

点击蓝字 关注我们

公众号更改了推送规则,记得读完点“在看”~下次新文章就能及时出现在您的订阅列表中
此教程供学员参考!
在学习这部分前,请确保已经完成了以下任务:
-
nnU-Net v2 环境已配置:请参考nnUNet安装部分 -
数据整理成 nnUNet v2 标准格式:请参考nnUNet数据准备部分 -
数据预处理:请确认已经运行 nnUNetv2_plan_and_preprocess命令,参考nnUNet预处理部分 -
模型训练:请确认已经运行 nnUNetv2_train命令,并完成模型训练,得到最终的checkpoint_latest.pth模型文件。
在完成 nnU-Net 模型训练(model training)之后,真正决定模型能否投入实际应用的关键步骤,就是推理(inference)。
所谓推理,也称为预测,是指使用已经训练好的模型对新的图像数据进行预测(prediction),并输出对应的分割结果。
在推理中,我们还可以加一个测试环节,测试(test)是指在测试集上做推理,并进一步计算评价指标,比如 Dice、IoU、HD95 等,用来验证模型性能(performance)。
总结:只要后续用训练好的模型对新数据进行分割,这个过程就叫推理。但我们还关心在新数据上的分割能力怎么样,要用指标来评价,这个过程就叫测试。测试是需要有测试集(数据和标签的)。
对新数据进行推理
之前,你已经体会过,nnU-Net的任何处理都只需要一行命令即可完成。推理也是一样的。
nnUNetv2_predict -i INPUT_FOLDER -o OUTPUT_FOLDER -d DATASET_NAME_OR_ID -c CONFIGURATION -f fold
参数解析:
-
i:待预测图像文件夹(需要经过标准化处理) -
o:输出分割结果文件夹(保存分割结果地址) -
d:数据集 ID 或数据集名 -
c:你训练时使用的配置,比如 2d、3d_fullres、3d_lowres、3d_cascade_fullres -
f:如果只训练了一折,需要填写fold是哪一折,比如我们训练的是fold 0,就填0。 如果5折都训练了,可以不写这个参数,默认将使用交叉验证的全部 5 个折叠数据作为一个集成模型进行
比如,我们的实验数据waw-tace,之前存放在nnUNet_raw\Dataset111_wawtace,为了推理,我将训练数据复制了几个到imagesTs,并且新创建了一个文件夹labelsTs用于放推理后的结果。

根据这个数据情况,我们使用下面命令
nnUNetv2_predict -i 'D:\nnunet\nnUNet_raw\Dataset111_wawtace\imagesTs' -o 'D:\nnunet\nnUNet_raw\Dataset111_wawtace\labelsTs' -d 111 -c 3d_fullres -f 0
这里,输入图像路径和输出我都给了绝对路径。
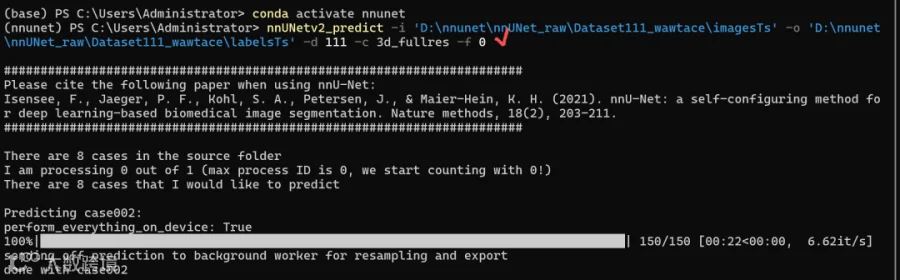
注意:运行命令前一定要先激活环境conda activate nnunet
运行之后可以打开slicer加载图像和分割结果,进行手动检查分割质量。
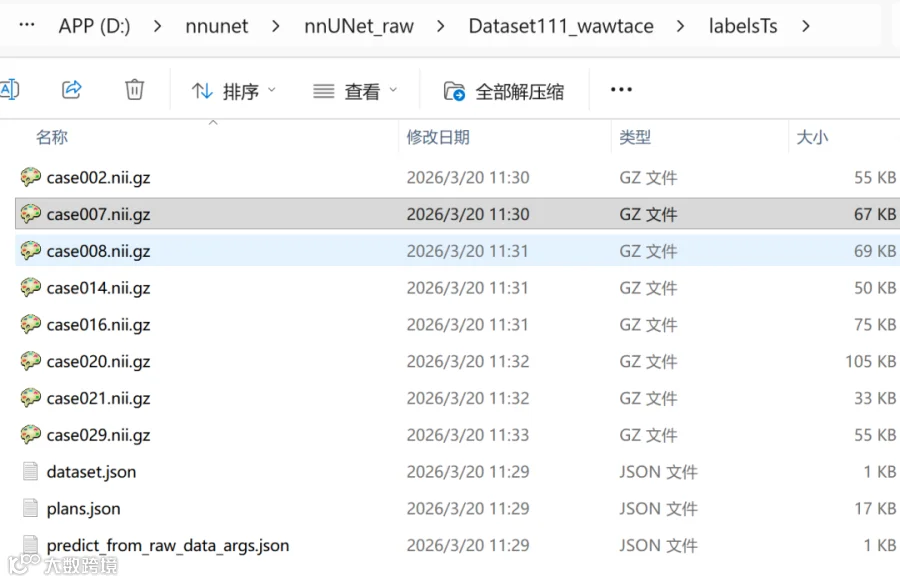
命令版本的优势是可以批量得到分割结果,如果你的目的是做单一数据分割,还要进行人工修改。可以参考在slicer 端进行nnunet推理相关的教程。我们就可以可视化的进行这一步。
当然,要想得到论文中的各种测试指标,比如Dice值等,期待后面的教程。
以上我讲的用法很简单,如果有更复杂的情况要面对,那就要看看这个命令的其他参数了
推理高级参数解析
我帮你把这段 完整翻译成中文(保持原有结构和格式):
用法: nnUNetv2_predict [-h] -i I -o O -d D [-p P] [-tr TR] -c C [-f F [F ...]] [-step_size STEP_SIZE] [--disable_tta] [--verbose]
[--save_probabilities] [--continue_prediction] [-chk CHK] [-npp NPP] [-nps NPS]
[-prev_stage_predictions PREV_STAGE_PREDICTIONS] [-num_parts NUM_PARTS] [-part_id PART_ID] [-device DEVICE]
[--disable_progress_bar]
用于使用 nnU-Net 进行推理。当你希望手动指定包含已训练 nnU-Net 模型的文件夹时使用此函数。
当 nnunet 环境变量(nnUNet_results)未设置时,这非常有用。
参数说明:
-h, --help 显示帮助信息并退出
-i I 输入文件夹。请确保文件的通道编号正确(如 _0000 等)。
文件后缀必须与训练数据集一致!
-o O 输出文件夹。如果不存在将自动创建。
预测分割结果将与输入图像同名。
-d D 要用于预测的数据集。可以指定数据集名称或 ID
-p P Plans 标识符。指定所需配置所在的 plans。默认: nnUNetPlans
-tr TR 使用的 nnU-Net 训练器类。默认: nnUNetTrainer
-c C 用于预测的 nnU-Net 配置。该配置必须存在于 -p 指定的 plans 中
-f F [F ...] 指定用于预测的模型折数(fold)。默认: (0, 1, 2, 3, 4)
-step_size STEP_SIZE 滑动窗口预测的步长。越大越快但精度降低。
默认: 0.5。不能大于 1。推荐使用默认值。
--disable_tta 禁用测试时数据增强(镜像)。更快但精度更低,不推荐。
--verbose 开启详细输出(程序会“多说话”)。
--save_probabilities 保存预测的类别“概率”。用于多配置集成时必须开启。
--continue_prediction
继续之前中断的预测(不会覆盖已有文件)
-chk CHK 使用的 checkpoint 名称。默认: checkpoint_final.pth
-npp NPP 预处理使用的进程数。并非越多越好,注意内存不足问题。默认: 3
-nps NPS 分割导出使用的进程数。并非越多越好,注意内存不足问题。
默认: 3
-prev_stage_predictions PREV_STAGE_PREDICTIONS
上一阶段预测结果所在文件夹。级联模型需要此参数。
-num_parts NUM_PARTS 将运行多少个独立的 nnUNetv2_predict 调用。默认: 1(一次完成全部预测)
-part_id PART_ID 当前是第几个任务。ID 从 0 开始,到 num_parts - 1。
例如提交 5 个任务,则 -num_parts 5,并设置 -part_id 为 0~4。
注意:需要你自己确保它们运行在不同 GPU 上!
使用 CUDA_VISIBLE_DEVICES 控制。
-device DEVICE 设置推理设备。可选 'cuda'(GPU)、'cpu'、'mps'(Apple 芯片)。
⚠️ 不要用它来指定 GPU 编号!请使用 CUDA_VISIBLE_DEVICES=X
--disable_progress_bar
禁用进度条。推荐在 HPC(非交互环境)中使用
举例说明
-
使用保存的最佳模型分割
nnUNetv2_predict -i 'D:\nnunet\nnUNet_raw\Dataset111_wawtace\imagesTs' -o 'D:\nnunet\nnUNet_raw\Dataset111_wawtace\labelsTs' -d 111 -c 3d_fullres -f 0 -chk checkpoint_best.pth
这里,比基础命令多加了一个chk参数,如果不指定chk参数,默认使用checkpoint_final.pth训练结束后保存的最终模型进行预测,这是 nnUNet的常用方法,但你也可以试试最佳模型的效果。
-
多个 folds 集成预测
nnUNetv2_predict -i 'D:\nnunet\nnUNet_raw\Dataset111_wawtace\imagesTs' -o 'D:\nnunet\nnUNet_raw\Dataset111_wawtace\labelsTs' -d 111 -c 3d_fullres -f 0 1 2 3 4
-f控制集成的数量,想集成几个就集成几个
-
开启详细输出模式 想要终端输出更多内容,添加 --verbose参数
nnUNetv2_predict -i 'D:\nnunet\nnUNet_raw\Dataset111_wawtace\imagesTs' -o 'D:\nnunet\nnUNet_raw\Dataset111_wawtace\labelsTs' -d 111 -c 3d_fullres -f 0 --verbose
如果你有更多需求,请仔细阅读使用说明
使用 nnU-Net 时请引用以下论文:
Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J., & Maier-Hein, K. H. (2021). nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2), 203-211.
注:本文内容仅供科研学习与学术交流使用,不构成任何医疗建议。

# 好友邀请函 #

备注:由于公众号没有留言功能,很多时候都是我们在输出,并没有反馈。也不知道大家喜不喜欢文章,或者想了解哪方面的内容。
学术的交流应该是及时的, 讨论的。目前给大家建了一个交流群,大家一起快乐学习,微笑生活。科研艰难,让我们一起携手前进~~~
进群需先加上面vx, 注明来意。