

点击蓝字 关注我们

公众号更改了推送规则,记得读完点“在看”~下次新文章就能及时出现在您的订阅列表中
本文将结合理论和实践,讲清训练一个分割模型的逻辑,训练伪代码以monai框架为基础
申明:本文搭配训练代码食用更佳
-
1. 什么是图像分割(Image Segmentation)? -
2. 什么是模型 Model? -
1. 特征提取(Feature Extraction) -
2. 特征恢复(Feature Reconstruction) -
有哪些经典模型 -
3. 什么是模型训练 (Model Training)? -
4、 一个标准的训练代码构成:以 MONAI 框架为例 -
1. 数据加载 -
2. 创建transforms -
3. 创建数据集与加载器 (Dataset & DataLoader) -
4.模型构建(Model Architecture) -
5. 定义损失函数与优化器 (Loss & Optimizer) -
6. 训练循环 (Training Loop)
1. 什么是图像分割(Image Segmentation)?
如果说分类是给整张图打标签(例如:这是一张 CT 图),那么分割就是给每一个像素(体素)打标签。
-
本质: 将图像中属于特定物体(如肝肿瘤)的像素(体素)提取出来。 -
输出: 模型会输出一张和原图大小一样的“分类图”。对于每一个像素,模型都要判断:它是背景(Label 0)还是肿瘤(Label 1)?
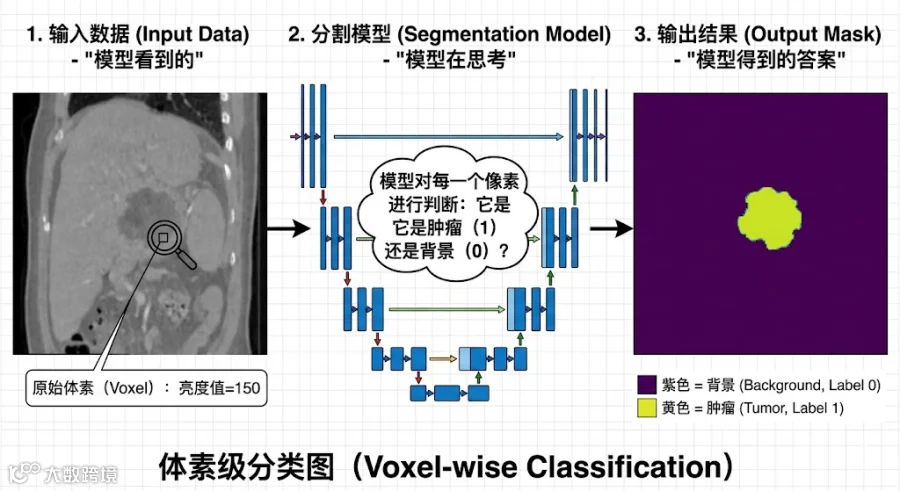
2. 什么是模型 Model?
在深度学习中,模型(Model)本质上是一个带有大量参数的函数(function),对于分割任务,这个函数的目标是实现从输入图像到逐体素分类(voxel-wise classification)的映射
以 UNet 为代表的分割模型,其结构本质可以概括为两个阶段:
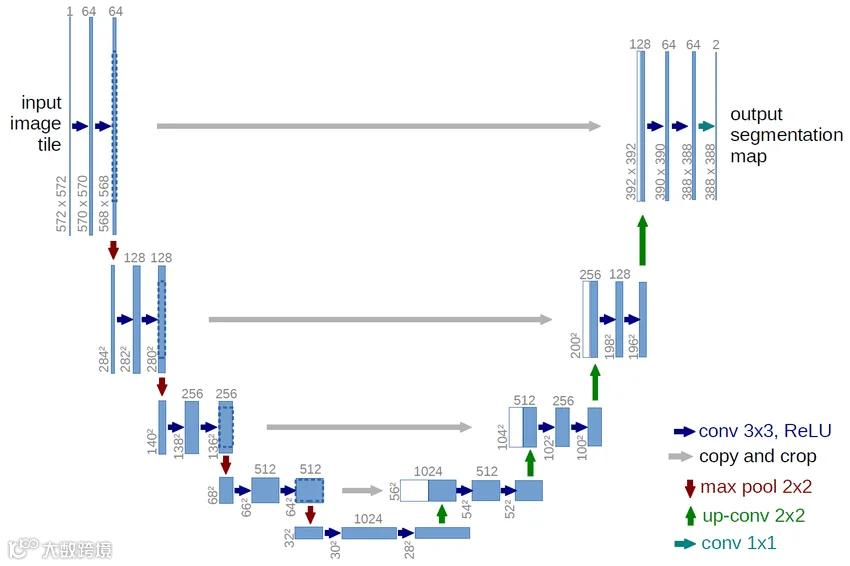
1. 特征提取(Feature Extraction)
通过下采样(downsampling)逐步提取特征(图像越来越小):
-
卷积:提取局部模式(边缘、纹理等) -
下采样:扩大感受野,整合更大范围的上下文信息
👉 本质:在更高语义层面理解图像内容
2. 特征恢复(Feature Reconstruction)
通过上采样(upsampling)将特征恢复到原始分辨率(图像越来越大),并输出分割结果:
-
上采样:恢复空间尺寸 -
融合浅层特征(skip connection):补充细节信息
👉 本质:把“理解到的内容”还原成精细的空间分布(分割图)
一句话总结:分割模型是一个带参数的函数,通过“特征提取(包含下采样)+ 特征恢复(上采样)”实现逐体素分类。
有哪些经典模型
医学图像分割常用的模型大多是基于U-Net及其变体,MONAI里已经集成了不少经典实现,例如:
-
U-Net:最经典的编码器-解码器结构,医学分割的基线模型 -
UNet++(Nested U-Net):在U-Net基础上增加跳跃连接的密集性,提高精度 -
Attention U-Net:引入注意力机制,更关注关键区域 -
V-Net:专为3D医学图像设计,常用于体数据分割 -
DynUNet(Dynamic U-Net):MONAI中常用的自适应U-Net,支持自动配置网络结构 -
SegResNet:结合ResNet思想的分割网络,性能稳定 -
UNETR:基于Transformer的U-Net结构(ViT + CNN解码器) -
SwinUNETR:使用Swin Transformer的改进版本,适合大规模3D数据 -
BasicUNet / FlexibleUNet:MONAI中更灵活或轻量的U-Net实现
总结:当前医学图像分割模型主要分为CNN(如U-Net系列)和Transformer(如UNETR、SwinUNETR)两大类,MONAI基本都覆盖了主流方案。
3. 什么是模型训练 (Model Training)?
训练本质上是一个数学优化过程。
-
模型: 像一个拥有数百万个可拨动“旋钮”(即参数 )的黑盒。 -
目标: 通过不断调整这些“旋钮”,使得黑盒对图像的预测结果(Prediction)与医生的标准答案(Ground Truth)越来越接近。
核心类比:寻找最优的权重 和偏置
为了理解模型训练,我们可以把复杂的神经网络(如你代码里的 UNet)简化为初中数学里最基础的线性函数:
在深度学习中:
-
(输入): 对应你代码里的 CT 图像像素值(体素)。 -
(输出):对应模型预测的结果(该位置属于肿瘤的概率)。 -
(权重,Weights) 与 (偏置,Bias):*这就是模型内部数以百万计的可学习参数。
下图展示一个卷积网络的中的部分参数示意:
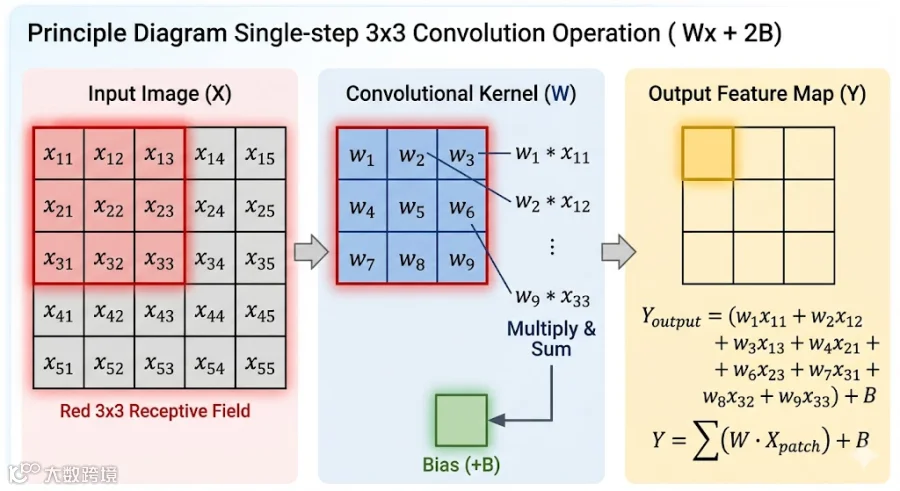
的卷积核 (蓝色)在 的输入图像 上滑动,每次只处理红色方框内的局部像素, 对应位置进行逐元素相乘并求和,最后加上偏置项 (绿色),
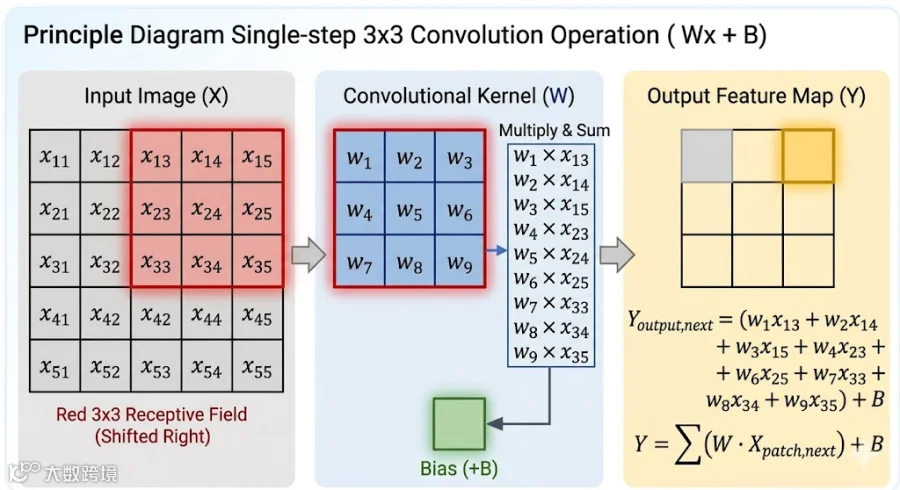
不断滑动得到输出特征图。最后图像从 浓缩为 ,实现了空间特征的提取与降维
训练的最终目的:当你刚启动代码时,模型内部的 和 是随机初始化的(比如 )。此时你输入一张肿瘤图像 ,模型算出来的 极大概率是错误的。
训练的目的就是通过大量的样本数据,去寻找那一组最准确的 和 参数值,使得模型计算出的预测图 能够完美地契合医生标注的标准答案(Label)。
训练的三大关键动作:
-
量化差距 (Loss): 通过损失函数(如 DiceLoss)对比预测值 与真值 的差异。如果参数 设置得不合理,Loss 就会很高。 -
推导方向 (Gradient): 利用微调中的导数概念,计算出梯度。它告诉模型:“如果把 调大一点,Loss 是会增加还是减少?” -
执行更新 (Update): 根据梯度的指引,微调 和 的数值。
对应的代码逻辑:
在分割代码中,这个数学优化过程被分解为以下指令:
-
参数容器: model = UNet(...)初始化了数百万个随机的 ** 和 **。 -
前向传播 (Forward): outputs = model(inputs)。数据 经过无数次 的矩阵运算,得到预测概率outputs。 -
计算损失 (Loss): loss = loss_function(outputs, labels)。通过数学公式评估当前这组 的表现有多差。 -
反向传播 (Backward): loss.backward()。程序自动计算出 Loss 对每一个 和 的导数(即梯度)。 -
参数更新 (Step): optimizer.step()。优化器正式修改 和 的值,完成一次进化。
**总结:经过数个 Epoch 的循环,模型内部的 和 就会进化到一种极其精准的状态,从而实现自动化的肝肿瘤分割。
4、 一个标准的训练代码构成:以 MONAI 框架为例
1. 数据加载
在训练模型的第一步,数据加载的核心任务是“配对”与“格式化”。它将分散在磁盘上的原始医学影像文件转化成模型可以批量读取的结构化列表。
数据加载的第一步并不是直接读图,而是获取所有图像文件(Images)和对应的标签文件(Labels)的路径,并将它们一一对应。
-
做什么: 扫描文件夹,确保 case_001的图像对应case_001的标签。 -
加载成什么格式: 一个包含多个字典的列表(List of Dictionaries)。
伪代码示例:
# 1. 获取所有文件的路径列表
images = ["path/to/case001_0000.nii.gz", "path/to/case002_0000.nii.gz", ...]
labels = ["path/to/case001.nii.gz", "path/to/case002.nii.gz", ...]
# 2. 将图像和 Label 进行“表面配对”
data_dicts = [
{"image": image_path, "label": label_path}
for image_path, label_path in zip(images, labels)
]
# 结果展示:
# data_dicts = [
# {"image": "case001_img.nii.gz", "label": "case001_gt.nii.gz"},
# {"image": "case002_img.nii.gz", "label": "case002_gt.nii.gz"},
# ...
# ]
2. 创建transforms
在配对好路径后,我们需要定义一系列数据变换(Transforms)。这是医疗影像训练中最关键的一步,因为模型无法直接读取磁盘上的 .nii.gz 文件,且医疗影像的尺寸、亮度范围千差万别,必须经过统一的“深加工”。
我们将变换分为 Train(训练集) 和 Val(验证集) 两部分:
2.1 训练集变换 (Train Transforms)
做什么: 除了基本的加载和标准化,还会加入“随机性”来扩充数据。
-
加载与格式化: 将磁盘路径变成内存中的张量(Tensor),并确保图像和标签成对。 -
物理属性统一: 通过重采样(Spacing)确保所有病例的体素大小一致,通过归一化(Normalize)将 CT 值缩放到固定范围。 -
数据增强 (Data Augmentation): 随机切块、旋转或缩放。 -
有什么用: 增加数据的多样性,防止模型“死记硬背”训练集,提高它在未知病例上的泛化能力。
2.2 验证集变换 (Val Transforms)
做什么: 仅执行必要的加载和标准化,严禁使用随机增强。
-
确定性操作: 只包含加载、重采样和归一化。 -
有什么用: 验证集是为了客观评估模型现在的水平。如果给验证集加了随机旋转或切块,我们就无法准确对比每一轮(Epoch)模型是否真的在进步。
伪代码实现逻辑:
# 训练集变换:重在“强健性”
train_transforms = [
# 1. 加载:把字典里的路径变成真正的 3D 矩阵
LoadImaged(keys=["image", "label"]),
# 2. 物理校正:统一所有图像的分辨率(如 1.5mm x 1.5mm x 2.0mm)
Spacingd(keys=["image", "label"], pixdim=(1.5, 1.5, 2.0)),
# 3. 数值标准化:把 CT 值从 [-175, 250] 缩放到 [0, 1]
ScaleIntensityRanged(keys=["image"], a_min=-175, a_max=250, b_min=0.0, b_max=1.0),
# 4. 随机切块:由于 3D 全图太大,随机切出 96x96x96 的小方块喂给模型
RandCropByPosNegLabeld(keys=["image", "label"], roi_size=(96, 96, 96), pos=1, neg=1),
]
# 验证集变换:重在“真实性”
val_transforms = [
LoadImaged(keys=["image", "label"]),
Spacingd(keys=["image", "label"], pixdim=(1.5, 1.5, 2.0)),
ScaleIntensityRanged(keys=["image"], a_min=-175, a_max=250, b_min=0.0, b_max=1.0),
# 注意:验证集不需要 RandCrop,通常在测试时使用滑动窗口推理
]
3. 创建数据集与加载器 (Dataset & DataLoader)
有了变换规则,我们就要正式把 data_dicts 塞进“工厂流水线”了。
-
Dataset (数据集):负责执行上面定义的 transforms。MONAI 常用CacheDataset,它会把处理好的数据缓存到内存里,避免每次训练都重复读硬盘,速度提升 10 倍以上。 -
DataLoader (加载器):*负责把 Dataset里的单个数据打包成 Batch(批次)。
伪代码示例:
# 1. 创建缓存数据集(把处理好的数据存入内存)
train_ds = CacheDataset(data=train_dicts, transform=train_transforms)
val_ds = CacheDataset(data=val_dicts, transform=val_transforms)
# 2. 创建加载器(每次给模型喂 2 个 Batch)
train_loader = DataLoader(train_ds, batch_size=2, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=1)
总结: 这一步完成后,原本磁盘上的文件就变成了内存中成对的、标准化的、随时待命的 train_images** 和 train_labels** 张量。下一步,我们将定义模型(UNet)的结构。
4.模型构建(Model Architecture)
在数据准备就绪后,我们需要定义模型(Model)。在医疗影像分割中,最常用的模型是 UNet 架构。
-
做什么:实例化一个模型,定义它的层数、通道数和输入输出规格。 -
加载成什么格式: 一个包含数百万个随机初始化的 权重 和 偏置 的计算图。这些参数分布在编码器(提取特征)和解码器(还原尺寸)中。
伪代码示例:
# 定义 3D UNet 模型
model = UNet(
spatial_dims=3, # 处理 3D 数据
in_channels=1, # 输入是 1 个通道(CT 灰度图)
out_channels=2, # 输出是 2 个通道(背景 vs 肿瘤)
channels=(16, 32, 64, 128, 256), # U 型结构的每一层宽度
strides=(2, 2, 2, 2), # 下采样的倍数
)
# 将模型移动到显卡 (GPU)
model.to(device)
5. 定义损失函数与优化器 (Loss & Optimizer)
模型建好后,定义训练策略
-
损失函数 (Loss Function)
用于量化预测结果与真实标签之间的差距。医疗分割常用 DiceLoss。由于肿瘤在整张 CT 中占比极小(类别不平衡),DiceLoss 专门计算区域的重叠度,能有效防止模型因为“背景太多”而忽略微小的肿瘤。
-
优化器 (Optimizer):
根据损失函数算出的“错因”(梯度),更新模型内部的 和 。常用 Adam 优化器。它像一个聪明的驾驶员,能自动调节“学习率”,在训练初期大步流星寻找方向,在后期小步微调以求精准。
伪代码示例:
# 1. 损失函数:计算预测 Mask 与 真实 Mask 的重叠程度
loss_function = DiceLoss(smooth=1e-5, sigmoid=True)
# 2. 优化器:负责更新模型参数,学习率为 0.0001
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
6. 训练循环 (Training Loop)
这是最核心的进化阶段,开启一个大循环(Epoch),每一轮都遍历一遍所有训练数据。
-
核心步骤: -
前向传播:模型给出预测结果 outputs。 -
计算损失:算出 outputs离labels差多远。 -
反向传播: 算出每个参数 应该往哪个方向调。 -
参数更新:*真正拨动“旋钮”,修正 和 。
伪代码示例:
for epoch in range(max_epochs):
model.train() # 切换到训练模式
for batch_data in train_loader:
# 获取当前批次的数据
inputs, labels = batch_data["image"], batch_data["label"]
# 核心四步走:
optimizer.zero_grad() # 1. 清空上一轮的旧梯度
outputs = model(inputs) # 2. 前向传播(预测)
loss = loss_function(outputs, labels) # 3. 计算本轮误差
loss.backward() # 4. 反向传播(找修正方向)
optimizer.step() # 5. 更新参数(完成进化)
# 每隔几轮在验证集(Val)上测试一下 Dice 分数,保存表现最好的模型
总结: 经过这一整套流程,模型内部的参数就从“随机乱码”变成了“专家知识”,最终导出的 best_model.pth 文件就是训练好的肝肿瘤识别器。
注:本文内容仅供科研学习与学术交流使用,不构成任何医疗建议。

# 好友邀请函 #

备注:由于公众号没有留言功能,很多时候都是我们在输出,并没有反馈。也不知道大家喜不喜欢文章,或者想了解哪方面的内容。
学术的交流应该是及时的, 讨论的。目前给大家建了一个交流群,大家一起快乐学习,微笑生活。科研艰难,让我们一起携手前进~~~
进群需先加上面vx, 注明来意。