
一、背景
近年来,人工智能技术迅速发展,尤其是ChatGPT和DeepSeek等深度推理模型的面世,为各行各业提供了新的发展机遇。在证券行业中,大模型的应用为智能专家投顾、非现场业务办理、智能客服、OA自动化办公等业务环节提供了有力支撑。为满足不同场景下的业务需求和监管要求,中信建投证券构建了一套私有化与公有云相结合的大模型资源体系。然而随着大模型资源的扩展和各业务部门的陆续接入,大模型资源的管控也面临更深层次的挑战,具体表现为以下几个方面:
模型接入标准不一:当前处于大模型蓬勃发展期,据不完全统计,中国市场上的大模型提供商有200余家。虽然各家大模型在输入输出标准上整体遵循标准OpenAI格式,但各家出于个性化的产品差异,难以做到完全统一。
模型拓展不便:大模型产品版本迭代迅速,用户接入的大模型产品往往在短时间内会有新的迭代版本出现,在使用新版本时需要重新进行程序上的适配。
私有化部署资源不足:大模型的部署需要极高的资源消耗,尤其是GPU计算卡资源,当前中信建投证券所能应用于大模型部署的GPU资源有限。
大模型调用监测手段不足:随着接入大模型的用户数量增多,各用户调用的模型种类、调用的token数量、问题与结果等的合规性等方面需要进行有效监控。
针对以上痛点,构建一套统一的大模型管控服务有其必要性和紧迫性。
二、大模型统一管控服务的设计与实现方案
大模型统一管控服务由三部分组成:大模型统一接入模块、大模型流量调配模块、大模型调用统计模块三部分构成。同时依托公司的致胜平台管理网关提供公共调用服务,整体架构如图1所示。
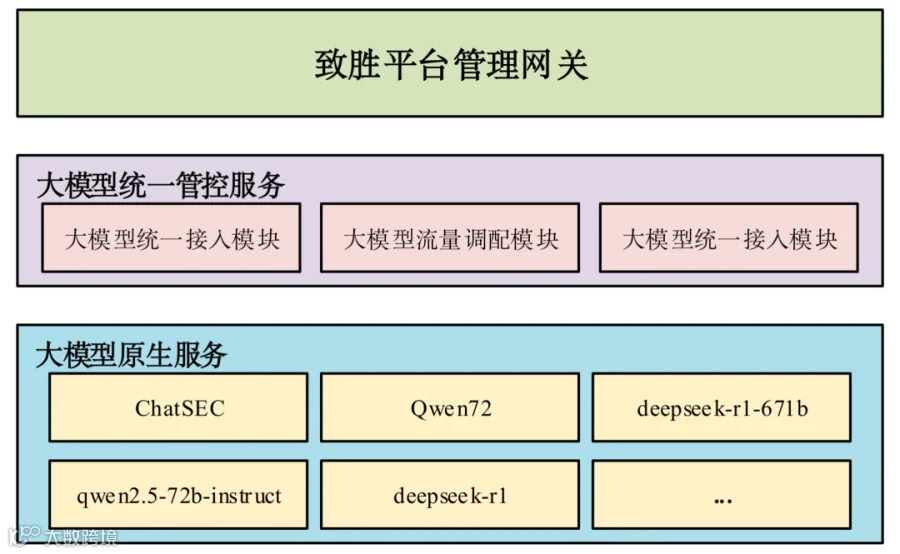
图1 大模型统一管理服务整体架构
1、大模型统一接入模块
大模型统一接入模块主要功能是综合整理各个原生大模型调用时的关键参数,归结其中的共同点和差异,通过配置统一的接入模板,设计公共程序解析大模型接入模板中的关键信息完成大模型原生接口的调用和结果转发。大模型接入模板采用yaml配置文件来统一管理,根据目前主流大模型的特点和不同用户调用时的具体需求,接入模板的格式如图2所示。

图2 大模型统一接入模板
其中:
imputModel:用户调用时传入的模型名称
modelName:后台调用大模型原生服务的模型名称
token:调用第三方大模型时所用的鉴权token
url:第三方大模型的调用地址
chatIdNullFlag:调用第三方请求时chatId是否置空(部分大模型调用时不支持传chatId信息)
msgNullFlag:调用第三方请求时msg信息是否置空(部分大模型调用时不支持传msg信息)
enableWebSearch:是否开启联网搜索
poolSize:模型资源池容量,用于后续流量调配
2、大模型流量调配模块
大模型流量调配模块主要用于缓解计算资源不足的问题,旨在优先满足重要业务的大模型调用。基于以上需求,我们借助致胜平台的Apikey设计了用户优先级体系,并借助redis实现了任务资源竞争机制。
在用户优先级体系中,用户被划分为优先调用方(Vip)和普通用户(Normal),用yaml配置文件维护,格式如图3所示。

图3 用户优先级体系示意图
Apikey是用户调用大模型接口的鉴权标识,由致胜平台监控中心维护,当用户调用大模型接口时,通过取配置文件中的信息可以确认调用方用户的相关信息,其中:
是否vip标识:用来标识用户的重要级别,取值“true”为Vip用户,反之则为Normal用户,Vip用户的优先级要整体大于Normal用户。
优先级:默认为1,值越大则优先级越高,用于给同一级别的用户进行优先级排序。
会话数:默认为1,标识当前用户占用的资源数,数值越大,占用的资源数越高。
任务资源竞争机制的设计原理图如图4所示。
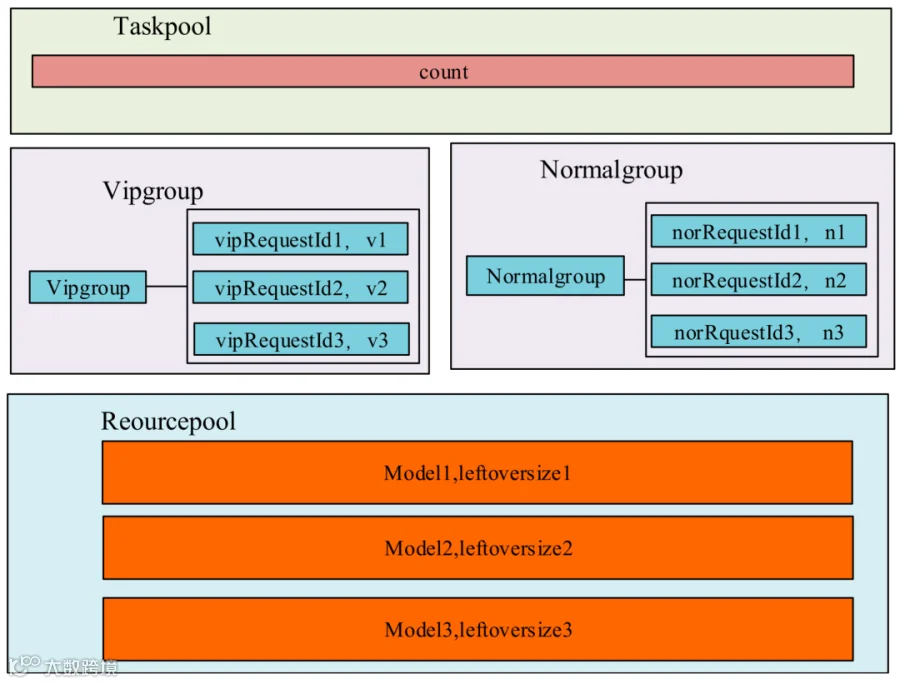
图4 任务资源竞争机制原理
其中,Taskpool表示服务同一时间可以接受到的任务数,在redis中用一个k-v键值对来存储,当接收一个任务时count数加1,执行完任务时,count数减1,对任务总数设定一个上限,当达到上限时不再接收新任务。
Vipgroup和Normalgroup采用zset数据结构,用来存储具体的任务目录,根据发起方Apikey,Vip用户的请求会存入Vipgroup,普通用户请求存入Normalgroup,value为任务的requestId,score为任务的优先度。任务初始的执行优先度根据用户的优先级取值来确认,Vipgroup整体优先级大于Normalgroup,每次由优先度最高的任务获得执行权限,其他任务延时等待并将优先度加1,下一次重新竞争。这样就构建出一个虚拟的令牌竞争队列,可以保证重要的系统或用户优先获得大模型资源的调用权限。
Reourcepool用来标识各个模型的资源量,防止同一时间请求某一模型的请求过多,进而导致大模型服务卡顿甚至宕机。Reourcepool是多个k-v键值对结构,key值为模型种类,value为剩余的资源量。根据大模型的统一接入模板,为各个大模型初始化一个总的资源容量,当某一请求获得执行权限时,根据当前用户的会话数取值,从当前资源容量中扣减相应的资源数作为新的剩余资源容量,任务执行结束时释放资源。当某一模型的资源容量无法满足当前任务的需求时,任务暂时挂起,等待资源释放,直到有足够的剩余资源。
大模型流量调配模块整体运行流程图如图5所示。
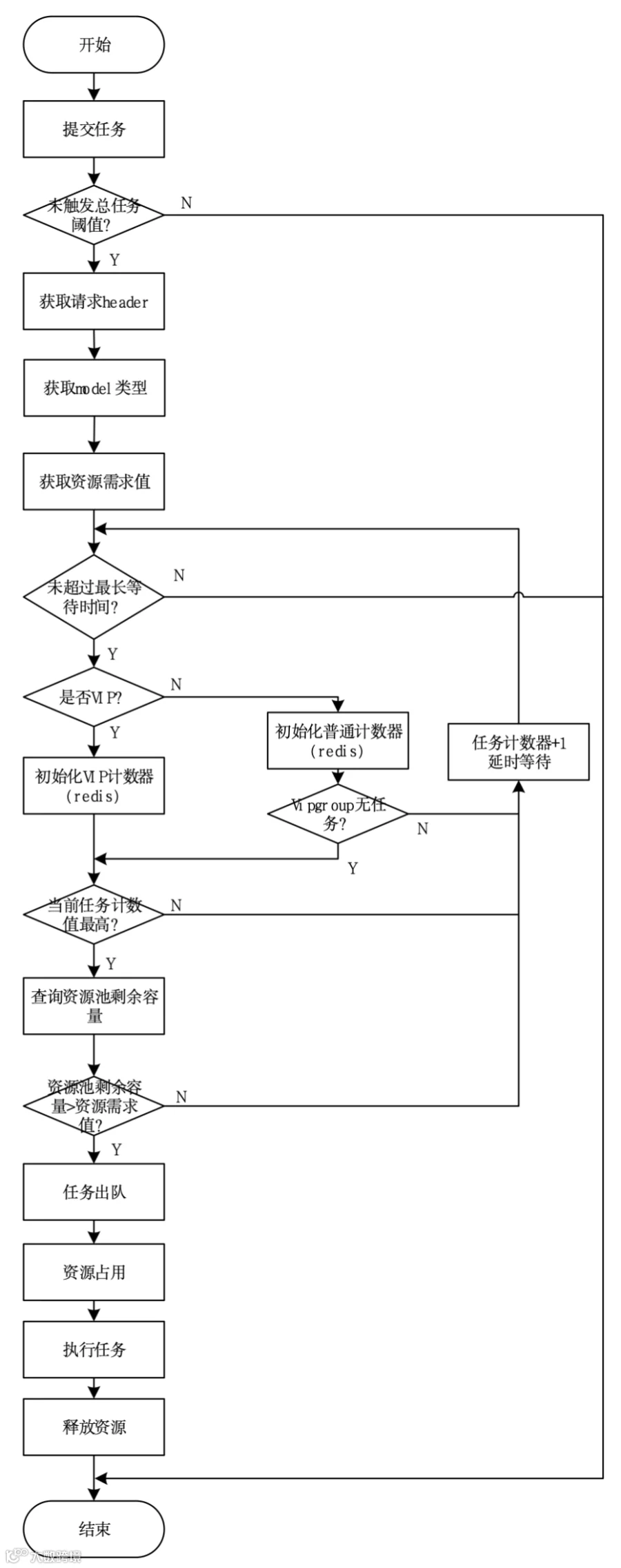
图5 大模型流量调配模块运行流程图
3、大模型调用统计模块
大模型调用统计模块主要作用是从任务、日期、模型三个维度统计模型的调用量和请求结果,方便后续的展示和问题排查。数据表设计结构如图6所示。

图6 大模型调用统计模块数据表设计模型
其中,reqlogdata是任务维度的请求统计信息表,用来记录每条请求的关键信息,如请求的chatid,apikey信息,模型名称,是否流式调用,问题信息,请求开始时间,请求结束时间,请求成功与否,失败时的错误原因,提示词token用量,生成token用量,总token用量等信息。
usageofmodels是模型维度的统计信息表,按日期和模型统计token使用量。
totalusage是日期维度的统计信息表,按日期统计所有模型的token总使用量。
三、大模型统一管控服务实践效果
1、大模型敏捷化拓展支持
大模型统一管控服务,通过统一的入口实现了不同大模型接口的调用,同时支持私有化大模型和公有云大模型。后续只需修改配置文件即可实现新模型支持,真正做到了敏捷扩展。当前支持的大模型种类及参数如表1所示。
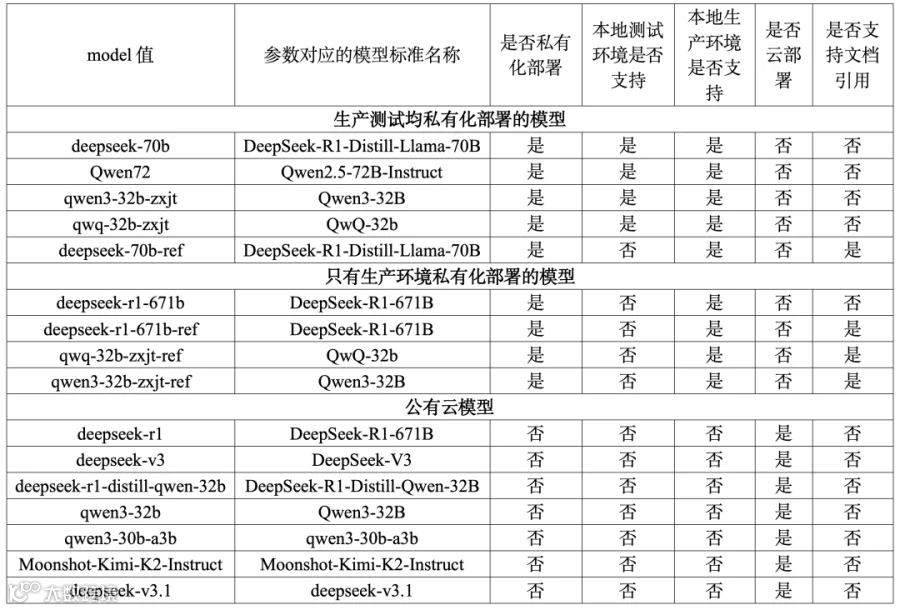
表1 当前支持的大模型种类一览表
2、重点业务场景优先调度实现降本增效
大模型统一管控服务的上线,可以根据业务类型的重要程度分配用户的重要级别,保证重点业务能优先调度到资源,在有限的资源下实现资源利用率的提升,进而实现降本增效。
当前通过大模型统一调度服务进行大模型调度的业务系统已达10余个,大模型接口日均调用量8000+次,日峰值调用量18000+,系统运行整体平稳。后续随着更多系统接入大模型,大模型统一管控服务的吞吐量会更创新高。
3、大模型调用记录形成结构化日志
大模型统一管控服务,通过结构化的数据表,将用户调用的关键信息和日均调用的统计信息进行存储,形成结构化日志。在运维分析过程中,可以直接根据用户传输的requestid信息定位到具体请求记录,便于在调用出错时的问题排查。
四、总结与展望
大模型技术是信息技术发展的重要方向,随着大模型的应用普及,对大模型资源的调度管理探索是极具现实意义的研究课题。当前大模型统一管控服务,初步实现了大模型调度的集中管理,并为后续的服务功能扩充和完善搭好了框架。后续规划中,功能层面上大模型管控服务会逐步完善多规格的大模型支持;合规层面上架设围栏,过滤用户输入和模型输出,使其满足合规要求;运维层面上,构建可视化的监控和操作页面,实现大模型统一管控服务向大模型管理系统的过渡。

