
嗨!这里是 Research AI+ 的「社区来稿」栏目。
我们想把这里打造成一个有温度又有 taste的地方——在这里,AI 以及 AI4S、AI4E 领域的同路人们可以发现彼此的“好东西”——不管是你刚中的顶会论文、踩过的坑换来的技术 Blog、还是那个效果惊艳的开源项目或者产品Demo,都可以分享出来,让更多志同道合的小伙伴发现你、链接你、甚至促成下一次合作。我们相信,每一次研究和技术创新都值得被更多人看见。
让 RL 不再"鼓励一切",而是学会判断「何时该画辅助线」。
近两年,基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Reward, RLVR)已经把大模型的数学推理推到了一个前所未有的高度。从 DeepSeek-R1-Zero 的横空出世,到 GRPO 在数学求解、代码生成、SQL 推断、工具调用等场景中的全面铺开,RL 几乎成了"激发模型推理能力"的标准答案。
然而,当社区把目光从纯文本数学转向几何这一更接近「人类直觉推理」的子问题时,事情变得不那么乐观——
几何题不像代数题那样可以一路演算到底。一道复杂的几何题往往绕不开"画辅助线"这一关键动作:要在图中补一条平行线、连一条对角线、作一个等腰三角形,才能把藏在图形里的角度关系、相似关系、对称关系撬出来。这不是一个"算更准"的问题,而是一个“何时该出手、何时不该出手”的判断问题。
现有路线大致有两种:要么像 Visual Sketchpad 一样依赖 GPT-4o、Gemini 这种动辄千亿参数的闭源大模型来"硬解",部署成本高昂;要么把 GRPO 直接套到中小模型的几何推理上,通过添加「使用工具就给奖励」的方式,让模型机械地、无条件地往答案里塞辅助线——结果往往是:该画的没画好,不该画的反而画了一堆,引入了大量冗余甚至错误。
研究团队意识到,这背后藏着一个长期被忽视的根本问题:
RL 目标里的奖励,到底应该是无条件的,还是有条件的?
针对这一问题,复旦大学、上海创智学院、上海人工智能实验室、浙江大学、南洋理工大学的联合研究团队从奖励机制本身出发,提出了 Group Contrastive Policy Optimization(GCPO,组对比策略优化)——一种用"组间对比"来量化辅助线收益、再据此动态发奖的新型 RL 框架。基于 GCPO,他们训练出了一系列轻量级(1.5B–7B)几何推理模型 GeometryZero,在 Geometry3K、Geomverse、MathVista、OlympiadBench 四大基准上全面超越 GRPO、ToRL 等 RL 基线。
论文 arXiv:https://arxiv.org/abs/2506.07160
代码与权重:https://github.com/ekonwang/GeometryZero

一、问题的核心:教会模型"怎么画",更要教它"什么时候画"
要理解 GCPO 的动机,先要理解为什么 GRPO 在几何上"水土不服"。
GRPO 通过对一组 rollouts 计算可验证奖励(accuracy reward + format reward),再用组内均值/方差归一化得到 advantage,从而在没有 critic 的情况下完成策略更新。这套思路在数学题上极其干净——答案对就奖励,答案错就惩罚,模型自然学会更靠谱的解题路径。
但在几何里,"是否调用辅助线(auxiliary construction)"是一个独立于"答案是否正确"的额外行为维度。最近的 ToRL 类工作借鉴了"工具使用奖励"的思路,给模型加了一个 R_aux:只要在思考过程中调用了 TikZ/Python 画辅助线、并能成功渲染,就给正向奖励。
问题在于:
这种奖励是无条件的(unconditional reward)。 不管这一题"画辅助线"到底有没有用,只要模型画了,就一律加分。
研究团队发现,这种"鼓励一切"的范式会带来明显的副作用:
简单的、本可以直接推理出来的题,模型会被诱导去画一堆冗余甚至误导性的辅助线;
复杂题里,由于"画就行"已经可以拿奖励,模型缺乏动力去判断不同辅助构造之间的优劣;
最终在 OOD 几何基准(如 MathVista、OlympiadBench)上,ToRL 相对 GRPO 的优势被吞没甚至反超。
这就引出了 GeometryZero 团队提出的核心命题:
辅助线不是"该不该用工具"的问题,而是"在这个具体场景下,用了工具到底有没有让答案更准"的问题。
要回答这个问题,不能再用"无条件奖励",必须设计一种条件性、量化的奖励信号。
二、GCPO:用「组对比」量化辅助线的真实收益
GCPO 的关键洞察十分朴素,但落到 RL 框架里却带来了截然不同的训练信号:
想知道"画辅助线是否有用",最直接的办法就是让模型分别在"画"和"不画"两种条件下各试一遍,再比答对率。
具体来说,GCPO 在 GRPO 的基础上扩展为三组 rollouts(如下图所示):
O:自由 rollout 组(模型自主决定是否画辅助线,用于真正的策略更新);
O^w:强制画辅助线的 rollout 组;
O^wo:禁止画辅助线的 rollout 组。
随后通过下面的 Group Contrastive Masking 函数为辅助线奖励 R_aux 决定方向:
直观理解:
如果"画了辅助线的那一组"答对率显著高于"没画的那一组"——说明这道题确实需要辅助线——那么对自由组里画了辅助线的样本给 正向奖励;
反过来,如果"不画的那一组"反而答得更好——说明这题根本不需要辅助构造,硬画反而碍事——则反向惩罚画了辅助线的样本;
当两组准确率相差不超过阈值 ε(实验中取 0.05),说明"画不画都差不多",此时直接置零,避免噪声信号扰乱训练。
这一机制把"是否使用工具"从一个模型无法自我反馈的盲目行为,转化为一个由真实准确率差驱动的条件性信号——本质上,是用"组间对照实验"取代了"经验先验"。
除了组对比掩码,GCPO 还引入了一个长度奖励(Length Reward):
辅助线推理本身需要更长的链路——既要解释为什么画、画在哪,又要在新构造上继续推理。借鉴 LCPO 的思路,研究者用一个简单的长度奖励鼓励模型生成更深入、更多维的推理过程,避免 RL 把链路压得过短。
最终,GCPO 的可验证奖励组合为:
其中 λ 与 β 均设为 0.5,整套框架完全继承 GRPO 的 outcome-based 训练管线,无需额外 critic、无需偏好数据。
三、实验结果:跨尺度、跨域、跨模态的一致提升
研究团队基于 Qwen2.5-1.5B/3B/7B-Instruct 训练了三个尺度的 GeometryZero,并在 4 个基准上与 SFT、GRPO、ToRL 进行了系统比较:
In-domain:Geomverse、Geometry3K
Out-of-distribution:MathVista、OlympiadBench
主表(BoN@3,平均准确率):
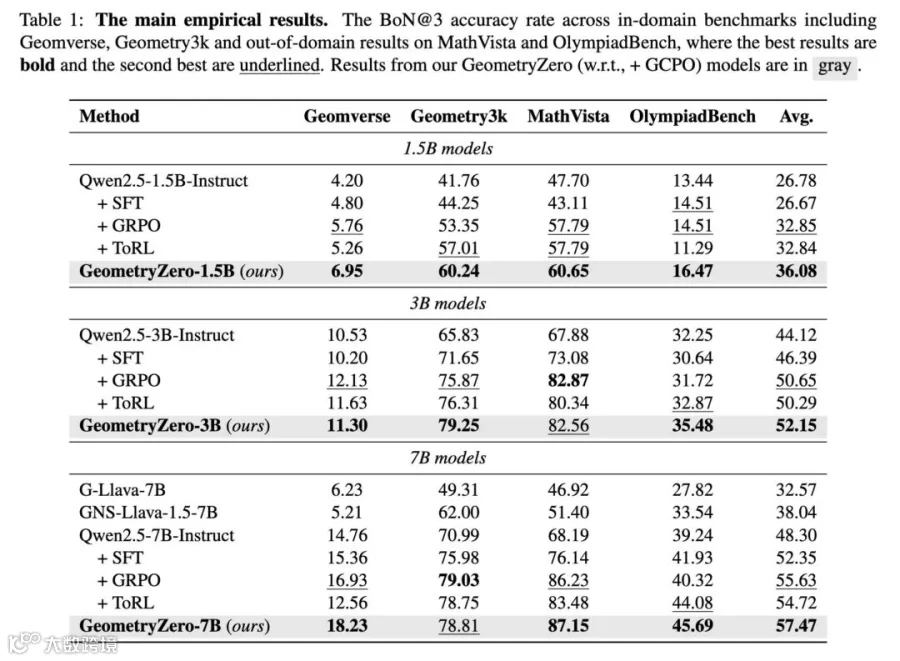
几个值得注意的现象:
1. SFT 记忆,RL 泛化
SFT 在 in-domain 基准(Geomverse、Geometry3K)上能稳定提升,但在 OOD 上常常出现倒退(如 1.5B-SFT 在 MathVista 上比 base 反而下降 4.59%)。RL 类方法(GRPO/ToRL/GCPO)则在 in/out-of-domain 上都更稳定地拉升——RL 学到的是策略,而不是答案分布。
2. 无条件鼓励工具调用,并不一定优于"什么都不做"
ToRL 在 3B 上仅比 GRPO 高 0.64%,到 7B 反而比 GRPO 低 0.91%。这恰好印证了团队的判断:粗粒度的"调用即奖励"无法稳定带来收益,反而可能稀释模型本来就有的能力。
3. GCPO 在三个尺度上一致超越 RL 基线
1.5B → +3.23 avg、3B → +1.50 avg、7B → +1.84 avg(相比当尺度最强 RL 基线)。在 OOD 的 OlympiadBench 上,7B 模型从 GRPO 的 40.32 直接拉到 45.69,提升幅度尤为显著。
4. 推广到视觉-语言模型同样成立
研究者把 GCPO 套到 Qwen2.5-VL-7B-Instruct 上(让模型生成的辅助线渲染回图像,再喂给 VL 模型"看"):
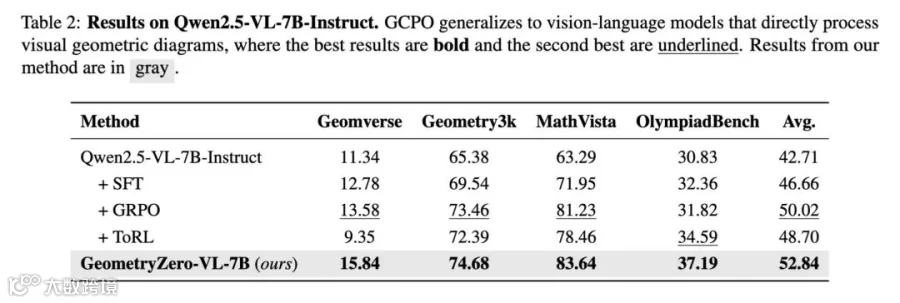
有意思的是,纯文本的 GeometryZero-7B(57.47)依然显著高于 VL 版本(52.84)——研究者认为,这暗示当几何上下文已经被形式语言完整描述时,纯文本空间的推理反而比多模态推理更精确、更不易被歧义干扰,这是一个值得继续深挖的方向。
四、消融与训练动力学:每一块拼图都不可或缺
研究者在 7B 模型上做了完整的组件消融(AR = 辅助奖励,GC = 组对比掩码,LR = 长度奖励):
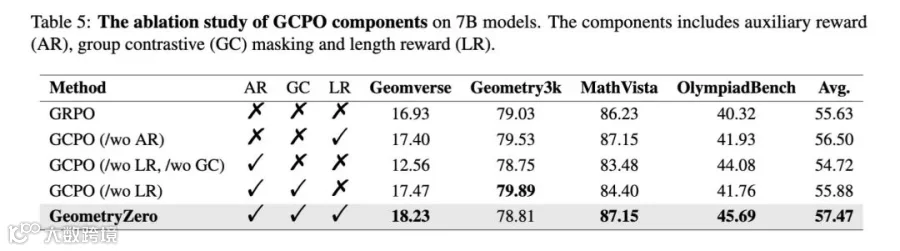
可以看到:单独加辅助奖励(即 ToRL)反而拖累了平均分;只有当组对比掩码把无条件奖励改造成条件性信号、再叠加长度奖励之后,性能才被真正打开。三件套缺一不可,缺任何一件都会回落到接近 GRPO 的水平。
在训练动力学层面,GCPO 还展现出一个有趣的"涨—跌—再涨"完成长度曲线:
第一阶段:模型为了拿到 format reward,迅速学会"先思考再作答",输出长度快速上升;
第二阶段:模型转而优化 accuracy reward,砍掉冗余、压缩链路,输出长度回落;
第三阶段:在长度奖励的牵引下,模型学会更复杂、更深入的推理结构,输出长度再次抬升。
值得注意的是,1.5B 模型只走完了前两阶段——它没有第三阶段的"再上扬"。研究者认为这是参数量不足以支撑更深层推理模式的体现,也提示了未来几何推理小模型的能力边界所在。
五、为什么这件事重要:从「奖励工程」回到「奖励本质」
GeometryZero 的真正价值,并不只是在几何题上多刷出 1–2 个点。它真正回答的是RLVR 范式中一个被长期回避的问题:
当我们想让模型学会"如何使用某种行为/工具"时,这种行为本身的奖励应该是无条件的,还是有条件的?
过去一年里,社区的注意力主要集中在:奖励的"形式"(结果奖励 vs 过程奖励)、采样策略(DAPO 的动态采样)、熵控制(防坍缩)、KL 项(防偏移)。这些都重要,但 GeometryZero 把视角拉回到了一个更基础的问题——
奖励信号本身是不是因果、是不是可证伪?
GCPO 给出的回答是:用一对"对照组 rollout"作为 in-context 的因果探针,把"使用某种行为"的收益就地、就题、就模型当前能力地估计出来,再据此发奖。这和因果推断里的 ATE/CATE 思想颇为相似——只是把对照组从"用户群体"换成了"同一道题的不同 rollout 路径"。
这个思路并不局限于辅助线。理论上,任何可以被开关的"中间行为"——调用 Python、查检索、走某个推理子流程——都可以套用同样的组对比框架。这可能是 GeometryZero 留给社区最有想象力的延伸:
RL 不再粗暴地"鼓励一切可能有用的行为",而是让模型自己用对照实验告诉你,这个行为现在到底值不值得做。
六、写在最后
|
|
|
|---|---|
|
|
GeometryZero: Advancing Geometry Solving via Group Contrastive Policy Optimization |
|
|
|
|
|
|
|
|
https://github.com/ekonwang/GeometryZero |
|
|
|
一句话总结:当 RL 想要"教模型用工具"时,先别急着发奖——让两组 rollout 替模型回答"这次到底值不值得用"。
GeometryZero 把这个朴素的因果直觉做成了一个 7B 小模型也能跑得动的训练框架,并第一次在几何这个"最考验判断力"的子领域里证明:判断何时出手,比出手本身更接近推理的本质。
关于我们:👋 Research AI+是一个面向青年研究者的 Global开放社区。我们汇聚了AI 及 AI for Science/Engineering方面的众多优秀学者、科研工作者和产业界研究员、工程师、AI项目开源贡献者和Tech Founders,是一个站在学术、产业与创业交叉点的创新型开源社区。欢迎志同道合的小伙伴关注和加入我们!👇
点击下方关注我们