

关注下方“公众号”,获取更多开源资讯
导读
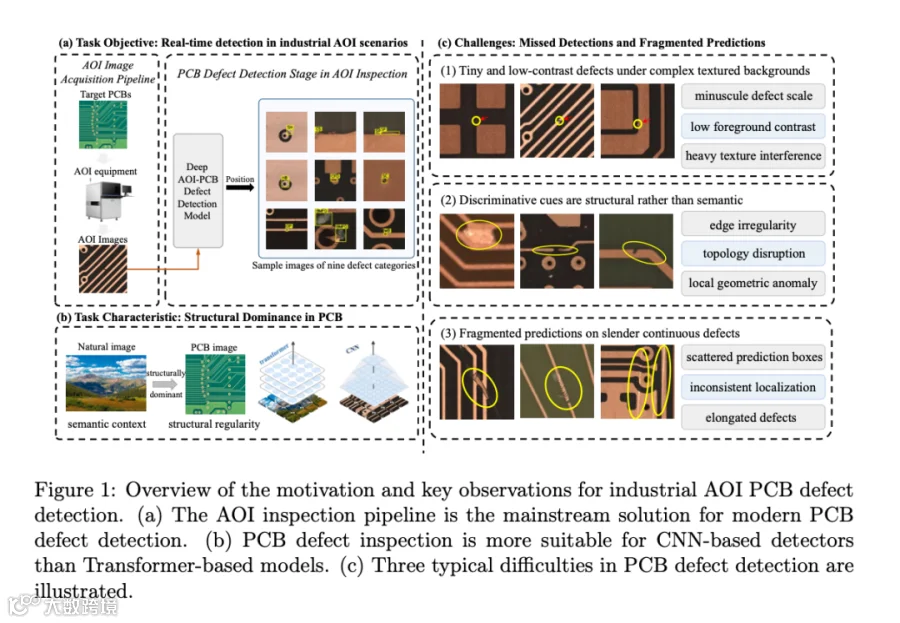
工业 AOI(Automated Optical Inspection,自动光学检测)一直被三类痛点缠住:缺陷又小又淡、特征是结构而非语义、细长缺陷会被切成多段碎框;同时 PCB 海量未标注图像也没法被传统 YOLO 这条监督路线吃透。
安徽大学等团队联合提出"两段式 PCB 缺陷检测框架"——前段用 SG-MIM(Structure-Guided Mixed Mask Image Modeling)+ 稀疏卷积重建,让 YOLOv8s 主干在无标签 PCB 图像上学到结构先验;后段在监督微调里加一项 Spatial Continuity Loss 来抑制"同一缺陷被拆成多框"的碎片化现象。在公开 DsPCBSD+ 数据集(9 类缺陷、10,259 张图、20,276 个标注)上把 YOLOv8s 的 mAP0.5 从 84.1% 拉到 85.5%、mAP0.5:0.95 从 50.7% 拉到 52.3%,并全面超过 RT-DETR、Co-DETR、YOLOv6-L6、YOLOv10 等 11 个强基线。
文章信息
-
标题:Structure-Guided Mixed Masked Pretraining and Spatial Continuity Regularization for Printed Circuit Board Defect Detection -
作者:Peitong Wang、Nuo Wang、Enxin Qin、Chengjin Yu、Hanyu Xuan、Yuanting Yan -
机构:安徽大学、中国科学技术大学、合肥综合性国家科学中心 -
数据集:DsPCBSD+(9 类 PCB 表面缺陷)
一、背景与挑战
PCB 是一切电子设备的"骨架",制造工序里的压合、钻孔、化铜、干膜等环节都可能引入缺陷,质检环节直接决定良率。传统人眼质检主观、慢、不一致;AOI 设备替代人眼后,深度学习又把 AOI 算法侧拉到了 YOLO、Faster R-CNN、RT-DETR 这些主流路线上。
但论文作者把 PCB AOI 场景的"真问题"拆得很清楚,分别落在视觉、表征、输出三层:
第一层是视觉层面。PCB 缺陷天然就是"小+弱+稀疏",背景却是高度规律但密集的导线、焊盘、过孔,前景与背景的对比度被严重压缩,特征判别力直接被稀释。
第二层是表征层面。PCB 缺陷的判别线索更多是结构性的——边缘是否规则、拓扑是否中断、局部几何是否畸变——而不是语义层面的"猫狗鸟"。CNN 主干靠局部卷积+层级聚合,跨区域结构关联能力天然不如 Transformer,但 Transformer 又不利于实时部署,这是工业 AOI 长期没法两全的矛盾。
第三层是输出层面。一阶段检测器(YOLO 等)面对 CFO、CS 这种细长且空间连续的缺陷时,会把一个缺陷拆成多个相邻小框,论文管这叫"fragmented prediction",事后 NMS 等启发式合并并没有从表示学习层面解决问题。
外加一个老大难——PCB 的像素级/实例级标注非常贵,监督数据天花板有限,但车间里其实积压着大量未标注图像,传统 YOLO 训练流程并没有把这些数据吃进来。
图片来源于原论文
二、核心方法
整体框架是两段式:阶段 A 做自监督预训练,阶段 B 做监督检测微调,主干统一用 YOLOv8s(CSP-Darknet 风格的卷积主干)。阶段 A 又拆出两个组件:结构引导混合掩码和稀疏卷积重建,合称 SG-MIM;阶段 B 在标准 YOLOv8 检测损失上叠加一项空间连续性损失。
阶段 A 第一个组件:结构引导混合掩码。
把 640×640 输入切成 16×16 图像块,对每张图同时用两类掩码:
-
随机掩码保留低层上下文学习能力; -
结构引导掩码通过对 PCB 图像做边缘和导线显著性提取,优先遮挡"导电图案密集、结构最关键"的区域,逼模型从可见的导线、焊盘片段去推断被遮的电路结构。
混合比例是关键超参,论文系统扫了 100:0 / 70:30 / 50:50 / 40:60 / 30:70 / 20:80 / 10:90 / 0:100 共 8 档,最终选 30:70(30% 随机 + 70% 结构引导)。整体掩码率固定 0.60。
阶段 A 第二个组件:稀疏卷积重建管线。
标准稠密卷积在被掩区域会用零填充并被卷积核"涂污",导致掩码区域的虚假激活回流到可见区,反而毁掉了掩码图像建模"以可见推不可见"的前提。论文把 YOLOv8s 主干的卷积换成稀疏卷积,让可见性掩码沿着卷积层一路传递,凡是源自被掩区的响应在编码阶段被显式抑制,最后只对被掩图像块计算重建损失。这一点是把掩码图像建模适配到卷积神经网络主干的工程关键。
预训练目标可以写成:
其中 是被掩图像块集合, 是稀疏卷积主干和解码器对该图像块的重建结果。预训练使用 AdamW 优化器,学习率为 ,权重衰减为 ,批大小为 64,训练 400 轮。

图片来源于原论文
阶段 B:空间连续性正则。
针对"同一缺陷被切成多个分散框"的输出层难题,论文在监督训练阶段对"被分配到同一个真实标注实例的多个正样本预测"施加紧凑性约束。简单说,就是让属于同一缺陷的预测框中心彼此靠拢,避免在缺陷区域内产生过度分散的多峰响应。完整训练损失为:
其中 是 YOLOv8 原生检测损失,包括边界框损失、分类损失和分布式焦点损失; 是空间连续性正则项, (论文消融选定)。值得注意的是, 只在训练时启用,推理阶段完全沿用原生 YOLOv8 流水线,不增加任何推理计算。
三、实验设置与对照基线
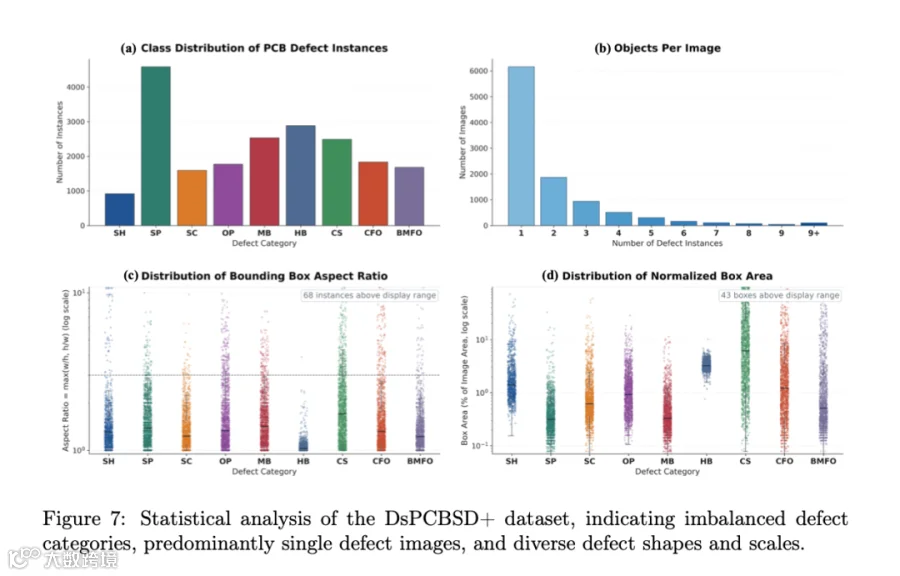
数据集:DsPCBSD+,9 类缺陷分别为短路(SH)、毛刺(SP)、多余铜(SC)、开路(OP)、鼠咬(MB)、孔破(HB)、导线划伤(CS)、导线异物(CFO)、基材异物(BMFO)。其中导线划伤和导线异物大量呈细长形态,与"碎片化预测"问题高度相关;毛刺与鼠咬多为小目标,对弱响应和背景干扰更敏感;孔破平均面积较大。
划分:官方 8:2,训练 8,208 张 / 16,184 标注,验证 2,051 张 / 4,092 标注。所有结果均在验证集上报告。
输入与训练:输入尺寸为 640×640,使用 AdamW 优化器;阶段 B 的学习率为 ,权重衰减为 ,批大小为 16,训练 100 轮; ;硬件为 RTX 4090D。
图片来源于原论文
评估指标:精确率、召回率、mAP0.5、mAP0.5:0.95,公式定义参见论文 (16)–(19)。
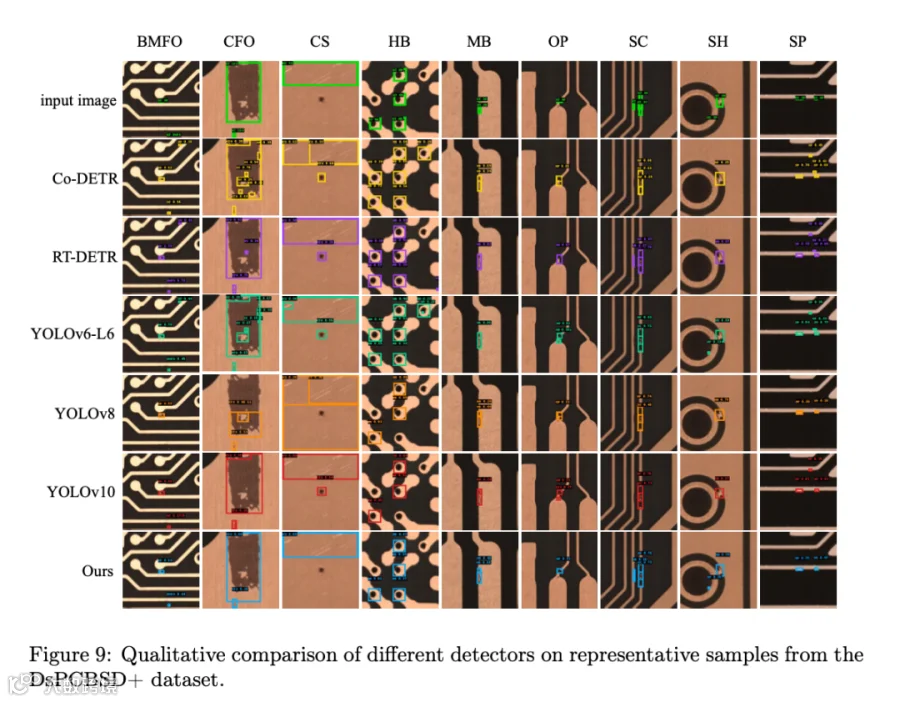
对照基线一共 11 个,覆盖了 PCB 自动光学检测业界主流路线:PRB-FPN-CSP、PPYOLOEs、YOLOv5s(8.0)、DAMOYOLOs、RTMDETs、RT-DETR、Co-DETR、YOLOv6s(3.0)、YOLOv8s、YOLOv10、YOLOv6-L6。预训练对照另设 5 种通用掩码图像建模或自监督学习方法:SimMIM、MAE、BEiT、iBOT,以及 ImageNet 官方权重和"不预训练"。所有对照统一在 DsPCBSD+ 上、同一 YOLOv8 设置下训练。
四、实验结果与对比
整体性能:本文方法在 DsPCBSD+ 验证集拿到 mAP0.5 85.5% / mAP0.5:0.95 52.3%,对 11 个对照全部领先:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
相对 YOLOv8s 基线,mAP0.5 提升 1.4 个百分点,mAP0.5:0.95 提升 1.6 个百分点,并在更严格的 mAP0.5:0.95 上同时压过 YOLOv6-L6、YOLOv10、Co-DETR、RT-DETR。后两者作为 Transformer 路线的强基线,被卷积神经网络 + 结构引导混合掩码建模这条 YOLO 路线反超。
图片来源于原论文
逐类指标里有几个细节值得拎出来:在多余铜、导线划伤、导线异物三类结构高度依赖的缺陷上,AP0.5:0.95 分别从 50.6 提升到 53.2、从 42.6 提升到 45.1、从 39.7 提升到 43.4,提升幅度都超过 2.5 个百分点;细长缺陷(导线划伤、导线异物)受空间连续性正则收益最显著。开路是少数 AP0.5 已经饱和的类别,提升微弱(89.1→89.2),而孔破原本就达到 98.4,本方法上略有 0.1 个百分点回退,属预期内的高位震荡。整体上精确率略降 0.3 个百分点、召回率上涨 1.5 个百分点,这意味着新模型在保持准确率的同时变得"更敢检",本来漏掉的缺陷被找回来。
预训练对照(不加空间连续性正则、纯比自监督学习路线,见论文表 4):SG-MIM 在 mAP0.5 / mAP0.5:0.95 上拿到 85.2% / 52.0%,对 SimMIM(84.7 / 51.7)、MAE(84.4 / 50.9)、BEiT(84.8 / 51.7)、iBOT(84.3 / 51.4)、ImageNet 官方权重(84.2 / 50.8)和不预训练(84.1 / 50.7)全部领先,并且是少数同时在召回率上提升(80.6%)的方法。这条对照很关键,它说明增益不是来自"反正预训练就有用",而是 SG-MIM 这一组针对 PCB 结构性的设计真的更对症。
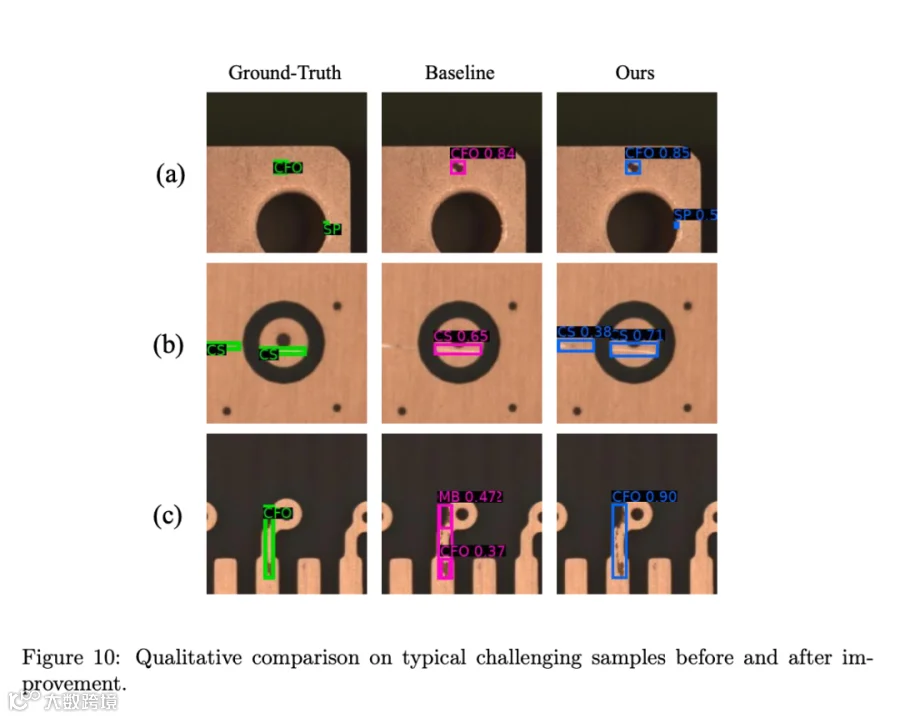
定性结果(图 9–11)方面,论文用三组典型样本展示:
-
场景 (a) 小且弱的毛刺缺陷:基线漏检,全模型补回来; -
场景 (b) 局部连续的缺陷:基线只覆盖一部分,全模型给出完整范围预测; -
场景 (c) 细长缺陷被基线切成两段:在空间连续性正则下被合并为单一紧凑框。
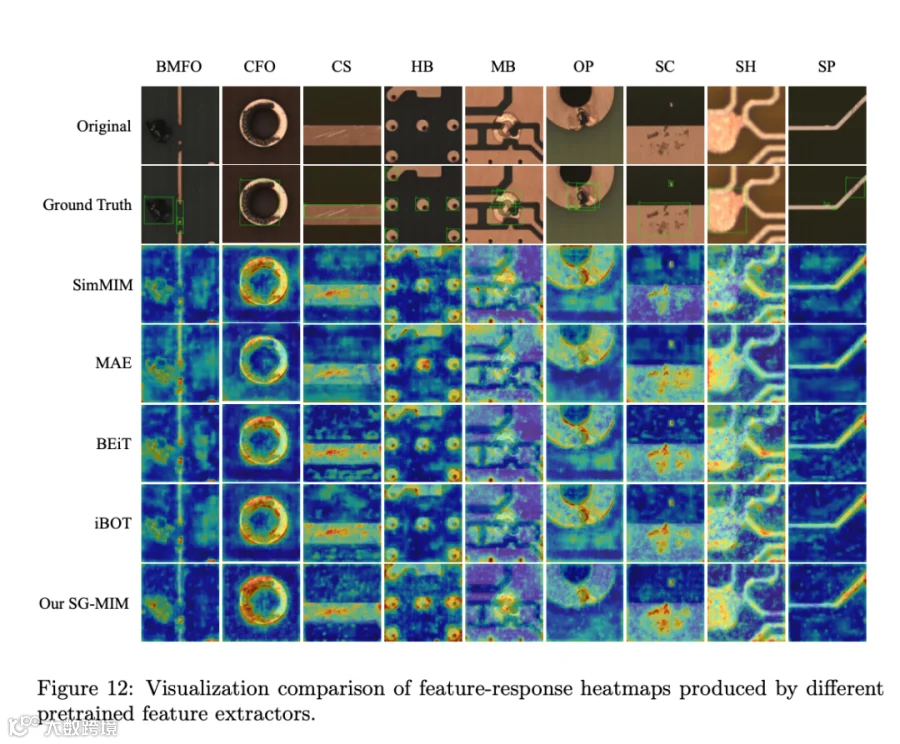
热图对比(图 12)显示 SG-MIM 在 9 类缺陷上的特征响应都比 SimMIM、MAE、BEiT、iBOT 更聚焦在主缺陷结构上,背景激活被显著抑制,与表 4 的数值结论吻合。
图片来源于原论文
五、总结与思考
从产业落地的视角看,这篇工作给 PCB 自动光学检测现场抛出的几个工程级判断都比较扎实:
第一,YOLOv8 这条实时单阶段路线在 PCB 缺陷检测上仍有空间,关键不在于换成 Transformer,而在于把"未标注 PCB 图像"和"输出层空间一致性"两个被忽视的杠杆补上;
第二,卷积神经网络主干的掩码图像建模不能照抄 ViT 的稠密重建,稀疏卷积是让掩码图像建模适配 YOLO 主干的关键工程;
第三,"细长缺陷碎片化"这种工业一线非常常见但学术界长期忽视的问题,可以用一项训练时正则去硬性约束,而不需要改架构、不影响推理速度。
图片来源于原论文
还有几条需要客观提醒的边界。
第一,所有数值仅来自 DsPCBSD+ 一个数据集。该数据集类别分布(毛刺多、短路少)与几何特征(导线异物 / 导线划伤偏长条)较为典型,但能否覆盖更高密度互连板、球栅阵列缺陷等仍需更多评测。
第二,阶段 A 预训练 400 轮,加上阶段 B 微调 100 轮,总成本不算低。对小厂或资源紧张的工业用户而言,迁移到自家数据集还需要一次类似规模的预训练投入。
第三,论文没有给出实测每秒帧数与实际产线节拍的对比;从设计上看推理与原生 YOLOv8s 一致,但部署侧的真实瓶颈,例如板载摄像头分辨率、工位节拍,仍需在客户现场确认。
下一步值得追问的是:把 SG-MIM 与其他工业自监督数据(半导体晶圆图、注塑表面、纺织瑕疵)做跨域预训练,能否形成一个"工业结构性缺陷"的通用基础模型?把空间连续性损失延伸到分割任务,能否把"细长缺陷的形态保持"问题一同解决?这些都是这套工作给出的可继续延伸的产业方向。
Coovally 团队持续关注工业缺陷检测领域的前沿进展,并在相关视觉算法方面有持续研发投入。如果您有技术交流或合作意向,欢迎联系我们和评论区留言讨论~
© THE END
转载请联系本公众号获得授权

 分享、点赞与在看,至少帮我拥有一个~
分享、点赞与在看,至少帮我拥有一个~