

关注下方“公众号”,获取更多开源资讯
导读
机场、地铁、快递分拣线的 X 光安检,每天产生海量图像,但绝大多数系统仍靠人工判图——安检员盯着屏幕逐帧辨认,疲劳、漏检、误判是行业常态。传统目标检测模型(YOLO、DETR 等)虽然能框出可疑物品,但遇到新类型违禁品就"抓瞎",更谈不上"理解"图像内容。视觉语言模型(VLM)本可以靠图文对齐能力解决开放词汇问题,但 X 光安检领域一直缺少高质量的大规模图文配对数据,导致通用 VLM 在安检场景上"水土不服"。
文章信息
-
标题:OneFocus: Enabling Real-World X-ray Security Screening with a Unified Vision-Language Model
-
作者:Jiali Wen、Hongxia Gao、Litao Li、Yixin Chen、Kaijie Zhang、Qianyun Liu、Xiaoqin Wen -
机构:西安交通大学、华南理工大学、深圳 Loop Area 研究院、琶洲实验室
一、问题与产业痛点:X 光安检 AI 为什么"看得清"却"看不懂"
X 光违禁品检测是高风险安全场景(机场、火车站、地铁、快递物流)的核心环节。随着客流量和包裹量持续增长,监管对违禁品识别的要求越来越严,但当前绝大多数安检点仍高度依赖人工判图——安检员盯着 X 光屏幕逐帧辨认,工作强度大、注意力易分散,漏检和误判难以避免。
现有的技术路线主要分为两类,但各自都有明显短板:
第一类是专用目标检测框架,如 SDANet、AENet、DOAM、LIM、AO-DETR 等。这些方法通过精心设计的特征融合机制提升定位和分类精度,在预定义类别上表现不错。但致命缺陷是无法处理开放词汇——遇到训练时没见过的新型违禁品(如新型液体伪装、新型刀具变种),模型直接"失明"。此外,这些方法只能输出边界框和类别标签,不能回答"这个包里有什么""这把刀在什么位置""为什么判定为违禁品"等需要语义理解的问题。
第二类是视觉语言模型(VLM),如 CLIP、LLaVA、Qwen2.5-VL 等。VLM 的核心优势在于通过大规模图文预训练获得了强大的开放词汇理解和跨模态对齐能力。但直接把通用 VLM 搬到 X 光安检场景,效果往往很差——原因不是模型不够强,而是训练数据与目标域的鸿沟:
-
通用 VLM 在自然图像上预训练,而 X 光图像具有独特的物理成像特性(低纹理、高穿透、材质依赖衰减、伪影多),视觉语义与自然图像差异巨大; -
X 光安检领域长期缺乏高质量的图像–标题配对数据。现有数据集(GDXray、SIXray、OPIXray、HiXray、PIDray、114Xray 等)要么类别少、要么样本量小、要么严重缺乏多模态标注——绝大多数只有边界框或像素级掩膜,没有自然语言描述; -
唯一的多模态数据集 STCray 虽然引入了 45,693 条标题,但类别覆盖只有 21 类,且标题由固定模板生成,文本丰富度不足,限制了理解型模型的训练。
这形成了一个"鸡生蛋、蛋生鸡"的困境:没有高质量多模态数据,就训不出好用的安检 VLM;没有好用的安检 VLM,就没人愿意投入资源构建数据。本文的核心贡献正是打破这个循环——从数据构建到模型训练,给出了一套完整的 X 光安检多模态智能解决方案。

图片来源于原论文
二、数据与方法设计
2.1 MMXray:目前最大规模的 X 光安检多模态基准
MMXray 包含 52,124 图像–标题对,覆盖 28 个细粒度违禁品类,数据来源包括机场、地铁站、包裹分拣线等真实安检场景,并补充了物理可信的合成数据。与现有数据集相比,MMXray 在四个维度上实现了突破:
-
准确性(Accuracy):标题由 Qwen2.5-VL 生成后经人工验证,确保事实正确; -
全面性(Comprehensiveness):支持视觉问答、违禁品定位、分类、图像理解四项核心任务; -
多样性(Diversity):覆盖从轻微遮挡到严重重叠的全谱遮挡条件; -
规模与粒度(Strong):52,124 对数据、28 个细粒度类别,类别分布均衡。
28 个细粒度类别包括:手机、充电宝、手铐、斧头、剪刀、警棍、子弹、锤子、枪支、金属柄菜刀、塑料柄菜刀、钳子、压缩气体、柱状电池、塑料瓶装液体、玻璃瓶装液体、金属瓶装液体、折叠刀、弹簧刀、直刀、美工刀、多功能刀、塑料柄刀、金属柄刀、塑料打火机、笔记本电脑、手榴弹、烟花。
2.2 AnyContraSyn:物理感知的 X 光违禁品合成方法
X 光成像遵循 Beer-Lambert 定律,像素强度 与入射强度 和材料光程 的关系为:
传统的 Mixup 等数据增强方法直接对像素值做线性插值,在 X 光场景下会产生不真实的材料叠加效果。例如,将两个光程分别为 和 的图像用 Mixup 混合,得到 ,而物理上正确的叠加应该是 。
AnyContraSyn 从 Beer-Lambert 定律出发,在衰减域中进行融合:
这种方法保证了:融合在物理上正确、非遮挡区域保持原始 X 光外观、支持任意数量违禁品与任意背景的组合。为了获得干净的前景违禁品图像和背景图像,团队从真实安检场景采集数据,使用 APSAM 提取违禁品区域并去除冗余背景,构建了 CleanDET数据集(28 类干净违禁品 + 多密度背景)。基于 CleanDET,AnyContraSyn 生成了 3,000 张高保真遮挡违禁品图像用于增强 MMXray。
合成过程还引入了掩膜约束的放置策略:通过 MobileSAMv2 获取前景和背景掩膜,确保违禁品完全放置在包裹区域内,并通过白画布嵌入保持分辨率一致性和背景纯净度。
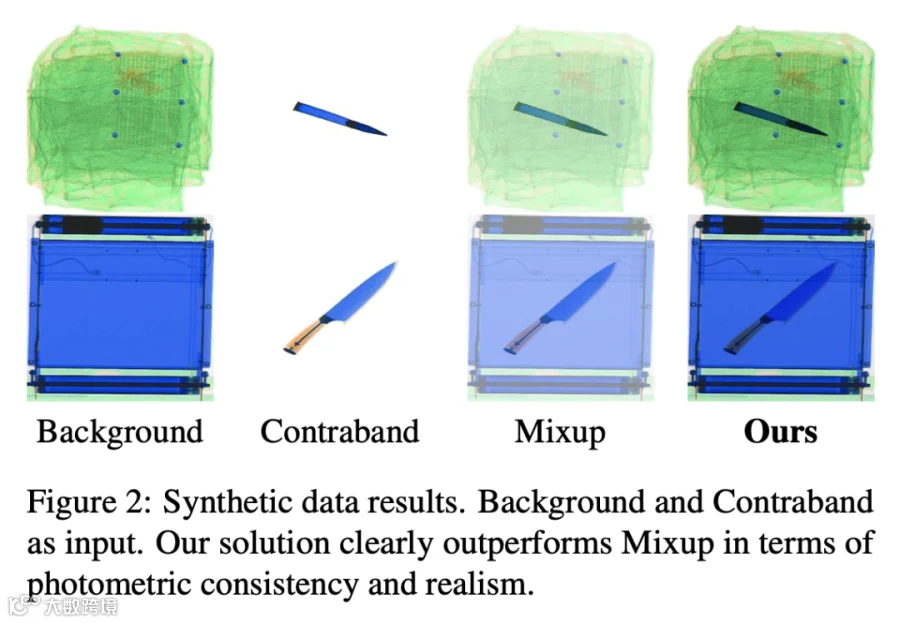
图片来源于原论文
2.3 OnePipe:可扩展的半自动标注流水线
X 光安检领域的高质量图像–标题配对数据极度稀缺。OnePipe 是一个三阶段流水线,用于系统性获取、清洗和重标注 X 光违禁品图文数据:
-
阶段 1:数据过滤。剔除分辨率低于 200 像素的图像,通过边界框与分割掩膜的一致性检查排除歧义样本,保留模型的计数能力; -
阶段 2:数据标注。人工标注 20,000 条标题,覆盖六个关键视觉属性:违禁品类、颜色、数量、近似位置、容器上下文、边界框坐标。使用 Qwen2.5-VL-32B 生成初始标题,经人工验证后用 LoRA 微调 Qwen2.5-VL-7B 得到专用 Captioner;Captioner 再为额外 10K 图像生成标题,人工验证后通过 GPT-4o 改写以提升语言多样性,再进行第二轮微调; -
阶段 3:半自动标注。精炼后的 Captioner 用于标注剩余图像,严格遵循同样的清洗和重标注协议。
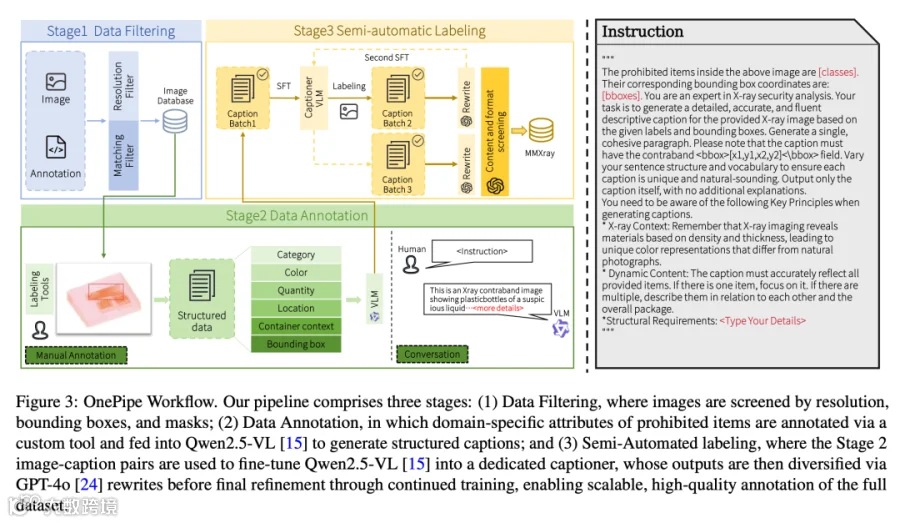
2.4 混合格式问答数据:支持四项核心任务
基于 OnePipe 生成的标题,团队构建了多轮对话数据,支持四项任务:视觉问答(VQA)、违禁品定位、分类、图像理解。与 STCray 仅使用模板化短回答不同,本文采用开放式 + 单选题混合格式,定义了六个评估维度:
-
实例位置(Instance Location):查询违禁品在包裹中的空间位置; -
实例计数(Instance Counting):统计违禁品数量; -
实例身份(Instance Identity):分类风格的类别识别; -
实例特征(Instance Feature):开放式描述物体特征,鼓励综合视觉推理; -
误导性(Misleading):引入高度迷惑性的干扰项,测试判别能力; -
基础理解(Basic Understanding):基于 X 光成像原理的领域知识问答。
每个标题被扩展为 2–4 轮事实一致的对话,测试集仅保留单选题(2–5 个选项,共 2,924 题),并通过语义相似的干扰项和反模板化设计防止捷径学习。
2.5 OneFocus:统一视觉语言基线模型
OneFocus 基于 Qwen2.5-VL-7B 架构(视觉 Transformer 编码器 + 两层 MLP 投影器 + Qwen2.5 LM-7B 文本解码器),采用两阶段渐进训练策略:
-
阶段 1(全量微调):在 X 光图像标题数据上对 LLM 进行全量微调,建立开放式视觉理解基础。批大小 64,余弦学习率调度(前 100 步预热,终值 ),DeepSpeed-Zero2,训练 1 个 epoch; -
阶段 2(LoRA 适配):在阶段 1 基础上,对 LLM 的所有线性层注入 LoRA(rank 16,alpha 32),在多轮对话数据上微调,覆盖 VQA、定位、分类、图像理解四项任务。批大小 128,DeepSpeed-Zero3,训练 2 个 epoch。
关键设计决策来自组件消融实验:仅微调 LLM 即可达到最佳性能(BLEU-1 55.43,ROUGE-1 54.61),LoRA 适配 LLM 甚至略超全量微调(BLEU-1 55.81,ROUGE-1 56.28)。冻结投影器反而优于联合微调,说明预训练投影器已足够泛化到 X 光图像;微调 ViT 编码器收益有限,确认主要挑战在于将固定视觉特征映射到领域特定语言概念,而非视觉表征本身。
三、关键实验结果:OneFocus 四项任务全面领跑
3.1 视觉问答(VQA):平均准确率 72.8%,超越 STING-BEE 25 个百分点
在六个子任务上的对比(论文 Table 6,测试集来自 STCray 和 MMXray,共 40,589 问答对、7,904 张独立图像):
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| OneFocus-7B | 76.5 | 60.7 | 75.2 | 94.8 | 69.7 | 60.0 | 72.8 |
OneFocus 在所有六个子任务上均取得最佳,平均准确率比第二名 Qwen2.5-VL-7B 高出 15.9 个百分点,比同为安检领域模型的 STING-BEE 高出 25.0 个百分点。尤其在"实例身份"(+19.1%)和"实例计数"(+15.5%)上优势显著,说明 MMXray 的细粒度标注和混合格式训练有效提升了模型的类别判别和数量统计能力。
3.2 分类:MMXray 上 F1 66.0%,比第二名高 19.9 个百分点
在三个基准数据集上的分类性能(论文 Table 7):
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| OneFocus | 29.5 | 30.8 | 29.4 | 34.7 | 66.0 | 60.9 |
OneFocus 在所有三个数据集上均大幅领先。在 MMXray 上,F1 比第二名 Qwen2.5-VL-7B 高出 19.9 个百分点,mAP 高出 13.7 个百分点;在 PIDray 上 F1 高出 6.9%,mAP 高出 8.0%;在 OPIXray 上 F1 高出 7.0%,mAP 高出 11.9%。这验证了 MMXray 数据在真实世界安检条件下的强大泛化能力。
3.3 违禁品定位:MMXray 上 mAP50 32.2%,比第二名高 11.7 个百分点
开放词汇定位性能对比(论文 Table 8):
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| OneFocus-7B | 18.5 | 31.2 | 32.2 | 51.6 |
OneFocus 在 MMXray 上 mAP50 达到 32.2%,比第二名 STING-BEE(20.5%)高出 11.7 个百分点;mAP25 达到 51.6%,高出 22.0 个百分点。在 PIDray 上 mAP25 也达到 31.2%,比第二名 GroundingDINO(22.6%)高出 8.6%。这说明 OneFocus 不仅能"说出"违禁品类别,还能"指出"它们在图像中的精确位置。
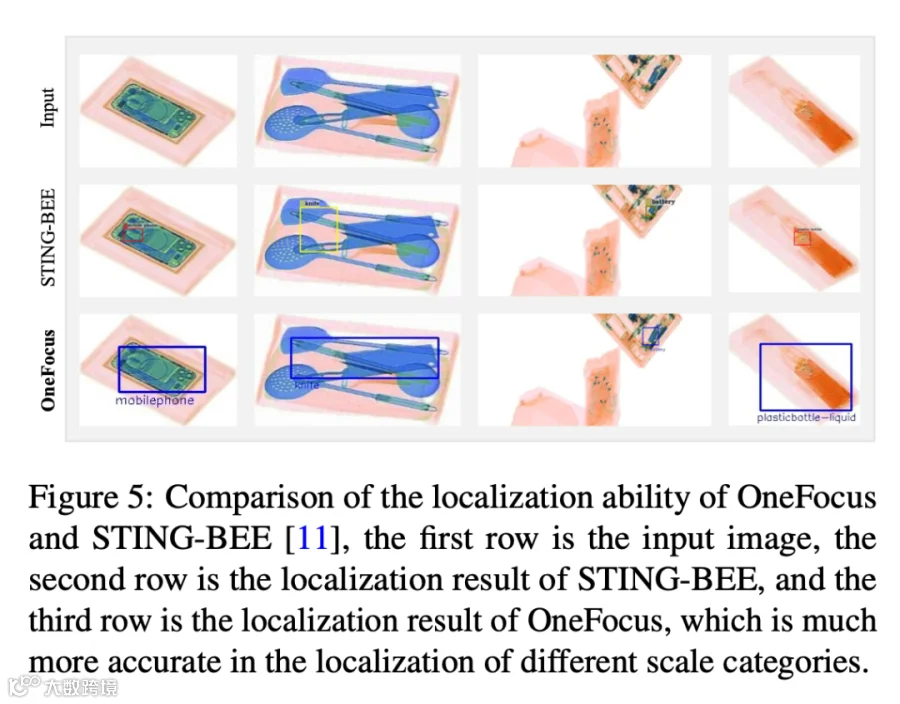
图片来源于原论文
3.4 图像理解:BLEU-4 12.3 / ROUGE-L 36.6,超越 STING-BEE 近一倍
开放式图像描述性能(论文 Table 9):
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| OneFocus-7B | 12.3 | 36.6 |
OneFocus 的 BLEU-4 比 STING-BEE 高出 5.4 个百分点,ROUGE-L 高出 8.9 个百分点。值得注意的是,STING-BEE 在单选题 VQA 协议下表现不错,但在开放式描述任务中性能大幅下降——这暴露了仅依赖短回答和模板化查询训练的局限性。OneFocus 通过混合格式训练(开放式 + 单选题),在保持指令遵循能力的同时,获得了真正的场景理解能力。
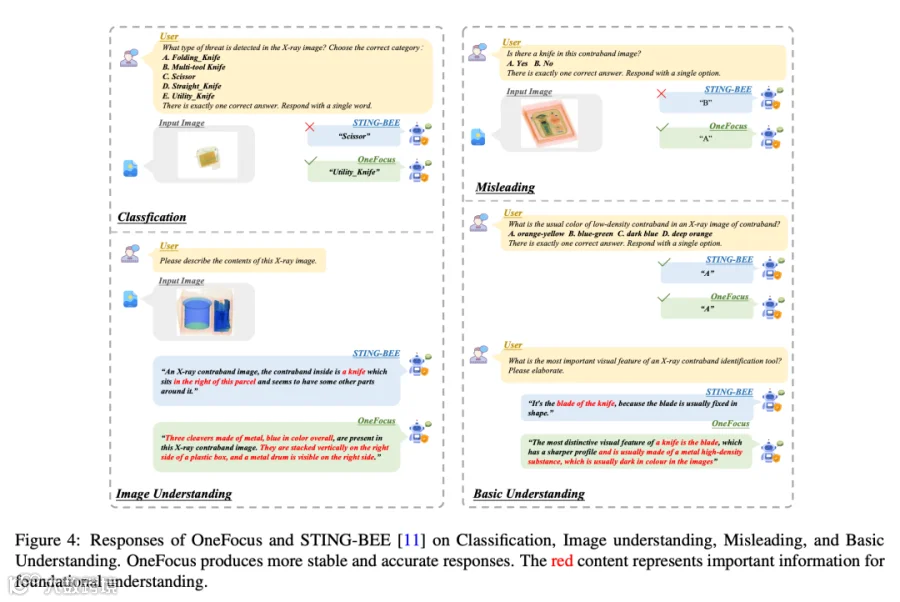
图片来源于原论文
3.5 跨域泛化:仅在 MMXray 上训练,零样本超越 STCray 微调模型
跨数据集零样本实验(论文 Table 11,OneFocus 仅在 MMXray 上训练,严格排除所有 STCray 样本):
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| OneFocus-7B | MMXray | 48.0 | 43.1 |
OneFocus 在零样本条件下 VQA 48.0、定位 43.1,虽然略低于在 STCray 上微调的 STING-BEE(52.8 / 46.5),但显著超越了同样在 MMXray 上训练的 STING-BEE(42.4 / 38.8),且远超未微调的 Qwen2.5-VL(32.5 / 21.1)。这说明 MMXray 使模型内化了 X 光成像原理和违禁品特征,获得了对未见数据分布和不同成像硬件的泛化能力,而非仅仅记忆训练集的噪声或偏差。
3.6 合成数据消融:两阶段都用合成数据,VQA 平均提升 8.1 个百分点
合成数据使用策略的消融(论文 Table 12 / Table 15):
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 两阶段都用 | 是 | 是 | 72.8% |
两阶段都使用 AnyContraSyn 合成数据时性能最佳,尤其在"实例身份"(+19.8%)和"实例特征"(+5.7%)上提升显著。这说明合成数据特别增强了模型学习违禁品组件级特征的能力——而严重遮挡场景下的组件识别,正是真实安检中最具挑战性的环节。
3.7 跨架构验证:数据质量比预训练规模更重要
论文 Table 10 的对比实验揭示了一个重要发现:虽然 Qwen2.5-VL 的预训练语料规模远大于 LLaVA-1.5,但未经微调的 Qwen2.5-VL(VQA 56.9%,定位 19.8%)在 MMXray 上微调的 LLaVA-1.5(VQA 55.6%,定位 36.3%)面前,定位性能差距巨大。这说明** specialized 领域任务性能的上限主要由高质量、领域特定的指令配对数据决定,而非通用预训练语料的绝对规模**。
四、讨论:OneFocus 的能力边界与失败案例
论文对 OneFocus 的局限性进行了坦诚分析,这些洞察对产业落地至关重要。
定位精度仍有提升空间。当多个违禁品具有相似视觉外观时,模型容易出现定位错误(论文 Figure 6)。这源于 VLM 天然优先语义对齐而非空间精度,视觉表征较粗粒度,缺乏坐标感知能力。重叠违禁品的混淆问题在 X 光安检中尤为突出——多个金属物品堆叠时,它们的衰减信号相互叠加,边界难以区分。
"No" 偏见现象。实验发现(论文 Table 13),未经充分领域微调的 VLM 在 X 光违禁品任务上存在强烈的"过度预测 No"偏见。当所有问题的正确答案都改为"No"时,模型准确率虚高;但在基础理解基准上表现仍差,说明这种提升是虚假的。OneFocus 通过 MMXray 的领域 grounding 有效缓解了这一偏见(Naive 条件下 69.7%,接近 100% No 条件下的 70.8%)。
STING-BEE 的模板化陷阱。STING-BEE 在单选题 VQA 上表现尚可,但在开放式图像理解任务中性能骤降(BLEU-4 仅 6.9),且存在 10.9% 的无效输出率(如只回复".")。这证明仅训练短回答和模板化查询会严重损害模型的指令遵循和推理能力——对需要自然语言交互的安检场景(如向安检员解释判定理由),这是致命缺陷。
五、总结与思考
把上述实验结论转化为给安检设备厂商、机场/地铁运营方、以及智慧安检平台技术团队的"落地指南":
-
数据先行:MMXray 的发布填补了 X 光安检多模态数据的空白。对于已有安检图像资源的企业,可以参考 OnePipe 流水线,将历史图像快速转化为带自然语言描述的指令微调数据,大幅降低 VLM 领域适配的门槛。 -
模型选型:在 7B 参数级别,OneFocus 已全面超越通用 VLM(Qwen2.5-VL、InternVL3.5)和领域专用模型(STING-BEE)。对于算力有限的边缘部署场景,7B 模型在 8 张 A100 上可完成训练,推理时温度参数设为 0.1 即可保证确定性输出。 -
合成数据策略:AnyContraSyn 的物理感知合成方法可直接复用。对于遮挡严重的场景(如行李中多层物品叠加),建议在两阶段训练中都引入合成数据,可带来约 8% 的 VQA 性能提升。 -
任务覆盖:OneFocus 同时支持"问答"(VQA)、"指出位置"(定位)、"是什么"(分类)、"描述内容"(图像理解)四项任务,适合构建统一的智能安检助手——既能辅助安检员快速判图,又能自动生成检查报告、向旅客解释判定依据。 -
开放词汇优势:相比传统检测模型只能识别预定义类别,OneFocus 的 VLM 架构具备开放词汇能力,遇到新型违禁品时可通过自然语言描述进行零样本识别,大幅降低"新型威胁漏检"的风险。 -
人机协同设计:当前 VLM 的定位精度仍有局限,建议在实际部署中采用"模型初筛 + 人工复核"的协同模式——模型负责快速标记可疑区域并生成描述,人工安检员负责最终确认和处置决策。
对安检设备制造商(如安检机厂商)、机场/地铁智能化改造服务商、以及快递物流安全平台而言,这项工作提供了一条"从数据到模型"的完整技术路径:不需要从零构建大规模标注团队,利用 MMXray + OnePipe + AnyContraSyn 的数据构建方案,即可快速训练出适配自身场景的安检 VLM。团队已承诺开源数据集和模型权重,这意味着产业界可以低成本复现和二次开发。
Coovally 团队持续关注工业缺陷检测领域的前沿进展,并在相关视觉算法方面有持续研发投入。如果您有技术交流或合作意向,欢迎联系我们和评论区留言讨论~
© THE END
转载请联系本公众号获得授权

 分享、点赞与在看,至少帮我拥有一个~
分享、点赞与在看,至少帮我拥有一个~