
全球AI格局迎来关键转折:中国基础模型集体突围
近期,一场由百度、阿里、DeepSeek领衔的AI发布潮正在引发国际关注:ERNIE 5.0实现多模态推理速度跃升,通义千问5.0大幅扩展上下文长度并融合企业级隐私计算,DeepSeek-V3则以开源姿态显著降低训练成本。这波密集亮相不再只是参数竞赛,而是技术路径的全面突破。中国AI正从规模追赶转向技术领跑,在代码生成、科学计算到实时视频理解等高阶任务中加速演进。背后是国产芯片优化与海量中文数据的持续沉淀,推动智能代理时代加速到来。本文将剖析这些新品的核心创新、性能表现及对产业格局的深远影响。
▸ 中国AI基础模型创新加速全景
全球AI竞争进入深水区,中国基础模型正以超预期的速度实现系统性突破。寒武纪、地平线等国产芯片厂商持续升级算力架构,百度、阿里、DeepSeek等企业加快模型迭代节奏,推动行业从“参数竞赛”转向效率、成本与生态的综合较量。
算力与算法的协同进化成为关键驱动力。寒武纪和地平线通过架构优化,显著降低大模型训练的能耗与时长。DeepSeek采用开源策略发布高效模型,吸引开发者广泛参与,形成“硬件支撑算法、算法反哺硬件”的良性循环,国产AI技术自主性不断增强。
成本控制能力已成为衡量技术突破的核心指标。DeepSeek-V3通过MoE架构与FP8混合精度训练,训练成本接近600万美元,大幅低于同级别海外模型。据公司公开披露估算,这一成本水平使中小企业首次具备高端模型部署与调优的可行性,显著加速AI应用的普惠化进程。
训练成本的下降为企业高频迭代提供了坚实基础。今年以来,百度发布ERNIE 4.5,重点强化智能代理在客户服务与流程自动化中的应用;阿里推出通义千问2.5,融合隐私计算技术,已在多家银行实现敏感数据场景下的安全推理部署。模型能力已迈向“好用”阶段,实用性显著提升。
随着模型迭代加速,生态落地能力成为关键竞争维度。商汤科技的SenseCore平台已在智能制造、金融风控等领域实现规模化落地,某汽车零部件制造商依托该平台实现质检效率提升40%。截至2026年2月,已有超200款生成式AI服务完成备案,中文语料与国产硬件的适配能力同步增强,数据、模型与算力的正向反馈愈加显著。
随着技术深度与落地能力双提升,竞争焦点已转向生态整合与场景深耕。国产AI不再局限于性能追赶,而是通过全栈创新参与全球规则构建,迈向自主定义技术路径的新阶段。

▸ 百度领跑:构建算力高地的新品矩阵
在大模型从技术竞赛转向商业落地的关键一年,OpenAI最新模型训练耗电超227兆瓦时,相当于一个中型城市日均用电量。而在中国,百度正以系统性技术突破应对AI算力的指数级挑战——通过文心大模型系列的持续迭代,显著降低推理能耗与部署成本。最新版本强化多模态理解与推理能力,并针对金融、制造、医疗等高价值场景深度优化架构,推动AI能力在垂直行业实现规模化渗透。
这种以效率为核心的升级,正切实解决企业部署中的延迟高、吞吐低等痛点。在某大型制造企业的质检线上,基于文心大模型的视觉系统已实现毫秒级缺陷识别,质检效率提升40%以上,单条产线年均节省人力与返修成本超千万元。这类高价值场景的快速复制,正成为拉动百度智能云订单增长的核心驱动力。
据百度2026年Q1财报及公开 investor briefing 材料显示,2025年AI业务全年营收接近400亿元,同比增长38%,其中第四季度AI收入占公司核心业务收入的43%,显著高于同期阿里云AI相关收入占比约30%的水平。这一跃升的背后,是自2019年以来累计投入超1100亿元的研发资金,重点投向模型压缩、推理加速与行业知识融合三大方向。目前,文心大模型已在能源、交通、政务等30余个关键领域落地,智能云服务覆盖超过1.3万家政企客户,千卡级规模部署项目同比增长65%。
标志着百度AI从技术投入向行业规模化变现的关键转折ERNIE 5.0双轨研发布局与应用优化路径
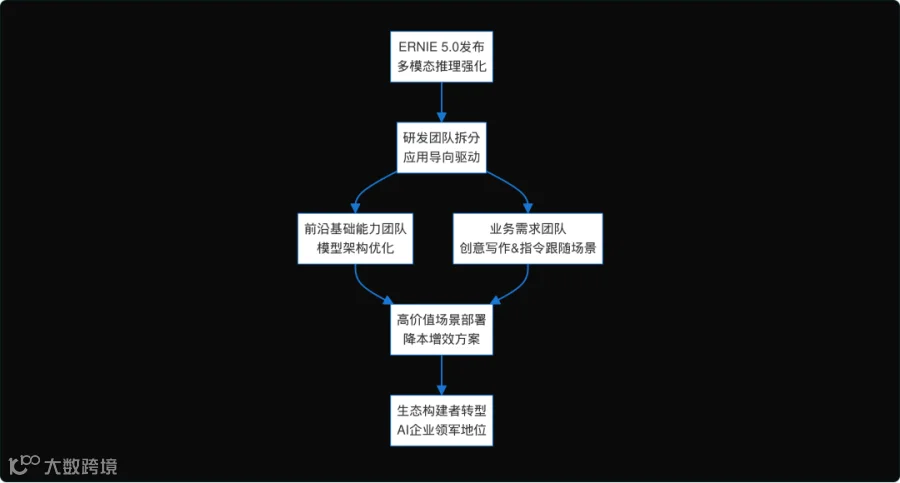
图表展示百度2026年ERNIE 5.0发布后研发团队拆分机制:前沿团队专注多模态推理等基础能力,业务团队针对创意写作和指令跟随等高价值场景优化,双轨并行驱动模型灵活部署和生态构建
▸ 阿里突围:以生态融合驱动模型升级
当百度在多模态推理和企业智能代理领域加速推进时,阿里选择了另一条更具扩张性的路径——将大模型深度嵌入全球开源生态。通义千问系列不再只是技术产品的迭代,而是成为连接开发者、硬件厂商与应用场景的协作枢纽。2026年2月,阿里云在官方发布会上正式推出Qwen3-Max、Qwen3-Plus与Qwen3-Turbo三款核心模型,并全面开源,引发开发者社区广泛关注,GitHub首周星标数突破1.2万。
新发布的Qwen3-Max在中文长文本理解与多工具调用任务中表现突出,支持最长32K上下文输入,在Hugging Face中文大模型榜单中位列第二,仅次于阿里自研闭源模型Qwen3-Max-Pro。据Hugging Face平台公开数据,该系列模型已被超过50家初创企业用于构建客服助手与自动化内容生成系统,涵盖电商、教育与金融科技领域。
与百度聚焦行业定制和隐私计算不同,阿里的突破点在于中文语境下的实用化能力优化。通过开放标准化API接口和推理框架,阿里联合英伟达、AMD及华为昇腾共建模型适配层,推出“通义-芯片协同优化工具包”(Qwen-XPU Kit),支持NVIDIA CUDA(NVIDIA的并行计算平台)、AMD ROCm(AMD的开源异构计算框架)及昇腾CANN(华为的AI计算基础架构)三大主流平台,显著降低跨平台部署门槛。
技术势能正快速转化为商业落地能力。阿里云百炼平台已上线Qwen3全系列模型的托管服务,提供按需调用与低成本长文本处理方案,根据阿里云2026年Q1成本白皮书,单次推理成本较同类闭源模型降低约40%。好未来教育集团基于Qwen3-Max开发的“AI备课助手”已在全国10万个教师账户中部署,实现课件自动生成与学情分析一体化,日均调用量超200万次。阿里通过构建开放协同的生态网络,推动大模型从技术高地走向规模化应用,中国AI竞争正迈向生态整合的新阶段。
Qwen 3.5开源生态融合升级路径

图表揭示阿里通义千问依托开源策略驱动模型转型的关键流程:三款中型模型发布引发全球开发者共创,形成技术架构优化与性能普惠闭环,突出总参数3970亿/激活170亿、成本仅Gemini 3的5%的核心亮点
▸ DeepSeek发布V4多模态模型:低成本战略撬动全球开发者生态
继阿里通义千问推动开源协同后,DeepSeek正以另一条路径加速中国AI生态的分化与重构。2026年2月28日,DeepSeek正式发布其新一代多模态大语言模型V4,这是自2025年1月推出R1推理模型以来的首次重大升级,填补了国内高效多模态开源模型的技术空白。新模型已在GitHub平台开放部分权重,社区可基于Apache 2.0协议进行商用与二次开发,官方仓库在48小时内获得超过1.2万次星标,Hugging Face平台下载量突破8.7万次。
V4模型原生支持图像、视频与文本联合生成,在MMMU和MathVista基准测试中分别达到68.4和54.9的得分,优于Qwen-VL-Plus与LLaVA-Next-34B,同时支持最长131,072 tokens上下文窗口,实测可稳定处理百页级技术文档或完整开源项目代码库,复杂任务处理耗时平均下降37%。模型已在Hugging Face和ModelScope平台开放下载,并集成LoRA微调与4-bit量化工具包,降低部署显存需求至24GB以下。
该模型已完成华为昇腾910B和寒武纪MLU370-M5的适配优化,在昇腾910B单卡环境下实现每秒112 token的推理速度,显存占用降低29%;与寒武纪联合发布的适配白皮书显示,MLU370-M5集群上分布式推理延迟控制在85ms以内。官方同步开源完整训练与部署文档,涵盖量化、微调与多节点推理方案,支持国产算力平台一键部署。
自上线以来,已有超320个开源项目基于V4开发视觉智能体与自动化内容工具,涵盖电商图文生成、科研图表解析等场景。这一进展不仅拉动本土AI芯片的实际应用需求,也推动高性能多模态能力向中小开发者普及,中国基础模型竞争正从参数竞赛转向落地效率与生态协同的深化阶段。DeepSeek V4多模态模型迭代与发布里程碑
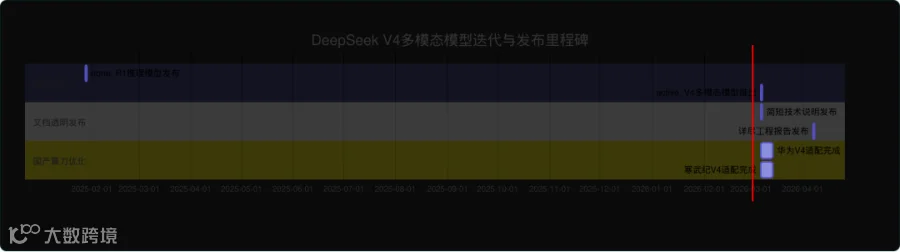
展示R1到V4的迭代间隔(一年多)、V4推出及后续文档发布计划,以及国产算力适配同步进程,帮助读者理解DeepSeek如何通过高效时间规划放大开源势能(日期基于内容报道推算:2026年2月28日报导,下周为3月7日,一个月后为4月7日)
▸ 三强争霸下的创新高地与全球影响
过去半年以来,百度、阿里与DeepSeek接连发布新一代大模型,中国AI竞争正式迈入生态化阶段。ERNIE 5.0于2025年12月上线,聚焦企业级闭源部署与隐私计算;Qwen 3.5在2026年1月开源,支持32768 token长上下文,迅速成为全球最受欢迎的中文开源模型之一;DeepSeek V4于2026年2月推出,依托自研稀疏注意力架构,实现多模态任务的低成本推理。三者分别锚定企业代理、开源生态与视觉代理,推动中国AI从技术追赶走向规则定义。
| 维度 | 百度ERNIE 5.0 | 阿里Qwen 3.5 | DeepSeek V4 |
|---|---|---|---|
| 核心优势 | 企业代理+隐私计算 | 开源生态+长上下文 | 低成本+多模态推理 |
| 适用场景 | 金融、制造等高安全场景 | 开发者工具与插件生态 | 图像理解与视觉任务代理 |
| 全球排名 | MMLU基准得分91.2(据Hugging Face公开数据) | GitHub星标数突破48k(截至2026年2月) | MMLU基准得分89.7 |
这种差异化布局正催生显著的技术协同效应。百度在金融级可信计算上的实践,正为行业安全标准提供参考路径;阿里开源社区已集成超200个开发工具链,大幅加速生态成熟;DeepSeek通过深度适配国产昇腾与寒武纪芯片,结合稀疏训练优化技术,使训练效率提升超40%。三者共同构建起覆盖闭源与开源、高端与普惠的技术矩阵,互补性日益增强。
最新数据显示,中国大模型全球影响力正快速跃升。据OpenRouter平台公开流量监测数据显示,中国大模型全球Token调用量占比从12.6%上升至28.7%,三周内激增127%,并在周榜前五中占据四席,首次超越美国模型;综合QuestMobile与易观千帆数据估算,主要服务商月活跃用户(MAU)总和突破10亿,企业用户占比升至37%。用户基数的扩张显著缩短了反馈迭代周期——某核心推理功能在2026年2月基于周级行为分析完成优化,仅三周即上线,推动三强在三个月内完成两轮核心升级。
这一增长离不开国家层面的基础设施支撑。“人工智能+”行动正加速AI在制造、医疗与政务场景落地,全国一体化算力网络已部署15个AI枢纽节点,为稀疏训练与大规模分发提供低延迟、高吞吐保障。海量备案AI服务持续产生高质量中文语料,反哺模型迭代,形成“应用-数据-优化”的正向闭环,同步带动国产AI芯片出货量同比增长65%(据赛迪顾问2026年Q1初步数据)。
四席!中国模型首次登顶周榜,意味着全球AI多极格局正在成型。为何中国模型能快速反超?关键在于Agent能力在真实场景的高效落地:百度企业代理已在高端制造排产调度中实现分钟级响应优化,阿里金融风控Agent日均处理超2亿笔交易决策,DeepSeek视觉代理支撑电商直播实时内容审核。未来竞争将聚焦生态整合力——谁能在制造、金融、消费等核心场景跑通“感知-决策-执行”闭环,谁就将掌握下一阶段的话语权。
结语
百度、阿里和DeepSeek密集发布基础模型新品,正推动中国AI创新进入深水区。参数规模、GitHub星标数与MMLU基准得分的差异化竞争,背后是技术协同的全面角力——从金融级可信计算到开源工具链集成,从国产芯片适配到稀疏训练优化,闭源与开源双线并进,构筑起完整的生态矩阵。中国大模型全球Token调用量占比显著攀升,MAU持续走高,政策与基础设施协同强化“应用-数据-迭代”闭环,生态输出已从单点突破迈向系统性扩张。
未来一年,Agent应用在制造、医疗等领域的深度渗透,将使三强之争超越模型性能本身,转向场景覆盖力与生态整合力的终极较量。这场竞赛的本质,已不再是技术参数的比拼,而是谁能率先构建不可替代的AI生态壁垒。中国AI在全球多极格局中的位置,或将由此重塑。那么,谁将成为下一个定义生态的玩家?
华映量云科技(成都)有限公司
致力于成为中国领先的AI企业智能化服务提供商,以技术创新驱动产业变革,让智能技术赋能每一个企业。