
点击上方蓝字加入我们


1
The rose is very beautiful.
请把英文“The rose is very beautiful.”翻译成中文:

-
上下文挤占:如果原句特别长(比如一大篇关于玫瑰的英文说明),前面输入的原题信息,可能会被后面生成的中文给“挤出去”。 -
任务混杂:模型必须在同一个流水线里,既要处理英文的语法(读懂原文),又要处理中文的逻辑(输出译文),还要自己领悟“哪些是原文、哪里开始是输出的结果,哪里要被重点参考”等等。
2
The rose is very beautiful 这句话从头到尾完整看一遍,把句子里词与词的关系、重点(比如 rose 是主语,beautiful 是核心形容词)整理成一份包含深度语义的“向量笔记”。
玫瑰”),它都会回头参考两部分信息:
-
自己已经写了什么?(我刚写了“ 玫瑰”) -
读题学生的“理解笔记”里关键信息是什么?(比如,原句后面说的是 very beautiful)
非常。
3
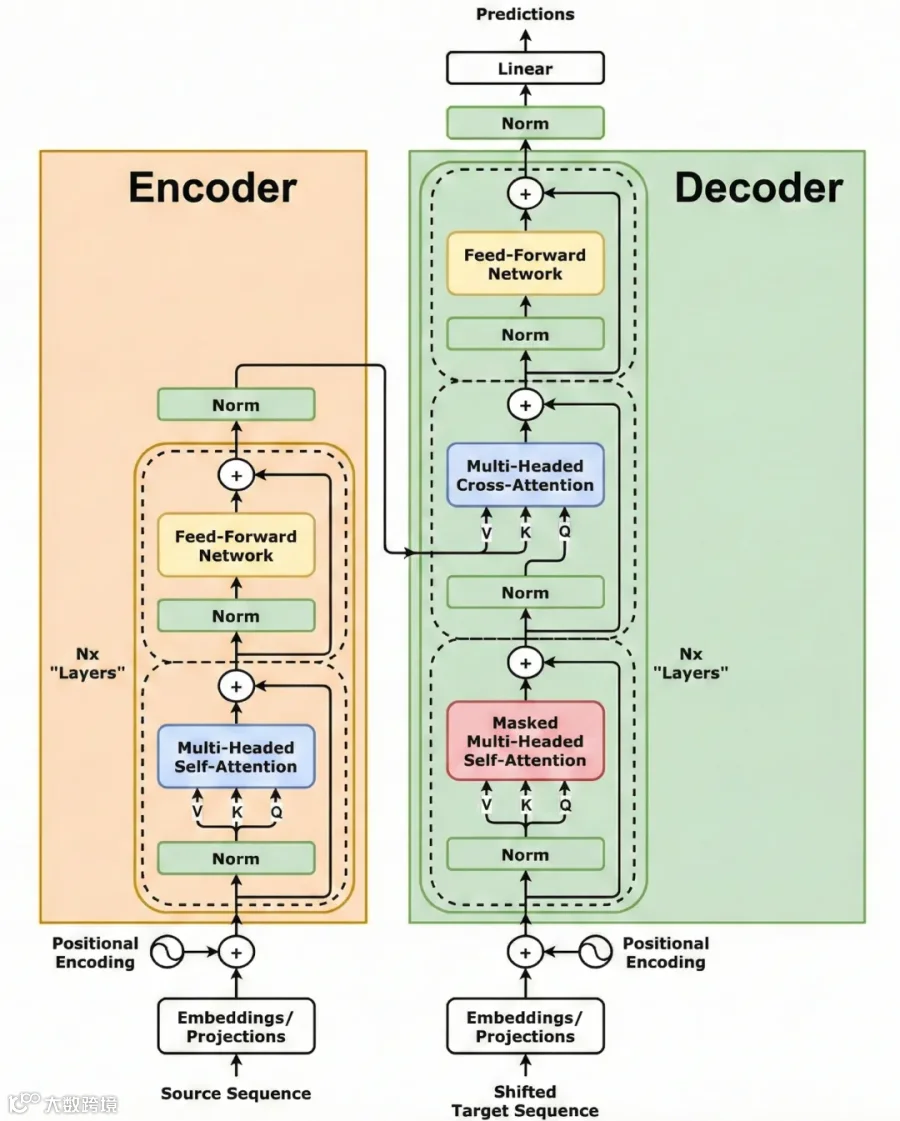
The rose is very beautiful” 后,Encoder 的过程和 GPT 模型的前向传播过程相似:
-
第一步,分词与嵌入,再加上位置嵌入,让每个词变成带有顺序信息的数字向量。 -
接下来,进入多层的 Encoder Block 进行加工。这里的重点是多头注意力机制与前馈网络(以及每个子层都会做的残差、层归一化等),和 GPT 训练的前向传播类似,但又有一个重要的区别:Encoder 里的自注意力机制是不加“遮罩(Mask)”的。
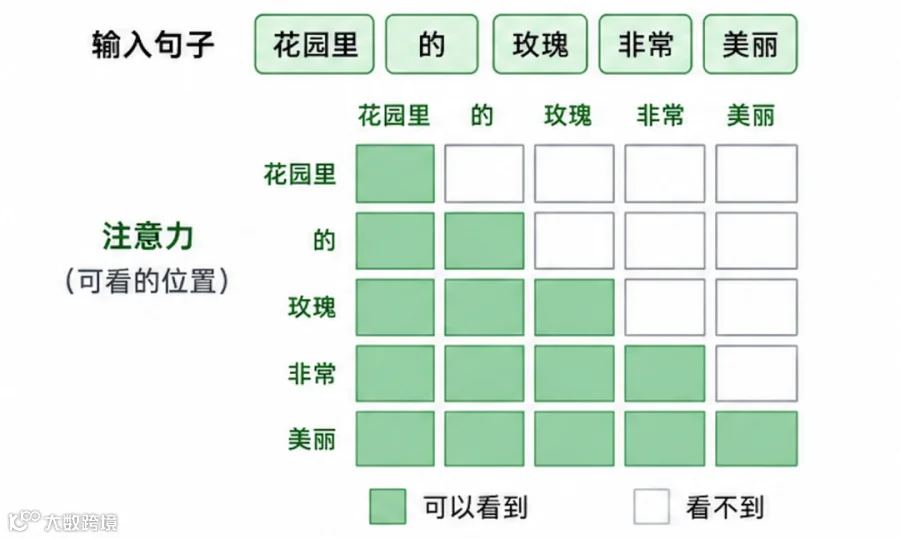
rose 可以同时和 beautiful 交换信息,互相理解。
-
经过多层处理,最开始的“词向量”,就变成了一组深度融合了整句上下文语境的“理解向量”。就好比学生彻底理解了题目,形成了清晰的“观察笔记”。
4
-
第一层:带遮罩的自注意力。如上文所说,Decoder 是在逐词生成答案,所以必须严格从左到右。 -
第二层:交叉注意力。
这是完整 Transformer 与 GPT 最大的区别! 如果说第一层的自注意力是 Decoder 内部事务 — 一段话内部的词“互相看和找关系“;那么这一层就是在翻看 Encoder 的理解笔记。 过程类似于:
Decoder 拿着当前写到的进度去问 Encoder:“我现在写到“ 玫瑰非常”了,英文原句里接下来最关键的信息是什么?” Encoder 的笔记反馈说,原句对应的重点是beautiful。于是 Decoder 吸收了这个关键提示。
-
第三层:前馈网络与输出。注意力机制负责“找信息”,前馈网络则负责“消化信息”,进行深度的非线性加工。最后通过线性层和 Softmax 算出词表里每个词的概率。
5
-
准备双语语料:把英文和中文都切成 token。 -
Encoder 读题:比如把英文 The red rose blooms.输入给 Encoder,得到一组代表原句语义的“理解向量”。 -
Decoder 练题:Decoder 开始逐个词生成中文。 - 输入 <开始符>,目标:预测红- 输入 <开始符> 红,目标:预测玫瑰- 输入 <开始符> 红 玫瑰,目标:预测绽放 -
不断查笔记与批改:Decoder 在每一步预测时,都会通过“交叉注意力”机制去参考 Encoder 的“理解向量”。如果最后预测错了(比如把“绽放”预测成了“枯萎”),损失函数就会给它扣分。 -
反向传播更新权重:模型根据扣分情况,反向调整内部的权重参数。
6
-
翻译:“请把【这朵玫瑰很美】翻译成英文:” -> 续写 -
摘要:“请总结这段关于玫瑰种植的内容:” -> 续写 -
代码:“请写一个 Python 函数画一朵玫瑰:” -> 续写 -
问答:“问题:玫瑰需要多少水分? 回答:” -> 续写 -
......
7
-
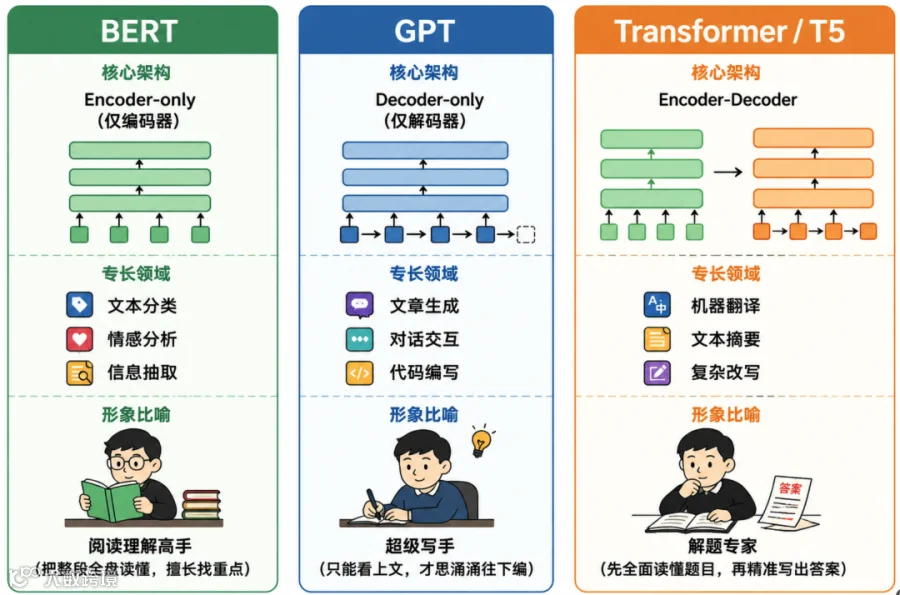
Transformer 有左右脑:左边 Encoder 负责全局读懂输入,右边 Decoder 负责逐字生成输出。 -
交叉注意力是核心桥梁:Decoder 在生成续写时,会不断回头查阅 Encoder 整理的“理解笔记”。 -
GPT 是目前主流 LLM 架构:因为它架构简单、适合规模化,能够用同一种形式适应不同的任务。


END


