关键词:推荐专栏 | 未来人类 | 趋势洞察
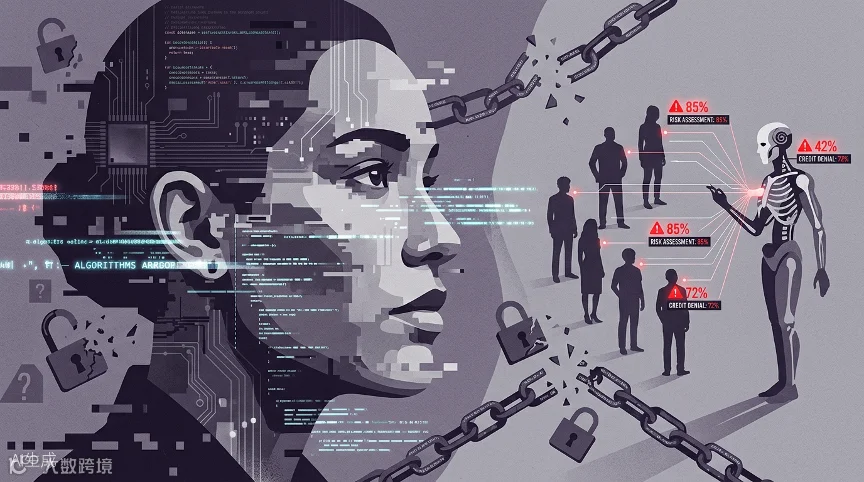
"AI是中立的"——这一信念在2026年已被彻底证伪。算法不是从真空中产生的,它们学习自人类社会积累的数据,而人类社会充满了历史性的偏见和不平等。当这些偏见被编码进决策系统时,技术的"客观性"反而成为不平等的新面具。
招聘领域的性别歧视。 2026年初,某头部互联网企业的简历筛选AI被曝光对女性工程师求职者自动降权。调查发现,该系统的训练数据来自该公司过去五年的招聘记录,而历史数据中男性工程师占比高达78%。AI从历史中"学习"到了"工程师=男性"的隐性关联,并将其固化为决策规则。尽管企业在事后采用AIF360工具检测群体分布,通过对抗去偏训练(λ=0.7)使性别偏差指标下降了42%,但已经造成的伤害无法逆转——数百名合格的 female 候选人在不知情的情况下被系统排除。
金融风控中的阶层偏见。某银行的风控系统过度依赖企业规模指标,导致中小企业贷款误拒率达到17%。更具隐蔽性的是某互联网银行的案例:该系统使用"夜间交易活跃度"作为信用评估维度,结果河北某农村养鸡合作社的授信额度仅为城市商户的30%。算法将农村从业者"早睡早起"的作息模式误判为"交易行为异常",本质上是将城市生活方式默认为"标准行为模式"。
医疗诊断中的种族差异。最触目惊心的案例来自医疗领域。美国23家医院联合研究发现,某商业皮肤病检测AI对深色皮肤患者的误诊率比对白人患者高出40%。原因简单却致命:训练集中白人患者图像占比超过80%。这意味着,当一位黑人患者使用该系统进行皮肤病变筛查时,他获得准确诊断的概率系统性低于白人患者。在医疗场景中,这种偏见可能直接危及生命。
偏见的产生机制。算法偏见通常产生于三个层面:数据层(训练数据本身存在代表性偏差)、算法层(模型设计对特定群体不敏感)和应用层(部署环境加剧了既有不平等)。上述案例中,招聘AI的偏见主要来自数据层,风控系统的偏见更多来自应用层——将特定场景下训练的模型泛化到不同社会经济环境中。
2026年,个人数据收集的广度和深度已达到前所未有的水平,而保护机制仍在追赶之中。
高校人脸识别事件。 2026年初,某高校未经充分知情同意采集学生面部数据,用于课堂考勤和情绪分析。技术漏洞导致3000名学生的生物特征信息泄露,被倒卖至网贷平台。事件曝光后,教育部紧急叫停全国高校的人脸识别项目审查,但已有超过200所高校部署了类似的系统。这些系统采集的数据不仅包括面部特征,还涵盖学生的出勤模式、课堂注意力分布、情绪状态——本质上是对学生行为的全方位监控。
"全选式"授权协议的泛滥。某高校使用的"全选式"授权协议强制学生同意所有数据收集条款,否则无法使用教务系统。这种"要么全同意、要么别用"的模式在2026年仍然普遍存在。中国《个人信息保护法》虽然明确规定了"数据最小化"和"可删除权"原则,但在实际执行中,企业和机构往往通过技术手段规避法律约束。
跨平台数据合谋。更隐蔽的威胁来自数据的跨平台流转。2026年3月,一项调查发现,某知名短视频平台将用户观看数据与关联的电商平台共享,用于精准推荐。单独的观看记录或购物记录可能看似无害,但当两者结合时,可以推断出用户的健康状况、政治倾向、财务状况等敏感信息。这种"数据拼图效应"使得碎片化的个人信息汇聚成完整的个人画像,而用户对此几乎毫无掌控力。
生物特征数据的不可逆风险。与密码不同,面部特征、指纹、声纹等生物特征一旦泄露,无法像更改密码那样"重置"。2026年4月,某医院基因数据泄露事件波及30万名患者,包括癌症易感基因检测结果。这些数据一旦进入黑市,可能被保险公司用于歧视性定价,或被雇主用于就业歧视。
算法偏见和数据 privacy 不是孤立的技术问题,而是深嵌在社会经济结构中的系统性挑战。
技术垄断加剧不平等。 AI技术集中在少数国家和企业手中。全球AI研发支出的70%集中在美国和中国,顶尖AI研究人员中有60%任职于不到20家企业。这种集中化意味着AI系统的价值取向主要由少数精英群体决定—— predominantly 白人、男性、高收入的技术从业者。当这些人的偏见(无论 conscious 还是 unconscious)被编码进影响数十亿人的系统时,技术垄断就转化为价值垄断。
"数据殖民主义"的新形态。发展中国家在AI时代面临双重困境:既是全球数据的主要生产者(通过社交媒体、移动应用产生海量数据),又是AI技术的主要消费者(进口发达国家开发的AI产品),却鲜少参与AI系统的规则制定。非洲、拉丁美洲的数据被用于训练面向全球市场的AI模型,但这些模型往往以发达国家的使用场景为优化目标,对发展中国家的适应性不足。
自动化决策的"黑箱困境"。当AI系统做出对个人有重大影响决策时(拒绝贷款、拒绝求职、标记为"高风险"),当事人往往无法理解决策依据,更难以申诉。欧盟《AI法案》要求高风险AI系统提供可解释性说明,但"可解释性"本身就是一个技术难题——如何在保持模型性能的同时,让深度神经网络的决策过程对人类透明?2026年的研究显示,现有解释性方法的准确度仅为60%-70%,远未达到法律要求的可靠性标准。
面对日益严峻的伦理挑战,全球监管机构在2026年加快了立法步伐,但成效参差不齐。
欧盟:最严标准的示范效应。欧盟《AI法案》将AI应用按风险等级分为四类:不可接受风险(如社会信用评分)、高风险(如信贷评估、招聘筛选)、有限风险(如聊天机器人)和最小风险。高风险AI必须满足数据质量、透明度、人类监督等严格要求。法案的域外效力意味着,任何希望在欧盟市场运营的AI企业都必须遵守这些规定——这使得欧盟标准事实上成为全球标准。
中国:从原则到执行的推进。中国《生成式人工智能服务管理暂行办法》要求AI服务提供者对训练数据来源的合法性负责,禁止生成歧视性内容。《个人信息保护法》确立了"知情-同意"的基本原则。2026年新修订的《生成式AI服务管理办法》进一步要求企业建立"算法备案"制度,向监管部门披露核心算法逻辑。但在执法层面,地方监管能力的不均衡导致政策执行存在显著差异。
美国:碎片化的州级立法。联邦层面的统一AI伦理法规在2026年仍未出台,但加利福尼亚州、纽约州等已通过地方性的AI透明度法案。加州的《自动化决策工具透明度法案》要求企业披露使用AI进行就业决策的情况,赋予求职者"选择退出"自动化评估的权利。这种碎片化的监管格局给企业合规带来挑战,但也为不同监管模式的比较提供了自然实验。
行业自律的兴起。在监管滞后的领域,行业自律机制开始填补空白。2026年,由谷歌、微软、Anthropic等企业发起的"AI伦理联盟"发布了行业自律准则,承诺定期发布算法影响评估报告、建立独立伦理审查委员会。但这些自律机制缺乏强制执行力,其有效性取决于企业的自愿遵守。
2026年,一个新兴职业正在快速升温——AI伦理顾问。这一趋势的兴起反映了技术治理需求的结构性转变。
三重驱动力。技术迭代的伦理真空、监管框架的强制性升级、市场需求的结构性转变,共同推动了这一职业的爆发。欧盟《AI法案》、中国《个人信息保护法》、ISO/IEC 42001等法规强化了企业的伦理审查义务,但企业内部普遍缺乏具备跨学科背景的专业人才。AI伦理顾问的角色正是填补这一缺口——他们需要理解机器学习的技术原理、熟悉数据保护的法律要求、具备伦理分析的哲学素养,同时能够将这些知识转化为可操作的合规方案。
从边缘到主流。 2026年初,AI伦理顾问主要存在于大型科技公司和金融机构。到年中,中小企业和初创公司也开始聘用这一角色——或是全职,或是以自由顾问的形式。自由职业模式因灵活性和低成本优势受到青睐:一家AI初创公司可能不需要全职伦理顾问,但在产品上线前进行为期两周的伦理审查则十分必要。
技能成长的新路径。对于从业者而言,AI伦理领域提供了从传统合规、审计、风险管理岗位转型的路径。核心的技能组合包括:AI系统的基本技术理解、数据保护法规的专业知识、伦理分析框架的应用能力、跨部门沟通与协调能力。2026年,多所高校已开设AI伦理方向的硕士项目,为企业提供专业化的人才储备。
AI伦理与社会影响的讨论,最终指向一个根本性问题:技术发展是否自动等同于社会进步?
2026年的实践给出了明确答案:不是。AI技术在提升效率的同时,也在复制和放大既有的社会不平等。算法偏见让弱势群体面临更隐蔽的歧视,数据隐私的侵蚀使个人在数字空间中日益"透明",技术垄断将AI的话语权集中在少数精英手中。
应对这些挑战,需要超越纯粹的技术视角,拥抱"技术人文主义"——将人的尊严、社会公平、文化多样性置于技术发展的核心位置。这意味着:在AI系统的设计阶段就纳入多元化的参与者(不仅仅是技术人员),在部署阶段建立持续的伦理监测机制,在治理层面推动更具包容性的规则制定。
DeepSeek团队有一句话值得深思:"AI不是要取代人类,而是要赋予每个人超能力。"但"超能力"的分配是否公平,取决于我们此刻的选择。
来源:综合公开报道、行业研究报告及政策文件整理
配图:AI生成
本文内容基于互联网公开信息及AI生成整理,仅供行业资讯参考,不代表本平台立场。如文中内容涉及侵权或存在事实争议,请邮件联系 aitrendshub@qq.com,我们将及时核实并处理。