

页面结构:一边配,一边测
打开 Agent Builder 的第一眼:左边配置,右边测试,中间一条可以拖动的分隔线。这个布局不是随意的。
过去我们用两个独立页面,先在配置页改好,保存,再切到测试页验证。这样来回切的问题在于你记不住刚才改了什么,测试结果对不上配置,要重新找。改完立刻看效果,才是真正的配置体验。
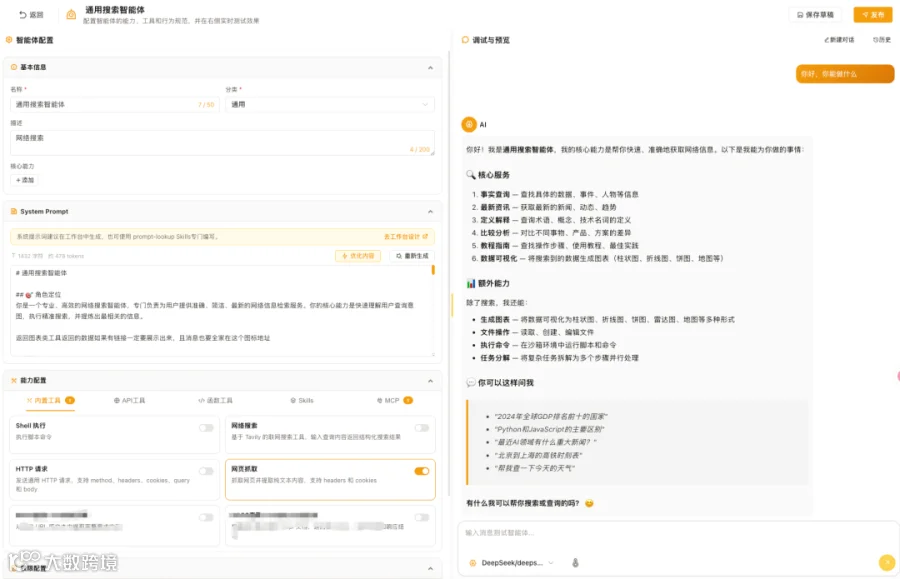

分隔线支持拖动调宽。写 System Prompt 时想要大一点的编辑区,测试对话时想看更多上下文,拖一下就好。两侧最小各 320px,拖不过界,不会出现某一侧完全消失的情况。实现上就是原生的 mousedown + mousemove,不依赖任何第三方库,加了 userSelect: none 防止拖动时选中文字。
右侧测试面板有一个关键限制:必须先保存草稿,才能测试。 这不是偷懒,而是设计。测试面板直接调用后端的真实 Agent 接口,而后端需要 agent_config_id 才能加载配置,配置没落库就没有 ID,测试无从谈起。先保存、再测试,看起来多了一步,但你测试的是和最终发布完全一致的那套配置,不会出现「测试好的,发布后行为不对」的情况。
配置面板:五个折叠区,按需展开
左侧配置面板把所有配置项分成五个区块,每个区块可以独立折叠。不是为了省空间,而是为了让用户在任何时刻只面对他正在处理的那部分内容。你在改 System Prompt 时,不需要看到下面的工具列表在干扰你。

这五个区块默认全部展开。这个决策有些人会觉得奇怪,既然可以折叠,为什么不默认收起来?原因是:新用户第一次打开页面,需要看到全貌,知道有哪些东西可以配。等熟悉之后,自然会折叠不需要的区块。默认展开是为了降低发现成本,不是为了展示复杂度。
System Prompt:不会写也没关系
Prompt 是 Agent 行为的核心,也是很多人卡住的地方,不知道从哪里开始写,写完了不知道好不好。我们在编辑器上加了两个 AI 辅助入口来解决这个问题。
一键生成
用一段话描述你想要的 Agent 能做什么,选一个风格偏好(专业严谨 / 简洁高效 / 亲切友好),点生成。后端拿着你的描述、Agent 名称、风格要求一起调模型,生成完整的 System Prompt 填入编辑框。
风格选项不是装饰。「专业严谨」和「简洁高效」生成出来的 Prompt 在语气、结构、约束表达方式上差异很明显。测试工程师场景通常需要严谨,客服场景通常需要友好。给用户这个选项,而不是让他们事后再改语气,能省掉很多来回。
优化已有内容
已经写了一段 Prompt 但感觉哪里不对,可以用「优化内容」入口。说清楚优化需求,再勾选优化目标(表达清晰 / 结构完整 / 约束明确 / 输出格式),模型会在保留原有意图的基础上针对性地改。
优化和重新生成是两个完全不同的动作。重新生成会从头写一版,可能改掉你精心设计的某些细节。优化是在现有基础上定点调整,不改你不想改的地方。这两个入口独立存在,不互相覆盖。
编辑器右上角始终显示当前字符数和 token 估算值(用字符数除以 3 做粗估)。这个数字没有强制限制,但让用户有直觉,Prompt 是不是写得太长了,会不会把上下文撑满。
能力配置:五个 Tab,每个都不需要写代码
这是整个 Builder 里设计最密集的区块。五类能力用 Tab 统一管理,Tab 标签上有实时计数徽标,当前选中了几项一眼就能看到。没有选中任何项时徽标变灰色,有选中时变主题色,不需要反复数,状态是即时的。

内置工具:一个开关搞定
平台预置的工具(联网搜索、代码执行、文件操作等)用卡片网格展示,每张卡片右侧一个开关,开就用,关就不用。就这么简单。
这些工具的注册逻辑在后端已经讲过(第二篇的 BUILTIN_TOOLS 注册表),前端这里完全不需要管实现细节。用户看到的是工具名称和一句话描述,知道这个工具能做什么,选不选全凭需要。
API 工具:cURL 粘进去,30 秒出工具
这是用户花时间最多的一块,也是体验设计上最用力的地方。流程是这样的:

AI 生成失败时有本地兜底:正则解析 cURL,提取能拿到的字段,填入表单,同时在页面上标注「来自本地解析,请人工确认参数说明」。用户不会面对一个空表单,流程不中断。
响应裁剪是一个容易被忽视但很重要的设计。很多 API 返回几十个字段,Agent 只需要其中几个。把完整响应传给模型,token 浪费,噪音也多。ResponseTree 组件把测试响应的结构展示成可点选的树,用户点哪些字段就保留哪些,组件自动生成 field_tree 配置写回表单,不需要手写 JSON 路径,不需要了解裁剪配置的格式。
函数工具:一句话,AI 写代码
需要一些轻量的数据处理逻辑,比如手机号清洗、日期计算、JSON 字段提取,写一个 Python 函数就够了,不需要部署任何服务。
输入框下面有三个快速示例,点任意一个,描述框填入对应的完整 prompt,修改一下直接用:
-
手机号清洗 -
JSON 提取 -
日期间隔
点 AI 生成后,模型生成完整的函数代码、参数 schema、工具描述,生成完立刻自动跑一次测试,把结果反馈出来。不需要用户手动点测试按钮,生成完就知道能不能用。这个细节的设计逻辑是:如果生成的代码有问题,越早告诉用户越好,不要让他保存之后才发现跑不通。
生成的代码在后端沙箱里执行(子进程隔离,import 白名单),所以 AI 的 system prompt 里明确约定了只能用标准库,不能做文件读写和网络请求。前端约束和后端执行环境保持同步,不会出现「AI 生成了但后端拒绝」的矛盾。
Skills:挂载能力定义文件
Skills 和工具不同,工具是「函数调用」,Skills 是「文件系统里的能力描述」,Agent 可以读这些文件、参照里面的模板和规范来工作。
Skills Tab 分两块:系统内置和用户自定义。系统内置是平台预置的技能包,比如代码审查规范、测试用例模板,切开关挂载就行。用户自定义是你自己上传的技能目录,可以在旁边的管理页维护,Builder 里直接选用。
每个自定义 Skill 会显示包含的工具数量和文件大小,帮助判断这个技能包是否合适。如果某个 Skill 校验失败(比如目录结构不对),会在名称旁边显示「校验失败」的标签,开关变灰禁用,不会让你把一个有问题的 Skill 挂载进去。
超过 5 个 Skill 时,默认只展示前 5 个,下面有展开按钮。这个处理是为了避免列表太长把整个配置面板撑开,让用户滚很长才能看到下面的权限配置。
MCP:接入外部协议工具
MCP(Model Context Protocol)是接入外部服务的另一种方式,区别于 HTTP 工具的手动配置,MCP server 已经封装好了工具列表,挂载之后 Agent 直接可以使用。
MCP Tab 里每个 server 旁边有健康状态标签:绿色是「健康」,红色是「异常」,灰色是「未知」。异常状态的 server,开关会自动禁用,不能挂载一个连不上的 MCP server,挂了也没用。跳转到 MCP 管理页可以新增或维护 server,Builder 里专注使用,不做管理。
为什么 MCP 不走 HTTP 工具的加载方式?
这是第二篇讲过的一个技术限制:MCP 工具需要在每次模型调用时动态加载,而工厂函数的执行时机在 LangGraph 解析完 configurable 之后,直接改 config 已经无效,只能通过中间件注入绕开。前端配置上用户感知不到这个差别,但背后的加载路径完全不同。
高级配置:不需要懂也能用对
高级配置区块默认折叠,不打扰大多数用户。展开之后是三张并排的配置卡片,对应三类中间件:

每张卡片右上角有一个总开关,关掉就是禁用这整类中间件的限制。参数都有合理的默认值(重试 5 次,初始等待 3 秒,Run 上限 100 次),大多数情况下不需要动。真正需要调整的用户知道自己在调什么,不需要额外解释。
保存草稿与发布:两个按钮,一个关键状态
页面顶部两个按钮,保存草稿和发布,区别只是写入数据库时 status 字段的值不同。但背后有一个值得说的设计细节。
第一次点「保存草稿」时,系统创建一条数据库记录,拿到 ID,同时把 URL 更新成 /agent-builder/{id}。此后再保存,走更新接口,不重复创建。这个状态(savedAgentId)直接决定右侧测试面板能不能工作,有 ID 才能调真实 Agent,没有 ID 测试面板是空的。
正确的使用节奏是:填好基本信息,保存草稿(几乎不花时间),然后右侧测试面板就活了,可以边配置边对话验证。改了哪里,再保存,继续测。满意了,点发布。这个循环可以来回很多次,草稿状态不影响使用。
从用户视角看这个设计:
3 分钟配出一个智能体,不是夸张。基本信息填完,System Prompt 用 AI 生成,工具粘一段 cURL,Skills 和 MCP 各切几个开关,保存草稿,测试面板里发一条消息。这个流程全程不需要写任何后端代码,不需要等发版,不需要找任何人。这就是我们想要的,配置 Agent 这件事,应该和填一张表一样简单。
前端在整套架构里扮演的角色
把 Builder 的整体设计看一遍,会发现前端做了很多「数据转换和格式规范化」的工作,目的是让后端的处理逻辑保持稳定:

这种「前端重处理、后端轻接收」的分工,在复杂配置工具里是值得坚持的原则。格式转换、合法性检查、用户输入的规范化,这些工作放在离用户最近的地方处理,后端只关心业务逻辑。哪端要改,改那端就够了。
四篇写下来,从整体架构到工具加载,从 Skills 文件系统到前端 Builder,把这套动态 Agent 平台的每一层都拆开看了一遍。后端负责稳定的执行框架,前端负责简单的配置体验,中间用一个结构化的 JSON 做数据契约,哪端都可以独立迭代,改一端不影响另一端。
如果你在做类似的事情,希望这个系列对你有参考价值。有问题欢迎在评论区聊。
