
上一篇我们完整拆解了自注意力机制的核心计算流程,从Q、K、V的生成,到矩阵乘、Softmax,再到最终的加权求和,把注意力机制的核心逻辑讲得明明白白。但你有没有想过:就是这样一个看似基础的矩阵运算,为什么会成为大模型的「算力黑洞」?
为什么训练一个千亿参数大模型,需要上万张A100/H100显卡,烧掉数亿人民币?为什么我们用普通电脑跑大模型,会慢到让人崩溃?为什么大模型的长上下文功能,对硬件要求高到离谱?
今天这篇,我们就彻底讲透:自注意力机制里的矩阵乘(MatMul),到底是怎么吃掉海量算力的,以及它为什么是大模型硬件成本的核心来源。
一、先搞懂:矩阵乘到底是什么?
在自注意力机制里,矩阵乘是最核心、也最吃算力的一步,本质上就是让两组信息做一次全量的两两匹配。
我们用大白话拆解:
• Q矩阵:每个词的「查询」,代表这个词「想找什么信息」
• K矩阵:每个词的「键」,代表这个词「有什么信息」
• 矩阵乘(Q × K^T):让每一个词的查询,都和所有词的键做一次匹配打分,算出每个词和其他所有词的关联度
举个最通俗的例子:就像一个班级有n个学生,矩阵乘就是让每个学生都和全班所有同学(包括自己)做一次一对一交流。n个学生,就要做n×n次交流——学生越多,交流次数就呈平方级暴涨。
对应到自注意力场景,n就是「输入文本的token长度」。比如你输入1000个汉字,Q和K的矩阵大小就是1000×d(d是向量维度),它们相乘就会得到一个1000×1000的注意力分数矩阵,也就是要做1000×1000=100万次计算。
如果你输入4096个token(大模型的常见上下文长度),计算量就直接变成4096×4096≈1600万次,是1000token的16倍!
二、为什么矩阵乘是「算力黑洞」?核心是O(n²)的时间复杂度
矩阵乘之所以能成为大模型的算力黑洞,核心原因就是它的时间复杂度是O(n²)——计算量和输入长度n的平方成正比,是指数级暴涨,而不是线性增长。
我们用一组直观数据,让你秒懂这个差距:
输入 token 长度 |
矩阵乘 计算量(次) |
相对 1000 token 算力倍数 |
|---|---|---|
1000 |
1,000,000 |
1 倍 |
2048 |
~4,194,000 |
4.2 倍 |
4096 |
~16,777,000 |
16.8 倍 |
8192 |
~67,108,000 |
67.1 倍 |
128000(128k) |
~16,384,000,000 |
16384 倍 |
你看,只是把上下文从1000token拉到8192token,算力需求直接暴涨了67倍;如果拉到128k长上下文,算力需求直接翻了1.6万倍!
这就是为什么大模型的上下文越长,跑起来越慢、越吃显卡——不是多了一点点计算,是多了十几倍、上万倍的计算量。
在大模型的整个计算流程里,矩阵乘是最吃算力的环节,没有之一。其他计算(比如Softmax、加性偏置、激活函数)的复杂度都是O(n),和输入长度成正比,哪怕n翻倍,计算量也只翻倍;但矩阵乘是O(n²),直接把算力需求拉到了天花板。
可以说,大模型的算力成本,80%以上都花在了矩阵乘上——这就是「算力黑洞」的由来。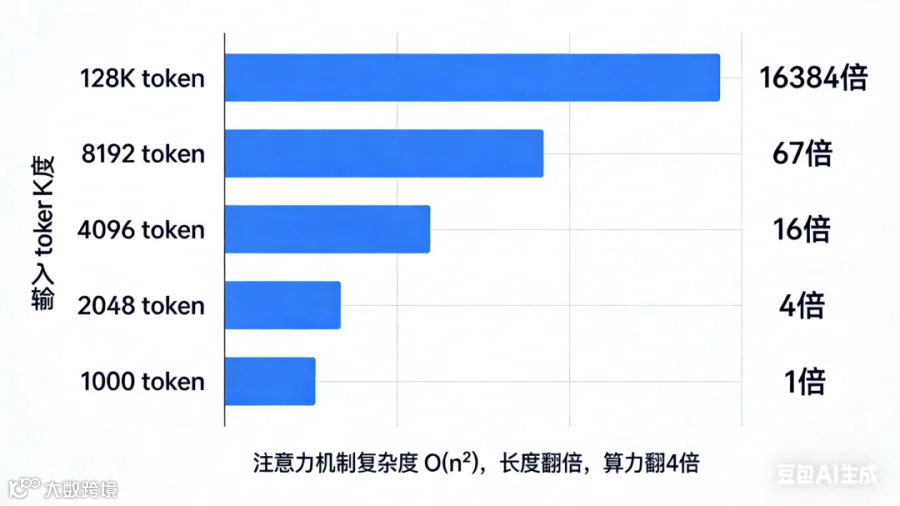
三、矩阵乘的算力黑洞,到底影响了什么?
搞懂了矩阵乘的本质,我们就能看懂大模型行业里的所有核心问题,本质上都是在和这个「算力黑洞」死磕。
硬件层面:为什么大模型只认高端显卡?
矩阵乘是高度并行化的计算,刚好能发挥GPU(显卡)的并行计算优势,而CPU的串行计算完全跟不上。
这就是为什么:
• 训练大模型必须用A100/H100这种顶级训练卡,普通消费级显卡根本扛不住;
• 我们用普通电脑跑大模型,会因为矩阵乘的算力不足,导致推理速度极慢;
• 大模型的硬件成本,本质上就是矩阵乘的算力成本。
应用层面:为什么长上下文大模型这么难?
正是因为矩阵乘的O(n²)复杂度,大模型的上下文长度才一直是技术瓶颈。
早期大模型上下文只有2048token,后来慢慢做到4k、8k、32k、128k,每一次提升,都需要硬件算力的指数级提升,以及算法层面的极致优化。我们现在能用到长上下文大模型,本质上就是工程师们在和矩阵乘这个「算力黑洞」死磕的结果。
个人开发者/嵌入式场景:为什么机器人上跑大模型这么难?
这也是我在做机器人项目时最头疼的问题:机器人的嵌入式硬件算力有限,根本扛不住大模型矩阵乘的算力开销。
所以我们才需要做算子优化、模型量化,本质上就是在给矩阵乘「减负」,让它能在有限的算力下跑起来。
四、写在最后:矩阵乘,是大模型的「命门」
矩阵乘,看似只是一个基础的线性代数运算,却是大模型的「命门」。
它决定了大模型的算力成本、推理速度、上下文长度,甚至决定了大模型能在什么硬件上运行。所有大模型的优化技术,从算子融合、模型量化,到vLLM的PagedAttention,核心目标都是为了「干掉矩阵乘的算力浪费」,让大模型跑得更快、更省算力。
搞懂了矩阵乘是算力黑洞,我们接下来就会明白:为什么大模型需要算子优化、模型量化这些技术。下一篇,我们就来拆解:什么是AI算子?它为什么是神经网络的最小计算单元?