
点击上方蓝字加入我们

-
Graphify 是什么 :给 AI 编程助手的“地图” -
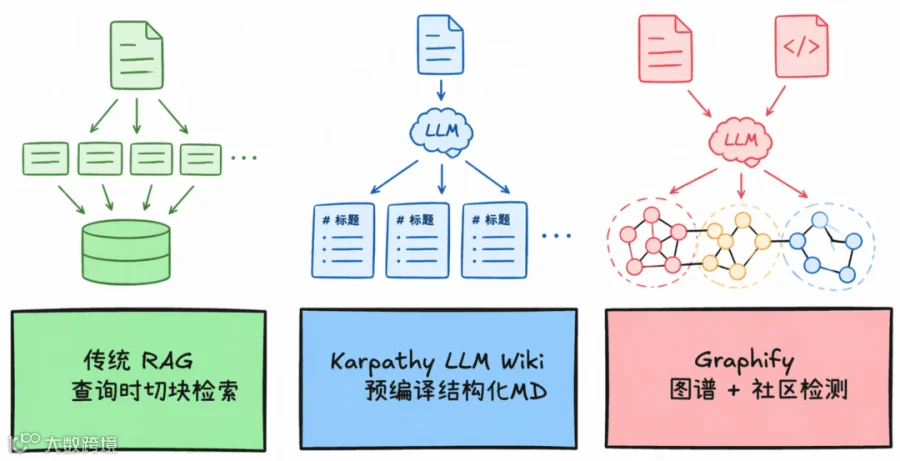
Graphify 如何作为存量软件开发的“第二大脑” -
上手 Graphify:快速构建存量软件的图谱 -
揭开面纱:Graphify 原理拆解 -
效果对比:有 Graphify vs 无 Graphify -
别神化 Graphify:并非万能解药
1
-
代码(符号、关系、docstring、注释) -
业务知识、需求、设计、接口说明、辅助理解材料等 -
各类编程、设计、测试、CI/CD规范
-
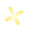
RAG 的方法是“只召回相关的文本”,然后让模型据此回答。 -
LLM Wiki 则是让 LLM 编译成结构化的 MD 文档 + 导航,直接查阅。 -
Graphify 则是创建文档与代码的深层结构:知识图谱,给 AI 使用。
2
3
pip install graphifyy && graphify install --platform xxx/graphify .
# 在终端查看产出
ls graphify-out/
# ├── GRAPH_REPORT.md # 总览报告
# ├── graph.json # 结构化数据
# ├── graph.html # 可视化 HTML
# ├── wiki/ # 社区的Wiki文档
# └── cache/ # 增量更新缓存-
AGENTS.md(或CLAUDE.md)的常驻系统指令。让 AI 在回答问题或者试图 grep 搜索时,优先看“地图”,而不是直接看代码:

-
使用 /graphify 技能,并告诉它你需要查询的内容。比如:
/graphify query "这个系统的一次完整分析流程是怎么启动的?"-
还有一种方式是启动 Graphify MCP,让 AI 调用工具查询。
/graphify update .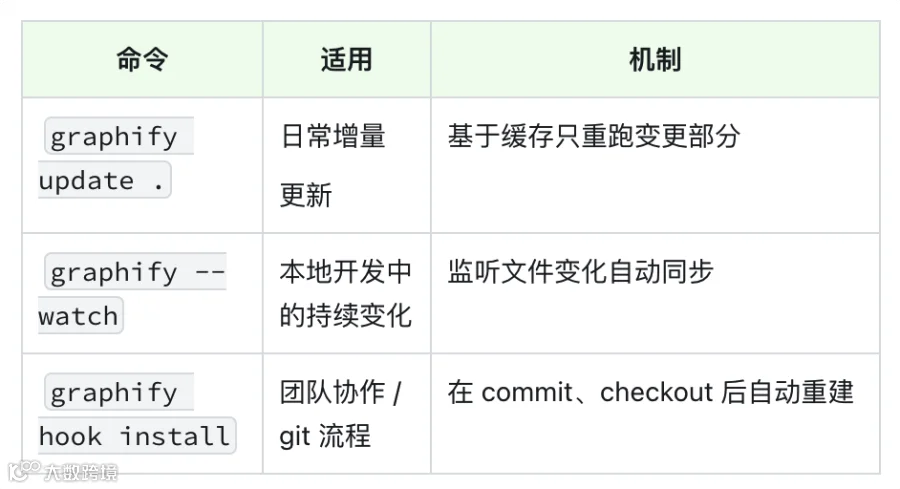
4
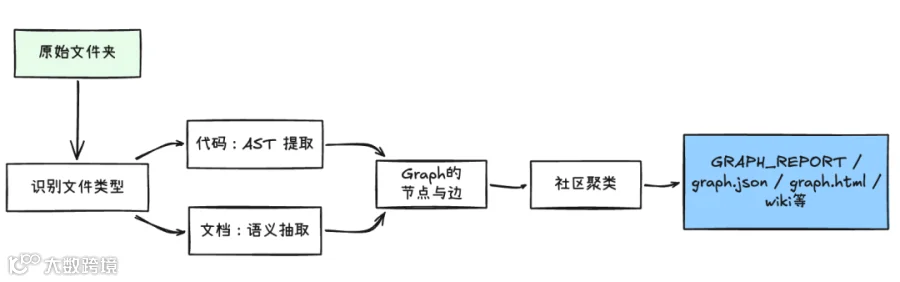
-
代码:AST(抽象语法树)抽取策略,拿到类、函数、调用、继承等显式结构与关系,不需要消耗 Token。 -
文档:借助模型进行语义理解与抽取,由 AI 编程助手的模型来完成。

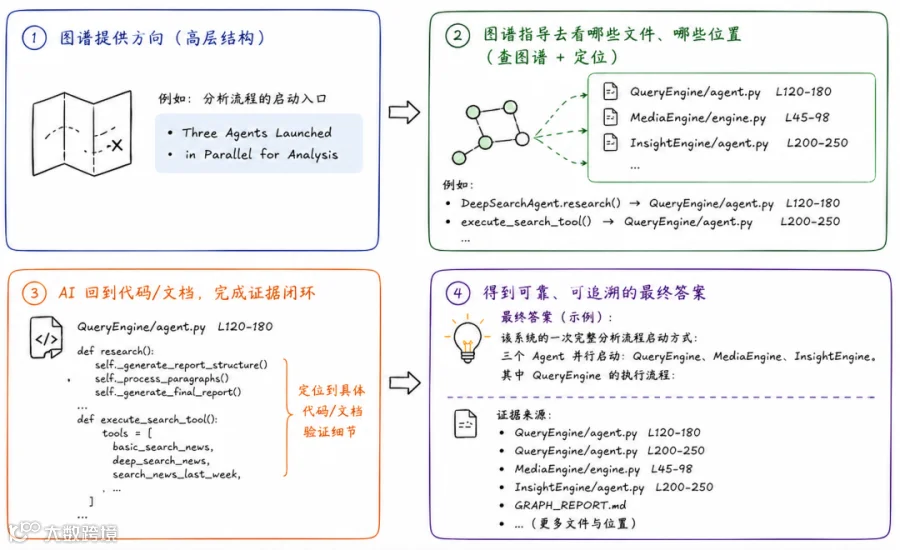
-
图谱先给 AI 助手提供方向 -
图谱告诉 AI 助手去看哪些源文件、哪些位置 -
AI 助手通过代码或文档完成证据闭环,得到答案
5
-
探索过程指标
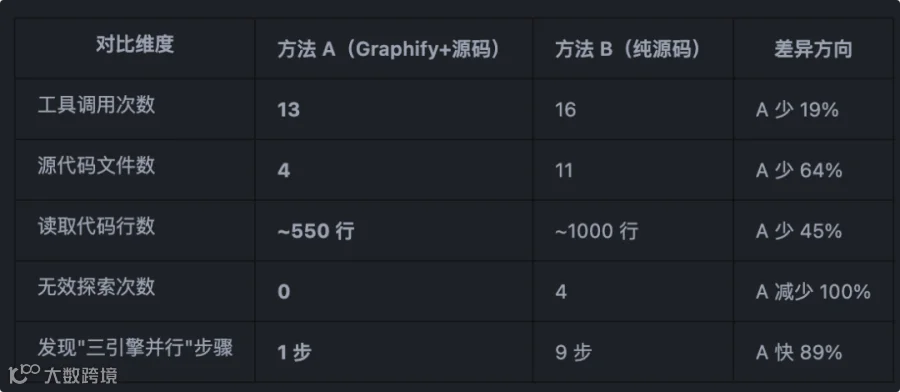
-
成本指标 这里的 Token 消耗是比较出乎意料的部分,下文会解释。
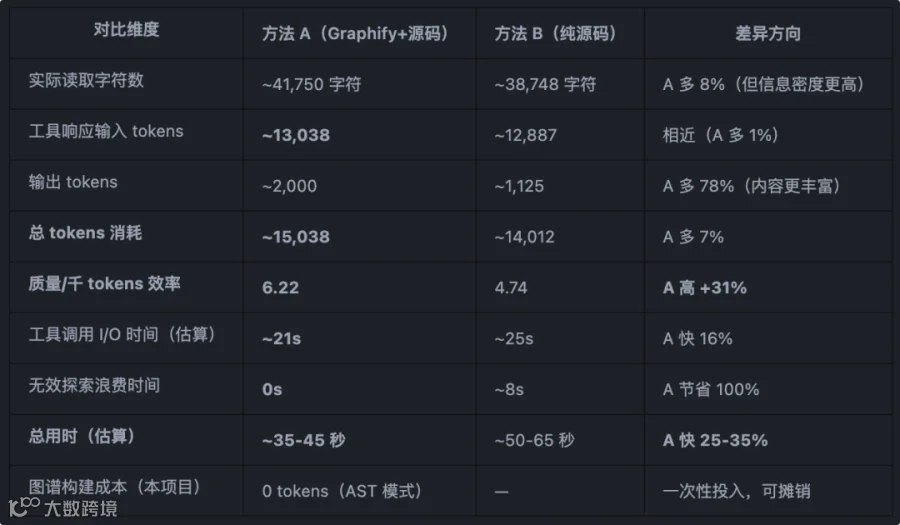
-
质量指标
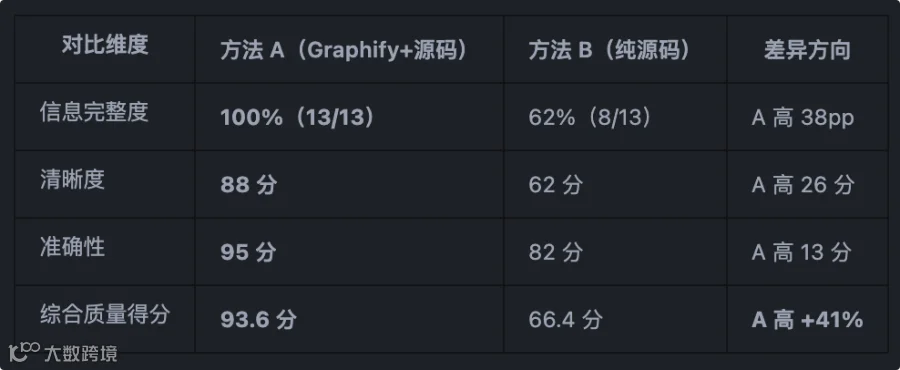
-
Graphify 在综合质量上提升非常明显。而探索成本(工具调用次数)反而更低,这证明了"以结构化知识导航代替直接文件探索"的策略有效性。 -
Graphify 的最大价值在于跨文件架构事实的获取。比如上面例子中的多引擎并行关系等需要"关系视图"的知识,这是纯代码探索较难完整获得的。 -
Graphify 方法是否一定节约 Token 会依赖于问题类型与模型/Agent。
问题类型:在探索系统整体架构、跨模块依赖的问题上,由于图谱及其报告中的信息很多时候能直接给出答案,节省 Token 更多;但是在细节性的问题上,由于必须深度读源代码,在 Token 上消耗差异不大。可以总结为:跨文件探索程度越高,Graphify 才能体现更高的 Token 优势。 此外,由于Graphify 在查询时通常会首先读取graph_report.md,本身也是一笔 Token 消耗。 模型/Agent:有时候探索倾向性更强的模型,会有很多”验证性“的读取大量源代码的行文,导致 Graphify 优势反而不明显。
6
-
某个函数的参数签名到底是什么 -
某段分支逻辑最终是怎么执行的 -
某个异常到底在哪里被抛出
-
这个业务概念和哪些代码相关? -
哪些接口处理了这个场景? -
如果更改这个接口,可能影响哪些代码和业务?
-
在specs 阶段,可以补充需求的边界场景、既有规则和约束文档; -
在design阶段,可以加载架构约束、接口约定、原型参考等;

END


