
本文来自 LMSYS/SGLang Team,原文标题:Agent-Assisted SGLang Development: An Initial Exploration,以下为全文翻译。
SGLang 的开发已经越来越不只是孤立的代码改动。同一个仓库现在同时覆盖 LLM serving、分布式运行时、GPU kernel、diffusion pipeline、模型特定执行路径,以及生产事故处理。过去,很多工作流都依赖单个开发者的经验记忆:如何启动某个模型,如何阅读一份 profile trace,调试 CUDA crash 时第一条日志应该加在哪里,或者一个性能 PR 应该包含哪些 benchmark。随着 Agent 工具成熟,这些经验可以被转化成可执行的 SKILL.md 文件、脚本、benchmark 契约和 review loop。
围绕 SGLang 的 Agent 开发,一组面向 LLM 和 diffusion 工作的技能已经出现:
-
SGLang .claude/skills维护在 SGLang 仓库内部,记录仓库级开发工作流,例如 CUDA crash debugging、kernel integration、tests、CI、profiling、production triage 和源码树约定。 -
SGLang diffusion .claude/skills聚焦 diffusion 相关工作流,包括新增 diffusion 模型、benchmark 和 profiling denoise 路径、调优性能选项,以及验证量化 pipeline。 -
BBuf/AI-Infra-Auto-Driven-SKILLS 覆盖跨框架 serving benchmark、容量规划、profile 和 pipeline 分析、模型计算模拟、SGLang human-style review、生产事故 triage、SGLang 和其他开源推理框架的 SOTA loop,以及模型 PR 历史。 -
kernel-design-agents 是 KDA 项目,也是 MLSys 2026 FlashInfer Kernel Contest 的获胜方案。 -
BBuf/KDA-Pilot 将 KDA 风格的 agent kernel 工作流应用到 SGLang。它公开的 B200 diffusion summary 目前追踪了 10 个 SGLang kernel task。大多数行来自 KDA-Pilot 的公开 benchmark ledger,而 residual_gate_add使用的是原始任务 baseline 变动后,已合并 SGLang integration PR 报告的 B200 speedup。KDA-Pilot 派生工作现在已经进入三个 SGLang integration PR。
把这些努力放在一起看,它们指向同一个方向:Agent 的价值来自流程化工程知识,包括可执行步骤、可复现实验和可 review 的证据。
1. TL;DR
-
当 Agent 可以沿着定义清楚的工作流持续推进时,它们在 SGLang 中最有用。Benchmarking、profiling、kernel API logging、新增 diffusion pipeline、production incident replay 和 SOTA loop 都可以被编码成 skill。 -
SGLang skill 是一种可执行的开发流程。在 debug-cuda-crash、sglang-diffusion-benchmark-profile和llm-torch-profiler-analysis中,重要内容包括 preflight checks、hard failure gates、artifact contracts、reproduction commands 和 result formats。 -
Profile evidence 是性能工作的核心。SGLang profiler skills 会生成固定的 kernel table、overlap-opportunity table 和 fuse-pattern table。KDA-Pilot 进一步把它扩展到 same-ABI baseline/candidate comparison、真实 workload、correctness gates、NCU evidence 和 per-shape results。 -
长周期优化已经开始进入 Loop Engineering。SGLang SOTA Performance Loop 把“追 SOTA”拆成公平 benchmark、gap decision、profiling、patching 和 revalidation。Humanize/RLCR 加入外部 review,而 Codex Goal 可以用更低协调成本运行同样的 loop。 -
Review 变得更加重要。Agent 可以运行更多实验,但也会生成更多看起来合理、仍然需要仔细 review 的改动。开发者越来越需要定义问题、选择证据、设计工作流,并判断结果是否已经适合进入生产路径。
2. 为什么 SGLang 适合 Agent 辅助开发
SGLang 是面向 LLM 和多模态模型的高性能 serving framework。随着模型家族和硬件路径不断扩展,开发中会反复出现几类问题:
-
LLM 路径很复杂。一个性能问题可能跨越 Python runtime、scheduler、CUDA graph、Triton/CUDA kernels、FlashInfer/FlashAttention、distributed collectives 和模型特定 wrapper。 -
Diffusion 路径同样复杂。一次较慢的 denoise pass 可能涉及 pipeline/stage partitioning、DiT blocks、attention backends、 torch.compilegraph breaks、CFG/SP parallelism、VAE 或自定义 fused kernels。 -
验证成本很高。许多改动必须在 H100、H200、B200 或 RTX 5090 上,用真实模型和真实 workload 测试。仅靠本地单元测试并不够。 -
Profiles 很难手工复用。一次 trace 可能包含数百次 kernel launch。手工阅读 Perfetto 时,可能漏掉 kernel 到 Python 源码的映射,也很容易混淆 prefill 和 decode。开发者在阅读 profiler 输出时会积累很多 know-how,例如哪些 kernel name 对应哪些模型逻辑,哪些 launch pattern 暗示 graph break,哪些 NCCL/attention/MLP 布局是正常的。如果这些知识只留在一个人脑子里,下一个任务就无法复用。 -
性能结论高度依赖上下文。GPU 类型、shape、batch size、parallelism、precision、backend 和 compile state 都会改变结果。一个孤立的 microbenchmark 往往无法证明真实模型级收益,因此需要一个端到端的长期测试流程,在固定 workload 下反复验证 throughput、latency、memory、accuracy 和 stability。这个过程既耗人力,也耗时间。
这些问题天然适合交给 Agent。启动 server、固定 workload、收集 trace、triage profile row、添加测试、记录实验结果,都有清晰的输入和输出,也适合脚本化和重复执行。开发者需要定义范围:同样的 benchmark 设置、同样的 profile 解读规则、同样的 accuracy gates,以及 Agent 应该在什么条件下停止改代码。
因此,这里讨论的 Agent,是受工程工作流约束的执行者。重复出现的 SGLang 开发流程可以被捕获为 skills,让 Agent 处理重复执行、证据收集和状态跟踪。开发者仍然负责定义目标、判断证据,并 review 某个改动是否应该进入真实 serving path。
3. 从 Prompt Engineering 到 SKILL:协议与示例
在 SGLang 框架中,一个有用的 skill 至少应该回答以下问题:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SGLang Agent 相关 skills 覆盖不同层级。有些靠近源码改动,例如 debugging、testing、新增 diffusion models,以及 benchmark/profile workflows。另一些则面向跨框架 benchmarking、容量规划、计算模拟、生产事故 triage、PR 优化知识、SGLang human-style review,以及 Humanize/RLCR 这类更高层工作流。
3.1 当前 Skill Stack
常用的 SGLang Agent 相关 skills 可以分成以下几组。
|
|
|
|
|---|---|---|
|
|
debug-cuda-crash |
|
|
|
llm-serving-auto-benchmark |
|
|
|
llm-serving-capacity-planner |
|
|
|
llm-torch-profiler-analysis |
|
|
|
llm-pipeline-analysis |
|
|
|
model-compute-simulation |
|
|
|
sglang-diffusion-benchmark-profile |
|
|
|
sglang-diffusion-add-model |
|
|
|
sglang-diffusion-performance |
|
|
|
sglang-prod-incident-triage |
|
|
|
sglang-humanize-review
model-pr-history-knowledge
|
|
|
|
sglang-sota-humanize-loop |
|
这些条目把容易遗漏的步骤转成可执行协议,让工作流能够运行、恢复和被 review。
3.2 近期优化和工作流示例
下面的示例来自近期已合并的 SGLang PR。表格关注完整工程路径:benchmarking、profiling、localization、code changes、tests 和 revalidation。
|
|
|
|
|---|---|---|
|
|
|
input_ids fallback 和 proxy body construction,避免 router 和 engine 重复 tokenization
|
|
|
|
|
|
|
|
flashinfer_trtllm NVFP4 fused-MoE kernel 能在真实模型路径中正确使用,并通过 GSM8K/MMLU checks
|
|
|
|
|
|
|
|
|
|
|
|
|
在这些示例中,Agent 的主要贡献是执行工作流:运行 benchmark、读取 profile、定位 Python 源码、修改代码、添加测试、重新验证,并准备 PR descriptions。如果没有 skills,许多步骤都依赖人工提醒。一旦被编码成 skills,工作流就更容易重复。
4. Profiling、Review 与 Loop Engineering
SGLang 性能工作中一个常见错误,是只看总运行时间,或者打开 Perfetto 看几分钟,就凭直觉判断某个东西“应该 fuse”。对 Agent 来说,这更危险,因为它们很容易把视觉上很热的 kernel 误认为真正瓶颈。
实践中,通常会一起使用两个 profiler skills。llm-torch-profiler-analysis 处理第一层 trace triage,把 global profile 转成三张固定表:
-
Kernel Table:按 stage 总结 GPU time share、launch count 和 kernel category,并在可能时把 kernels 映射回 Python source 和 CPU ops。 -
Overlap Opportunity Table:使用 exclusive/hidden time share、dependency risk 和 kernel category,识别剩余 overlap 或 headroom。 -
Fuse Pattern Table:把 trace 与 source-backed pattern catalog 对比,catalog 覆盖 SGLang、其他开源推理框架和 kernel libraries 中的 fusion/overlap paths。
这些表回答第一组问题:哪个 stage 和哪个 kernel 占了多少 GPU 时间,它们映射到哪一行 Python,以及是否已有可以学习的 fuse/overlap path。如果 SGLang 落后另一个推理框架,那么在任何代码改动开始前,profiler table 应该先解释这个差距。
下一步是 llm-pipeline-analysis。当 global hotspots 已经明确后,我们仍然需要知道它们属于哪个 forward pass、layer type 和 kernel flow。这个 skill 读取 Chrome trace JSON 和模型 config.json,使用 layer-boundary anchor kernels 把 trace 切分成 forward passes 和 layers,然后生成几张用于深入分析的表:
-
Forward pass summary:区分 cold-start 和 steady-state,避免把 warmup 变成优化目标。 -
Per-layer timeline:报告每层的 wall time、sum duration,以及 MLA、MoE、GEMM、NCCL、MHC、Hadamard 等类别的占比。 -
Layer cluster statistics:对具有交替层结构的模型尤其有用,例如带compress_ratios的 NSA/hybrid-attention models,其中 C4_LIGHT、C128_HEAVY、HASH 或其他 layer types 可能主导 latency。 -
Compute flow table:把代表性层展开成具体 kernel flows,包含 hotness、relative timestamps 和 input dimensions,方便跳回 Perfetto。
因此,profile analysis 变成一个两步过程。首先,llm-torch-profiler-analysis 在完整 trace 中识别主要冲突。然后,llm-pipeline-analysis 把问题落到 steady-state forward passes、代表性 layers 和具体 kernel flows 上。第一步避免凭直觉选方向;第二步避免只盯着一个 global hot kernel,却漏掉模型结构中的 layer-type differences。
4.1 Humanize/RLCR:把外部 review 加入 loop
Humanize 处理长周期任务中的状态和 review。一个高风险的 SGLang 性能任务通常不会在一次实现 pass 中完成。它可能经历多轮 benchmarking、profiling、patching、reverting、改变方向和再次验证。Humanize 把这个过程拆成两个阶段:
-
先运行 gen-plan。 humanize-gen-plan把 draft requirement 转成结构化plan.md,其中包含 goal description、acceptance criteria、positive/negative tests、path boundaries、milestones 和 implementation notes。 -
再运行 RLCR loop。 humanize-rlcr从plan.md开始 loop。每一轮中,Claude Code 读取.humanize/rlcr/<timestamp>/round-<N>-prompt.md,执行实现、commit,并写 summary。Codex Review 随后检查 state files、summaries、git cleanliness、review results、open questions、max-iteration conditions 和其他 gates。仅凭一句“task complete”不足以退出 loop。
这个机制为 SGLang SOTA Performance Loop 提供执行和 review 基础。Claude Code 运行 benchmark、读取 profile、修改 SGLang 代码并重新验证。Codex Review 在每一轮结束时检查 evidence、state 和 risk。它适合那些会变成 PR、影响 serving correctness,或需要多天、多轮实验的任务。
实践中,命令顺序应该明确,避免 Agent 直接跳到实现:
1. Write a task draft under artifact_root/draft.md.
2. Run humanize-gen-plan to generate artifact_root/plan.md.
3. Start humanize-rlcr from artifact_root/plan.md.
4. Keep all decisions, summaries, and review state in the local Humanize workspace.
4.2 SGLang SOTA Performance Loop(Loop Engineering)
单个 skill 可以稳定一个任务。然而,在十几轮实验之后,会出现另一个问题:哪个 candidate 最好,哪些方向已经失败,上一份 NCU report 显示了什么,benchmark 是否仍然匹配 baseline,以及什么时候应该停止。这些状态不能只存在于聊天上下文里。
SGLang SOTA Performance Loop 是一个建立在 Humanize/RLCR 上的 Loop Engineering 工作流。这里的 SOTA 指的是固定实验条件下的最佳可复现结果:相同模型、硬件、GPU 数量、precision、workload、SLA、framework commit 和 serving parameters。问题是,在这些条件下,SGLang 是否能达到当前最佳可复现结果。
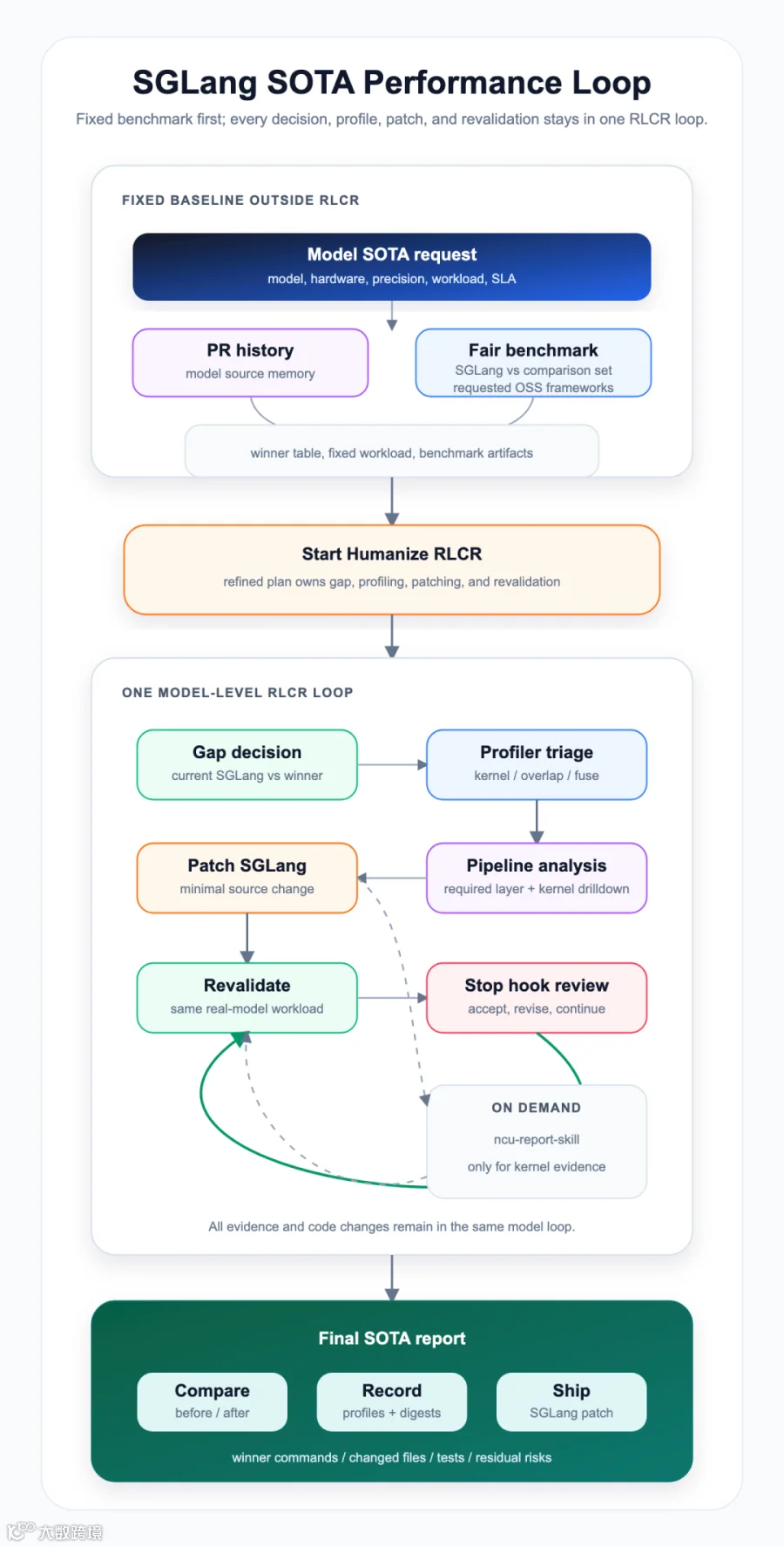
图 1 是 SGLang SOTA Performance Loop。固定的公平 benchmark 首先建立一个可复现 baseline。后续 gap decision、profiling、pipeline analysis、patching 和 revalidation 都由 Humanize/RLCR loop 驱动。
一个完整的 SGLang SOTA Performance Loop 包含以下阶段:
-
定义 target boundary。例如 Qwen/Qwen3-Next-80B-A3B-Instruct-FP8、single-node 2x B200、FP8、SGLang TP=2,并在同样 2-GPU budget 下与指定开源推理框架比较。 -
先运行 fair search。在 patch SGLang 之前,先在相同 workload 和 resource budget 下,为 SGLang 和每个指定开源推理框架搜索最佳可复现命令。 -
判断 gap。如果 SGLang 已经持平或领先,就记录 completion evidence。如果它持续落后并超过 threshold,就进入 profiling。 -
用 profiles 解释 gap。不要急着改代码。先在需要时生成 kernel tables、pipeline tables、overlap/fuse tables 和 NCU reports。 -
只 patch 有证据支撑的路径,例如 hybrid attention、Mamba/GDN、radix cache、target verify、CUDA graph、MoE/EP、quant kernels 或 model wrappers。 -
在同一个 workload 上重新验证。每一轮都记录 benchmark、profiles、accuracy、failed attempts、environment information 和 cleanup actions。
对于 2x B200 上的 Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 这类目标,这个 loop 很重要,因为 benchmark results、profile traces、failed patches 和 intermediate conclusions 都需要持续绑定到同一个模型、硬件、workload 和 framework commits。如果这种任务被拆成很多互相独立的 prompt,就很容易丢失哪个命令产生了哪个结果,或者后续 profile 是否仍然匹配最初 baseline。带有 evidence 和 review 的 loop 可以让各轮条件保持对齐。
4.3 Codex Goal:一种成本更低的 loop 实现
上面的 SGLang SOTA Performance Loop 使用两角色设置:Claude Code 执行 benchmark、profiling、patching 和 revalidation,Codex Review 在每一轮结束时检查。这种设置适合严肃 PR 工作,但每一轮都会同时消耗执行模型和 review 模型,增加成本和等待时间。
Codex Goal 提供了另一种实现方式。当“fair benchmark -> gap decision -> profile -> patch -> revalidate -> artifact ledger”被写入持久 Goal 后,一个 Codex Goal 就可以在没有两角色 execution/review 设置的情况下,承载执行、自检和重新验证。SGLang SOTA Performance Loop 的核心约束保持不变:固定 workload、evidence-driven patches、在相同实验条件下 revalidation,并在每一轮后更新 artifact manifest。
两种方式区别如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
.humanize/rlcr/...
|
artifact_root 下的 manifest/evidence
|
|
|
|
|
|
|
|
|
|
|
|
|
下面是 AI-Infra-Auto-Driven-SKILLS/prompts 中一个 2x B200 模型优化 prompt 示例。
Humanize/RLCR 版本:
使用 sglang-sota-humanize-loop 工作流。
任务:优化 SGLang serving performance,目标模型为 Qwen/Qwen3-Next-80B-A3B-Instruct-FP8,运行在单节点 2 张 NVIDIA B200 GPU 上,使用 FP8 precision,初始 SGLang TP=2。
SGLang 应该在相同 2-GPU budget、workload、SLA、model、precision 和 environment constraints 下,匹配或超过指定开源推理框架中的最佳可复现结果。
Required workflow:
1. 在 artifact_root 下创建 draft task document。
2. 运行 humanize-gen-plan,把 draft 转成结构化 plan.md。
3. 在 Claude Code session 中,从该 plan.md 启动 humanize-rlcr。
4. 将 benchmark、profile、patch 和 revalidation decisions 保留在同一个 Humanize workspace 中。
Evidence and safety requirements:
- patch 前,针对 SGLang 和指定开源推理框架集合运行公平、有界的 search。
- 在选择 SGLang baseline 前,检查 sgl-project/sglang 和 BBuf/sglang 中相关 open PR。
- 如果 SGLang 落后超过 1%,先 profile 再 patch。
- 优先关注 hybrid attention、Mamba/GDN、radix cache、target verify 和 CUDA graph 相关证据。
- 记录每一轮的 benchmark commands、profile artifacts、failed attempts 和 cleanup evidence。
- 只 patch 有证据支撑的 SGLang code paths。
- 如果需要 PR,只能 push/open 到 BBuf/sglang,并包含 benchmark、GSM8K 和 full MMLU accuracy tables。
artifact_root: /workspace/sglang-agent-artifacts/b200_qwen3_next_80b_a3b_instruct_fp8_sota_humanize
Codex Goal 版本:
/goal Keep optimizing SGLang serving for Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 on a single node with 2 NVIDIA B200 GPUs until SGLang matches or exceeds the best reproducible result from the requested open-source inference frameworks under the same 2-GPU budget, FP8 precision, workload, SLA, model, and environment constraints.
当前 Codex Goal 就是这个 loop:fixed fair benchmarking、gap decision、profiling、pipeline analysis、evidence-backed patching、revalidation、final report 和 optional PR preparation 都在这个 Goal 内完成。
Completion requires benchmark evidence, profile evidence when SGLang was behind, correctness/accuracy evidence, a final artifact manifest, and no regression in environment safety constraints.
model_id: Qwen/Qwen3-Next-80B-A3B-Instruct-FP8
root_dir: /workspace
target_hardware: single-node 2x NVIDIA B200
minimum_gpu_count: 2
precision_quantization: FP8
initial_deployment: SGLang TP=2
artifact_root: /workspace/sglang-agent-artifacts/b200_qwen3_next_80b_a3b_instruct_fp8_sota_goal
Requirements:
- Use the current Codex Goal as the only persistent loop.
- Before patching, run a fair bounded search for SGLang and the requested open-source inference frameworks under the same 2-GPU budget.
- If SGLang is behind by more than 1%, profile in the same Goal, then use llm-torch-profiler-analysis, llm-pipeline-analysis, and ncu-report-skill when needed before patching.
- Focus on hybrid attention, Mamba/GDN, radix cache, target verify, and CUDA graph.
- Update the artifact manifest, benchmark evidence, profile evidence, failed attempts, and next-step decision after every round.
- Stop and report a blocker if resources are unavailable, evidence is untrustworthy, the budget is exhausted, or no defensible next patch exists.
Goal 版本保留了同样的 benchmark、profile、accuracy 和 artifact requirements。区别在于,执行和 review 被折叠进一个持久目标中。只要 hard-stop conditions 写清楚,它就能用更少 orchestration 承载同样的 SGLang SOTA Performance Loop。
5. 基于 KDA 的 SGLang 系统 CUDA Kernel 优化
除了 LLM 和 diffusion 的模型级优化,kernel optimization 有一个更严酷的扩展问题。脱离硬件和 workload,并不存在单一最优 kernel。同一个 operator 在 H100、H200、B200 或 B300 上可能偏好不同实现;不同模型架构会暴露不同 tensor shapes 和 layout constraints;serving workload 也会改变 batch size、sequence length、precision format、wrapper overhead、synchronization behavior 和 fallback paths。实践中,搜索空间是 hardware、model 和 workload definitions 的笛卡尔积。
这会形成组合优化负担。对于每个 candidate kernel,开发者需要提取代表性的 production rows,构建 same-ABI harness,运行 A/B measurements,跨 shape buckets 检查 correctness,阅读 NCU metrics,判断某个 bucket 是否值得 specialization,然后再在真实 SGLang path 中重新验证。手工为每个 hardware/model/workload 组合做这件事成本很高。这也正是 Agent 擅长的重复性、证据密集型工作流,只要人类定义 invariants 并 review 最终路径。
然而,让 Agent 直接写 CUDA 很容易导致 benchmark reward hacking:改 benchmark、使用更轻的 wrapper、只给 candidate 开启 baseline 没有用的 fast math、只优化一个 shape、破坏 numerical semantics,或者在真实 SGLang path 中没有收益。
KDA-Pilot 将 kernel optimization 拆成 isolated tasks,让 Agent 不能自由修改整个 SGLang 仓库:
-
Workloads 来自真实 SGLang diffusion models。流程会先运行 20 个 diffusion models,并总结实际 kernel metadata。 -
Baseline 从 upstream SGLang main 复制,并记录 source lineage。 -
Baseline 和 candidate 必须使用相同 local ABI 和相同 build/export path。 -
Benchmarks 使用固定 production rows、A/B interleaving,以及 CUDA event 或 wall timing。 -
Correctness 覆盖 production rows、canonical regression grid、NaN/Inf checks、poison output checks 和 fallback contracts。 -
每次迭代都会刷新 task prompt、benchmark evidence、KernelWiki 和 ncu-report-skill。 -
允许 shape-specialized dispatch,但每个 bucket 都必须记录 condition、path、latency 和 fallback。
一个具体快照可以更直观看到规模。公开的 KDA-Pilot B200 diffusion summary 当前列出 10 个被追踪的 SGLang kernel tasks。多数行在 KDA-Pilot ledger 中有稳定的 B200 数字证据;在提取的 production rows 上,wall-geomean speedups 从 1.1341x 到 2.7499x 不等。residual_gate_add 行显示为 1.11x,与已合并 upstream LTX-2.3 B200 结果一致。
截至 2026 年 6 月 27 日,已有三个 KDA-Pilot-derived optimizations 合入 upstream SGLang。第一个是 SGLang PR #27392,为 Qwen-Image-2512 提供 B200 native diffusion norm-scale-shift CUDA fast path。那一周晚些时候,又有两个合入:SGLang PR #29281,面向 Cosmos3 VAE causal Conv3D cat/pad copy path;SGLang PR #29361,面向 LTX-2.3 residual-gate update path。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
torch.compile 后,median E2E time 从 181.521 ms 改善到 177.687 ms,即 1.021x
|
|
|
|
|
|
关键结论并不是每个 standalone kernel win 都会变成巨大的端到端收益。真正关键的是,同一个 KDA-Pilot evidence package,也就是 fixed production rows、correctness gates、same-ABI comparisons、profiler attribution 和 real-model checks,可以把一个 kernel task 从 isolated benchmark 推进到可 review 的 SGLang serving path。
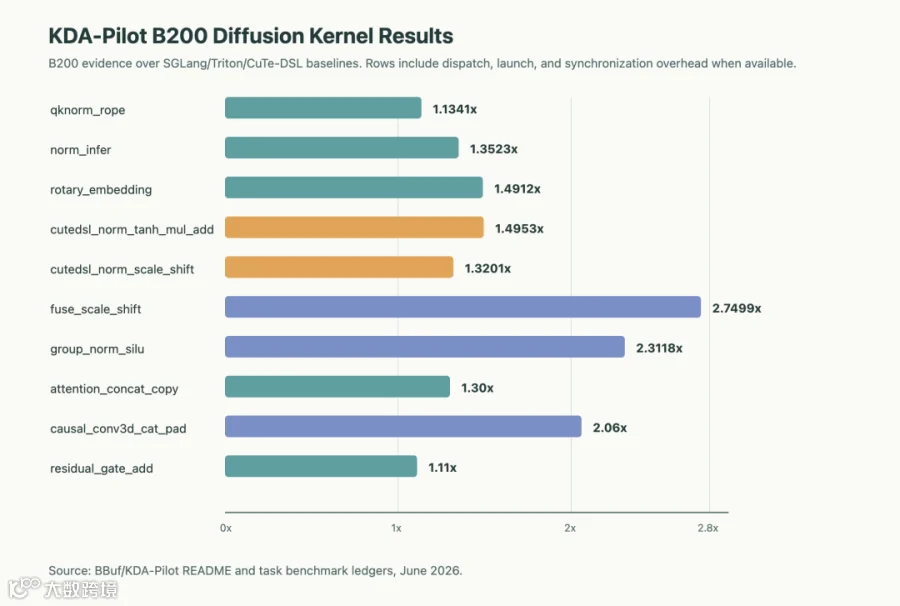
图 2 是 KDA-Pilot 优化的 10 个被追踪 SGLang diffusion kernel tasks 的 B200 证据。大多数行报告 KDA-Pilot wall-geomean speedup;wall time 包含 Python dispatch、wrapper overhead、kernel launch,以及通过 cuda.synchronize() 可见的 synchronization overhead,因此比纯 kernel device time 更接近真实调用路径。
|
|
|
|
|---|---|---|
qknorm_rope |
1.1341x |
|
norm_infer |
1.3523x |
|
rotary_embedding |
1.4912x |
|
cutedsl_norm_tanh_mul_add |
1.4953x |
|
cutedsl_norm_scale_shift |
1.3201x |
|
fuse_scale_shift |
2.7499x |
|
group_norm_silu |
2.3118x |
|
attention_concat_copy |
1.30x |
|
causal_conv3d_cat_pad |
2.06x |
|
residual_gate_add |
1.11x |
|
阅读图表和任务表时,需要记住实验设置:它们报告的是从 production rows 中提取的 kernel-task speedups,不是完整模型端到端收益。它们仍然有用。一旦 baseline、workload、correctness、profiling 和 review 被固定下来,Agent 就可以在真实框架 kernel 上产生可 review 的增量改进。
KDA-Pilot 实验中有两条规则值得保留:
-
不要给 benchmark reward hacking 留空间。当 baseline 和 candidate 使用不同 ABI、不同 fast-math 设置或不同 wrapper path 时,结果就会变得不可靠。另一个常见问题是看到结果后再改变 benchmark shape set,例如移除 candidate 更慢的 shape。这样的结果不应使用。 -
接近 Roofline 的 buckets 应允许 no-go 或 fallback decisions。一个好的 kernel optimization task 不应该强迫 Agent 赢下每个 shape。对于 giant contiguous buckets 或已经接近 bandwidth limit 的路径,记录一个 fallback 可能比增加更多复杂度更好。
6. 实践规则
-
在启动 Agent 之前先定义任务范围。
“Optimize SGLang” 太宽泛。相比之下,“在 2x B200 上,固定
1000->1000和8000->1000workload,让Qwen/Qwen3-Next-80B-A3B-Instruct-FP8对齐另一个开源推理框架”才是一个可执行目标。 -
在阅读 profile 之前先固定 benchmark。
如果结果出来后 workload 还能改变,Agent 可能会意外优化一个更容易的问题。SOTA loop 和 KDA-Pilot 都把 fixed workloads 放在 patching 之前。
-
按 kernel 的计算特征解读 NCU 结果。
对 memory-bound kernels,应关注 DRAM/L2 throughput、load/store efficiency 和 memory pipe utilization。对 compute-bound GEMM/attention kernels,应关注 Tensor Core utilization、SM busy、eligible warps 和主要 stall reasons。对 small latency-bound kernels,应检查 launch count、per-kernel duration、synchronization points 和可能的 fusion opportunities。单张 trace screenshot 不够;下一次代码改动应该由具体 metrics 支撑。
-
信任 profile 之前,先检查 backend 和 fallback gates。
如果一次 LLM run 静默切换了 attention backend、禁用了 CUDA graph,或者走了一条和 benchmark 不同的 wrapper path,那么这份 trace 就不再描述目标 serving path。Diffusion 也一样:如果日志显示 fallback 到 diffusers backend,那么该 trace 不能作为 native SGLang diffusion 的证据。这些 hard-stop conditions 应该写进 skill。
-
Kernel optimization 必须使用相同 ABI、wrapper 和 compile flags。
特别是,candidate 不应该静默走一条更轻的 path,
--use_fast_math也不应该只在一侧开启。 -
Review 比以前更重要。
Agent 可以创建更多 PR,也可以创建更多看似合理的错误。对 SGLang 这样的高性能系统来说,review 需要检查 shape、dtype、distributed execution、CUDA graph behavior、fallback behavior、accuracy、serving APIs、metrics 和 benchmark setup。
Agent 时代的 SGLang 开发不会把开发者从系统中移除。更现实的变化,是把开发者经验写入工作流,把重复执行交给 Agent,把判断、设计和 review 留给人。节省下来的时间可以投入更难的性能问题、模型路径和生产稳定性,也可以反过来继续改进 Agent 工作流本身。对一个开源推理框架来说,这类基础设施值得持续投入。
7. 致谢
感谢帮助构建 SGLang agent skills 的 SGLang Team 成员和贡献者:Xiaoyu Zhang (BBuf)、Lianmin Zheng、Liangsheng Yin、Ke Bao、fzyzcjy、Kangyan Zhou、DarkSharpness、Mick、Alison Shao、Baizhou Zhang、Bingxu Chen、Cheng Wan、Ratish P、shuwenn、ykcai-daniel、Yuhao Yang 和 Artem Savkin。
感谢 KDA 团队:Dongyun Zou、Ligeng Zhu、Sihao Liu、Junxian Guo、Yixin Dong、Zijian Zhang、Hao Kang 和 Song Bian。
感谢 Humanize 团队和贡献者:Sihao Liu、Ligeng Zhu、Zijian Zhang、Zenus Zhang、shinan6、DYZhang、Chao Liu、Zhou Yaoyang、gyy0592、AcrossForest、Emin、Qiming Chu、jiaxiaoyu、tastynoob 和 zhenwei。
8. 参考链接
-
SGLang GitHub Repository:https://github.com/sgl-project/sglang -
SGLang .claude/skills:https://github.com/sgl-project/sglang/tree/main/.claude/skills -
SGLang diffusion .claude/skills:https://github.com/sgl-project/sglang/tree/main/python/sglang/multimodal_gen/.claude/skills -
AI-Infra-Auto-Driven-SKILLS:https://github.com/BBuf/AI-Infra-Auto-Driven-SKILLS -
AI-Infra-Auto-Driven-SKILLS prompts:https://github.com/BBuf/AI-Infra-Auto-Driven-SKILLS/tree/main/prompts -
Kernel Design Agents (KDA):https://github.com/mit-han-lab/kernel-design-agents -
KernelWiki skill:https://github.com/mit-han-lab/KernelWiki -
ncu-report-skill:https://github.com/DongyunZou/ncu-report-skill -
KDA-Pilot:https://github.com/BBuf/KDA-Pilot -
SGLang Diffusion Advanced Optimizations, LMSYS Blog:https://lmsys.org/blog/2026-02-16-sglang-diffusion-advanced-optimizations/ -
OpenAI Codex Prompting: Goal mode:https://developers.openai.com/codex/prompting#goal-mode -
Humanize:https://github.com/PolyArch/humanize -
原文:Agent-Assisted SGLang Development: An Initial Exploration:https://www.lmsys.org/blog/2026-07-02-agent-assisted-sglang-development/
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点 
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括LLM、预训练模型、自动生成、文本摘要、智能问答、聊天机器人、机器翻译、知识图谱、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。
