
看到太多文章直接机翻好啰嗦,让我来用几句话讲清楚FA4
FA4 诞生背景 & 动机
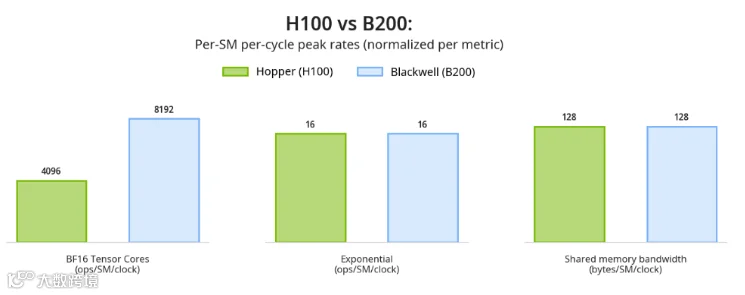
Blackwell 架构 tensor core 吞吐量相比hopper 翻倍,而shared memory bandwidth、指数运算单元MUFU等吞吐与hopper保持一致,造成瓶颈转移到这二者,所以需要重新设计Flash Attention pipeline。
FA4 的核心 idea
如最上图,基于 Blackwell 的全异步 MMA 操作和更大 tile 尺寸,设计pingpong pipeline让 tensor core 与 softmax 最大化overlap,同时通过软件模拟指数操作缓解指数计算单元MUFU的瓶颈,且充分利用 tensor memory解除MMA和epilogue在pipeline上的依赖。
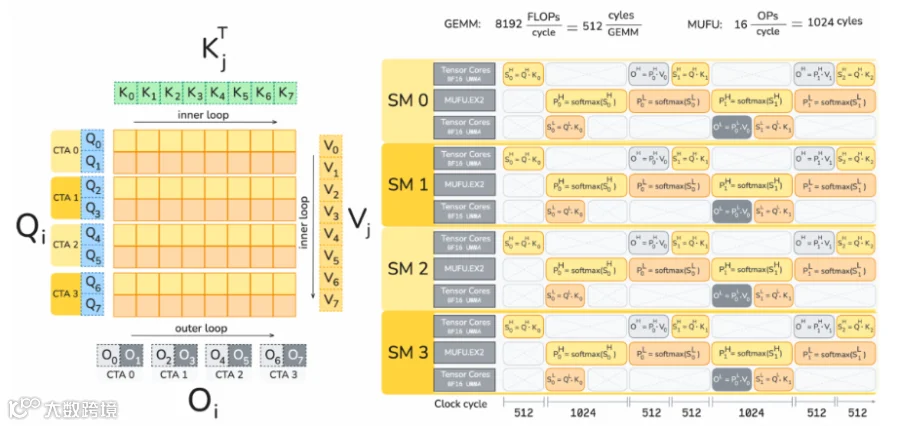
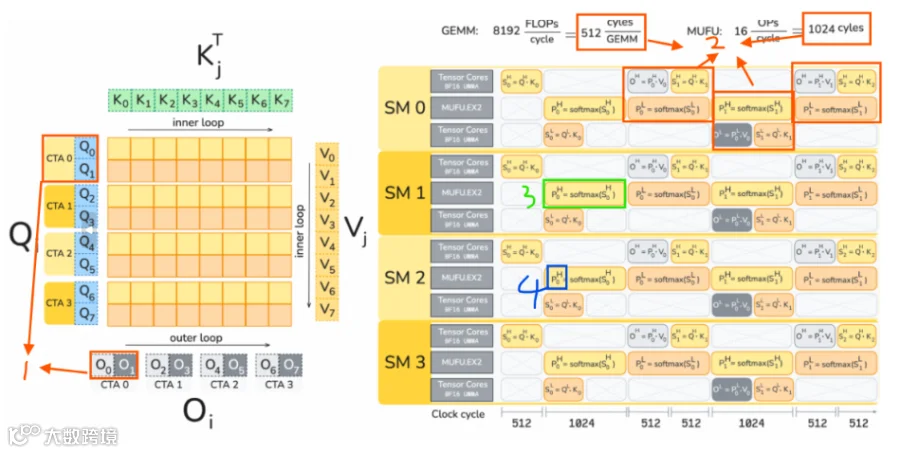
这句话里面基本包含了FA4 forward pass的所有信息,让我们对着下图来逐一拆解并理解一下FA4的核心优化地方就行,你们手里不会真的有Blackwell吧?
序号1:每个CTA own两个Q block和O block,为了基于pingpong实现tensorcore overlap softmax才这样搞的,如序号2,在对一个CTA作softmax的同时对另一个CTA作tensorcore gemm
序号2:理论上GEMM的耗时是softmax的2倍,因此用两个tensorcore mma去overlap一个softmax
序号3:提出使用多项式逼近来实现一部分softmax,另一部分依然保留用MUFU指数运算单元,旨在多一个选项加速softmax
序号4:Blackwell特有属性,用tensor memory存储gemm的accumulater,减少寄存器压力,且解除与epilogue的依赖。
最后,预测一下harness engineering时代,FA5应该完全由harness engineering完成了吧,FA4或成手搓FlashAttention为代表的融合算子的绝唱。。
过往FlashAttention相关文章,见以下
FlashAttention-V3解读之FP8/FP16/BF16关键细节实现 (下篇)
FlashAttention-V3解读之Hopper GPU版FlashAttention (上篇)
下游训练任务起飞!FlashAttention终于高性能地支持多样的attention mask!
Flash Decoding++:有些槽点的“更快的大模型推理”
FlashAttention for inference出来了,专治小batchsize大上下文长度的实时生成式推理
Flash Attention2-对1在GPU并行性和计算量上的一些小优化
Flash Attention1-真正意义上的scale dot product attention的算子融合