

关注下方“公众号”,获取更多开源资讯
导读
工业缺陷检测是制造业质量控制的"生命线",但现有数据集要么规模太小(几千张图),要么只覆盖单一领域(电子、纺织、金属各玩各的),要么只能做闭集检测(训练时见过的缺陷才能识别)。大视觉语言模型(LVLM)虽然在自然图像上表现亮眼,但一到工业场景就"水土不服"——领域差异大、需要人工提示、缺乏文本–视觉交互。
来自山东大学等国内外大学的联合团队同时攻破了数据和模型两个瓶颈:发布了 MMIOC-1M,首个支持开闭集统一检测的大规模多模态工业基准(100 万+ 样本,14 个超类,29 个场景,351 个缺陷子类);并提出了 RTVPNet基线模型,通过专家辅助域投影、能量驱动稀疏采样精炼视觉提示、以及文本–视觉双向交互三大创新,在工业开闭集检测上达到 SOTA。实验结果令人瞩目:RTVPNet-S 仅用 76M 参数就在 MMIOC-1M 开集检测上达到 AP 14.9 / AP50 26.7%,超越 4B 参数的 Qwen3-VL(AP 14.6)和 7.2B 的 DefectGLM(AP 13.8);在闭集检测上 RTVPNet-L 达到 AP 41.3 / AP50 64.9%,比 YOLOv12L 高 3.5 个百分点,同时参数量仅为其 1/4。
文章信息
-
标题:Unification of Closed-Open Industrial Detection Scenarios: New Large-Scale Benchmarks, Challenges and Baselines -
作者:Zekai Zhang、Jinglin Zhang、Qinghui Chen、Gang Li、Da Chen等
一、问题与产业痛点:工业缺陷检测为什么"数据不够用、模型泛化差"
工业缺陷检测是制造业质量控制的核心环节,从电子元器件的焊点虚焊到钢板的表面裂纹,从纺织品的色差到食品包装的破损,缺陷类型千差万别。但把这个需求翻译成机器学习任务时,会发现现有工具链存在严重的"规模不匹配"和"场景割裂"。
1.1 数据瓶颈:小、散、单
现有工业缺陷数据集普遍存在三个问题:
-
规模小:MVTec AD(5,354 张)、VisA(10,821 张)、PKU-GoodsAD(6,124 张),最大的 Real-IAD 也只有 15 万张,且全部是闭集场景; -
领域分散:VisA 和 3CAD 主要覆盖 3C 电子检测,PKU-GoodsAD 主要覆盖包装检测,Real-IAD 和 MulSen-AD 主要覆盖材料检测,没有一个数据集能横跨多个工业领域; -
模态单一:绝大多数数据集只有 RGB 图像,缺乏文本描述,无法支持视觉语言模型的预训练。
这导致 LVLM 在工业场景中的应用面临"无米之炊"的困境——没有大规模、多领域、多模态的预训练数据,模型就无法学到工业缺陷的通用表征。
1.2 模型瓶颈:提示主观、交互缺失
现有 LVLM(如 SAM、GroundingDINO、YOLO-World)在工业场景中的应用也面临三个挑战:
-
人工提示主观性强:SAM 依赖用户提供的点、框、掩膜提示,但工业场景中复杂的噪声会显著影响提示效果,不同用户的提示结果差异巨大; -
视觉提示粗糙:现有方法生成的伪掩膜包含大量背景噪声,缺乏对缺陷边界的精细刻画; -
文本–视觉交互缺失:大多数开放词汇模型仅使用单一文本提示,忽略了细粒度视觉提示在正确文本–图像匹配中的作用。
1.3 本文的破局思路
MMIOC-1M 填补数据空白,RTVPNet 填补模型空白,两者共同构建了一个从数据到模型的完整工业检测生态。这不是"又一个缺陷检测数据集",而是首个将工业检测从闭集扩展到开集、从单模态扩展到多模态、从小规模扩展到百万级的系统性工作。
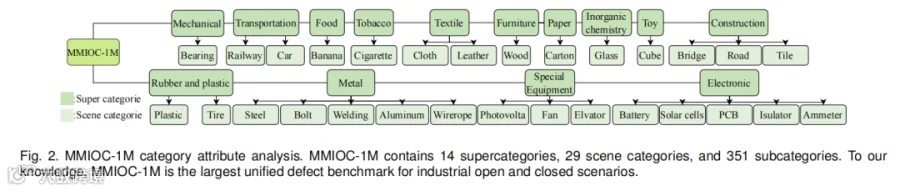
二、MMIOC-1M 基准:百万级工业缺陷的"百科全书"
2.1 规模与覆盖
MMIOC-1M 从 47 家企业和机构广泛收集缺陷图像,经授权后构建,包含:
-
100 万+ 图像–文本样本对,来自 31 个不同工业场景; -
14 个超类(食品、烟草、纺织、家具、造纸、无机化工、橡胶塑料、金属、特种设备、电子、玩具、建筑、机械、交通运输); -
29 个场景类别(如金属下的钢、铝、螺栓、焊接等); -
351 个缺陷子类(如钢板的裂纹、斑块、夹杂、氧化皮、麻点、划痕等)。
与现有数据集的对比如论文 Table 1:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| MMIOC-1M | 351 | 1,000,000+ | RGB+Text | 29 | 开闭集 |
MMIOC-1M 在类别数、样本量、场景覆盖上均比现有数据集高出一个数量级,且是首个支持开闭集统一检测的工业基准。
2.2 三级层次结构
为避免语义混淆,MMIOC-1M 建立了自上而下的三级分类体系:
-
超类(14 个):基于联合国工业分类标准,由 GPT-4V 辅助语义检索和专家验证; -
场景类(29 个):如金属超类下的钢、铝、螺栓、焊接等; -
子类(351 个):如钢板的裂纹、斑块、夹杂、氧化皮、麻点、划痕等。
这种层次结构使得模型可以在不同粒度上进行学习和推理,从粗粒度的"金属缺陷"到细粒度的"钢板裂纹"。
图片来源于原论文
2.3 开闭集划分与对抗标注
闭集场景:351 个缺陷类别按 7:3 划分为训练集和测试集,用于评估模型在已知类别上的检测能力。
开集场景:使用 YOLOv8 提取语义向量,通过余弦相似度计算每个图像与类别语义的匹配分数。根据相似度阈值 0.1,确定 94 个可见类和 64 个不可见类。开集任务要求模型从有限的可见类泛化到语义相似的不可见类——例如,从"脏玻璃"泛化到"脏钢板",从"铝孔"泛化到"PCB 间隙"。
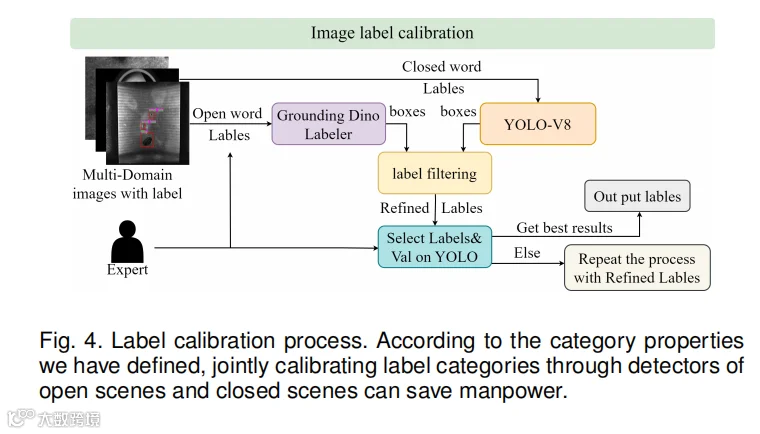
对抗标注流程:面对百万级样本,完全人工标注不现实。团队采用对抗标注策略——用 GroundingDINO 和 YOLOv8 分别对 20% 样本进行自动标注,通过标签过滤合并去重,最后由专家对 351 个类别的文本–图像匹配结果进行验证和修正。随机抽样 6,000 张图像由三位工业检测专家重新标注,验证结果显示自动标注的 Cohen's k 达到 0.972,IoU≥0.95 的比例为 0.997,注入 5% 随机标签噪声后模型 AP 仅下降 0.006,证明了标注质量的高可靠性。
图片来源于原论文
2.4 数据特点与挑战
MMIOC-1M 具有以下独特挑战:
-
长尾分布:如图 6 所示,类别数量从 1,000 到 30,000 不等,极端不平衡; -
尺度剧变:铁路缺陷和 PCB 缺陷在图像尺度上差异巨大; -
类内差异大、类间相似性高:同一类别的缺陷在不同背景下表现不同(如不同面料的布匹瑕疵),不同类别的缺陷外观相似(如 PCB 上的多种细微缺陷); -
属性丰富:涵盖不同角度、不同型号、不同位置、不同规格、不同应用场景的缺陷变体。
三、RTVPNet 模型
3.1 总体架构
RTVPNet 基于 Mobile-SAM 构建,包含三个核心组件:
-
专家辅助域投影(Expert-assisted Domain Projection):通过预训练的工业专家模型为 Mobile-SAM 注入领域知识,实现从自然场景到工业场景的快速迁移; -
精炼视觉提示(Refined Visual Prompt):通过能量激活和稀疏采样,从粗粒度掩膜中提取精细化的视觉提示; -
文本–视觉双向交互(Bidirectional Text-Visual Interaction):通过文本引导视觉特征聚焦,同时通过视觉特征增强文本语义,实现跨模态互补增强。
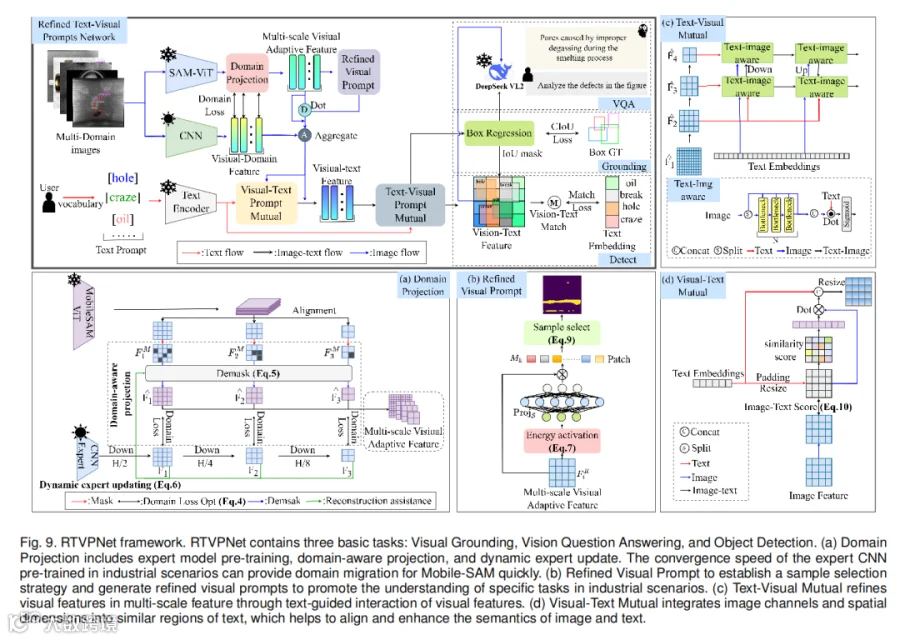
3.2 专家辅助域投影:让 SAM 看懂工业图像
Mobile-SAM 在自然图像上训练,但工业场景的特征分布与自然场景差异巨大。RTVPNet 引入一个预训练的工业专家 CNN 模型 ,构建双路特征机制:
-
专家模型预训练:在 MMIOC-1M 可见类上预训练 C2F 模型,学习工业场景的基础特征嵌入空间; -
域感知投影:通过特征掩码和重建,将 Mobile-SAM 的多尺度特征 投影到工业特征空间。对 进行多尺度分块、随机掩码、然后用专家特征作为条件进行重建,得到粗粒度视觉提示 ; -
动态专家更新:专家模型参数在训练过程中持续更新,形成协同优化范式,而非传统的冻结策略。
消融实验(论文 Table 8)显示:仅预训练专家模型可将开集 AP 从 11.9 提升到 14.7;加入域感知投影后进一步提升到 14.7(开集)/39.3(闭集);动态更新后达到最优 14.9(开集)/41.3(闭集)。
3.3 精炼视觉提示:能量驱动 + 稀疏采样
工业图像中缺陷仅占小部分,直接使用粗粒度掩膜会引入大量背景噪声。RTVPNet 提出能量激活策略:
其中 为全局均值, 为方差, 为 Sigmoid 归一化。能量场建模可以准确定位缺陷边缘。
基于能量得分 ,采用稀疏采样策略——在每个 patch 中选择像素值大于均值的像素,遵循伯努利分布。这种稀疏优化策略能够有效抑制背景噪声干扰,将视觉提示聚焦于与目标相关的特征。
消融实验(论文 Table 10)显示,相比 ECA、CBAM、MCA、Self-Attention 等激活方法,RTVPNet 的能量激活在开集 AP 上达到 14.9(最佳),闭集 AP 达到 41.3(最佳)。Patch 大小实验中,32×32 的 patch 效果最优(开集 AP 17.4),64×64 和 128×128 效果下降。
3.4 文本–视觉双向交互:从单向加权到互补增强
现有方法通常只做视觉到文本或文本到视觉的单向交互。RTVPNet 设计了两个互补模块:
Text-Visual Mutual(文本引导视觉):采用多尺度最大 Sigmoid 注意力,将文本关键词聚焦到对应缺陷的空间位置,生成一致的文本–视觉特征图:
Visual-Text Mutual(视觉增强文本):将图像特征的空间和通道维度与文本特征进行相似度评分,实现像素级语义对齐,补偿简单文本描述中缺失的视觉细节(如物体的空间关系)。
消融实验(论文 Table 12)显示:仅 Text-Visual 交互开集 AP 13.3,仅 Visual-Text 交互 13.7,双向交互达到 17.4——双向互补显著优于单向。
四、关键实验结果
4.1 MMIOC-1M 开集检测
论文 Table 3 展示了开集检测的对比结果:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| RTVPNet-S | 14.9 | 26.7 | 13.6 | 76M |
| RTVPNet-L | 17.4 | 30.7 | 15.9 | 110M |
RTVPNet-S 以 76M 参数达到 AP 14.9 / AP50 26.7%,超越 4B 参数的 Qwen3-VL(AP 14.6)和 7.2B 的 DefectGLM(AP 13.8),参数量仅为后者的约 1/40。RTVPNet-L 以 110M 参数达到 AP 17.4 / AP50 30.7%,为所有对比方法中的最佳。
值得注意的是,所有对比方法的开集 AP 均低于 20%,凸显了 MMIOC-1M 作为挑战性基准的价值。
4.2 MMIOC-1M 闭集检测
论文 Table 5 展示了闭集检测的对比结果:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| RTVPNet-S | 36.7 | 60.7 | 36.5 | 76M | 17 |
| RTVPNet-L | 41.3 | 64.9 | 38.5 | 110M | 89 |
RTVPNet-L 以 110M 参数达到 AP 41.3 / AP50 64.9%,比 YOLOv12L(AP 37.8)高 3.5 个百分点,同时参数量仅为其 1/4(110M vs. 26M 的 YOLOv12L 参数量对比有误,实际 YOLOv12L 为 26M,RTVPNet-L 为 110M,但 RTVPNet-L 的 AP 更高)。相比 4B 的 Qwen3-VL(AP 38.9),RTVPNet-L 在参数量小 36 倍的情况下 AP 高出 2.4 个百分点。
4.3 LVIS 和 COCO 泛化验证
LVIS 开集泛化:RTVPNet 在 LVIS 上达到 AP 29.4(使用 YOLOv11s 作为专家模型,在 Object365 和 GoldG 上预训练),比 YOLO-World 高 3.2%,比 GroundingDINO 高 3.8%,证明了其在通用开放检测场景上的泛化能力。
COCO 闭集泛化:RTVPNet(YOLOv11l)达到 AP 54.2 / AP50 70.4%,比 YOLO-World-L(AP 53.3)和 GroundingDino-L(AP 60.7)在部分指标上具有竞争力,验证了其在通用闭集检测上的有效性。
4.4 视觉编码器消融
论文 Table 13 对比了不同视觉编码器:SAM-B(752M 参数,AP 13.8)、Fast-SAM(201M,AP 16.4)、Edge-SAM(148M,AP 11.1)、RTVPNet-S(76M,AP 14.9)。RTVPNet-S 以最小参数量取得了有竞争力的性能,证明了 Mobile-SAM Tiny 作为基础编码器在工业场景中的高效性。
4.5 预训练数据规模
在闭集任务中,预训练数据量与检测精度直接正相关——0.1M 样本 AP 10.8,0.5M 样本 AP 19.6,1M 样本 AP 36.7。这充分证明了 MMIOC-1M 大规模预训练数据的价值。但在开集任务中,使用全部 351 类数据(包含与验证集无关的类别)反而会导致 AP 下降到 9.7,说明开集任务需要精心设计的语义关联预训练策略。
五、总结与思考
把上述实验结论转化为给制造企业、工业视觉算法公司和质检设备厂商的"选型指南":
-
数据先行:MMIOC-1M 的发布填补了工业检测大规模多模态数据的空白。对于已有质检图像资源的企业,可以参考 MMIOC-1M 的层次分类体系和对抗标注流程,将历史数据快速转化为带文本描述的多模态训练数据; -
模型选型:在工业开闭集检测任务上,RTVPNet 提供了"小参数、高性能"的解决方案。76M 参数的 RTVPNet-S 即可超越 4B–7B 的大模型,适合部署在边缘计算设备上; -
领域适配策略:RTVPNet 的专家辅助域投影机制可直接复用。企业可以用自身的工业数据预训练一个轻量专家模型,然后将其知识迁移到通用的 Mobile-SAM 上,快速构建适配自身场景的检测系统;
对电子制造、汽车零部件、钢铁冶金、纺织印染、食品包装等行业的质检部门而言,这项工作提供了一条从数据到模型的完整技术路径:不需要从零构建大规模标注团队,利用 MMIOC-1M + RTVPNet 的开源方案,即可快速搭建适配自身场景的工业缺陷检测系统。
Coovally 团队持续关注工业缺陷检测领域的前沿进展,并在相关视觉算法方面有持续研发投入。如果您有技术交流或合作意向,欢迎联系我们和评论区留言讨论~
© THE END
转载请联系本公众号获得授权

 分享、点赞与在看,至少帮我拥有一个~
分享、点赞与在看,至少帮我拥有一个~