
但凡对IT领域有一些了解的人,对"7纳米"、"5纳米"、"3纳米"这些词都不陌生。几乎每一款CPU、AI算力芯片发布时,厂商都会大肆宣传自家采用3nm、5nm先进制程,给大众灌输一个固有认知:制程数字越小,芯片性能越强。
从直观上理解,"3nm"制程意味着芯片里某个零件的长度真的是3纳米,但实际上,这就是半导体行业心照不宣的数字游戏。如今标称“3纳米”的芯片里,根本找不到任何一个3纳米的尺寸信息。
今天我们就完整梳理:“几纳米” 究竟是从何时起,从精准的物理测量标尺,沦为各大厂商自定义的等效营销代号?这背后是整个芯片制造技术迭代、全球行业标准变迁、三大晶圆大厂长期博弈的完整脉络。
最初的日子:所见即所得,纳米等与真是物理尺寸
在早期的芯片制造时代(大约2011年之前),纳米数确实代表着芯片内部晶体管栅极的真实物理长度。
栅极就像是控制电流开关的“水龙头”,水龙头的脖子越短,电流通过的速度就越快,芯片的性能也就越强。
在这个阶段,数字是诚实的。例如,英特尔在2004年推出的90纳米工艺,其晶体管栅极长度就是90纳米;到了2006年的65纳米工艺,栅极长度也实打实地缩小到了65纳米。那时候,几纳米就是几纳米,没有任何水分。
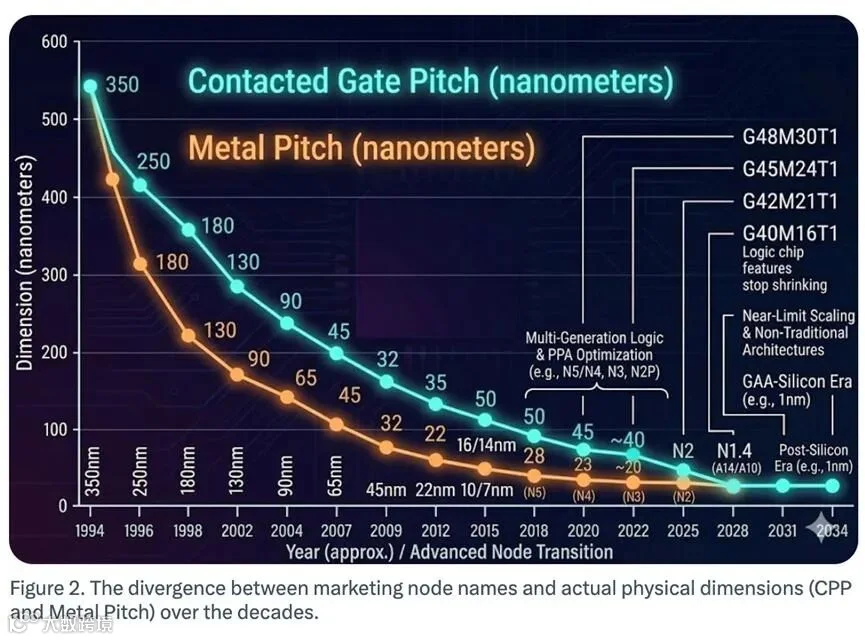
那个时代,芯片制造商按照摩尔定律的节奏,在每一代工艺制程升级的时候,差不多把栅极长度缩小到上一代的约0.7倍,从而实现晶体管密度翻倍,于是也就有了90nm→65nm→45nm→32nm这样清晰的迭代序列。
分水岭:晶体管撞上物理世界的极限,尺寸命名开始失真
芯片制程的虚标,其实远比很多人想象中的来的早的的多。
早期行业统一以栅极长度定义工艺节点,但是当工程师将栅极长度缩短到一定程度后,很快撞上了物理世界里不可逾越的墙,那就是短沟道效应。
当栅极长度来到30纳米以下的时候,差不多就到他的极限了,继续缩短栅极长度越来越难。如果强行继续缩小栅极长度,那严重的漏电将直接导致芯片功耗飙升,发热失控。
这个时候,如果制程的迭代继续用栅极尺寸来定义,似乎就很难体现出新工艺的优势了。
FinFET立体晶体管的出现,让原本的尺寸定义逐渐失去了它原本的意义。
在传统晶体管结构中,控制电流通过的闸门,只能在闸门的一侧控制电路的接通与断开,属于平面的结构。在FinFET的架构中,闸门成类似鱼鳍的叉状3D架构,可于电路的两侧控制电路的接通与断开。
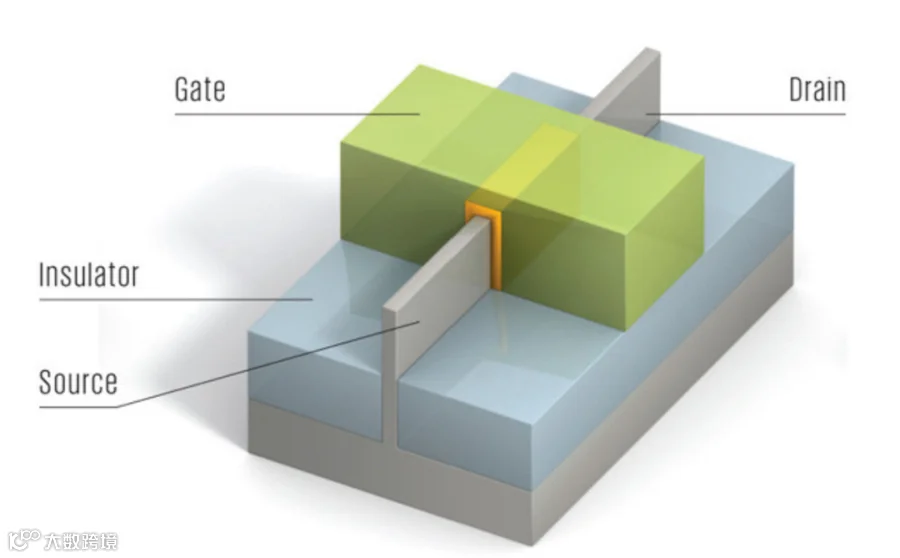
FinFET机构增大了栅极对沟道的控制面积,使得栅控能力大大增强,从而可以有效抑制短沟道效应。更强的栅控能力允许FinFET相比传统2D工艺进一步大幅缩短晶体管的栅长,从而进一步减小晶体管面积,增加单位面积内的晶体管数量。
而FinFET也让传统的单一"栅极长度"再也没办法正确衡量芯片的晶体管密度。
也就是从28纳米开始往下,几纳米就不再是芯片实际的栅极尺寸了,而是变成了单位面积内晶体管数量的等效概念。
其实工程师们无论是通过缩小晶体管、还是通过创新性的引入FinFET工艺,或者是芯片制造中的其他技术,最终目的都没有变化,那就是做到在相同尺寸的晶圆中塞进去尽可能多的晶体管,从而提升芯片的算力。
全新时代:标准瓦解,英特尔、三星、台积电自定规则
当栅极尺寸这个全行业统一标准失去参考价值后,工艺节点的定义彻底模糊,制程命名的最终解释权落到各家厂商手中。
比如相同代次的14nm\16nm制程,台积电Intel的14nm,栅极尺寸是33nm,三星的14nm,栅极尺寸是30nm,而Intel的14nm,栅极尺寸是24nm。
三家厂商对外宣称同一级别制程,但晶体管密度差距巨大,这也出现了一个名场面:Intel 10nm晶体管密度,反而超过台积电 7nm。
下图的数据可以直观佐证:台积电的7nm工艺,晶体管密度只有0.97亿个/mm²,而Intel的10nm工艺,晶体管密度达到了1.06亿个/mm²。台积电的7nm实际集成度不及Intel的10nm。
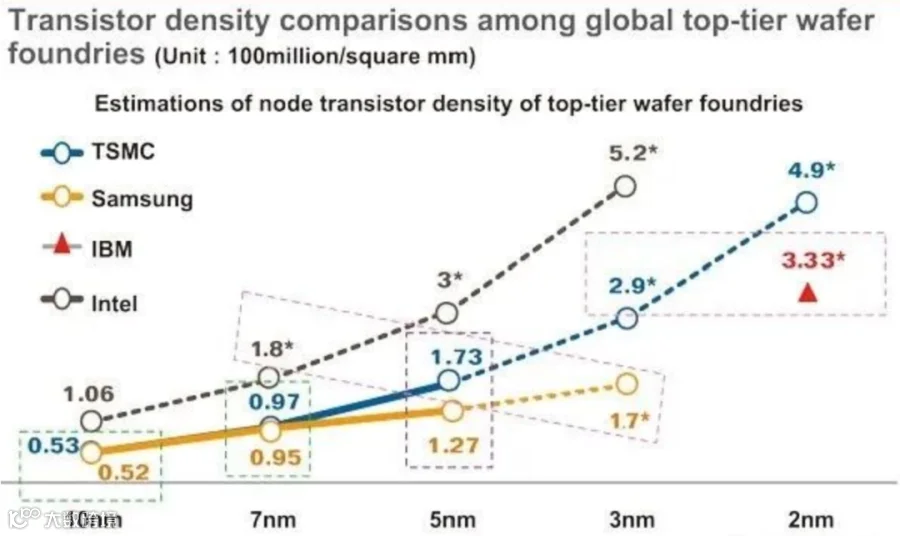
技术更先进的Intel,因为10nm和7nm的名称差异,在大众宣传层面持续处于劣势。这也逼得Intel在10nm制程以后,直接放弃了常规的工艺制程命名,而是改用了Intel7、Intel18A这种独有的制程命名方式,不陪台积电玩纳米数字内卷了。
完全代号化:迈入7nm时代,纳米沦为纯粹的营销话术
7nm往后更先进的制程工艺,是属于EUV和GAA的时代。EUV可能大家相对比较熟悉,而GAA,则是FinFET后的又一代全新工艺。
随着晶圆密度的进一步提高,上文说到的FinFET也已经被压榨到了极限,7nm、5nm制程下,FinFET还能勉强应付,但这也到达了FinFET的物理极限。
GAA全称Gate-All-Around ,是一种环绕式栅极技术晶体管,也叫做 GAAFET,可以认为是FinFET的改良版,这项技术下的晶体管结构又变了,栅极和漏极不再是鳍片的样子,而是变成了一根根 “小棍子”,垂直穿过栅极,这样栅极就能实现对源极、漏极的四面包裹。
下面两张图可以作为两种技术的简单理解,从三接触面到四接触面,并且还被拆分成好几个四接触面,显然,这次栅极对电流的控制力又进一步提高了。


上面展示的只是GAAFET的一个大致原理,实际Intel、台积电、三星的技术实现上会各有不同,总之在 GAAFET 技术的巧妙帮助下,半导体制程工艺的进化之路又可以继续往下走了。
目前三星、台积电、Intel从FinFET转向GAAFET的节奏各不相同。但无论如何,GAA的出现让“nm”这个制程概念进一步失去了意义。
在先进制程时代,“XXnm”已经沦为了纯粹的营销代号,没有任何实物尺寸可以跟这个代号能对应了。
以台积电的N3(3nm)工艺为例,其接触栅极间距是45nm,鳍片间距26nm,栅极长度是16nm,所有关键尺寸全部十几~五十纳米区间,没有任何一处物理结构实测等于3nm。
所谓3nm,仅代表这套工艺的晶体管密度、功耗性能,等效于早年平面晶体管需要做到3nm尺寸才能实现的水平,和真实测量尺寸无关。
延伸解读:关于“τ定律”
我们再来回顾下摩尔定律的概念:单片集成电路晶体管,每18~24个月数量翻倍。
摩尔定律的核心从来不是不断缩小栅极尺寸,而是单位硅片晶体管数量持续增长。过去数十年,行业依靠微缩晶体管完成这一目标,但这条路径如今已经走到瓶颈。
τ定律的核心,是依靠先进封装、芯片堆叠、系统架构优化,抵消制程限制,持续提升整机算力。
业内对τ定律的争议在于,这东西更多的是对现有理论和技术的总结,而没有提出本质的创新性技术。这也是为什么老黄说τ定律是一项突破,但不足以对台积电构成威胁。毕竟台积电在不断迭代先进制程的同时,3D堆叠、先进封装等技术也在同步提升。
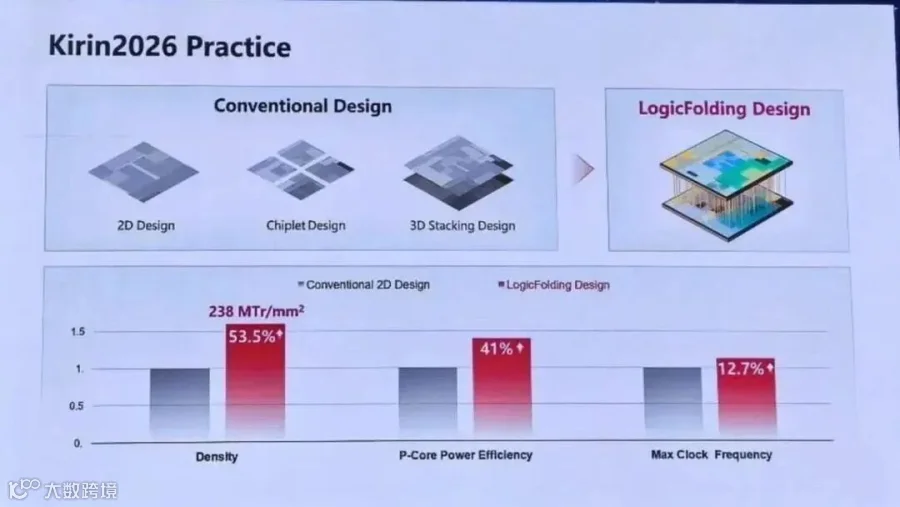
华为的价值在于,先进制程的受限会逼着华为在逻辑折叠这个方向上做一个极致的技术探索。
这个事情即使国外厂商有类似的概念和理论,他们现阶段也没有动力去做;而国内其他厂商没有这个资金和能力去做。目前看只有华为有这个实力和动力去干这个事情。
如果华为在逻辑折叠这个事情上最后实现产品化,且通过华为的工程优化把良率提上去,成本做下来,那的确是开辟出一条提升芯片单位面积算力的全新赛道。
至于逻辑折叠芯片的最终性能表现,华为宣布今年即将发布的手机芯片,晶体管密度将达到238 MTr/mm²,等效3nm。我们也不用猜,很快就能看到实测数据了。
结语
从早年栅长与标称完全对应到如今在EUV、FinFET、GAA 加持下XXnm沦为纯粹营销代号,半导体“数字游戏”的演变,本质是物理极限与商业发展相互妥协的必然结果。
半导体行业的进步从未停止,只是衡量进步的标准,早已悄悄改写。看懂这场持续数十年的制程数字游戏,我们才能跳出营销话术的误区,真正看懂芯片技术未来的发展方向。
阿里又双叒调整组织架构,频繁重构背后,阿里 AI 的突围与桎梏
全景拆解超聚变招股书:鲲鹏昇腾占比近半,核心财务、供应链与估值深度解析