

在一个典型的AI Agent项目里,“加一套长期记忆”这件事,往往比想象中要重。
团队的设想通常很朴素:让 Agent 记住用户说过的偏好、记住上一轮任务的上下文、记住知识库里沉淀下来的事实。
但真正动手时,常常会卡在这几个地方:
◎ 记忆能力难发现、难复用:每个项目都要重新对接一遍读写接口,自己拼检索逻辑,团队之间的经验很难直接迁移。
◎ 接入成本高:从零搭集成,要处理写入、读取、检索、去重一整条链路,光是把它跑稳就要耗掉不少工程时间。
◎ 跑起来之后不够"踏实":高并发场景下检索慢,反思(reflection)在负载高的时候结果不稳,数据多了之后还要担心重复和脏数据。
这些问题的共同点是:它们都不在“记忆算法本身”上,而在“记忆能力怎么被接入、怎么被信任”上。
红熊AI记忆科学MemoryBear v0.3.9版本(代号“破军”)这次更新,主线只有一件事:让记忆能力更容易被接入、被信任。
围绕这条主线,本次版本做了四件事:
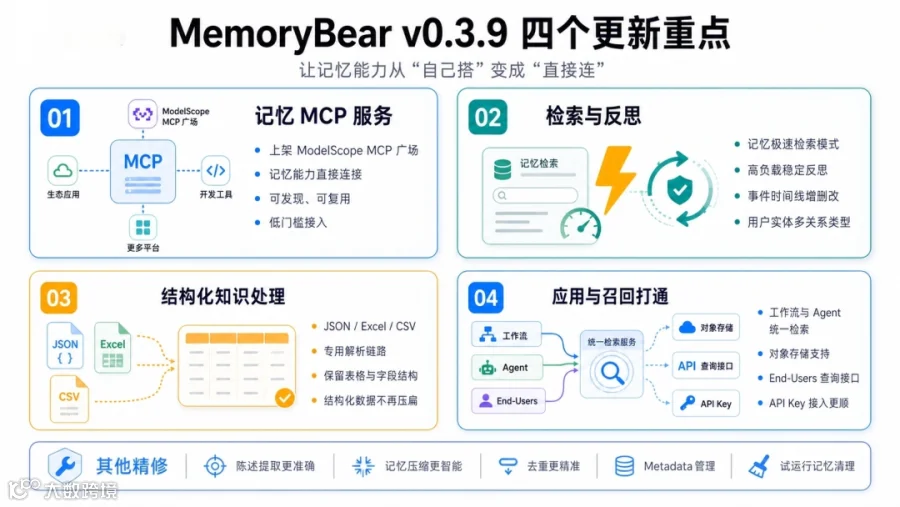
01 记忆MCP服务上架ModelScope MCP 广场:记忆能力第一次接入主流开放 AI 生态,从"自己搭"变成“直接连”。
02 检索与反思更快更稳:新增记忆极速检索模式,反思在高负载下稳步产出。
03 结构化知识处理:JSON / Excel / CSV 走专用解析链路,结构化数据进知识库不再"被压扁"。
04 应用与召回打通:工作流与 Agent 共享统一检索能力,叠加对象存储支持。
记忆MCP服务上架ModelScope MCP广场:从“自己搭”到“直接连”
昨天,记忆科学MemoryBear的记忆MCP服务,正式上架了ModelScope MCP广场。这意味着记忆能力第一次接入了一个主流的开放AI生态——开发者和 Agent 构建者可以在广场里直接发现、连接并使用 MemoryBear 的记忆能力,而不必再从零搭一套集成。
先用一句话解释 MCP:它是一种让大模型和 Agent 调用外部工具、外部能力的协议。当一项能力以 MCP 服务的形式存在,调用方不需要关心它内部怎么实现,只要"连上、调用"就能用。
举个常见的场景:一个团队在 ModelScope 上构建自己的 Agent,希望给它加上长期记忆。在过去,这件事的起点是"读文档、对接口、写适配层"——先搞清楚记忆服务的读写接口长什么样,再把写入、读取、检索一条条接进自己的代码,最后还要花时间把这套集成调稳。
现在,这条路径被大幅缩短了:在 MCP 广场里找到 MemoryBear的记忆服务,连接,然后直接调用。记忆能力从一个“需要自己搭建的子系统”,变成了一个“可以即插即用的外部能力”。
具体接入体验指南,可以参考:
红熊AI记忆科学登陆ModelScope MCP生态,欢迎体验
这件事的价值,不只是省了几天集成时间。它改变的是记忆能力被使用的方式:
◎ 可发现:
记忆能力出现在一个公共的入口里,而不是藏在某个项目的私有代码中。
◎ 可复用:
不同项目、不同团队连接的是同一套标准化能力,经验和配置可以沉淀、可以迁移。
◎ 低门槛:
让原本需要专门工程投入的"记忆集成",变成 Agent 构建流程里的一个标准步骤。
对正在ModelScope生态里做Agent的开发者来说,这相当于把“要不要自己做一套记忆”这个沉重的问题,换成了“连上一个现成的记忆服务”这个轻量的选择。
检索与反思:更快的响应,更稳的产出
接入门槛降下来之后,下一个问题就是:连上之后,它跑得好不好?
记忆熊v0.3.9在“快”和“稳”两个方向上都做了实打实的改进。
❖ 记忆极速检索模式:为响应敏感的场景而设计
这一版新增了记忆极速检索模式,面向那些对响应速度特别敏感的场景,提供更快的检索响应。
举个常见的场景:一个实时对话型 Agent,用户每说一句话,系统都要先去记忆里检索相关上下文,再决定怎么回应。如果检索这一步慢上几百毫秒,对话的"跟手感"就会明显下降;在高并发时,这种延迟还会被放大。
极速检索模式正是为这类场景准备的——当你需要的是"尽快拿到相关记忆"而不是"穷尽所有细节"时,可以用更快的方式拿到响应。它不替代完整检索,而是为延迟敏感的链路多提供了一种选择。
❖ 反思更可靠:高负载下也能稳步产出
记忆系统里的“反思”,可以理解为系统对已有记忆做的二次加工:归纳、提炼、形成更高层次的结论。它是让记忆“越用越聪明”的关键一环,但也恰恰是计算密集、对负载敏感的一环。
这一版让反思引擎在高负载下也能稳步、安全地产出结果。对于跑在生产环境、需要长期连续运行的记忆系统来说,这种"压得住"的稳定性,往往比峰值性能更重要——它意味着系统在真实流量下的表现是可预期的。
❖ 让记忆结构更可维护
除了快和稳,这一版还在记忆的"结构"上做了两处增强:
◎ 事件时间线增删改:
支持对实体事件时间线的新增、更新和删除。记忆不再是只能往里写、不能修正的流水账,而是可以被持续维护的结构化时间线。
◎ 用户实体多关系类型:
同一个实体之间可以建立多种维度的关系,从而构建出更立体的实体关系网络,而不是只能表达单一关联。
结构化知识处理:
JSON/Excel/CSV走专用链路
记忆之外,知识库是这一版另一个集中发力的地方,重点是结构化数据。
过去,把一份Excel或CSV喂进知识库,常常会遇到一个尴尬:这些天然带着行列结构、表头、层级关系的数据,被当成普通文本"压扁"处理,结构信息在解析过程中流失,检索时自然也就找不准。
记忆熊v0.3.9为结构化数据开了一条专用解析链路:JSON、Excel、CSV不再走通用文本解析,而是按各自的格式特点来处理。
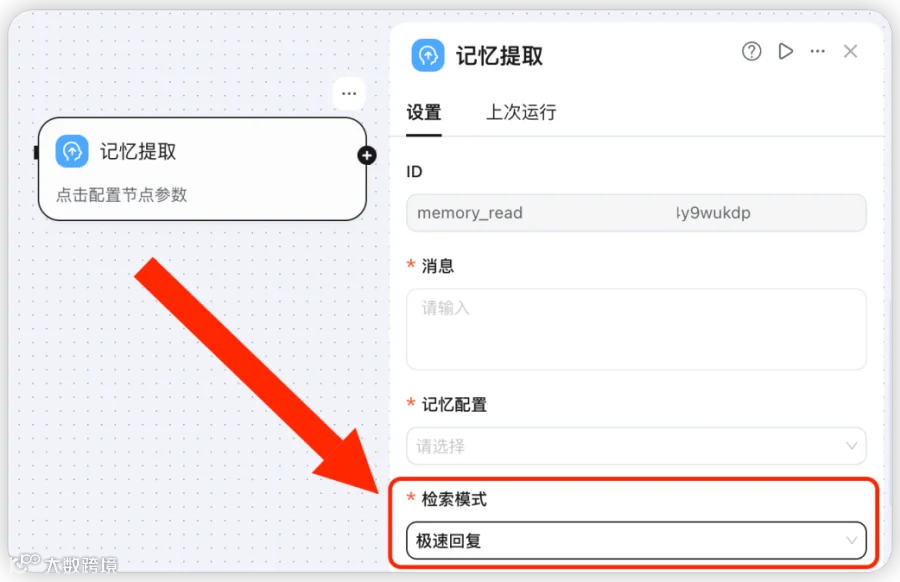
其中最值得说的是新增的结构化 Excel 解析器。它能识别:
◎ 多个Sheet:一个工作簿里的不同表分别处理,不再混作一团;
◎ 合并单元格:正确还原合并单元格背后的语义,而不是留下一堆空值;
◎子表与表头:识别表头和子表结构,让每一行数据都带着正确的字段含义被存下来。
举个常见的场景:数据团队手里有一份业务报表 Excel,里面有合并的表头、按月份分的子表。把它直接喂进知识库后,系统能理解"这一列是什么、这一行属于哪个子表",于是后续的 RAG 检索能更准地命中真正相关的那几行,而不是返回一堆结构错乱的碎片。
配合这条链路,这一版还增强了父子分块模式识别——系统会统一判定文档的分块结构并返回 parent_child_mode,让分块的处理方式对上层更透明。分块流程本身的稳定性与可扩展性也一并得到了提升。
应用与召回:统一检索,叠加对象存储
最后一组更新,关于“记忆和知识怎么被应用层用起来”。
统一知识召回:这一版让工作流和 Agent 共享同一套检索能力。也就是说,无论你是在工作流里编排一个检索节点,还是让 Agent 自主调用检索,背后用的是同一套统一的召回逻辑。
这件事的好处很直接:行为一致、维护成本低。举个常见的场景——一个团队既有用工作流搭的固定流程,又有需要灵活应变的 Agent。过去这两条路径的检索表现可能存在细微差异,调优时要分别照顾;现在它们落在同一套能力上,调一处、两边都受益。
对象存储支持:文件存储这一层增加了对象存储支持,提升了可扩展性与可靠性。对于文件量大、需要长期稳定存放的部署来说,这是一块更结实的底座。
面向集成和运营,这一版还补了两个接口层面的能力:
◎ End-Users 查询接口:
新增/v1/dashboard/end_users,支持分页查询用户与对应的记忆数量。运营和数据视角下,"有多少用户、各自积累了多少记忆"终于有了一个直接的查询入口。
◎ API Key 接入更顺畅:
创建 API Key 时会同步返回关联的用户标识,省去了再绕一圈去查对应关系的麻烦。
其他更新
除了上面四条主线,这一版还有一组面向体验和细节的改进:
▫︎记忆提取更准确:陈述提取的准确性提升,字段结构更简洁;
▫︎记忆压缩更智能:在压缩时更好地保留时间、重要事件等关键信息;
▫︎去重更精准:真正重复的内容才稳定归并;
▫︎Metadata管理:支持字段的正确增、删、改;
▫︎试运行记忆清理:自动清理临时记忆,提升数据质量;
▫︎知识库详情页UI调整、工作流画布操作栏下移;
▫︎导航菜单更名:"应用管理"更名为“Agent 管理”。
写在最后
随着Agent应用从Demo走向生产,记忆能力的两个属性正在变得越来越关键:
一个是可接入性——能不能被轻松地连接和复用;另一个是可靠性——在真实负载下跑得稳不稳、查得准不准。
MemoryBear v0.3.9把记忆服务接入ModelScope MCP广场、让检索更快、让反思更稳、让结构化知识被正确理解、让工作流与 Agent 共享统一召回——这些事情加在一起,指向同一个方向:让记忆不只是一个存储层,而是真正能被生态接入、能支撑长期交互的基础设施。
当记忆能力足够容易接入、又足够值得信任,Agent 的长期可靠性才会自然浮现。
