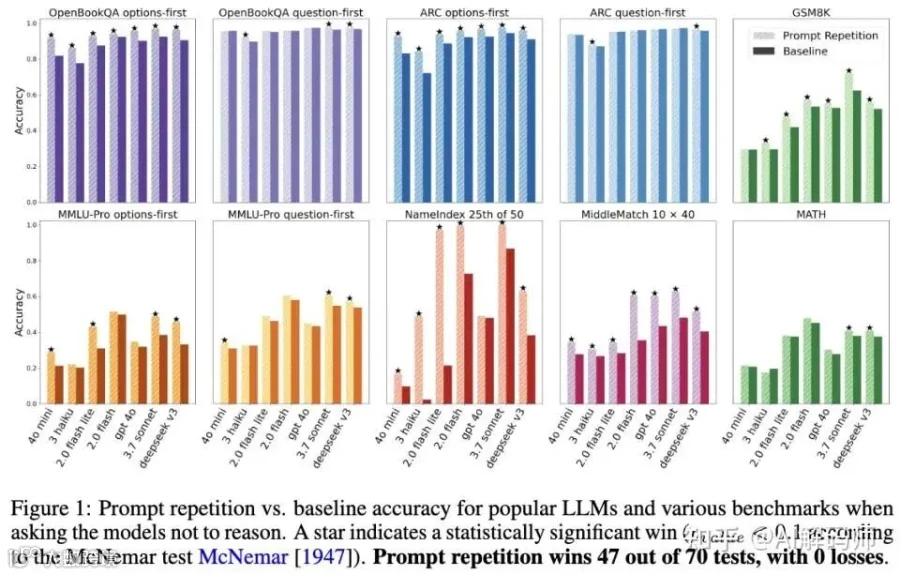
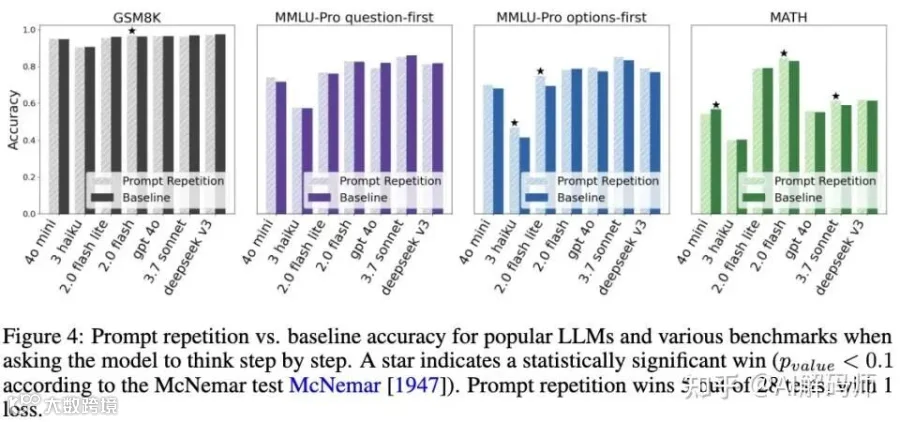
在这里我们可能得重新看待过去几年的 prompt engineering 的发展路径了。
从 Chain-of-Thought 到 Few-shot Learning,再到后来流行的「情感操控」(告诉模型写不好代码就扣工资),大家一直在用人类的心理逻辑去」操控」模型。
但有时候问题根本不在「怎么让模型想得更多」,而在「怎么让模型看得更全」。
这是两个完全不同的问题。
前者是在假设模型的能力够用,只是需要被激发。后者是在承认模型的架构有结构性缺陷,需要被绕过。
在扯的远一点,未来我们可能需要:
架构层面,未来的模型可能会在设计上解决这个问题。比如引入部分双向注意力,或者内置」重读机制」,让模型在处理 prompt 时自动进行信息对齐。这样就不需要用户手动复制粘贴了。
应用层面,AI 产品可以在后端自动判断任务类型。对于非推理类任务(选择题、实体提取、格式识别等),自动重复 prompt;对于推理类任务,保持原样。用户完全无感,但效果实实在在。
如果有在做选择题判断、信息检索、实体提取这类任务的朋友,可以试试这招。不需要任何复杂的 prompt 模板,就是把你的问题复制粘贴一遍。
可能比你研究半天的 Chain-of-Thought 还管用。

知友讨论
@momo:
就是做阅读理解或者完形填空的时候,老师说的,带着问题去看文章
@Ser Spencer:
那我为什么不直接prompt:“在下列50个人名中找出第25个人名……”
@某科学的电脑配件:
其实是因为现行的注意力机制不是全连接的,前面的位置看不到后面的token。把问题重复一遍相当于手动让所有位置都可视了
@吴豪:
你去面试,主考官一个问题重复问你,你也知道估计前面的回答方向不对
@火炎:
重复带来的是全局平滑的稀释
@木易杨浅疯狂:
这个技巧不同模型的反应不一样,比如GLM4.7重复1~2遍的是错误答案,直到重复3次时才能正确输出
阅读更多
AI Infra 团队是否应该有算法?🚀 AI 产品扶持计划:
知乎为AI产品提供定制宣发支持,了解/报名请戳:知乎「AI 新品非正式发布现场」扶持计划
🚀 知乎 AI 社群:
如果你是泛 AI 爱好者,对 AI 资讯感兴趣,并愿意认真测评、为开发者反馈真实意见或交流沟通。欢迎扫码加入知乎 AI 社群↓,我们将不定时送上 AI 热点问答和产品测试活动。

知乎AI交流群
让一部分开发者先走起来
🚀 知乎科技账号正式登陆 X:
👉 https://x.com/ZhihuFrontier,聚焦「技术 × 观点」的跨语境对话