
关注大模型架构的同学应该能感受到,最近半年的核心内卷点,已经从“参数规模”转向了“效率革命”——如何在不牺牲模型效果的前提下,降低长序列推理的计算和显存开销,成为大厂发力的关键。
Qwen3.5 397B作为阿里达摩院推出的旗舰级大模型,就给出了一个极具参考价值的答案:将Gated DeltaNet(简称GDN)与Full Attention混合使用,既解决了传统Transformer的效率瓶颈,又守住了长序列任务的精度底线。
今天就从模型架构、核心原理、发展历程到代码实现,手把手拆解Qwen3.5的GDN设计,全程干货不bb。
一、先搞懂:Qwen3.5 397B的架构基础
在聊GDN之前,我们得先明确Qwen3.5 397B的整体架构。Qwen3.5 397B采用的是MoE(混合专家模型)+ 混合注意力的双重架构,核心参数如下(具体是参考官方config:https://huggingface.co/Qwen/Qwen3.5-27B/blob/main/config.json):
总层数:60层,其中45层(75%)采用GDN线性注意力,15层(25%)采用Full Attention(标准Softmax注意力);
混合规则:每4层为一组,前3层用GDN,第4层用Full Attention(由config中的full_attention_interval=4控制);
核心配置:隐藏层维度4096,Full Attention部分有32个注意力头(head_dim=256),GDN部分分为16个key头(linear_num_key_heads=16)和64个value头(linear_num_value_heads=64),还加入了kernel_size=4的因果卷积;
序列能力:最大上下文长度支持262144(256K),这也是GDN发挥作用的关键场景。
可能有同学会问:直接全用Full Attention或者全用GDN不行吗?为什么非要“混合”?
一句话回答:Full Attention精度高但效率低,GDN效率高但存在信息损失,混合使用能实现“效率与精度的平衡”——日常用GDN快速处理,定期用Full Attention校准关键信息,避免因信息压缩导致的误差累积。
可能又会有疑问:为什么GDN(线性注意力)能比Full Attention更高效,却会存在精度损失?这里我给大家举个具体例子简单分析一下,帮助刚接触这块的同学加深理解。
首先要明确两者的核心区别,这也是效率和精度差异的根源:Full Attention的核心是“逐一对标所有历史信息”,每一个token都要和之前所有token做交互;而Linear Attention(以GDN为代表)则是“用固定大小的状态矩阵,汇总压缩所有历史信息”,无需逐个交互。简单说,两者的计算量差距,本质就是“逐个遍历所有”和“汇总压缩后复用”的差距。
我们举一个直观的例子,帮大家理解这种差距:
假设我们有一段序列长度n=10000的文本,模型注意力头维度d=128(即Q、K、V的维度均为128):
Full Attention的计算过程与开销:
1.第一步:计算Q和K的点积,会得到一个n×n的矩阵(也就是10000×10000=100,000,000个元素);
2. 第二步:对这个n×n的矩阵做Softmax运算,得到每个token对历史token的注意力权重;
3. 第三步:用得到的权重矩阵与V(n×d)相乘,最终得到注意力输出(n×d)。
Linear Attention(以GDN为代表)的计算过程与开销:
1.第一步:计算K和V的外积(d×d),得到一个固定大小的状态矩阵S(128×128=16384个元素);
2. 第二步:用当前的Q(1×d)与状态矩阵S直接相乘,就能得到当前token的注意力输出(1×d);
3. 第三步:用新的K、V更新状态矩阵S,且仅需更新d×d的矩阵,与序列长度n无关。
综上不难看出,Full Attention的计算量会随序列长度的平方(n²)增长,而Linear Attention则随序列长度线性(n)增长,在长序列场景下,两者的效率差距会呈指数级扩大——这正是Qwen3.5引入GDN的核心原因。但凡事有利有弊,GDN是基于汇总压缩后的信息进行计算,相比拥有完整K、V缓存(可调用所有历史信息)的Full Attention,不可避免会出现一定的信息解读损失,这也是它精度略低的根源。
二、GDN的发展史:从RNN到Mamba,再到Gated DeltaNet
GDN不是凭空出现的,它是“线性注意力”发展的集大成者,而线性注意力的核心目标,就是解决“Full Attention效率低”和“传统RNN并行性差”的双重痛点。我们梳理一条清晰的发展脉络,重点讲关键节点Mamba:
1. 早期探索:从RNN到Linear Attention
最早的序列模型是RNN,它通过“状态迭代”实现长序列处理(用固定大小的隐藏状态存储历史信息),计算量线性,但存在两个致命问题:长序列记忆衰减、无法并行训练(只能逐token计算)。
为了解决并行性问题,Transformer(Full Attention)横空出世,但代价是计算量和显存开销陡增。于是研究者们开始思考:能不能结合两者的优点?——Linear Attention应运而生。
Linear Attention的核心思路:将Full Attention的“Q×Kᵀ×V”,通过矩阵结合律转化为“Q×(Kᵀ×V)”,把n×n的中间矩阵,转化为d×d的固定矩阵,从而实现线性计算量,同时保留并行训练能力。
2. 关键突破:Mamba(线性注意力的“标杆之作”)
Mamba(尤其是Mamba2)是状态空间模型(SSM),本质上是一种优化后的线性注意力,它的核心设计的是:
用“状态空间对偶性(SSD)”将线性注意力转化为RNN形式,实现“训练并行、推理高效”;
引入衰减因子α,通过Sₜ = αₜ×Sₜ₋₁ + Vₜ×Kₜᵀ的公式,让模型选择性遗忘旧信息,缓解RNN的记忆衰减问题;
采用chunkwise parallel(块并行)算法,让线性注意力能充分利用GPU的张量核心,提升训练速度。
但是Mamba的局限也很明显,它的衰减因子α是“全局统一”的——也就是说,每次更新状态时,所有历史信息都会被统一衰减,无法针对不同重要性的信息进行“精准遗忘”。比如在长文本检索中,有些关键信息(如人名、时间)需要保留,而无关信息(如语气词)需要快速遗忘,但Mamba做不到这种精细化控制,容易导致关键信息被误衰减,或无关信息累积造成噪声。
3. 集大成者:Gated DeltaNet(GDN)
GDN是由MIT和NVIDIA团队提出(论文:Gated Delta Networks: Improving Mamba2 with Delta Rule),核心思路是“融合Mamba的门控衰减和DeltaNet的精准更新”,它不是对Mamba的否定,而是在其基础上的优化升级——Qwen3.5 397B采用的,就是适配自身MoE架构的GDN变体。总体流程如下:
输入 token embedding↓[Conv1d(kernel=4)] 局部短期信息↓投影得到 Q, K, V, 门控↓GDN 递归隐状态[head_num,d,state_dim]更新:每个头维护一个 d×state_dim 的记忆矩阵↓输出 O = V 与 state 的加权融合
三、核心提升:GDN相对于Mamba,强在哪里?
GDN的核心优势,在于解决了Mamba“全局衰减”的痛点,实现了“精准记忆管理”,具体有3点关键提升,结合公式和场景讲明白(公式简化,重点看逻辑):
1. 用“门控Delta规则”替代“全局衰减”,实现精准遗忘与更新
Mamba的状态更新公式(简化版):Sₜ = αₜ×Sₜ₋₁ + Vₜ×Kₜᵀ
GDN的状态更新公式(简化版):Sₜ = αₜ×Sₜ₋₁×(I - βₜ×Kₜ×Kₜᵀ) + βₜ×Vₜ×Kₜᵀ
关键区别在于多了一个“Delta项”(I - βₜ×Kₜ×Kₜᵀ)和“更新系数βₜ”:
αₜ(衰减因子):和Mamba一样,控制整体历史信息的保留比例;
βₜ(更新系数):控制当前新信息的写入强度,同时通过(I - βₜ×Kₜ×Kₜᵀ),只对当前K对应的旧信息进行衰减,不影响其他历史信息。
举个场景例子:在处理“小明今天去北京,小红昨天去上海”这样的句子时,当模型处理到“小红”时,Mamba会统一衰减“小明去北京”的所有信息;而GDN只会衰减“小明”相关的旧信息,同时保留“北京”“今天”等无关但可能有用的信息,精准度更高。
2. 双门控机制,兼顾“记忆质量”和“输出纯度”
GDN比Mamba多了一套“输出门”,形成“遗忘门+输出门”的双门控体系,职责正交:
遗忘门(αₜ、βₜ):控制“记什么”——决定旧信息保留多少、新信息写入多少,解决Mamba全局衰减的问题;
输出门(zₜ):控制“说什么”——从状态矩阵S中,筛选出与当前query相关的信息输出,过滤无关噪声,提升输出纯度。
而Mamba没有输出门,会将状态中的所有信息不加区分地输出,容易导致信噪比低,尤其是长序列场景下,噪声累积会影响模型效果。
3. 加入短卷积,弥补线性注意力的“近视缺陷”
线性注意力(包括Mamba)有一个反直觉的缺陷:虽然能保留全局历史信息,但对“最近的几个token”反而不够敏感——因为状态矩阵是迭代更新的,最新写入的信息还没来得及充分编码,就会被新信息覆盖(类似“墨水没干就被擦掉”)。
GDN的解决方案:在线性投影之后、状态更新之前,加入一个kernel_size=4的因果卷积,专门捕捉最近3个token的局部信息,弥补“近视”缺陷。而Mamba没有这个设计,局部信息捕捉能力较弱。
因此GDN在保持线性计算量和并行训练能力的基础上,通过“精准门控更新”“双门控机制”“短卷积补充”,解决了Mamba的全局衰减、噪声累积、局部信息不足三大痛点,实现了“效率与精度的双重提升”——这也是Qwen3.5选择GDN的核心原因。
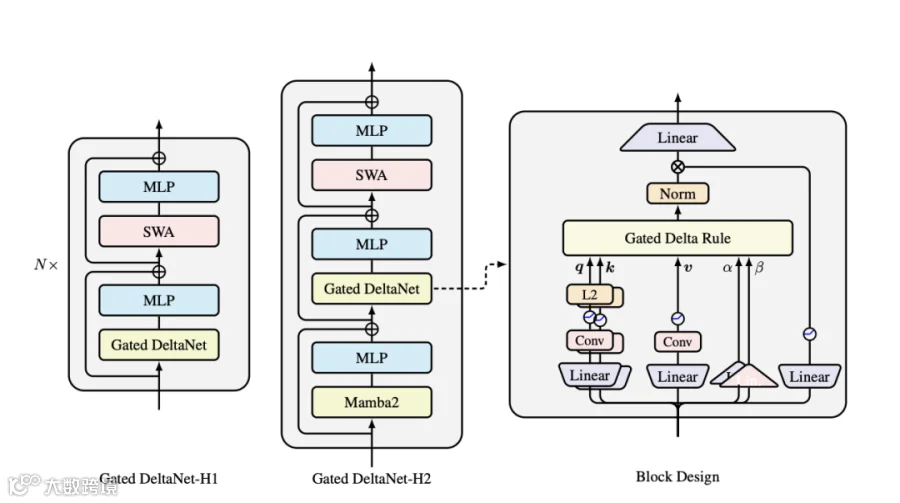
GDN结构
四、代码实现:GDN伪代码解析
需要提醒大家,这个伪代码我只列出了GDN的核心流程:线性投影 → 因果卷积 → 门控因子计算 → 状态更新(Delta规则) → 输出门调制,以及附带维度变换来方便大家理解。Qwen3.5 397B官方版本里的MoE融合、量化优化和并行计算我就先省略不提
class Qwen35GDN: def __init__(self, num_key_heads, num_value_heads, key_head_dim, value_head_dim, conv_kernel_size): self.num_key_heads = num_key_heads self.num_value_heads = num_value_heads self.key_head_dim = key_head_dim self.value_head_dim = value_head_dim # 1. 线性投影层(Q、K、V、门控因子) self.proj_q = torch.nn.Linear(4096, num_key_heads * key_head_dim) self.proj_k = torch.nn.Linear(4096, num_key_heads * key_head_dim) self.proj_v = torch.nn.Linear(4096, num_value_heads * value_head_dim) self.proj_alpha = torch.nn.Linear(4096, num_key_heads) # 衰减因子α(per-head) self.proj_beta = torch.nn.Linear(4096, num_key_heads) # 更新系数β(per-head) self.proj_z = torch.nn.Linear(4096, 4096) # 输出门z # 2. 因果卷积(弥补局部信息缺陷) self.conv = torch.nn.Conv1d( in_channels=num_key_heads * key_head_dim, out_channels=num_key_heads * key_head_dim, kernel_size=conv_kernel_size, padding=conv_kernel_size - 1, groups=num_key_heads, bias=False ) self.conv_mask = torch.tril(torch.ones(conv_kernel_size, conv_kernel_size)).view(1, 1, conv_kernel_size, conv_kernel_size) # 3. 初始化状态矩阵S(固定大小,与序列长度无关) self.state = torch.zeros( 1, num_value_heads, value_head_dim, num_key_heads * key_head_dim, device="cuda", dtype=torch.bfloat16 ) def forward(self, x): batch_size, seq_len, hidden_size = x.shape # 步骤1:线性投影 + 因果卷积(处理K、Q,补充局部信息) q = self.proj_q(x).view(batch_size, seq_len, self.num_key_heads, self.key_head_dim).transpose(1, 2) k = self.proj_k(x).view(batch_size, seq_len, self.num_key_heads, self.key_head_dim).transpose(1, 2) v = self.proj_v(x).view(batch_size, seq_len, self.num_value_heads, self.value_head_dim).transpose(1, 2) # 因果卷积应用于K(维度调整:[batch, heads, seq_len, dim] → [batch, heads*dim, seq_len]) k_conv = self.conv(k.transpose(2, 3).reshape(batch_size, -1, seq_len)) k_conv = k_conv.reshape(batch_size, self.num_key_heads, self.key_head_dim, seq_len).transpose(2, 3) # 应用因果掩码,确保只关注当前及之前的token k_conv = torch.nn.functional.conv2d(k_conv, self.conv_mask, padding=(self.conv_kernel_size-1, 0))[:,:,:,:seq_len] # 步骤2:计算门控因子(α:衰减,β:更新,z:输出门) alpha = torch.sigmoid(self.proj_alpha(x)).view(batch_size, seq_len, self.num_key_heads, 1) beta = torch.sigmoid(self.proj_beta(x)).view(batch_size, seq_len, self.num_key_heads, 1) z = torch.sigmoid(self.proj_z(x)) # 输出门,逐元素调制 # 步骤3:GDN核心状态更新(Delta规则 + 门控衰减) output = [] for t in range(seq_len): # 当前时间步的K、V、α、β k_t = k_conv[:, :, t, :].unsqueeze(-1) # [batch, key_heads, key_dim, 1] v_t = v[:, :, t, :].unsqueeze(-1) # [batch, value_heads, value_dim, 1] alpha_t = alpha[:, t, :, :].unsqueeze(1) # [batch, 1, key_heads, 1] beta_t = beta[:, t, :, :].unsqueeze(1) # [batch, 1, key_heads, 1] # 状态更新:S_t = α_t * S_{t-1} * (I - β_t * k_t * k_t^T) + β_t * v_t * k_t^T I = torch.eye(self.key_head_dim, device=x.device).unsqueeze(0).unsqueeze(0) delta_term = I - beta_t * torch.matmul(k_t, k_t.transpose(-1, -2)) self.state = alpha_t * torch.matmul(self.state, delta_term) + beta_t * torch.matmul(v_t, k_t.transpose(-1, -2)) # 步骤4:读出当前输出(Q_t × S_t) q_t = q[:, :, t, :].unsqueeze(-1).transpose(-1, -2) # [batch, key_heads, 1, key_dim] attn_out_t = torch.matmul(q_t, self.state.transpose(-1, -2)).squeeze(-2) # [batch, value_heads, value_dim] output.append(attn_out_t) # 步骤5:输出门调制 + 维度恢复 output = torch.stack(output, dim=2) # [batch, value_heads, seq_len, value_dim] output = output.view(batch_size, seq_len, -1) # 拼接所有value头 output = output * z # 输出门过滤噪声 return output, self.state
五、总结:Qwen3.5 GDN的核心价值与未来趋势
Qwen3.5 397B采用GDN与Full Attention混用,核心是平衡效率与精度——Full Attention兜底精度,GDN提升长序列处理效率。对开发者而言,其核心启示是大模型竞争已转向架构效率优化,这也是下一步众多大模型厂商所要厮杀的战场!
觉得有用的话,希望大家点赞收藏,关注我,持续提供大模型相关干货~
建了一个仓库链接供学习vLLM/SGLang/CutedDSL:https://github.com/RussWong/vLLM_SGLang_cuteDSL_tutorial,欢迎clone并点个⭐