

【前言】
本文再回头来深度研究下「光互联」赛道,剖析其中多个细分,包括插拔光模块、OCS、CPO等,涉及技术方向、产业趋势、商业竞争格局等;
行文逻辑部分借鉴于让尘博士的产业观点论述,并逐个展开进行学习,深入阐述;
综合下来有几点重要观点,一是光互联超级周期仅仅刚开始,未来的巨大空间在Scale up;
二是CSP们在互联方案上的选择,不会“宗教式”地执着某一家供应商或某一种方案,要回到商业视角看待,多数云厂商都会多种互联方案并推,包括可插拔、NPO、XPO等,即各种方案不必互相争论谁是未来唯一,头部厂商的核心竞争力之一就是同时具备多种光互联方案能力,比如旭创等;
三是光互联上游的激光器、光器件等,从未来产业规模看,仍是制约瓶颈之一,换言之发展空间较大,也是英伟达连续投资LITE、康宁等动作的原因,为下一代CPO集成做准备;
四是铜缆是能用尽用,但由于无法解决的物理局限性,800G以上铜缆传输速率、散热等问题开始“撞墙”,光进铜退是必然趋势;
其他还有CPO短期商业化进程中堵点背后的商业逻辑、OCS的缺点等等。
下面逐一展开阐述学习。

【正文】
一、脑灰质与脑白质,算力瓶颈从GPU算力转向互连
1、人脑神经网络的底层逻辑
谈算力瓶颈,从脑灰质和脑白质结构谈起,因为大模型的底层训练基于人工神经网络Artificial Neural Network,所以本质上AI大模型的逻辑,可以用人脑神经网络底层逻辑去类比;
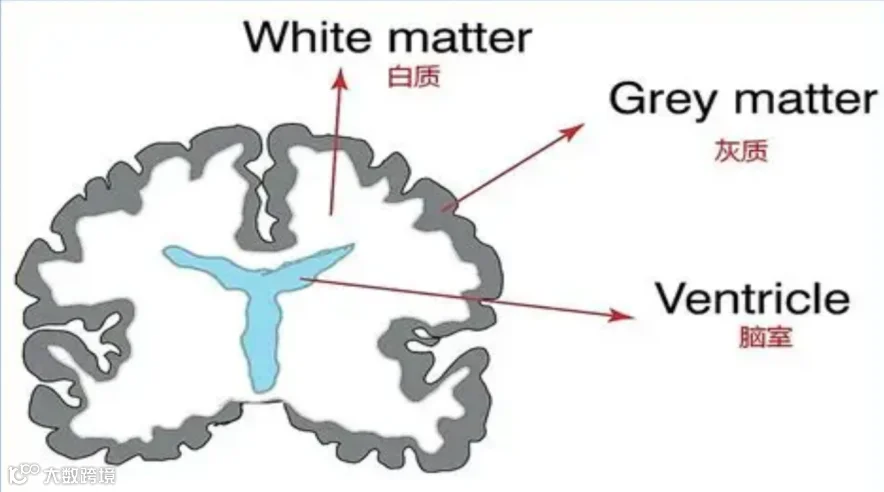
在神经科学中,脑灰质主要由神经元胞体构成,负责认知、推理、记忆与计算,是大脑执行信息处理的核心区域;
而脑白质则由大量包裹髓鞘的神经纤维组成,其作用并不是“思考”,而是负责不同脑区之间的信息传输与协同;
现代神经科学已经逐渐发现,决定高级智能表现的,并不仅是灰质规模,而是灰质与白质之间的协同效率,一个拥有更强连接能力的大脑,往往比单纯拥有更多神经元的大脑更高效;
原因在于,复杂认知本质上并不是某一个脑区独立完成,而是多个脑区之间持续的信息交换、同步与反馈。如果连接效率下降,即便单个脑区能力再强,也会因为信息传输受阻而导致整体认知效率下降。
那么相对应的,“脑灰质”对应计算单元(GPU/TPU 芯片),负责单点计算与 “思考”;
“脑白质”对应互连系统(光互连 / 高速网络),负责连接计算单元,传递数据与信号。
2、“脑白质”互联在超大集群数据中心,逐步成为制约瓶颈
过去多年,全球算力主要集中于“灰质扩张”——即不断提升单芯片算力;
从CPU到GPU,再到AI ASIC,产业不断追求更高FLOPS、更大HBM带宽、更先进制程,其逻辑本质上都是在提升“单个神经元”的计算能力;
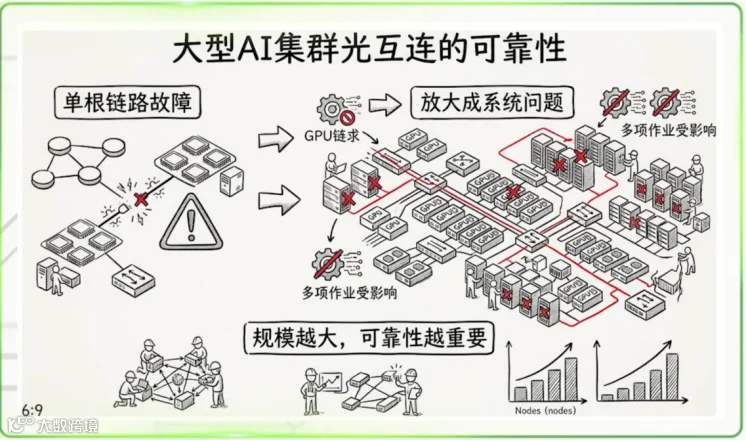
然而,当AI训练开始进入万卡、十万卡时代后,系统瓶颈开始从“计算能力不足”转向“连接能力不足”。
因为超大规模AI集群,本质上并不是一颗芯片,而是一个分布式系统。每一次模型训练,都需要海量GPU之间持续进行参数同步、梯度交换、Token调度与数据搬运;
GPU越多,系统内部的信息交互复杂度越高。其通信压力并非线性增长,而更接近指数级增长。
这意味着,当AI进入大规模集群时代后,真正决定有效算力的,已经不再只是GPU本身,而是GPU之间的连接效率;
一个拥有10万张GPU、但互连效率低下的系统,其实际利用率可能远低于一个连接高效的5万卡系统;
换句话说,未来AI竞争的核心,不再只是“谁拥有更多GPU”,而是“谁能够让更多GPU高效协同工作”。
以上正是“脑灰质”互联价值重估的底层逻辑。
3、AI大规模“白质”建设是产业必然趋势课题
过去GPU是AI时代的“灰质扩张”,那么未来光互联、本地交换、Scale Up网络、Scale Out网络以及跨数据中心光网络,则正在成为AI时代真正的“白质建设”;
关键是,其产业地位,正在从数据中心中的辅助组件,逐步上升为决定AI系统效率的核心基础设施;
【光互联GAP现状】过去三年多,AI算力增长了约300倍,但光连接的总带宽仅增长了约30倍。这导致限制AI集群规模的瓶颈已不再是单点算力,而是芯片间的数据搬运效率;
自然界进化论趋势是:低等动物的白质比例很低,而人类大脑的白质与灰质比例接近1:1。目前AI系统还处于“小鼠”阶段,未来互连(白质)的增长速度必须超过计算(灰质),才能保证算力不被浪费;
也就是说,未来“脑白质”互联的发展速度,要显著快于“脑灰质”算力的扩张速度。
随着GPU集群规模持续扩大,网络带宽需求将呈现远高于算力本身的增长斜率;
未来AI系统对于互连带宽、交换容量、光链路密度以及低时延通信的需求,可能是当前水平的数倍甚至十倍以上,尤其是Scale up潜力巨大。
从这个角度看,光互联并非单纯受益于AI算力增长,而是在AI架构演进过程中,从“外围通信设备”升级为“AI系统神经网络”;
CSP们开始将互连能力视为下一代AI基础设施竞争的核心。因为未来真正稀缺的,可能不再是单颗GPU的算力,而是整个AI系统内部的信息流动能力。
二、Scale Up、Scale Out及Scale Across共同构成光互联
AI时代的互连,需要从Scale Up、Scale Out以及Scale Across三个层面重新理解整个AI Fabric。
目前一个大数据中心基本是万卡互联,包含多层网络的互联,大脑内(Scale up)的互联基本是10倍带宽的互联,英伟达机架逐步从NVL72到NVL576,Scale up的互联是未来最大的增长极;
同时,过去柜内都是铜缆连接,由于铜缆的物理局限性,光互联就是必然趋势,大脑内未来需连接更多芯片,谷歌最多已能做到连接9000颗TPU,未来只会越连越多。
互联底层逻辑上的核心逻辑转变:
过去云计算时代,数据中心网络的核心目标,是解决“服务器之间的数据交换”,传输具有低同步、高容错、低实时性的特点;
而AI时代,表面上传输特点类似,实质上大模型训练则要求极高频率的数据同步、极低时延以及持续的大带宽交换,本质不同,所以AI时代的互联,开始从传统的“IO系统”,逐渐演变为“算力系统组成部分”。
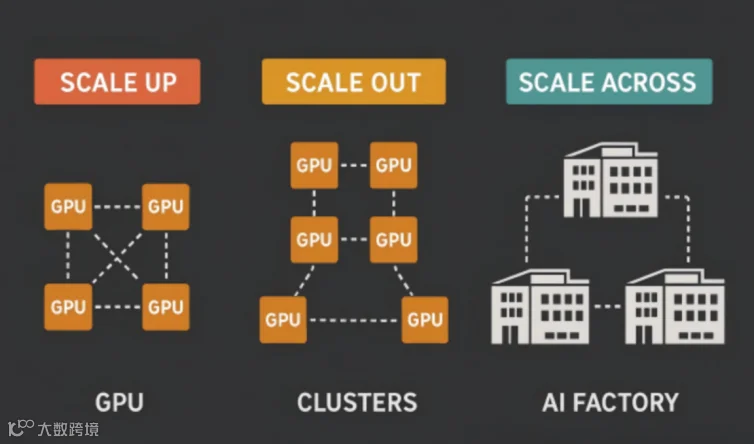
1、Scale Up的光进铜退趋势
Scale Up,是未来成长性最大的细分方向;
在机架内将更多芯片组合成一个“超级大脑“。这是目前带宽需求最苛刻、潜力最大的领域(约10倍带宽需求),也是CPO/NPO技术的主要战场。
即单机柜内部、甚至单节点内部的高速互连,其目标是将越来越多GPU构建为一个“统一计算单元”;
这一层级追求的是极致低时延、极致带宽以及尽可能高的GPU利用率;
典型代表是英伟达NVLink与NVSwitch体系。早期DGX系统仅支持8卡互连,而进入Hopper与Blackwell时代后,单系统GPU规模已经快速向72卡、144卡甚至更大规模演进;
以GB200 NVL72为例,其内部NVLink带宽已经达到数百TB/s级别,本质上已经不再是传统服务器,而更接近于一个“机柜级超级计算机”。
1)铜缆逐渐逼近物理极限
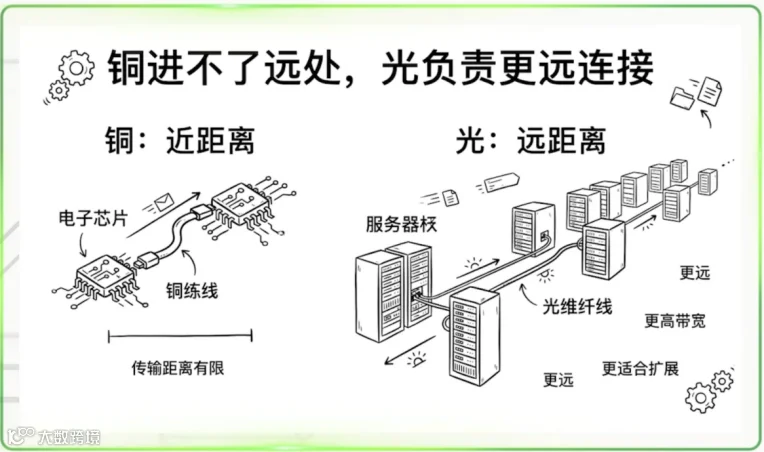
Scale Up的真正变化,并不只是GPU数量增加,而是旧有连接方式开始接近物理极限;
过去几十年,机柜内部互连主要依赖铜缆。原因很简单:距离短、成本低、延迟小;
然而随着单lane速率从56G升级至112G,再向224G演进,铜互连开始迅速暴露问题,包括高频损耗、信号完整性、PCB走线复杂度以及Retimer功耗正在指数级恶化;
尤其在AI机柜功耗已经突破100kW之后,铜缆带来的散热与布线问题,已经成为系统设计的重要约束。
这也是为什么,光开始从Scale Out向Scale Up内部渗透。
2)光互联的范式转移
过去行业普遍认为,光只适用于长距离通信,而短距离互连依然属于铜的领域;
但AI集群的超高带宽需求,正在迫使光向更短距离侵入。包括Linear Drive Optics、LPO、Near Package Optics以及CPO,本质上都在试图解决同一个问题:如何在GPU越来越密集的情况下,继续提升系统内部带宽密度,同时控制功耗与热设计。
本质上讲,光进入Scale Up,既是不得已的必然趋势,也算是光互联产业“范式转移”,因为光不再只是数据中心外围网络,而是AI计算核心区域。
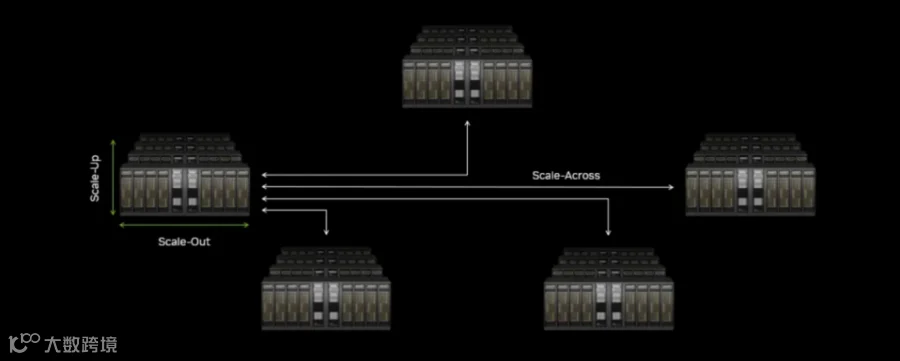
2、Scale Out 应用最成熟的区域
在万卡级别的集群中,通过几层网络连接不同的大脑。距离通常在1公里到2公里之间。
Scale Out则是当前市场最成熟的应用场景,包括我们熟知的各类可插拔光模块。
Scale Out的核心,是实现不同服务器、不同机柜乃至不同Pod之间的互连,其目标是构建大规模AI Cluster。
当前主流AI数据中心普遍采用Spine-Leaf Clos架构,通过InfiniBand或RoCE以太网实现GPU集群互连,这一层级对于网络带宽的需求已经进入爆发阶段。
以Meta、微软、谷歌等超大规模AI集群为例,其GPU规模已经从过去数千卡进入数万卡时代。一个典型万卡AI集群,其内部可能需要数万只800G光模块,以及大量51.2T交换芯片;
随着1.6T时代临近,整个Scale Out网络正在进入新一轮升级周期。
基于MoE架构、并行训练以及参数同步,会导致网络内部出现极高频率的数据洪峰,导致AI数据中心对于网络阻塞容忍度极低,也进一步推动了高速光模块、低时延交换机以及更高等级网络拓扑的持续升级。
23年以来Scale Out 快速放量,产生了“易中天们”的业绩暴增,今年是1.6T放量年,光模块头部企业会继续兑现优异的业绩。
3、Scale Across。
这是相对新的网络层级。跨数据中心互连,解决地理、供电和功耗限制,距离可达几十公里。
过去数据中心的设计逻辑,通常是一栋楼对应一个Cluster,同时对实时同步要求较低,因此跨园区通信需求有限;
随着单一AI集群规模持续扩大,未来超大规模训练系统不再局限于单一建筑,而是演变为“园区级AI Fabric”;
Meta提出“Manhattan-scale Data Center”的概念,本质上就是多个建筑、多个机房共同组成一个统一AI系统。
而一旦进入Scale Across阶段,整个网络逻辑将发生以下变化。
首先,铜彻底退出。
因为跨楼宇、跨园区通信距离已经进入数百米至数公里范围,只有光纤能够承载这种级别的高速互连。
其次,传统短距光模块也开始向相干光、DWDM以及更高等级光交换演进。
Scale Across并不仅仅意味着“距离更远”,而是AI系统开始从“单机房计算”进入“区域级计算”。
当AI数据中心从一栋楼扩展为一个园区,其内部通信复杂度将进一步指数级上升。意味着未来数据中心内部光纤数量、交换节点数量以及整体带宽需求,远超当前市场预期。
Scale Across正在将整个AI产业,从“服务器时代”推进到“超级网络时代”,未来AI竞争,表面上看是GPU竞争,实际上是互连架构竞争。
因为真正限制AI系统规模的,不是算力芯片本身,而是整个系统能否在足够低时延下,实现海量GPU之间的高效协同。

三、光进铜退之后,LPO、NPO、CPO、OCS的角逐终局
数据中心的互连升级,本质上是在解决两个问题:带宽密度与功耗密度。
过去十年,铜缆体系能够长期占据主导,核心原因在于其低成本、低时延以及成熟生态。进入112G PAM4之后,铜互连开始快速逼近物理极限。尤其224G时代到来后,PCB走线损耗、串扰、Retimer功耗以及散热问题迅速恶化;
电互连是通过不断提升SerDes速率实现带宽增长,随着频率持续提升,信号衰减呈指数级增加。为了维持信号完整性,需要引入DSP、Retimer、Equalizer等大量补偿芯片,最终导致系统功耗迅速上升;
当前AI机柜功耗已从过去20-30kW提升至100kW以上,GB200 NVL72级别系统甚至继续向150kW演进,同时互连系统成为整个机柜内部最主要的热源之一。
我们都知道,CSP异常关心运营成本,尤其在北美电力可能成为制约数据中心建设的瓶颈之一的背景下,功耗要求没有最低,只有更低。
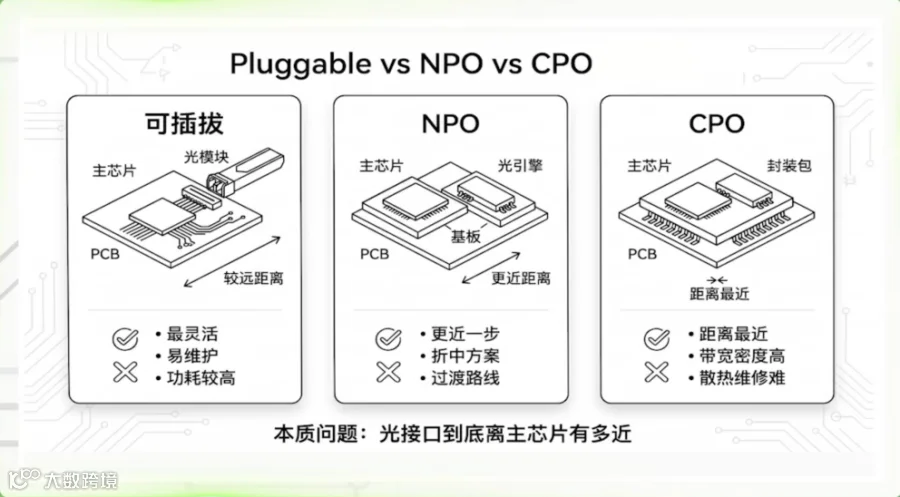
所以光进入Scale Up之后,产业端开始了多路线的角逐。目前主流路线主要包括LPO、NPO以及CPO。
目前产业端公开信息看,谷歌更优选插拔光模块方案,Meta、AWS偏爱NPO,英伟达积极推进CPO。但以上CSP未来也不排除应用其他方案,底层逻辑是每家CSP都不会宗教式专注某一种方案,而是会根据不同场景,应用最适配的方案。
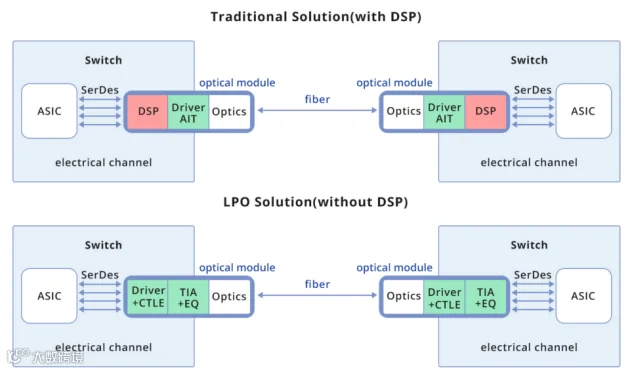
1、LPO-低功耗可插拔路线
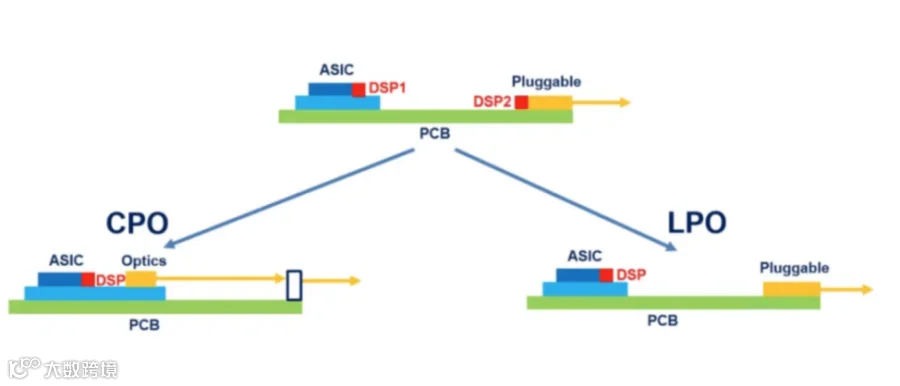
LPO(Linear Pluggable Optics)本质上仍属于传统可插拔光模块体系,但其核心变化在于“去DSP化”。
传统800G光模块内部通常集成DSP芯片,用于信号重整、误码修复与均衡补偿。DSP能够提升系统稳定性,但代价是高功耗。
800G DSP模块功耗通常达到16-20W,1.6T时代甚至可能进一步提升。
LPO路线则尝试取消DSP,仅保留线性驱动链路,将信号处理压力转移至交换芯片SerDes侧。
1)优势非常直接
第一,显著降低功耗。第二,降低模块热密度。第三,缩短系统时延。
对于AI集群而言,功耗下降不仅意味着运营成本的降低,更意味着可以在固定供电条件下部署更多GPU。
2)LPO的缺点同样明显。
由于缺少DSP补偿能力,其对于系统信号完整性要求极高,包括PCB设计、交换芯片SerDes能力、连接器质量以及整体链路长度都受到严格限制。
因此,LPO本质上更适用于“可控环境”的AI数据中心,而非复杂运营商网络。
目前LPO核心推动者包括:NVIDIA、Broadcom、Credo。国内光模块厂商如新易盛等,已布局LPO技术路线。

2、NPO:过渡阶段的重要路线
NPO(Near Package Optics)被视为介于传统可插拔与CPO之间的过渡方案。
其技术逻辑是将光引擎从交换机前面板进一步靠近ASIC封装区域,从而缩短电信号传输距离。
传统交换机内部,ASIC到前面板之间往往需要经过数十厘米PCB走线。而在112G/224G时代,长距离PCB走线会带来巨大的损耗与功耗压力。
NPO通过将光引擎靠近交换芯片,可显著降低:PCB损耗、Retimer需求、SerDes功耗,同时保留一定可维护性。这也是NPO相较CPO最大的优势。
因为在AI系统中,ASIC价值远高于光模块。如果采用完全共封装,一旦光器件失效,可能导致整个交换芯片报废,维护成本极高。
因此,NPO本质上属于一种工程折中方案。
其目标不是极致性能,而是在功耗、带宽密度与可维护性之间取得平衡。
NPO主要推动者包括中际旭创等。
3、CPO-终极形态
CPO(Co-Packaged Optics)是当前产业讨论度最高的方向,即将光引擎与交换ASIC共同封装,最大限度缩短电信号路径。

其核心价值在于:第一,极大降低高速电互连距离;第二,大幅降低系统功耗;第三,提升带宽密度;第四,支持更高等级交换容量。
当前51.2T交换芯片已经进入量产阶段,102.4T交换芯片也逐渐推进。随着交换容量继续提升,传统前面板可插拔架构将越来越难以承载。
长期来看,CPO几乎是高端AI交换机的必然方向。但CPO距离真正大规模商业化,仍存在多个关键障碍。
1)首先是散热。
AI交换芯片本身已经属于高热源,而激光器对温度极为敏感。如何在高热环境下维持光器件稳定性,是CPO最核心难点之一。
2)其次是维护。
传统可插拔模块损坏后,可以单独更换。但CPO体系下,光与电深度耦合,维护复杂度大幅提升。
3)再次是良率。
CPO属于典型异构集成体系,需要同时解决:ASIC封装、硅光、激光器、光纤耦合、热管理等,任何单点失效,都可能降低整体封装良率。
因此,现阶段产业对于CPO的态度,并非“全面替代可插拔”,而更接近于“分场景渗透”。
Broadcom和英伟达是主要推动者。同时,英伟达更多强调多技术并行,包括LPO、NPO、XPO等不同方案共同存在。
CSP更是不会“宗教式”押注某一种技术路线,而会根据不同场景动态选择,一方面CSP不想被NV垄断“黑盒”绑架,一方面也担心维护成本问题,这点商业竞争格局角度思考非常重要,因为涉及多种路线长期的“争吵”,现在看不用吵架,相当长的一段时间内,CSP的超大集群算力中心,都会是LPO、NPO、XPO、CPO等并用的格局。核心竞争力看哪家能同时具备多种成熟技术路线,全面和系统能力才是护城河。
4、OCS:AI时代的网络架构变化
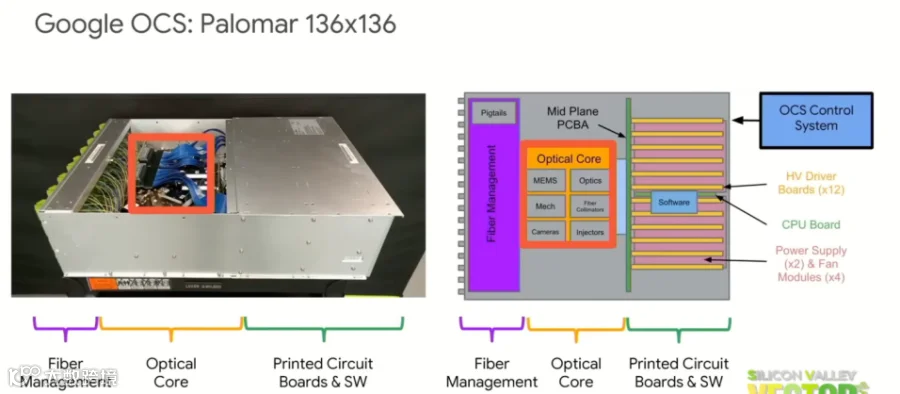
相比LPO与CPO,OCS(Optical Circuit Switch)的产业意义更大,其改变的并非单个模块,而是整个网络交换逻辑。
传统数据中心采用的是Packet Switching(包交换)架构。数据需要经过:收包、缓存、转发、排队,整个过程依赖大量电子交换芯片,因此功耗极高。
但AI训练流量与传统互联网流量存在根本差异,传统互联网流量随机性强、突发性高;而AI训练任务则高度固定,大量通信长期存在于固定GPU节点之间。
OCS的核心逻辑,就是通过光路直连方式,在节点之间建立固定高速通道,而非持续进行电子转发。
Google已在大规模使用OCS配合TPU系统。
1)其优势包括
第一,显著降低交换功耗;第二,降低网络时延;第三,提升大规模集群带宽效率;第四,降低网络阻塞。
Google早期已开始部署OCS体系。Meta、微软等厂商也在持续推进。
2)但OCS也有缺点
其最大问题在于灵活性不足。因为光路建立需要时间,更适用于长期稳定的大流量场景,而不适合随机突发流量。
因此,未来AI数据中心更可能形成:“电子交换 + 光路交换”混合架构,而不是全光OCS一统江湖,电交换路线也将长期存在。
3)应用场景的局限性
基于OCS的仅适合大象流,不适合老鼠流的技术特点,切换慢(毫秒级)、灵活性低、粒度粗等缺点,只适配长期稳定大其应用场景适配上有一定局限性;
其中Scale Across最优,Scale Out部分适用,Scale Up极难(OCS太慢、笨重、粒度太粗,无法适用柜内极细粒度的要求)。在Scale Out中,谷歌Iron、英伟达Feynman架构已采用此方案。
5、产业未来趋势——半导体化
光互连正在经历半导体化的过程。激光器生产正3英寸晶圆向 6英寸、12英寸演进,甚至探索量子点激光器在硅基上的集成。
光互连不再是“配件”,而是算力的核心组成部分。未来光互联在AI资本开支中的比重将持续增加。
四、硅光与激光器:被长期低估的“光互联心脏”
这部分很重要,涉及到光互联近几年核心产业紧缺环节——光芯片(激光器)。
过去几年,市场对于光互联的关注点,长期集中于光模块、交换机以及网络架构本身;
去年随着AI集群规模进入十万卡时代,产业开始逐渐意识到:真正制约光互联继续扩张的,可能并不是交换芯片,而是更上游的激光器与光子器件体系。
【激光器的产业地位跃迁】
过去产业认为,激光器只是光模块中的一个“器件”;但未来,激光器可能反而成为整个AI光互联体系的瓶颈之一。
本质原因在于,AI时代的光互联需求,不再是传统通信时代的“长距离低密度”,而是“短距离超高密度”。
这种变化,对激光器产业链提出了完全不同的要求。
1、AI时代,激光器第一次成为“算力基础设施”
传统光通信时代,激光器主要服务运营商网络,其特点是:数量有限、单价较高、生命周期长、更强调稳定性。
因此,激光器虽然重要,但并不属于产业瓶颈。
但AI时代不同,随着Scale Out与Scale Up同步扩张,AI数据中心内部光链路数量开始指数级增长。
一个典型万卡AI集群,可能对应数万只800G光模块;而进入1.6T时代后,单个集群所需激光器数量进一步增加。
更关键的是,未来光开始进入Scale Up。
这意味着:光不再只是机柜之间通信,而是开始进入机柜内部,进入GPU附近,进入交换芯片附近,最终进入封装内部。
于是,整个产业对于激光器的要求发生了变化。过去更看重距离。现在,更看重密度、功耗、热稳定性与成本。
所以,激光器开始从“通信器件”,转向“高密度计算器件”,同时其产业地位也随着发生根本性变化。
同时,产业地位刚变化,产业端产能准备可未不能马上随着变化,所以这几年高功率激光器产能严重不足,LITE的订单预定一空,高功率激光器紧缺短期难以缓解。

2、硅光最大的瓶颈,不是“硅”,而是“光源”
市场经常将硅光理解为:“用硅替代传统光模块”。
但实际上,硅光真正的意义,并不是“替代”,而是“半导体化”。
传统光模块由大量分立器件组成,包括:激光器、调制器、波导、探测器、耦合器。
其问题在于:封装复杂、工艺离散、难以规模化、成本随速率快速上升。
而硅光的核心逻辑,是利用CMOS工艺,将大量光器件集成到硅基平台中,本质上是把光通信做成“芯片”。
这也是为什么,Intel、Broadcom、Cisco、Marvell等厂商持续重金投入硅光。因为只有硅光,才有可能支撑未来1.6T、3.2T、CPO这种超高密度互连体系。
但问题在于:硅可以导光,却无法高效发光。换句话说:硅光最大的难点,并不是波导,而是激光器。
目前主流硅光方案,仍需要外置III-V族材料激光器,包括:InP(磷化铟)、GaAs(砷化镓),然后再通过混合集成方式,与硅光芯片耦合。
因此,未来真正决定硅光产业能力的,并不是单纯硅工艺,而是激光器能力、光源集成能力、异构封装能力。
所以推导出,未来真正卡脖子的,很可能不是交换芯片,而是激光器。
3、小尺寸激光器与大尺寸激光器
“小尺寸”和“大尺寸”激光器,本质上是在AI时代,激光器正在从“通信型器件”转向“高功率、高密度光源平台”。
过去传统光模块,多采用小尺寸EML、DML等方案。其特点是:功耗较低、单链路速率有限、面向可插拔模块。
例如:EML(Electro-absorption Modulated Laser,电吸收调制激光器)长期是高速光模块主流方案,尤其400G、800G、长距场景。
EML优势在于:高速率、长距离、色散性能较好。
缺点则是:成本高、功耗高、工艺复杂。
AI时代开始出现新的变化。随着CPO、NPO、Scale Up逐渐推进,产业开始需要更高功率、更高密度、更长寿命、更适合共封装环境的新型光源。
因此,“大尺寸激光器”本质上是在讨论未来AI系统内部,是否需要更集中式、更高功率的光源架构。
这也是当前产业正在从“每模块一个激光器”,逐渐向“集中式CW Laser”演进的重要原因。即:将激光器集中放置在系统外围,再通过光纤分发光源。
这样做的原因非常现实:第一,降低封装热压力;第二,提高激光器寿命;第三,提升系统维护性;第四,降低CPO失效率。
因此,未来AI时代的激光器产业,并不是简单“数量增加”,而是整个光源架构正在重构。
4、英伟达三笔投资背后的真实逻辑
今年以来,英伟达连续投资光互联上游,包括Lumentum(LITE)、Coherent、Corning(康宁);
这三笔投资,表面上是供应链绑定,实际上指向的是:AI时代光互联底层基础设施重构。
Lumentum与Coherent两家公司本质上都属于激光器+光器件+光子平台公司,
其中Coherent强于高端激光器与材料;Lumentum强于EML、VCSEL以及高速光器件。
英伟达同时投资两家,本质是在提前锁定未来AI光源供应能力。因为未来真正稀缺的,不是GPU,而是高端激光器产能、硅光配套能力、CPO所需光源体系。
再看康宁,市场容易低估康宁这笔投资。很多人只把康宁理解成“光纤公司”。但实际上,AI时代的光纤、连接器、光学玻璃、超低损耗材料、高密度布线的重要性正在急剧提升。
尤其Scale Across时代到来后,AI数据中心之间的光纤需求可能远超传统云计算时期。
英伟达投资康宁,本质上是在布局未来AI超级集群时代的“物理光层”;
英伟达正在把自己从GPU公司,变成AI基础设施公司,即CUDA是软件层+NVLink是互连层+Spectrum/X800是交换层+现在的物理光层。
物理光层,即在激光器、光纤、光学材料、硅光上游延伸,其目标是锁定未来AI光互联产业链核心资源。
5、未来真正竞争的是“光电融合平台能力”
当前市场对于光模块关注较多,但长期来看,产业价值可能逐渐向更上游迁移。
因为未来真正决定竞争壁垒的,不只是封装能力,而是:EML能力、CW Laser能力、硅光平台能力、III-V异构集成能力、高端封装能力。
尤其进入CPO时代后,光模块与交换芯片之间的边界开始模糊。最终产业竞争,很可能从“模块厂竞争”逐渐转向“光电融合平台竞争”。
这也是为什么,未来真正长期具备高壁垒的,未必是普通光模块,而更可能是:高端激光器、硅光平台、光芯片、异构封装。
因为AI时代,光已经不再只是“通信”,而是在逐渐成为算力系统本身。

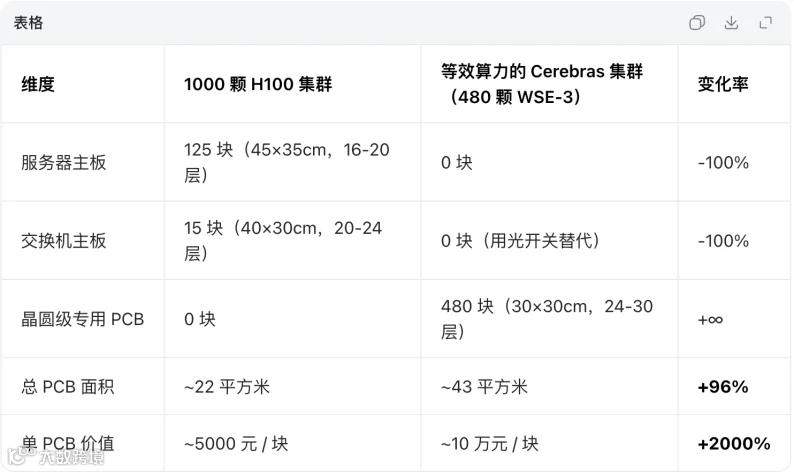
五、超大单芯片/晶圆级计算(Wafer-Scale Computing)技术的潜在影响
代表公司:Cerebras Systems
前面聊到的产业技术痛点,可插拔光模块、PCB、激光器、电芯片等之前的互联越来越复杂、越来越密集,那么怎么办?
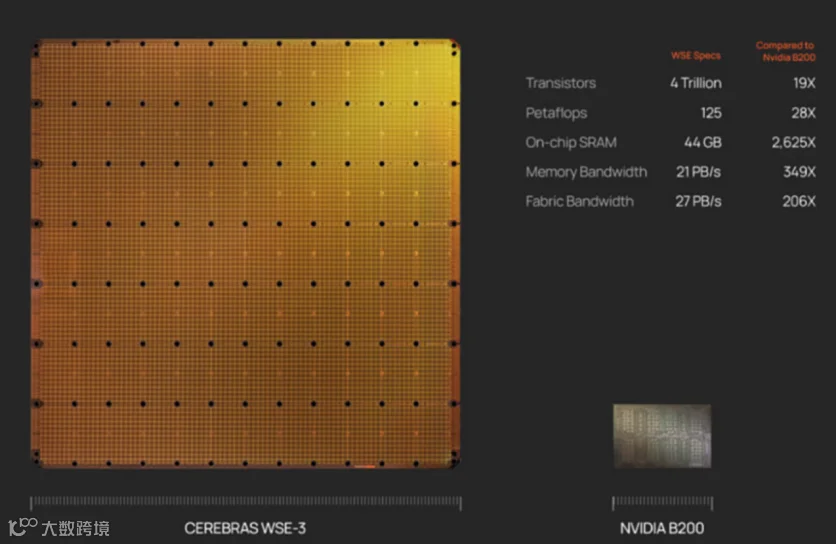
以Cerebras为代表的公司想到一个方案:把更多算力直接做进“一整块超大芯片”里,已成功推出并量产了WSE-3芯片,其晶体管数达到惊人的4万亿个;
WSE-3(峰值125 FP16 PetaFLOPS)在AI推理场景中比基于英伟达DGX B200的系统快2倍以上,有学术论文指出,其在能效比(Performance per Watt)和内存可扩展性上优于英伟达H100和B200。
1、方案优势
1)传统GPU
一块芯片大概600-800mm²,因为光刻机曝光尺寸有限,所以NVIDIA只能多GPU、多节点、NVLink、InfiniBand互连。
2)整片晶圆级芯片
WSE(Wafer Scale Engine)接近整片晶圆大小,数十倍于普通GPU面积,数十万AI Core,超大SRAM。
那么理论上,如果这种方案规模产业化落地,影响是否可能是:原本需要很多的光模块、PCB、光器件都不需要了?直接异质集成在一块超大芯片内部就OK了。
2、方案技术难点和商业化痛点
首先,我们此前分析过CPO产业化落地的技术难点,包括异质集成不成熟导致的良率低、散热问题、维护成本问题、维修成本高昂问题,还有商业模式角度考虑的,CSP们不愿为某家公司的“黑盒”买单,而只接受开放生态,比如用你的互联,但可以用自家的ASIC等。
那么在Wafer-Scale Computing上问题与CPO类似,由于技术路线的封闭化,与CUDA生态、TPU生态都不兼容,其选择的商业模式避开了与巨头在生态上的直接对抗,也是其大规模普及的最大制约。
未来随着台积电技术的成熟,NV和CSP也会将技术逐步融合到自家生态上,而不会直接颠覆现有技术路线,这不仅仅是单纯技术路线问题,是各家的商业角度思维的必然。
3、方案潜在影响细分
Wafer-Scale Computing在产业逻辑上,仅对插拔光模块和柜内短距离铜互联有较大影响,逻辑与CPO类似,因为利用了"异质键合"进行"晶圆级集成",将CPO的 "共封装" 从 "芯片级" 升级到了 "晶圆级"。
同时,对光互联的影响层级,从机架级影响,延伸到了芯片级。
同时,在固定规模上,逻辑上减少了插拔光模块使用量,但其大幅提升单芯片算力,在总规模上会大幅增加光模块需求。以Cerebras的“仙女座”集群为例,一个包含2048颗CS-3系统的集群,需要超过170公里光纤和约20,000个连接点,这需要海量高速可插拔光模块,跨机柜、跨节点的Scale Out网络对高速光模块的需求很高。
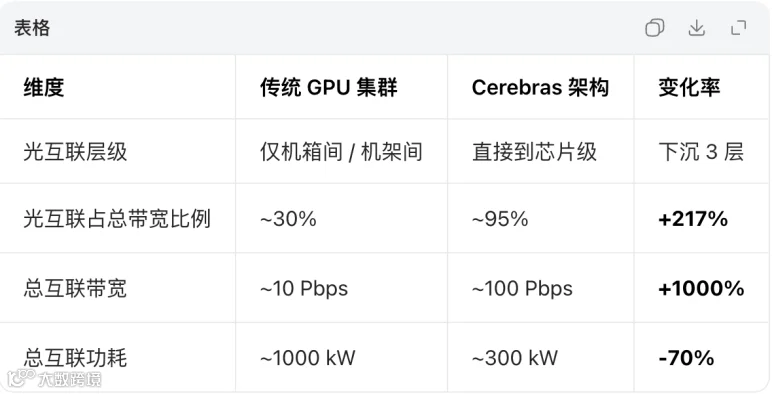
那么实际影响是,会促进Scale Up + Scale Out同时增强,单PCB价值量大幅提升,光引擎、光器件、光芯片用量及价值量均提升,因为异质键合并不是不需要了;
说到底,超大单芯片等于“局部架构大幅优化”,优化力度超过NV的CPO方案,产业预估技术成熟至少需五年以上;
如果未来某个时点落地,将大幅度提升AI算力和需求,进一步催化Scale up、out及Scale Across互联规模,导致DCI、OCS、光纤等用量继续扩大。
由于该技术路线短期不影响巨头产业格局,当下不过多阐述。

六、光互联部分重点公司巡礼
基于前文整理,代表“脑白质”的互联的成长规模尤其Scale up,引用于博士观点,将是万亿美元的产业规模,Scale up的光互联成长性是10X级,且目前刚刚开始;
由于产业端还有很多细分如激光器等,还停留在过去通讯时代的情况,导致产能、功率都严重滞后;
所以催生了英伟达的焦虑,并直接投资LITE、康宁等三家公司,来保供后续增长需求;
总结下来,未来大级别成长赛道,逻辑是【卡住AI光电融合关键瓶颈」的公司。包括:激光器、光芯片、光引擎、硅光器件、CW Laser、III-V材料、高速EML、光电封装、光纤物理层等;
所以我们看近几个月的资本市场,也主要围绕在以上提及的细分的明星公司里投资,部分的估值很高,但基于产业链地位,市场在继续为后续成长性买单;
这里依据光互联产业发展趋势,列举巡礼部分或具备“大级别平台潜力”的公司;
以下公司名单只阐述产业地位、产品结构和核心成长逻辑,仅阐述产业逻辑,不代表投资建议。
1、天孚通信
这家业绩一直MISS的公司,为什么市场持续给予120倍PE以上,因为过去插拔光模块时代,它仅是光器件公司;
在未来,天孚更类似AI光互联时代的“连接平台公司”,尤其在NV体系,早就定位为CPO产业链的核心平台公司;
研究其产品组合,包括光引擎、耦合、FA、MPO、高精密结构件、CPO配套、硅光配套等,几乎卡在所有高端光方案的中间层;
产业未来无论是LPO、CPO、硅光、Coherent、OCS等技术路线,都离不开天孚的高精密光学连接产品组合;
同时,公司另外的核心竞争力是制造能力,基于其Know-how能力在内的微米级良率、耦合工艺、自动化,所以天孚一直保持着50%+的毛利率;
结合算力未来产业趋势看,天孚具备平台级潜力,其产品结构非单一路线绑定,非客户绑定可受益多技术路线、同时公司具备工艺壁垒及全球化能力。
2、仕佳光子
笔者一季报后专门写的光子的文章,认为中期看仍具备上升潜力,具备平台级公司潜力;
光子的产品结构,卡位的是PLC、AWG、波分、光芯片、CPO等,光子国内少有的同时具备光芯片、波分底层能力的公司;
公司依托其核心产品AWG,作为波分系统中的核心器件,CW\EML激光器在小规模出货中,MPO\CPO组件也有布局等;
随着未来AI产业价值链向上游迁移,光子的逻辑更偏长期技术路线,未来逐步有潜力成长为光互联上游无源+有源光芯片、光器件的平台型公司。
3、长光华芯
长光华芯为国内少数具备外延、芯片、封装一体化能力的IDM厂商;
由于激光器本身,正在从传统通信器件,逐渐演变为AI光互联核心基础设施,所以长光其长期战略价值正在提升;
具体需跟进公司海外客户的认证进度和拓展进度,基于AI产业的技术趋势,长光有机会逐步成长为高端光源平台。
4、源杰科技
源杰也是老朋友,也是大A的明星公司;
借助旭创成功打开了北美大客户市场,CW激光器已经放量,高功率激光器正在放量;
源杰未来的潜力是高速EML,未来的AI产业要求的高速率时代,EML仍然是高速、长距、高可靠性的核心方案,尤其800G/1.6T。
未来即使硅光发展,EML也不会消失,同时未来几年EML仍然是产业主力;
源杰的估值始终不低,未来要持续跟进的是客户层级和客户拓展、高功率CW激光器和EML的放量能力,以及其全球市场份额。
5、中际旭创、新易盛
这俩简述吧,都是核心资产了。
未来AI互联公司的核心竞争力是产品要多元化,要覆盖多种技术路线,而不是单一押注某技术路线,因为CSP也不会单押,比如CSP也会同时应用可插拔、NPO、LPO、XPO多种方案一样。
旭创已经从“高弹性”进入“大市值核心资产”,核心竞争力之一是深度客户绑定;
业绩优秀、兑现能力强、自研光芯片占比高,进一步保证业绩兑现度和客户交付能力。
新易盛逻辑类似,光芯片依赖外购,导致物料紧缺问题导致业绩波动和交付波动;
依旧是AI大市值核心资产,季节性波动不改公司确定性比较高。
6、光迅科技 华工科技
光迅是国内最像“全栈光通信平台”的公司,营业结构卡位光芯片、模块、硅光、相干等都有布局;
如未来国内推动国产AI光链,它地位会继续提升,国内光互联产业龙头公司。
华工产品结构卡位光器件、激光、光模块、硅光多个方向;
国资背景下,未来会深度受益国产AI光产业链。
7、腾景科技
产品组合卡位精密光学、光学组件、硅光配套。
未来产业端随着CPO放量,腾景的精密光学器件、组件将明确受益。

七、总结综述
基于AI时代的互联要求,产业节奏上,当下仍是光互联产业的前期阶段,Scale Up、Scale Out以及Scale Across仍具有很大的产业空间,Scale Up刚刚开始;
过去通讯时代导致光器件的产业地位偏低、价值量偏低、用量稳定、升级换代不紧迫等,导致光互联公司大多为上游光器件供应商的定位;
AI时代,脑白质相对于脑灰质的落后,包括英伟达在内的巨头公司已经有紧迫感,并真金白银通过投资股权的方式进行保供,光互联的产业地位在通讯时代与AI时代是不同的,这点目前普遍产业认知仍不足;
未来具备成为“光互联平台级公司”的企业,具备较高弹性,产品组合单一的器件、组件公司,成长空间受限,能匹配AI时代大客户多种产品组合需求的平台级公司,具备较好的潜力,如天孚、旭创、仕佳、长光等,当然,北美业务占比高的,利润兑现度较好;
本文基于于让尘的产业访谈学习,重点阐述脑白质的成长逻辑和空间,系统梳理下光互联各细分、各环节的技术趋势和价值量,加深算力产业理解,进而跟踪、挖掘产业机会。
相关阅读:
「NVIDIA如何续写Scaling Laws」物理墙下的工程突围,光互联、存储、PCB、电力墙的极限降本
2026「光芯片』产业趋势:硅光加速渗透下EML/CW缺口与国产IDM企业机遇
2026「光芯片产业」趋势:硅光加速渗透下EML/CW缺口与国产IDM企业机遇
从器件配角到垂直一体化王者:天孚通信CPO时代的「价值跃迁」
「仕佳光子」从1.6T AWG到高功率CW,IDM光芯片核心企业26Q1财报跟进及进展
【鹏友圈CapitalCircle】继续欢迎科技行业、半导体行业、有色化工顺周期行业的资深投资人、产业投资人、机构研究员等人士加入鹏友圈,一起分享讨论投资机会。
申请免费,仅要求加入后,未来做一期内部产业分享或投资分享。
欢迎更多符合要求的朋友,私信或邮箱背景履历、拟分享题目,我们一起拥抱2026年更多产业及投资机遇。Email: jypcapital@163.com
「洞见AI+产业爆发点,关注❤收藏☆转发=提前布局AI机遇」
现在关注的人,未来会感谢今天的自己
「风险提示:本文企业投研结论系个人投资笔记,个人观点仅供参考,不构成投资建议。数据基于公开数据和行业及券商研究报告。市场有风险,决策需谨慎」
「版权声明:原创内容未经许可禁止转载,侵权必究。如需使用,请联系作者获取许可,并注明来源」
#光互联#AI算力#Scale up#CPO#英伟达#谷歌#天孚通信#仕佳光子#IDM#GPU