在一个真正复杂的企业级软件设计与编码任务里,Coding Agent 面对的从来不是一句简单的“帮我写个小游戏”。
它要理解用户的原始需求,要读取项目里的既有代码,要遵守架构约束、编码规范、接口协议,还要调用各种工具、加载不同的技能和规则,甚至记住用户十分钟前随口补充的限制条件:
代码任务越往后推进,上下文就越像滚雪球:需求文档、历史对话、源码片段、报错日志、工具 schema、执行结果、……每一样都重要,但每一样都在消耗上下文窗口(还有 Token)。
这其实是 Coding Agent 的一个核心矛盾:
模型的上下文窗口再大,也不可能把整个项目、全部历史、所有工具和完整推理过程一股脑塞进去。
真正决定一个 Coding Agent 能不能跑长任务的,不只是模型有多聪明,而是它有没有一套成熟的“上下文管理机制”;而对于其他企业级 Agent 也是一样。
本文尝试一窥 Claude Code 上下文管理的一些关键机制,一方面能帮助我们更好地使用它;另一方面,也能为我们开发自己的复杂 Agent 提供重要参考。当然,它也是当下时髦的“Harness”的重要一环。
Claude Code 的上下文更像一套分层缓存:有会话级的基础信息,有每轮都可能变化的状态,有用到才加载的文件和规则;还有预算线、清理线和最后的“逃生通道”。模型负责推理,Agent 负责让它不迷路。
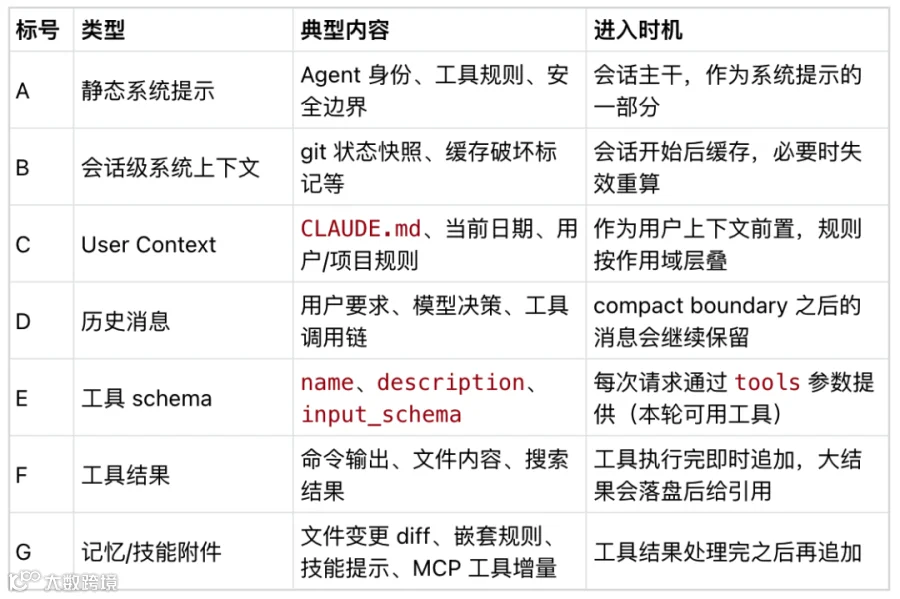
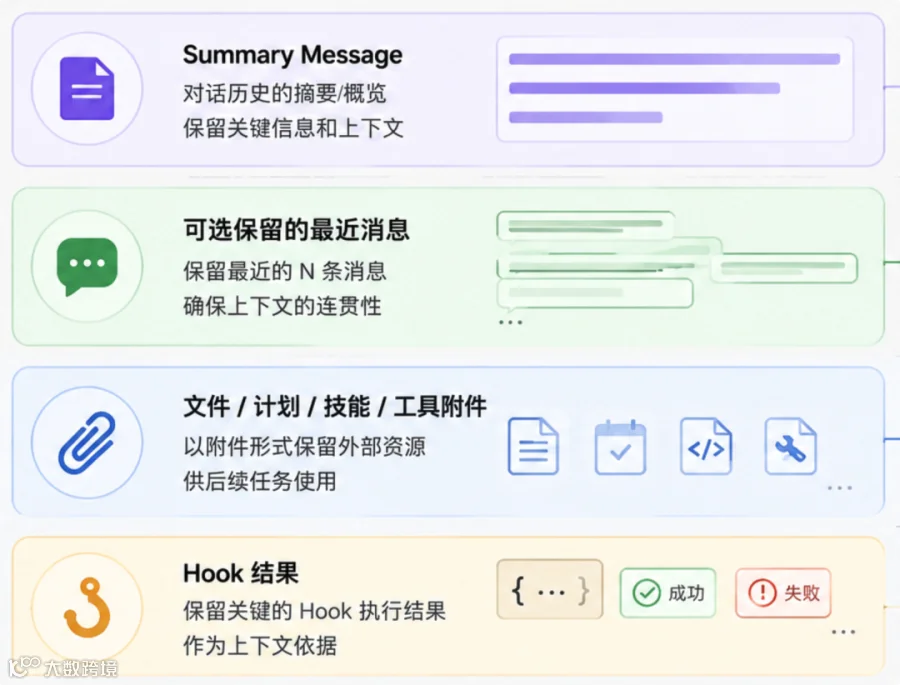
Claude Code 的上下文至少包含七类输入,每类有不同的进入时机和预算逻辑:
尽管不同类的上下文进入时机不一样,但有一些规则不可违背。
比如,Claude Code 发出 tool_use(工具调用)后,紧接着的 user message 必须优先放入对应的 tool_result。换句话说,普通说明、文件附件、系统提醒,都不能插在工具调用和工具结果之间。一些 Agent 框架也有类似约束。
整体上,Claude Code 上下文管理的一个基本原则是:
不是越多越好,而是要在正确时间,把正确粒度的信息,放在正确位置。
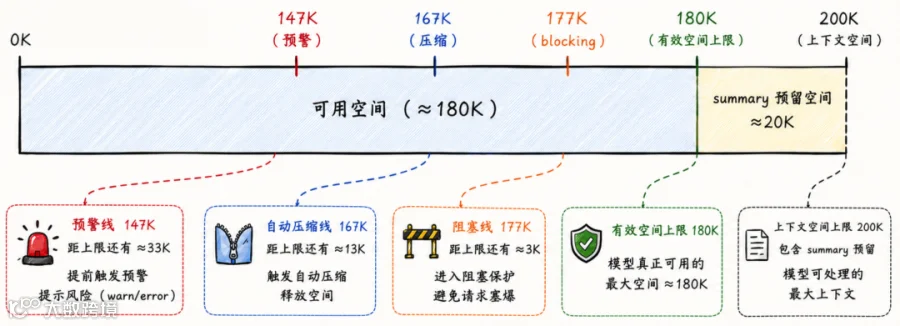
或许你在构建自己的 Agent 时只会关心"本轮 prompt 能不能发出去"。Claude Code 会把窗口当成预算来管理,而且会给“压缩动作本身”预留座位。
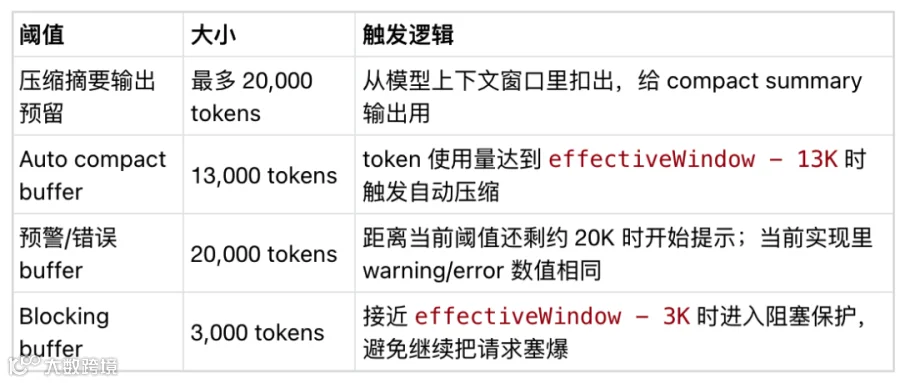
这里的 effectiveWindow 不是模型总窗口,而是:
effectiveWindow = 模型上下文窗口 - 压缩摘要输出预留
-
20K summary 预留:给“压缩模型生成 summary”预留的输出空间。
-
13K auto compact buffer:是给触发压缩留下的缓冲空间。
-
20K warning buffer:距离有效窗口上限约 20K 时开始预警
-
3K blocking buffer:接近 effectiveWindow 顶部时的硬保护。
以200K的上下文空间为例,大概是这样(不同版本可能会调整):
正常情况下,到了约 147K 会出现预警;如果继续增长到约 167K,自动压缩触发。压缩成功后,上下文会被重建并变小,预警自然消失。
另外,Claude Code 有一个熔断保护机制,防止压缩失败:连续压缩失败 3 次后系统自动停止重试,避免浪费 API 调用。由于 Claude Code 曾出现过单个会话连续失败 3,000+ 次,一天浪费约 25 万次 API 调用的情况,熔断是针对这类失控循环的安全阀。
压缩请求太长。即,“总结旧消息”这个请求本身就太长。
压缩请求没有返回有效文本、API调用错误、网络错误等。
如果压缩有pre/post的hooks,如果出现异常未拦截,也会异常。
Claude Code 的规则文件是按作用域分层读取。加载层级大致是:
-
企业或管理员规则:例如
/etc/claude-code/CLAUDE.md
-
用户规则,例如
~/.claude/CLAUDE.md
-
项目规则,例如项目里的
CLAUDE.md、.claude/CLAUDE.md
项目规则会从当前目录向上查找,再按“越靠近当前工作目录越具体”的顺序进入上下文。有两个特殊的机制:
-
.claude/rules/*.md 支持 YAML frontmatter 的 paths 字段:有 paths 的规则只在 Claude 读到匹配文件时触发。比如:
---
paths:"apps/web/**/*.tsx"
---
React components should follow the existing design system.
-
CLAUDE.md 还支持 @path/to/file 形式的 import — 可以把规则拆到其他文件里(会限制递归深度,避免一个规则文件把半个磁盘拖进上下文)。
有这些机制,好的 CLAUDE.md 应该类似“索引”,而不是百科全书。太早把所有东西塞进上下文,只会更早压缩。
- Backend is under `services/api`; frontend is under `apps/web`.- Do not edit generated files under `src/generated`.- Run package-scoped tests with `pnpm test --filter ...`.
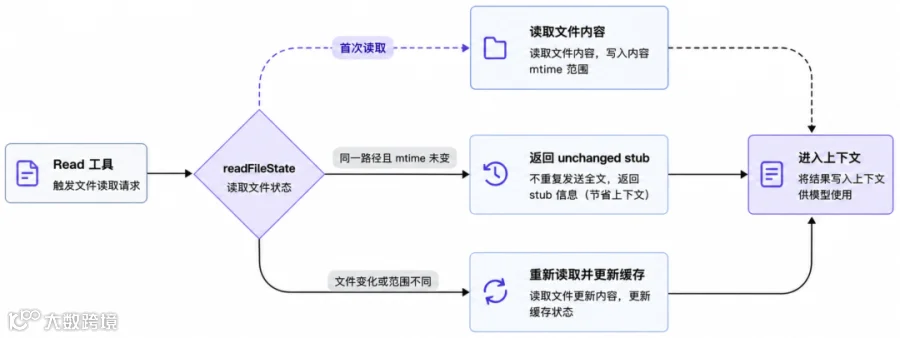
如果在一次会话中,读取大量文件(比如代码、规则),有的甚至会反复读取,如果不做控制,很容易撑爆上下文。
Claude Code 的机制是:维护一个文件内容缓存,记录每个已读文件的路径、内容和最后修改时间,上限为 100 个条目、25MB 总内存,超出时按 LRU,即最近最少使用原则淘汰旧条目。
这里的 “unchanged stub” 很关键。模型不需要再看一遍同一个 800 行文件,只需要知道:前面那次读取的内容仍然有效。
如果某个已经在缓存里的完整文件后来被外部修改,Claude Code 会比较旧内容和新内容,生成一段 diff/snippet 作为附件注入。总结下:
<persisted-output>
Output too large (124 KB). Full output saved to: /path/to/session/tool-results/abc123.txt
Preview (first2,000 bytes):
FAIL src/auth/login.test.ts
● AuthService › login › should reject invalid password
Expected: "Invalid credentials"
Received: "User not found"
...
</persisted-output>
Preview 只取开头约 2KB,并尽量在换行处截断。这个选择很有意思 — 测试日志和命令输出的第一个失败点通常就在前面;如果不够,模型还可以去读落盘文件。不过多数时候,2KB 已经足够判断下一步该看哪个文件。
Micro compact 可以理解成“轻量打扫桌面”。它不重新总结整段对话,也不搬迁任务现场,只处理那些最容易膨胀的东西:旧工具结果、缓存里的大块输出、部分 thinking 内容。
其中最主要的一个机制是:Time-based micro compact。
这个逻辑最好理解:如果会话停了很久,服务端 prompt cache 多半已经过期,下一轮请求反正要重新发送 prefix。既然如此,就别把很久以前的测试日志、搜索结果、文件输出再完整发一遍。
这个触发时机是:距离上一条主线程 assistant 消息超过阈值(默认60分钟)。
历史消息(压缩前):
[turn 3] Bash → 测试输出 15,000 tokens
[turn 4] Bash → 编译日志 8,000 tokens
[turn 5] 用户:继续修
历史消息(micro compact 后):
[turn 3] Bash → [Old tool result content cleared]
[turn 4] Bash → [Old tool result content cleared]
[turn 5] 用户:继续修
这样模型还能知道“之前调用过什么工具”,也能保留 tool_use / tool_result 的消息结构,但不用背着几万 token 的消息历史继续跑。
第三层:Session memory compact(实验性)
Session memory compact 是一条更轻的压缩路径。它不重新总结整段对话,而是用已经存在的 session memory 承接旧状态,再保留最近一段消息。
Claude Code 在长会话中提前写好的、按 session 存放的滚动摘要,类似边聊边记的“会议纪要” — 由一个专门的 Agent 在一定的时机(比如消息量达到1万token)负责写入到文件。
前 60 轮:
- 用户让 Claude 重构登录模块
- Claude 读了 auth/service.ts、auth/session.ts
- 修过一次 token 过期 bug
- 跑过测试,失败原因是 mock clock 没同步
- 最后已经把这些状态写进 session memory
最近 20 轮:
- 用户继续让 Claude 修登录页 UI
- Claude 刚读了 LoginForm.tsx
- 刚调用 Bash 跑了前端测试
- 最新失败日志还在最近消息里
Session memory compact 的思路不是把前80轮的对话交给 summarizer 做全量压缩,而是:
前 60 轮状态:
不重新总结,用已经存在的 session memory 承接
最近 20 轮:
保留一段原始消息,尤其是刚刚读过的文件、刚刚失败的测试、最新用户要求
compact boundary
→ session memory 摘要:
当前任务:重构登录模块并修 UI
已改文件:auth/service.ts、auth/session.ts
已知问题:mock clock 曾导致测试失败
用户约束:保持旧 API 兼容
→ 最近消息:
用户:继续修 LoginForm
Claude:Read LoginForm.tsx
Claude:Bash pnpm test ...
工具结果:前端测试失败日志
当然,Claude Code 会小心处理工具协议的边界:如果保留区里有 tool_result,就往前找对应的 tool_use,避免把一对工具调用拆散。
很显然,这条路径适合已经有稳定 session memory 的超长会话 — 旧状态已经被搬进记忆文件,没必要每次都让 summarizer 重新复述一遍整个旅程。
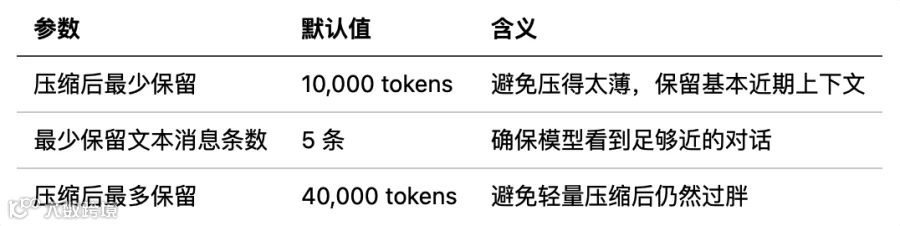
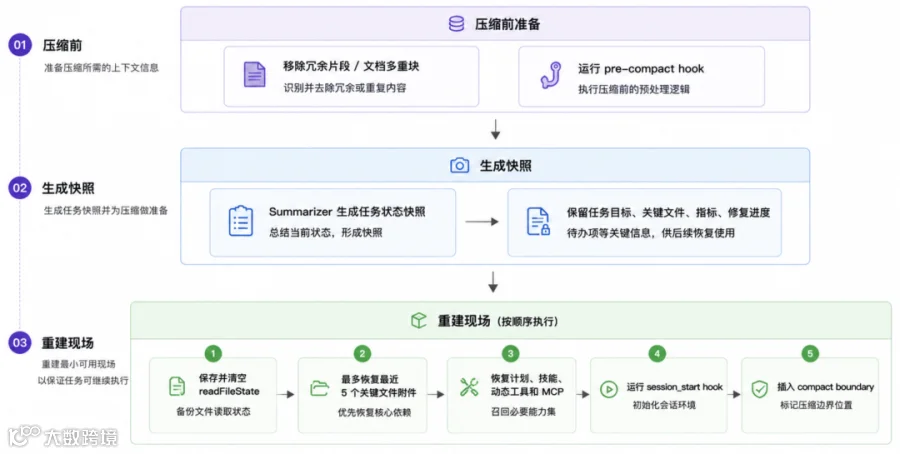
Auto compact 更像一次大清理和”搬家“。它要做的不是“把聊天记录简单压缩成三段话”,而是把任务现场搬到一个全新窗口里。
很显然,压缩并非想的那么简单 — 让模型 summarize 下就行。
比如,压缩后如果不重新声明动态工具、MCP 指令、已发现工具等信息,模型可能以为某些工具已经不存在。Claude Code 会在重建阶段重新注入 tools、agent listing 等上下文,确保压缩前能用的能力,压缩后仍然看得见。
第五层:Reactive compact (PTL “逃生”)
PTL 是 Prompt Too Long。这是一种很尴尬的情况:你已经知道要压缩了,但“压缩请求本身”也太长,发不出去了。怎么办?
最后的兜底方式是:把对话按 API round 分组,从最旧的一组开始丢,直到覆盖错误里报告的 token 差距;如果不知道这个差距,就先丢约 20% 的旧分组。最多重试 3 次。
这是最后的急救通道。正常系统不应该常走到这里,但现实里会有图片、文档、超大日志、工具结果没及时瘦身等各种情况。PTL 逃生的目标只有一个:不能让用户卡死在“想压缩却压缩不了”的死循环,换句话说,先让任务活下来,再谈优雅恢复。
可以看到 Claude Code 的上下文管理,本质上是一套分层缓存 + 多级预算管理系统。那么这套机制对我们开发 Agent 有些什么启示呢?
静态提示、动态环境、用户规则、历史消息、工具 schema、附件、工具结果各有不同生命周期,要分层分级管理,混在一起是 token 浪费的主要来源。
不能等到上下文塞满,报错了才压缩,那时候压缩本身可能也塞不进去。最重要的是,一次报错的后果很可能是致命的。
小结果内联;大结果落盘 + preview;历史结果可以定期根据重要性做清除。分层的处理比一刀切截断更灵活,也更可追溯,且不会丢失重要信息。
核心指令、任务目标、关键文件路径、待办事项、重要错误与修复结果都要保留,确保压缩后 Agent 能继续干活,而不是得了“健忘症”。
能读文件就要能判断文件是否变了;能用工具就要能清除旧结果;能加载规则就要能去重防止重复注入;或者说,把宝贵的上下文空间留给最重要的信息。
下回我们聊聊 Claude Code 的 Memory 机制:它如何在会话之外保存状态,又如何和上下文压缩配合起来。欢迎继续关注。