
我越来越觉得,大模型升级里最容易被低估的,不是它能不能再多做对几道题,而是它会不会少折腾人。
4 月 23 日, OpenAI 发布 GPT-5.5。我把发布页、 system card 和配套说明连着看下来,真正让我停住的,不是榜单又抬高了多少,而是另一件更具体的事:
模型终于开始少占人的管理精力了。
过去一年,很多人嘴上说在用 AI ,实际工作方式却很像在带一个很聪明、但还是要你全程盯着的实习生。
你得把任务拆成一小段一小段。
你得不断补背景、补约束、补文件。
你得提醒它别漏步骤、别乱猜、别忘复核。
做文档要盯结构,做表格要盯口径,写代码要盯上下文,查资料还得盯它有没有真的核过来源。
模型当然在干活。
但你也在同时干另一份活:
管理模型。

这次最关键的变化,是“管理成本”开始往下掉
OpenAI 在 GPT-5.5 的发布页里反复强调,它更擅长处理 messy, multi-part tasks,理解任务更早,需要更少指导,还能自己扛更多步骤。
这句话我觉得比“更会回答问题”重要得多。
因为真实工作本来就不是一道干净的选择题。
你面对的,往往是一团混着网页、表格、代码、旧文档、邮件和口头要求的脏任务。真正有价值的模型,不是把其中某一步做得更像专家,而是能把这些零碎东西接起来,自己规划、自己调用工具、自己检查,然后继续往前推。
所以我看 GPT-5.5,最在意的不是它又把哪个 benchmark 刷高了,而是它有没有把那段最烦的来回沟通压短。
官方这次给的工程描述也很说明问题。很多任务里,它不只是结果更好,还能用更少 token 、经历更少重试,并把延迟保持在 GPT-5.4 的同级别。
翻成人话就是:
它不只是更聪明,而是更省人、省来回、省返工。
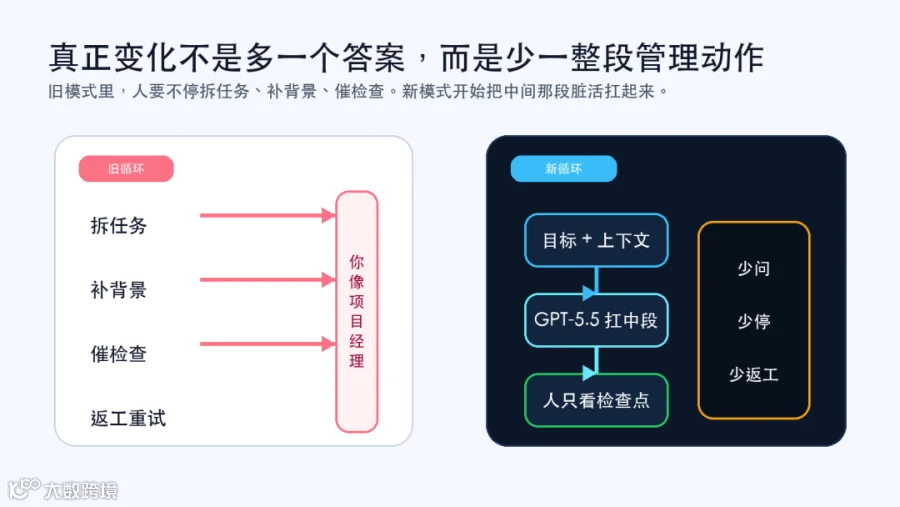
这比 benchmark 更重要,因为公司里的活本来就很脏
很多模型演示之所以看起来很强,是因为题目被提前洗干净了。
但公司里真正贵的工作,往往都不干净。
需求是模糊的,信息是分散的,工具是多套的,责任是要回看的,最后还得交付一个别人能继续接手的结果。
GPT-5.5 这次让我觉得值得认真看,就是因为它把评估重点继续往这些场景拉了。Terminal-Bench 2.0、GDPval、OSWorld 这些指标,本质上都不再只问“会不会答”,而是在问“能不能把过程跑顺”。
OpenAI 自己给的内部案例也很像真实组织会遇到的事。 Comms 团队拿它分析半年的 speaking request ,先搭分类和风险框架,再把低风险请求自动化; Finance 团队拿它处理两万多份 K-1 税表、七万多页材料;公司里每周使用 Codex 的人已经超过 85%。
这组信息放在一起,真正说明的是一件事:
AI 开始从“帮你出一个答案”,走向“帮你把一段工作接住”。
同一天 OpenAI 还同步放出了 GPT-5.5 System Card 和 GPT-5.5 Bio Bug Bounty。这在我看来也很关键。说明 frontier 模型的发布方式开始更像正式软件上线,不只是演示能力,还要把外部测试、专项风险和持续验证一起纳入流程。
因为一旦模型真的能扛复杂工作,它带来的就不只是效率,还有操作权。
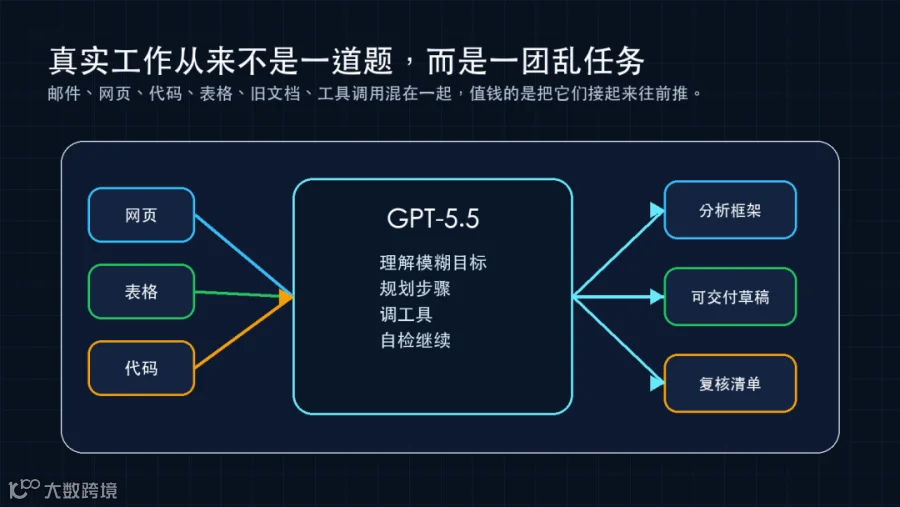
软件入口会从 Prompt Box ,慢慢长成 Task Cockpit
如果这个判断成立,接下来很多 AI 软件的交互方式都会变。
过去大多数产品还是 prompt era 逻辑:
你负责想清楚,模型负责执行。
所以最重要的是输入框、提示词技巧和会不会下指令。
但当模型开始更能扛住脏活,这套逻辑就不够了。
接下来更合理的形态,会是 task era 逻辑:
你给目标、上下文、边界和检查点,模型负责把中间那段混乱工作尽量扛住。
这时候真正重要的,就不只是一行输入框了。
而是附件、上下文窗口、工具权限、预算限制、审阅节点、日志、回滚和 handoff 。
谁先把这套东西做顺,谁就更像下一代生产软件,而不只是一个更贵的聊天框。
这也是为什么我会觉得,GPT-5.5 这种升级真正推的,不只是模型能力,而是软件设计重心。
从“怎么把 prompt 写漂亮”,转向“怎么把任务系统设计完整”。

对团队来说,现在最值得做的不是追分,而是找对任务
如果你今天想在公司里认真吃到这波红利,我反而建议别先追最新榜单。
先找三类活:
第一,信息很乱,但目标明确。
第二,需要跨工具切换,但中间步骤有章可循。
第三,结果允许先出草稿,再进人工复核。
这类任务最容易吃到 GPT-5.5 这种“少管理模型”能力的红利。
因为它提升的不是灵光一现,而是持续把事情往前推的能力。
当然,这不等于可以彻底放手。
审批、日志、权限、回滚、人审,还是得有。
GPT-5.5 解决的不是“人能不能消失”,而是“人能不能别再被迫当模型 babysitter”。
所以我看这次更新,最在意的不是它又把榜单抬高了几分。
我更在意的是, AI 终于开始少占管理精力了。
当一个模型开始少问、少停、少返工、少把脏活重新丢回给你,它才第一次真正接近一个能交付的工作系统。
那时候你买的,就不再只是智能本身,而是人终于能把注意力从盯步骤,挪回到做判断。