
YIXIN·AI·FINTECH
聚焦汽车金融智能化新阶段
2026· AI

【编者按】本文系统解读了易鑫训推一体平台推理模块的技术实践,诚挚感谢该平台团队在撰写过程中提供的全方位支持和专业指导。
全球正迎来一场由AI驱动的生产力革命,而Agentic AI正成为这场革命的核心引擎。
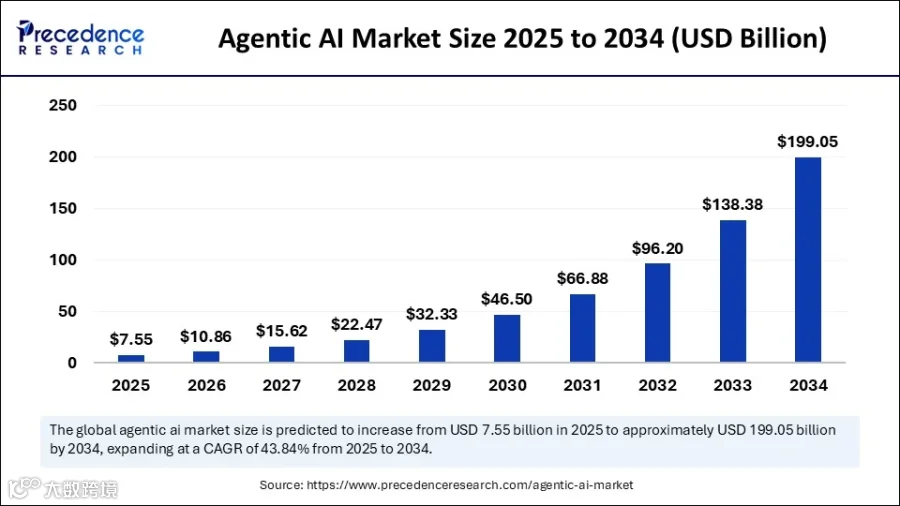
Precedence Research等多家机构预测,全球Agentic AI市场将以超过40%的复合年增长率加速扩张,预计到2034年市场规模将突破1,900亿美元(约合1.3万亿人民币)。
在这个万亿规模的蓝海市场,金融行业凭借完善的数据基础、严密的闭环逻辑与强劲的服务需求,成为全球Agentic AI落地变现的核心赛道。
在这条极具潜力的赛道中,汽车金融场景极具代表性。
一笔融资业务涵盖从渠道到资管等多个环节,涉及渠道、资方与消费者之间的多方博弈,并伴随着海量合同影像、通话录音、面审视频等非结构化多模态数据。
面对如此复杂的业务链路和数据处理需求,即便是业内成熟的通用AI产品,也常常面临适配性不足、推理成本高、模型幻觉频发和稳定性欠缺等挑战。
更关键的是,作为一个需要持续感知、实时决策、动态反馈的复杂智能系统,Agentic AI要在高度专业的金融场景稳健落地,必须构建从底层基础设施到上层业务应用的全栈式AI体系。
作为国内规模领先、AI驱动的金融科技平台,易鑫深谙这一产业逻辑,不仅推出了汽车金融行业专属的Agentic AI解决方案,还打造了能支撑其在复杂场景中稳健落地的训推一体平台。

该平台完整覆盖训练与推理两大核心模块,本文将围绕平台推理模块展开,拆解易鑫依托工程创新,打造兼顾大厂级高性能、金融级高可用推理平台的落地思路。
推理平台:支撑Agentic AI商业化的基石
易鑫从底层基础设施切入的逻辑,源于对Agentic AI发展趋势的判断:
当模型能力逐渐趋于成熟,决定AI能否规模化落地的关键,已从模型能力转向工程化能力。
企业不仅需要模型“足够聪明”,更需要其在真实业务场景实现低延迟、高并发、高稳定和可持续运营。
在这一过程中,推理平台成为连接模型能力与业务价值的关键基础设施。
如果说训练平台负责提升模型能力,那么推理平台负责将模型能力转化为生产力。
它将训练完成的静态模型转化为可随时调用的在线服务,是支撑AI规模化应用与商业变现的基石。
基于这一判断,易鑫持续完善推理平台的落地建设。
在架构设计上,易鑫采用原生K8s(Kubernetes)推理架构,支持vLLM、SGLang、Triton等主流框架,并兼容OpenAI、Anthropic等标准接口。
无论接入自研、开源还是商用模型,该平台都能做到「零代码改造、即插即用」。
在此基础上,易鑫还围绕汽车金融业务特点,从算力管理、极速部署和弹性扩缩三个维度进行了工程化创新。
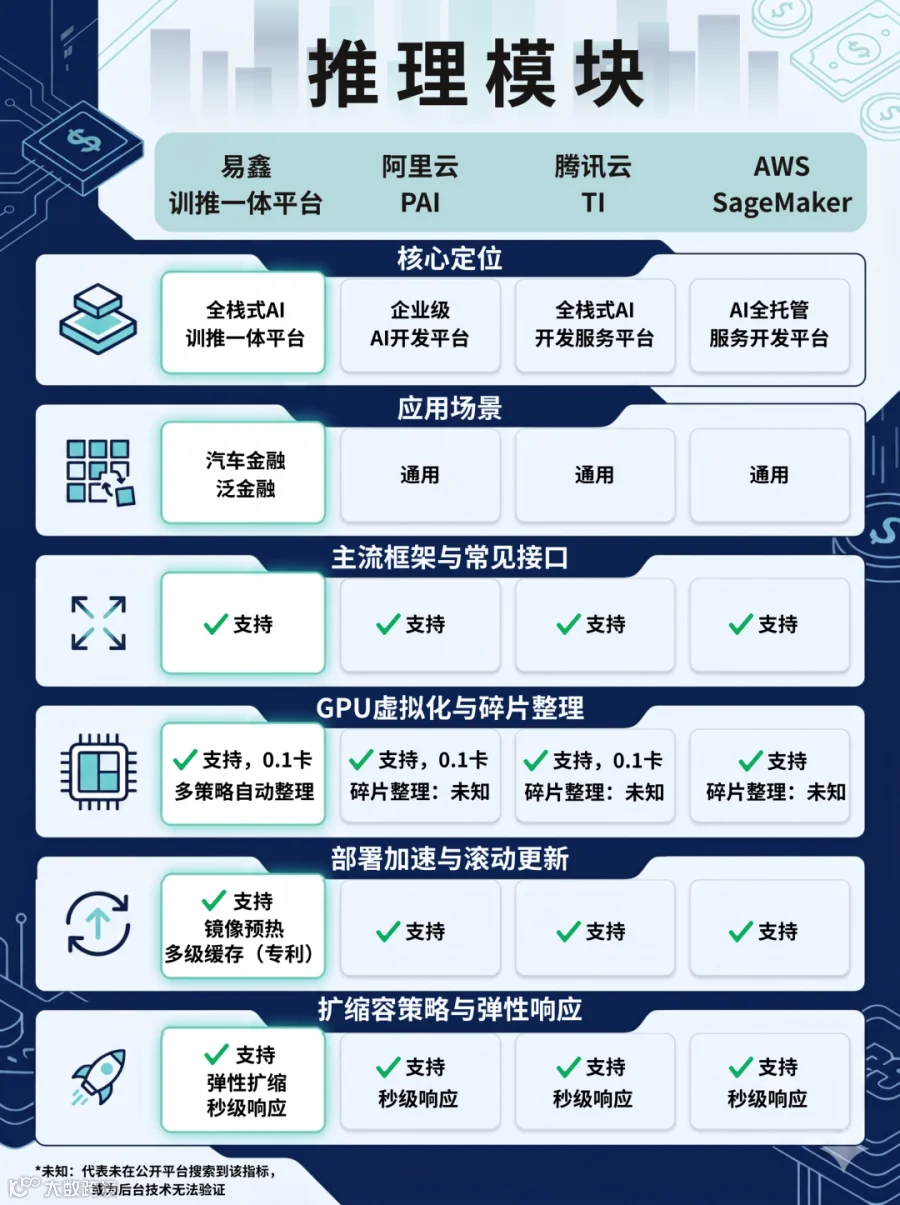
1. 算力管理
精细化调度,让每一分算力都创造价值
易鑫工程化创新的起点,是对算力资源进行精细管理。
行业数据显示,GPU平均利用率普遍偏低。在不考虑外部因素的情况下,提高利用率的突破口在于打破传统粗放的管理模式:一个任务(模型)独占一张GPU。
以OCR识别、人脸核验、反欺诈、信用评分等应用为例,在传统模式下,这类高并发小任务通常仅需使用约10%-40%的算力,却要独占整张GPU,导致大量算力资源浪费。
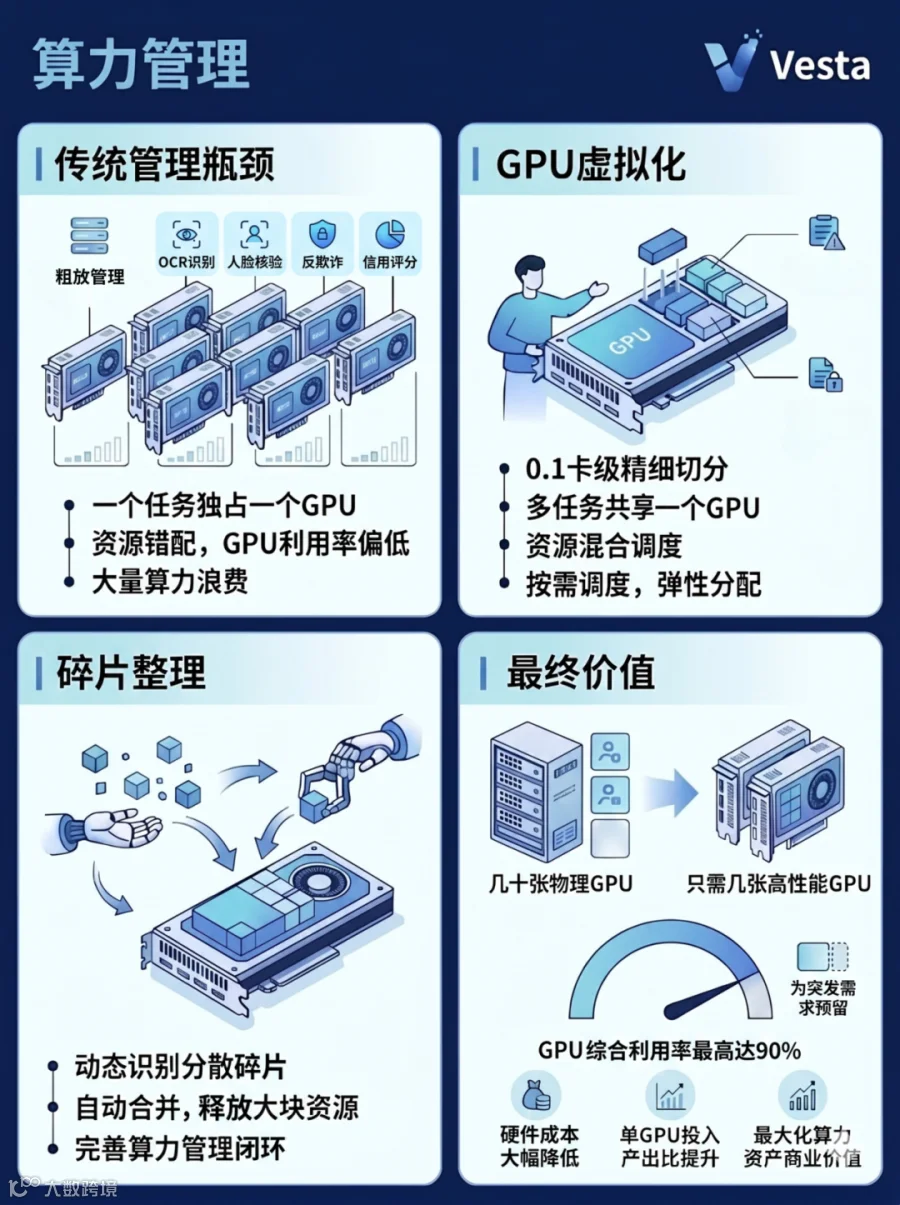
针对这一痛点,易鑫在平台引入GPU虚拟化技术,支持0.1卡级别的算力切分。简单来说,该技术将一张物理GPU拆分为多个独立算力单元,多个任务可共享这块算力资源。
过去被单一任务独占的物理GPU,如今可同时混合运行高算力需求的Agentic任务和低算力消耗的风控任务,实现按需调度、弹性分配。
最终效果也立竿见影。原本需要几十张物理GPU才能支撑的并发场景,如今只需几张高性能GPU通过切分即可完成,硬件成本大幅降低。
此外,针对GPU虚拟化产生的算力碎片,该平台依托内置的多策略自动整理机制,实现对分散算力的动态识别与智能合并,持续释放完整可用的GPU资源,进一步打通算力管理闭环。
在为突发需求预留算力资源的基础上,易鑫将集群GPU综合利用率最高拉升至90%,大幅提升了单GPU的投入产出比,让每一份算力资产都释放出最大的商业价值。
2. 极速部署
分钟级上线,告别「上线即停机」
解决了算力管理的问题后,接踵而来的考验便是「部署效率」。
在汽车金融的电销、客服、风控等核心业务中,模型迭代较为频繁,对部署速度提出了极高的要求。
传统模型部署方式存在两大痛点:
一是镜像拉取慢,单次耗时数分钟至数十分钟;
二是冷启动延迟高,模型加载、初始化及运行时预热耗时较长。
两者叠加,模型部署耗时最高甚至可达数小时。这不仅会拖慢迭代节奏,也难以保障故障修复的时效性。
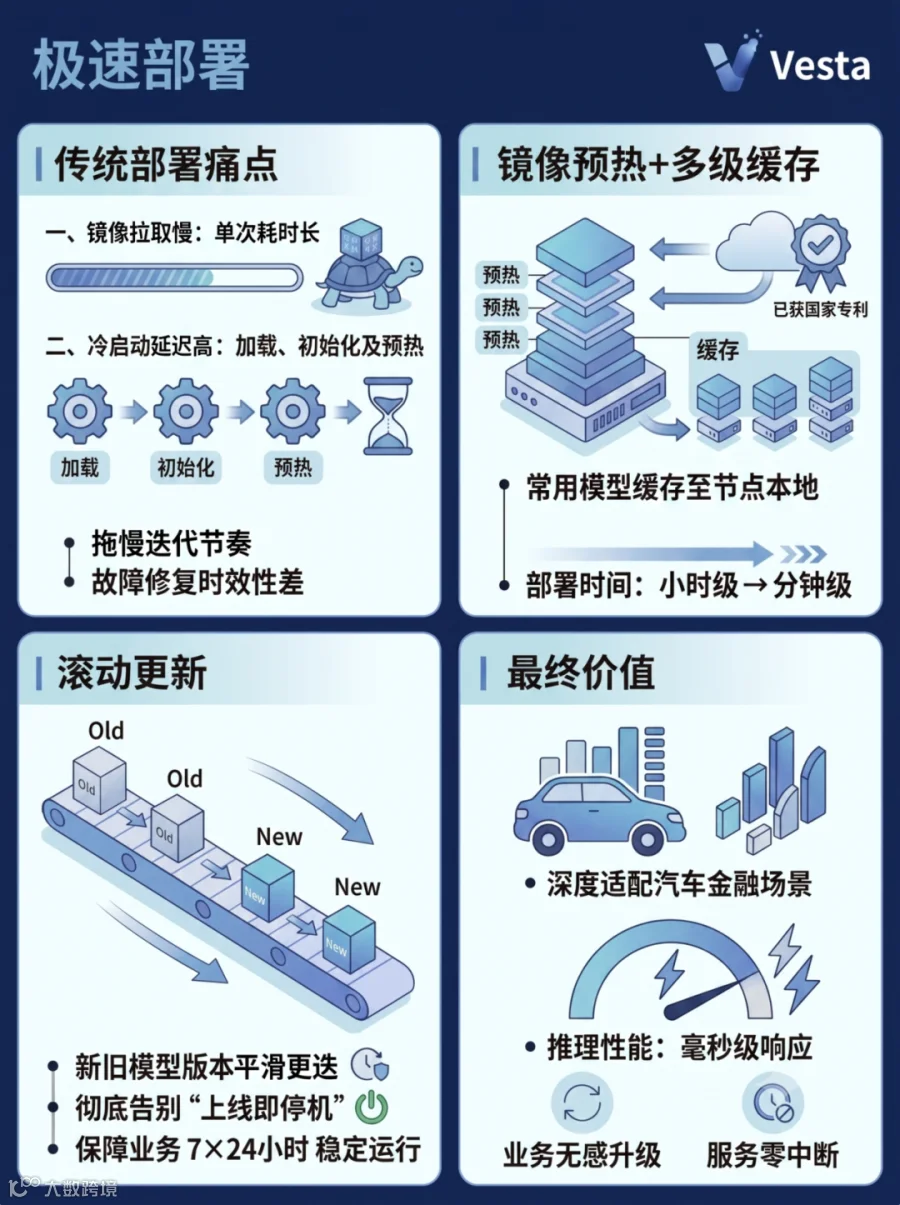
为此,易鑫采用镜像预热与已获国家专利的多级缓存技术(专利名称:一种多级缓存访问方法、系统、设备及存储介质),提前将常用模型缓存至节点本地,上线时省去重复拉取与加载等耗时步骤,模型部署时间由小时级缩短至分钟级。
在模型上线环节,该平台全面采用滚动更新策略,新旧模型版本平滑更迭,系统彻底告别“上线即停机”,确保核心业务7×24小时稳定运行,实现业务无感升级、服务零中断。
值得一提的是,在追求部署效率的同时,易鑫并未牺牲推理性能。在深度适配汽车金融场景的前提下,该平台依然保持着毫秒级响应速度,丝毫不逊于阿里、腾讯等一线互联网大厂。
3. 弹性扩缩:
秒级响应,从容应对业务流量波动
对于金融级AI应用而言,「快」只是基础,「稳」才是生命线。
汽车金融业务流量具备较明显的波动特性,如何在流量高峰和突发期确保服务稳定性是重要考验。传统单一响应式扩容往往反应滞后,难以及时匹配流量变化,从而影响整体业务效率与服务稳定性。
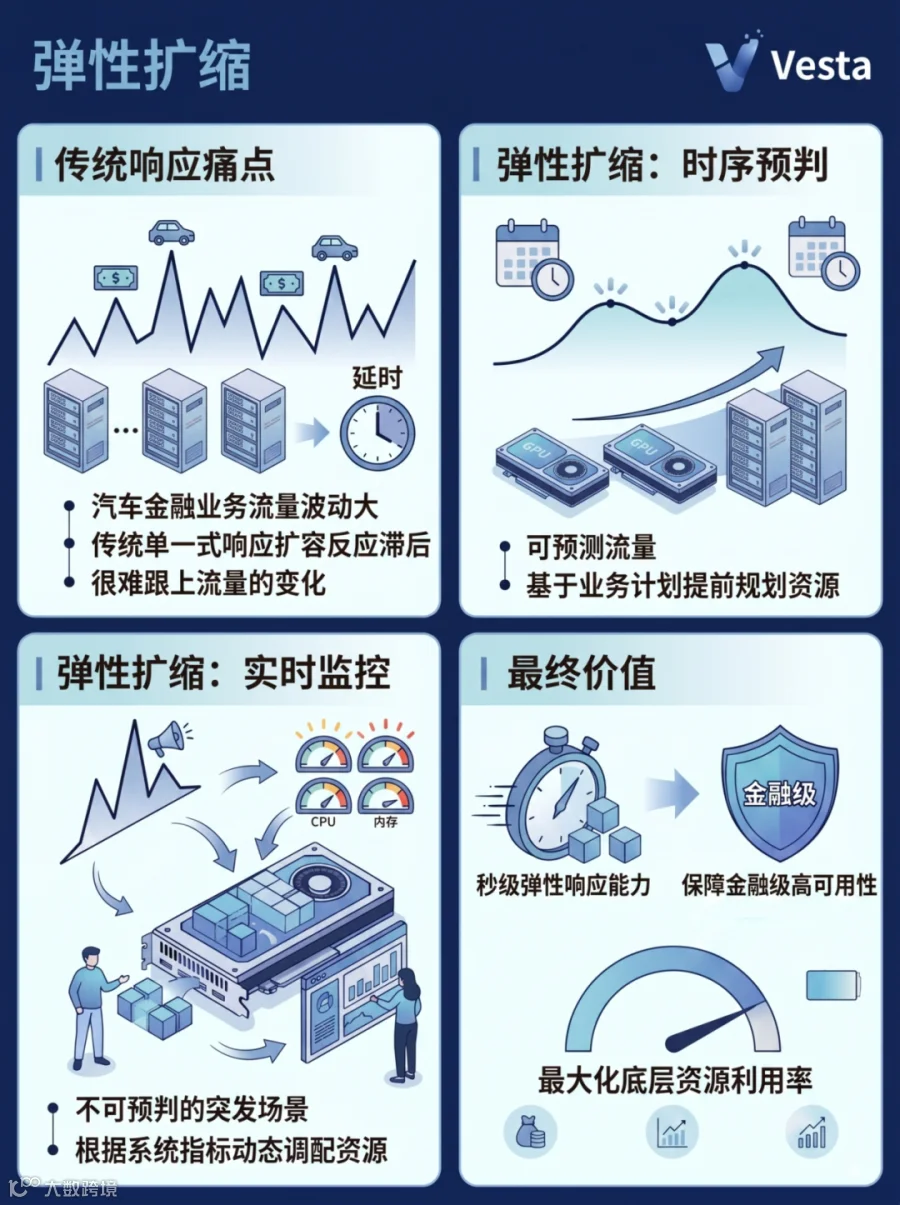
针对这一问题,易鑫采用了结合「时序预判+实时监控」的双模式弹性扩缩策略。
时序预判策略主要针对规律性高并发场景等可预测的流量,基于业务计划提前规划资源。
例如,针对电销团队固定的大规模外呼,系统会自动提前增加计算资源,确保首通电话拨出时,算力已全部就位,保障接通率与转化效果。
实时监控策略则针对不可预判的突发场景,根据实时的系统指标(如CPU、QPS等)动态调配资源。
例如,面对某条营销短信引发的客户集中回拨,系统24小时实时监控GPU负载状态,一旦越过安全阈值,平台会迅速拉起新节点,从容应对流量峰值,并在流量回落时自动释放多余资源,避免浪费。
更难得的是,该平台具备了对标头部互联网厂商的秒级弹性响应能力,在保障金融级高可用性的同时,实现了底层资源利用率的最大化。
结语
向下扎根,向上生长
构建金融级AI商业化护城河
正如英伟达CEO黄仁勋、Perplexity CEO Aravind Srinivas、Cursor CEO Michael Truell等硅谷AI专家的共识:
AI时代的机遇,不再是盲目追求通用大模型,而是深入金融、医疗、法律等垂类场景,用技术解决真实的业务痛点,创造可衡量的商业价值。
从技术探索走向商业变现,易鑫的领先之处在于,不仅在上层构建了行业适配的Agentic AI解决方案,更从底层打造了托底效率与成本的训推一体平台。
向下,依托GPU虚拟化、极速部署、弹性扩缩等技术,提升算力利用率与业务效率;
向上,全面拥抱Agentic AI,深度联动Harness治理框架,将人机协同融入业务闭环。
这种全栈式打法,不仅让AI在垂直场景中跑得稳、跑得省、跑得快,也为整个行业的智能化升级提供了一套极具商业价值的实践样本。
在Agentic AI这条万亿规模的快车道上,易鑫正以引领者的姿态,解码属于汽车金融的未来。
参考资料
https://www.precedenceresearch.com/agentic-ai-market
https://cast.ai/press-release/2026-state-of-kubernetes-optimization-report/
留言有奖
欢迎大家在评论区留言!
我们将根据内容质量及点赞回复数量选出5位关注易鑫AI的用户,每人将获得一份易鑫精美周边礼品。快来参与吧!
END

扫码可获取职位详细信息

易鑫AI
视频号丨抖音丨B站
小红书丨知乎丨微博

点赞
收藏
分享