
如果说大模型是一辆超级跑车,那算子就是跑车的核心零件:发动机、变速箱、刹车系统……
没有这些零件,跑车就是一堆废铁;不懂这些零件,你永远只能当乘客,没法自己造车、改车,更没法看懂大模型的底层逻辑。
上一篇我们讲了算子的本质:神经网络的最小计算单元,是大模型算力消耗的核心来源。今天,我们就把大模型里最核心、最常用的10个算子,一次性拆解透彻,帮你彻底搞懂大模型的底层计算逻辑。
二、10大核心算子全拆解
1. 矩阵乘(MatMul):大模型的「算力黑洞」
✅核心作用:完成向量/矩阵之间的乘法运算,是所有线性变换的基础。
⚡算力消耗:⭐⭐⭐⭐⭐(最高)
📌应用场景:
自注意力机制中Q、K、V的生成、相似度计算、加权求和
全连接层(MLP)的核心运算
模型参数与输入特征的映射
💡一句话总结:大模型90%以上的算力都耗在矩阵乘上,是当之无愧的「算力黑洞」,也是GPU加速的核心优化对象。
2. 激活函数(Activation):大模型的「非线性开关」
✅核心作用:给网络注入非线性,让模型能学习复杂规律(没有激活函数,神经网络就是线性模型,只能拟合简单直线)。
⚡算力消耗:⭐⭐
📌主流类型:
ReLU:最经典,计算简单,缓解梯度消失
GELU:Transformer默认,平滑性更好,训练更稳定
SwiGLU:最新大模型(LLaMA、GPT-4)首选,性能更优
💡一句话总结:没有激活函数,大模型就是「线性代数计算器」,根本学不会语言、图像等复杂任务。
3. 归一化(Normalization):大模型的「稳定器」
✅核心作用:标准化网络层的输入分布,加速训练、防止梯度消失/爆炸,提升模型稳定性。
⚡算力消耗:⭐⭐
📌主流类型:
LayerNorm(层归一化):Transformer标配,对每个样本的特征做归一化
RMSNorm:LLaMA等模型采用,简化计算,性能与LayerNorm相当
BatchNorm(批归一化):CV领域常用,大模型中较少使用
💡一句话总结:归一化是大模型训练的「定海神针」,没有它,模型很容易训练崩溃,根本跑不起来。
4. 残差连接(Residual Connection):大模型的「梯度高速公路」
✅核心作用:在深层网络中,让梯度能直接从输出传回输入,解决深层网络的梯度消失问题,让模型能堆叠上千层。
⚡算力消耗:⭐
📌应用场景:Transformer的Encoder/Decoder层、ResNet等深层网络
💡一句话总结:残差连接是大模型「深度」的保障,没有它,就没有现在的千亿参数大模型。
5. 自注意力(Self-Attention):大模型的「理解核心」
✅核心作用:让模型能计算输入序列中每个token与其他所有token的关联度,实现「上下文理解」,是Transformer的灵魂。
⚡算力消耗:⭐⭐⭐⭐⭐
📌衍生类型:
多头注意力(Multi-Head Attention):拆分多个注意力头,学习不同维度的关联
因果注意力(Causal Attention):Decoder-only模型(GPT)标配,防止未来信息泄露
稀疏注意力:优化长序列算力消耗
💡一句话总结:自注意力是大模型「理解语言」的核心,是ChatGPT等模型能对话的根本原因。
6. Softmax:大模型的「概率转换器」
✅核心作用:将模型的输出logits转换为0-1之间的概率分布,让模型能输出「下一个token的预测概率」。
⚡算力消耗:⭐⭐
📌应用场景:
自注意力机制中的权重归一化
分类任务、生成任务的输出层
💡一句话总结:Softmax是大模型「生成文字」的最后一步,没有它,模型只能输出无意义的数值,没法生成通顺的句子。
7. 池化(Pooling):大模型的「信息压缩器」
✅核心作用:对特征图进行下采样,压缩信息、降低维度,减少算力消耗,同时保留核心特征。
⚡算力消耗:⭐
📌主流类型:
最大池化(Max Pooling):保留最显著的特征
平均池化(Average Pooling):保留整体特征
全局池化(Global Pooling):将特征图压缩为单个向量
💡一句话总结:池化是CV模型的核心算子,在大模型中多用于特征压缩、长序列处理。
8. 卷积(Convolution):大模型的「局部特征提取器」
✅核心作用:通过卷积核提取局部特征,是CV模型的基础,在大模型中多用于视觉模型(ViT)、长序列优化。
⚡算力消耗:⭐⭐⭐
📌应用场景:
CNN视觉模型(ResNet、YOLO)
ViT模型的Patch Embedding
💡一句话总结:卷积是CV领域的「王者算子」,也是大模型多模态能力的重要支撑。
9. 嵌入(Embedding):大模型的「数据翻译官」
✅核心作用:将离散的输入(文字、图像、音频)转换为连续的向量,让模型能处理非数值数据。
⚡算力消耗:⭐⭐
📌应用场景:
词嵌入(Word Embedding):将文字转换为向量
位置嵌入(Positional Embedding):给序列注入位置信息,让模型理解语序
图像嵌入(Patch Embedding):将图像转换为序列向量
💡一句话总结:Embedding是大模型的「输入大门」,所有数据都要通过它才能进入模型计算。
10. Dropout:大模型的「防过拟合神器」
✅核心作用:在训练过程中随机失活一部分神经元,强制模型学习更鲁棒的特征,防止过拟合,提升模型泛化能力。
⚡算力消耗:⭐
📌应用场景:全连接层、注意力层、训练阶段(推理时关闭)
💡一句话总结:Dropout是大模型训练的「正则化工具」,让模型在训练后能更好地泛化到 unseen 数据。
三、10大算子核心价值总结表
算子名称 |
核心作用 |
算力消耗 |
核心场景 |
|---|---|---|---|
矩阵乘 |
线性变换、特征映射 |
⭐⭐⭐⭐⭐ |
自注意力、 全连接层 |
激活函数 |
注入非线性 |
⭐⭐ |
所有网络层 |
归一化 |
稳定训练、加速收敛 |
⭐⭐ |
Trans层 |
残差连接 |
解决梯度消失、支持深层网络 |
⭐ |
深层网络 |
自注意力 |
上下文理解、序列建模 |
⭐⭐⭐⭐⭐ |
Trans核心 |
Softmax |
概率转换、输出归一化 |
⭐⭐ |
注意力、输出层 |
池化 |
特征压缩、降维 |
⭐ |
CV、长序列处理 |
卷积 |
局部特征提取 |
⭐⭐⭐ |
CV、多模态 |
嵌入 |
数据向量化、输入处理 |
⭐⭐ |
输入层 |
随机失活 |
防过拟合、提升泛化 |
⭐ |
训练阶段 |
四、写在最后
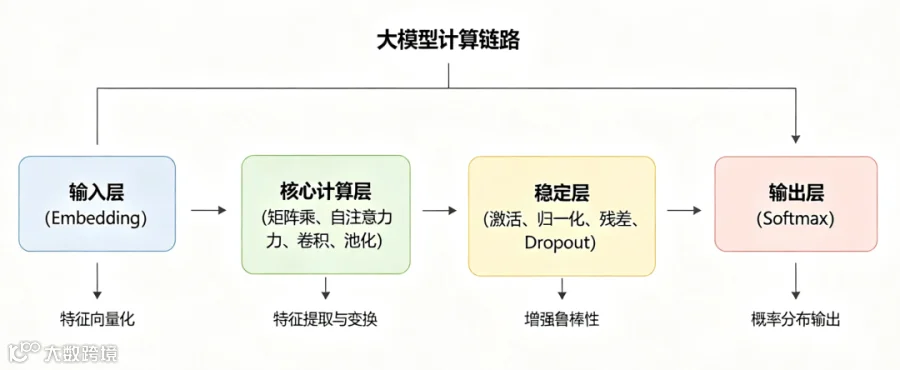
这10个算子,就是大模型的「底层积木」:
输入层:靠Embedding把数据变成模型能懂的向量
核心计算层:靠矩阵乘、自注意力完成特征提取与上下文理解
稳定层:靠归一化、残差连接、Dropout保证训练稳定
输出层:靠Softmax把计算结果变成可理解的概率
搞懂了这10个算子,你就彻底搞懂了大模型的底层计算逻辑,不管是读论文、做优化、还是自己搭模型,都能做到心中有数。
下篇预告
下一篇,我们会聚焦大模型的算力优化,拆解这些算子的优化技巧:如何通过算子融合、量化、稀疏化,在不损失精度的前提下,把大模型的算力消耗砍半,让千亿参数模型能在消费级硬件上跑起来。