
经常切换使用CC、Codex、OpenClaw这类Agent的人会发现:同一个模型,放进不同系统里,表现可能完全不同。
近期由CMU、耶鲁大学、弗吉尼亚理工大学及亚马逊等机构组成的研究团队,在系统梳理了170余个开源项目,并总结了OpenAI、Anthropic、LangChain以及大量开源Agent项目中的工程经验后明确指出:包裹模型的“线束系统(Harness)”才是决定Agent是否稳定、长期可用的硬约束。并写成综述《Agent Harness Engineering: A Survey》。

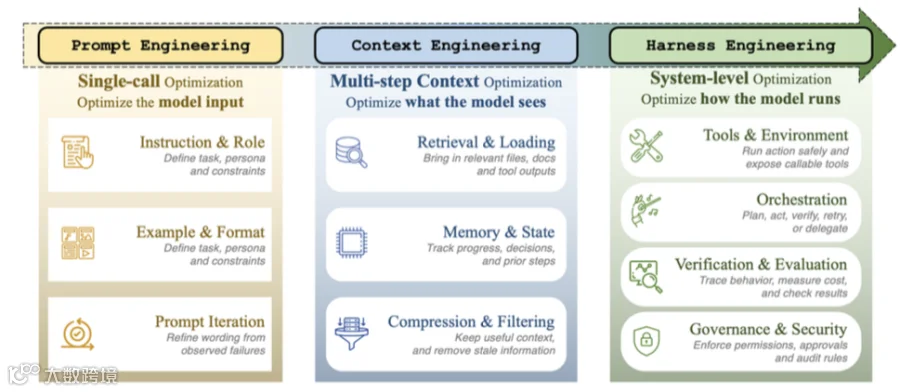
这项工作系统化提出了Agent Harness的ETCLOVG七层架构(覆盖执行、工具、上下文、生命周期、可观测性、评测与治理)体系。这篇文章将带你深度拆解这篇重磅论文,不管你是Agent的开发者还是使用者,看完这篇文章,对于Agent Harness Engineering你就算入门了。
核心命题:Harness才是Agent可靠性的硬约束
论文最重要的概念叫 binding-constraint thesis,可以翻译为“约束瓶颈命题”或者叫“约束绑定假说”。它的意思是:在长任务、多步骤、工具调用密集的Agent场景中,系统表现不再主要由模型本身决定,而是由模型外部的Harness决定。
论文引用了三个例子来支撑这个观点:
只修改编辑工具格式和工具Harness,不改模型,多个coding benchmark上出现最高10倍提升。
固定GPT-5.2-Codex模型,仅通过系统提示词重构、中间件上下文注入、自验证hook,把Terminal-Bench 2.0从52.8% 提升到66.5%。
Meta-Harness 通过自动优化Harness,在Terminal-Bench-2上达到76.4%,超过手工工程方案,而且没有修改模型权重。
论文由此得出一个很强的判断:在很多真实Agent任务中,换更强模型带来的收益,可能不如改Harness带来的收益大。这和过去两年很多人的直觉一致:同一个模型,在不同Agent框架中表现差异巨大;同样是Claude或Qwen,放进不同工具层、不同上下文管理、不同执行环境,稳定性会完全不同。
这对Agent工程的启发很直接:
模型只是推理引擎,Harness才是行为系统。
一个Agent真正能不能完成任务,取决于:
-
它能不能在安全可恢复的环境中行动; -
它看到的信息是不是正确、足够、不过载; -
工具是否清晰、可选、可验证; -
多轮任务状态是否持续; -
错误能不能被记录、归因、回滚; -
权限边界是否明确; -
人类是否能在关键节点介入。
这些都不是模型权重本身解决的问题,而是Harness的职责。
智能体工程的三个演进阶段
从2022年到2026年,行业经历了一个清晰的三阶段演进:
提示词工程(Prompt Engineering, 2022-2024): 优化单次模型调用的文本输入。工程范围很窄,主要关注指令、少样本示例和推理模板。
上下文工程(Context Engineering, 2025): 随着智能体运行时间变长,重点变成了“模型在每一步应该看到什么信息”。这涉及记忆检索、压缩、工具结果排序等。
线束工程(Harness Engineering, 2026): 重点转向了管理多步骤、长时间运行任务的执行外壳(Wrapper)。这包括维护状态、调度工具、注入反馈、强制执行安全约束等。
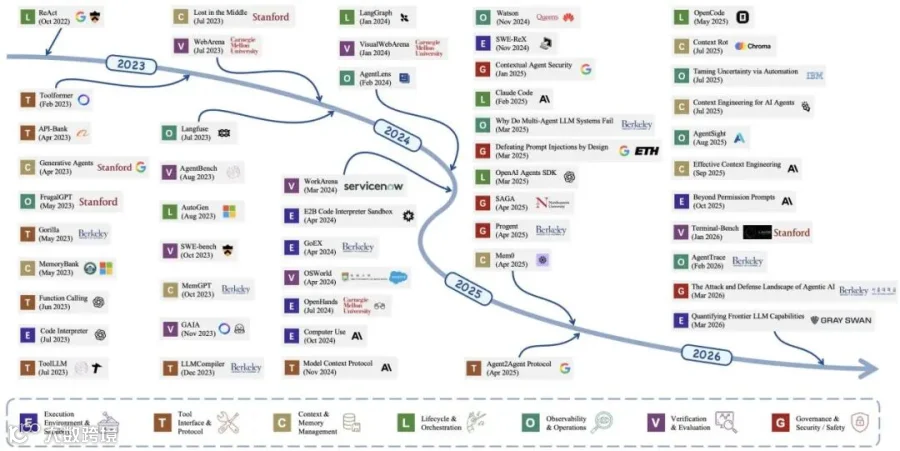 论文用时间线展示从ReAct、Toolformer、WebArena、MCP到Terminal-Bench等系统的发展,说明Agent工程逐步从单一模型循环扩展到执行环境、工具协议、上下文、编排、可观测性、评测和治理的完整基础设施。
论文用时间线展示从ReAct、Toolformer、WebArena、MCP到Terminal-Bench等系统的发展,说明Agent工程逐步从单一模型循环扩展到执行环境、工具协议、上下文、编排、可观测性、评测和治理的完整基础设施。
ETCLOVG:七层Agent Harness框架
为了系统化地研究这一领域,,研究者提出了ETCLOVG七层分类法: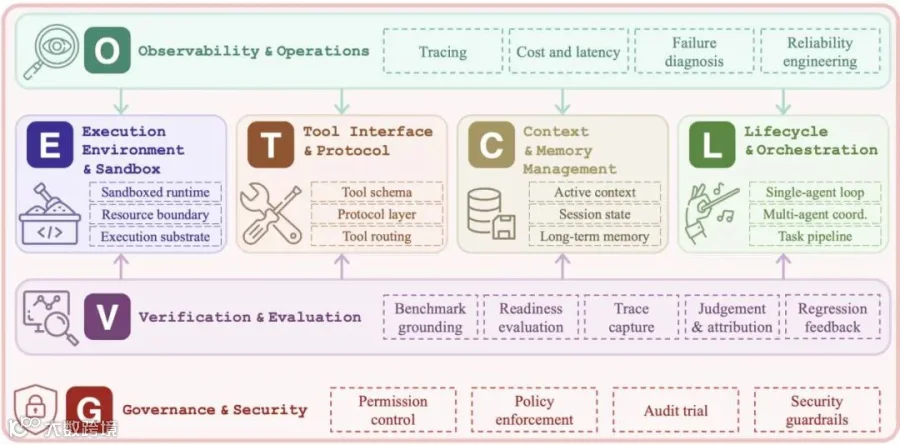
E:Execution Environment & Sandbox:执行环境与沙箱
-
解决的问题:Agent在哪里运行,怎么限制风险。 T:Tool Interface & Protocol:工具接口与协议
-
解决的问题:工具如何描述、发现、调用。 C:Context & Memory Management:上下文与记忆
-
解决的问题:管理模型每一步看到什么,状态如何延续 L:Lifecycle & Orchestration:生命周期与编排
-
解决的问题:单Agent、多Agent、任务流如何运行 O:Observability & Operations:可观测性与运维
-
解决的问题:如何追踪、监控、归因、控成本 V:Verification & Evaluation:验证与评测
-
解决的问题:如何判断任务是否真的完成 G:Governance & Security:治理与安全
-
解决的问题:权限、身份、策略、审计、人工介入
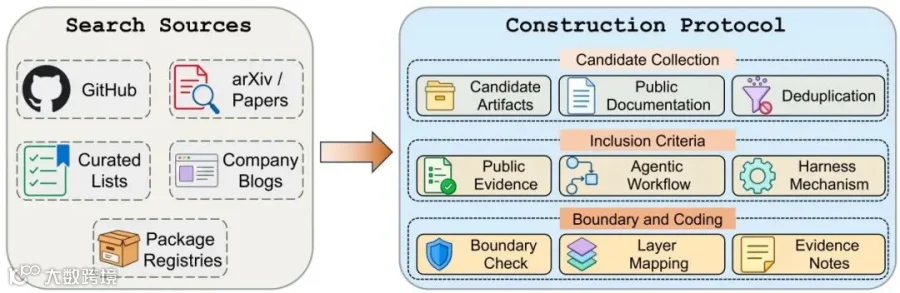 研究者从GitHub、论文、精选列表、公司工程博客和包注册表中收集候选项目,再经过去重、纳入标准检查和公开文档标注,将170+个项目映射到ETCLOVG七层框架中。
研究者从GitHub、论文、精选列表、公司工程博客和包注册表中收集候选项目,再经过去重、纳入标准检查和公开文档标注,将170+个项目映射到ETCLOVG七层框架中。
研究者强调,前四层E/T/C/L是结构核心,后三层O/V/G是控制平面。前者让Agent能运行,后者让Agent可控、可查、可验证、可上线。论文尤其强调Observability和Governance应该独立成层,而不是附属于生命周期hook,因为在生产系统中,它们已经有独立工具栈和独立团队所有权。
这个框架的好处是,它把Agent从“模型 + 工具”的简单结构提升成一个完整工程系统。对开发者来说,这意味着设计Agent时不能只写:
LLM + tools + memory
而应该拆成:
runtime + sandbox + tool protocol + context policy + orchestration + tracing + eval + governance
这就是论文的系统视角。
E层:执行环境与沙箱是Agent的物理底座
智能体必须在一个物理环境中执行动作。在智能体时代,沙盒不仅仅是为了安全,它还具有三个核心目的:安全(Security)、可复现性(Reproducibility)和活跃性(Liveness)。活跃性是指,通过把智能体关在沙盒里,它可以自由执行操作而无需人类频繁点击“允许”,从而避免了长周期任务中的权限提示疲劳。
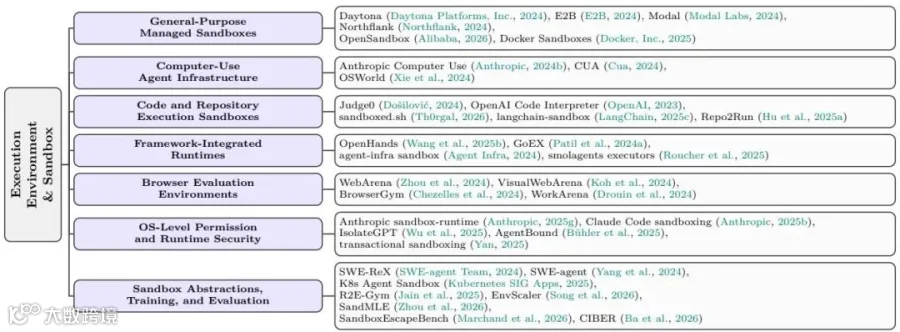 论文按沙盒类别整理了Daytona、E2B、OpenAI Code Interpreter、OpenHands、WebArena、OSWorld、SWE-ReX等代表系统,展示执行环境层既包含通用运行时,也包含代码、浏览器、桌面和OS级隔离方案。
论文按沙盒类别整理了Daytona、E2B、OpenAI Code Interpreter、OpenHands、WebArena、OSWorld、SWE-ReX等代表系统,展示执行环境层既包含通用运行时,也包含代码、浏览器、桌面和OS级隔离方案。
论文将沙盒分为七类:
通用托管沙盒(General-Purpose Managed Sandboxes): 如Daytona、E2B,提供基于微虚拟机(MicroVM)或容器的API接口,支持任意负载。
计算机使用基础设施(Computer-Use Agent Infrastructure): 像Anthropic的Computer Use,直接提供完整的图形桌面环境(虚拟机),让智能体通过模拟鼠标/键盘操作。
代码专用沙盒(Code-Specialized Sandboxes): 如OpenAI Code Interpreter,优化了代码生成和数据分析的启动速度和并发性。
框架集成运行时(Framework-Integrated Runtimes): 如OpenHands,将沙盒与智能体框架捆绑在一起,提供开箱即用的体验。
浏览器评估环境(Browser Evaluation Environments): 如WebArena,提供隔离的Web环境供智能体执行和基准测试。
操作系统级权限沙盒(OS-Level Permission Sandboxes): 不使用容器,而是通过操作系统的原语(如bubblewrap)限制文件和网络访问,非常轻量。
沙盒抽象层(Sandbox Abstraction Layers): 将底层沙盒技术解耦,使得智能体代码可以无缝切换不同的执行环境。
T层:工具协议能不能可靠调用
这一层定义了智能体如何发现能力、表示可用操作以及在不同运行时边界执行操作。
 工具层被拆成协议标准、工具描述与选择、工具增强训练、规模化与会话管理几类;MCP、A2A、Function Calling、Toolformer、ToolBench、ReAct和LLMCompiler都被放在这一层的不同问题域中。
工具层被拆成协议标准、工具描述与选择、工具增强训练、规模化与会话管理几类;MCP、A2A、Function Calling、Toolformer、ToolBench、ReAct和LLMCompiler都被放在这一层的不同问题域中。
协议与接口标准: MCP (Model Context Protocol) 已经成为整合工具的显学,它通过客户端-服务器架构提供标准化的工具和资源访问。而A2A协议则专注于不同智能体应用之间的通信与协作。
工具发现与选择: 生产环境的经验表明,“更少但更好的工具”往往优于提供庞大的工具菜单。庞大的菜单会消耗Token并导致规划错误。
规模化与会话管理: 处理长周期任务时,管理工具的状态(如过期的句柄、重试时的状态一致性)至关重要。
C层:上下文管理是Harness与Prompt的交界处
Context & Memory Management这一层决定智能体连贯性的核心。LLM的注意力机制成本随上下文长度呈二次方增长,并且存在“上下文腐烂(Context Rot)”和“U型注意力曲线”现象(模型容易忽略中间的信息)。因此,上下文不能被动积累,必须主动管理。
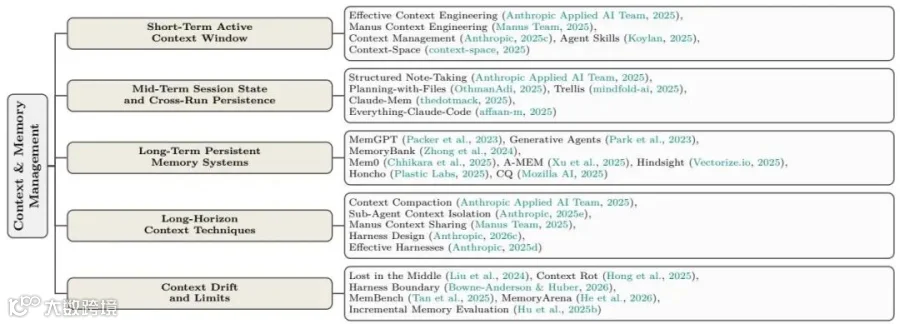 论文把上下文管理分成短期活动上下文、中期会话状态、长期持久记忆、长周期上下文技术和上下文漂移限制五部分,对应渐进式披露、结构化笔记、MemGPT/Mem0、上下文压缩和记忆评测等方向。
论文把上下文管理分成短期活动上下文、中期会话状态、长期持久记忆、长周期上下文技术和上下文漂移限制五部分,对应渐进式披露、结构化笔记、MemGPT/Mem0、上下文压缩和记忆评测等方向。
论文借用操作系统的内存层级,将其分为三层:
短期(活动上下文窗口): 优化系统提示词,使用渐进式披露(Just-in-time retrieval)按需加载文件,以及利用KV缓存(Prompt Caching)来降低成本。例如,将静态的系统指令和工具定义放在最前面,以最大化缓存命中率。
中期(会话状态与跨运行持久化): 通过“结构化笔记(Structured Note-Taking)”或将规划写入外部文件,让智能体在清空上下文后,能通过读取笔记恢复状态。
长期(持久化记忆系统): 类似操作系统的硬盘。例如MemGPT、Mem0和Honcho,它们结合了向量数据库、图数据库,不仅存储事实,还通过“观察、反思、检索”机制不断提取更高层的知识和用户偏好。
在长周期任务(100+ 轮对话)中,还需要使用 上下文压缩(Context Compaction) 和 子智能体隔离(Sub-agent context isolation) 来防止上下文漂移(Context Drift)。
L层:生命周期与编排决定Agent如何持续运行
这一层管理智能体在多次调用、失败、重试中的执行流和状态。
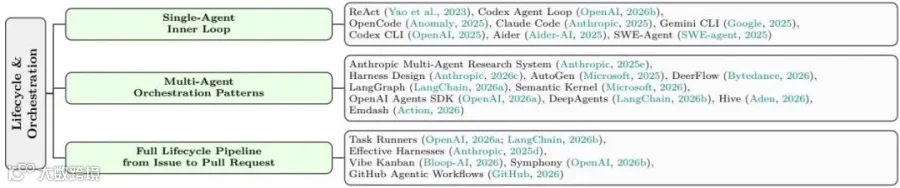 生命周期层覆盖单智能体内循环、多智能体编排和从Issue到Pull Request的完整任务流水线,体现Agent从一次工具调用走向持续运行、委派、验证和交付的过程。
生命周期层覆盖单智能体内循环、多智能体编排和从Issue到Pull Request的完整任务流水线,体现Agent从一次工具调用走向持续运行、委派、验证和交付的过程。
单智能体内循环(Single-Agent Inner Loop): 经典的ReAct模式(观察-思考-行动),基于无状态重放(Stateless replay)或混合状态运行。
多智能体编排(Multi-Agent Orchestration): 包括分层编排(如AutoGen)、图组合(如LangGraph)、工作流编排等模式。这能更好地分解任务并引入验证者角色。
全生命周期任务流水线(Full Lifecycle Pipeline): 将智能体嵌入到从Issue到Pull Request的完整软件工程流程中(如GitHub Agentic Workflows),利用持久化构件(文件、PR)作为状态锚点。
O层:可观测性决定Agent能不能被调试和运营
论文特别将可观测性提升为独立的一层。因为在生产中,“出了问题怎么排查”是一个巨大的挑战。
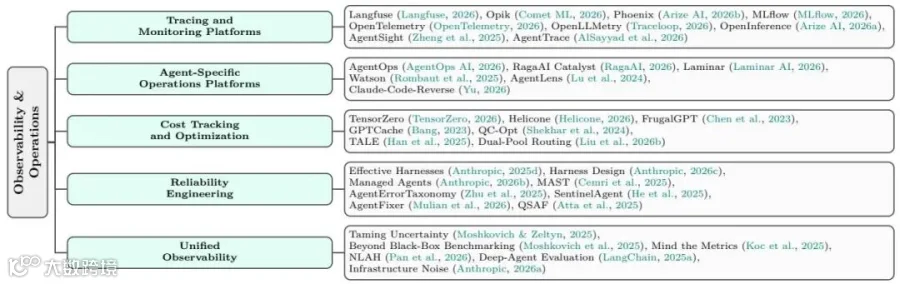 论文将可观测性拆成追踪监控、Agent专用运维平台、成本优化、可靠性工程和统一可观测性几类,强调Agent调试需要把模型调用、工具执行、检索、成本和失败归因串成一条可审计轨迹。
论文将可观测性拆成追踪监控、Agent专用运维平台、成本优化、可靠性工程和统一可观测性几类,强调Agent调试需要把模型调用、工具执行、检索、成本和失败归因串成一条可审计轨迹。
追踪平台: 基于OpenTelemetry,像Langfuse、Arize Phoenix这样的平台将大模型的调用、工具使用、检索步骤转化为可视化的“Span树”。
成本追踪: 因为每个子任务可能触发几十次LLM调用,成本很容易失控。FrugalGPT和智能路由(将简单任务路由给便宜模型)成为核心运维手段。
可靠性工程: 处理瞬时失败。比如,Anthropic提出了Managed Agents架构,将“大脑”(LLM)与“双手”(沙盒)解耦。沙盒崩溃了可以立刻重新拉起,而不会丢失进度。
V层:Agent评测必须评估“模型-Harness对”,而不是模型单体
评估不再是简单地看“最终答案对不对”,而是转变为一个 “任务到反馈”的五阶段生命周期 (Task-to-Feedback Lifecycle):
 论文把评测层组织成任务与基准基础、执行前准备验证、受控执行与轨迹捕获、多级判断与故障归因、持续回归反馈五类,强调评测对象应该是模型与Harness组合,而不是孤立模型。
论文把评测层组织成任务与基准基础、执行前准备验证、受控执行与轨迹捕获、多级判断与故障归因、持续回归反馈五类,强调评测对象应该是模型与Harness组合,而不是孤立模型。
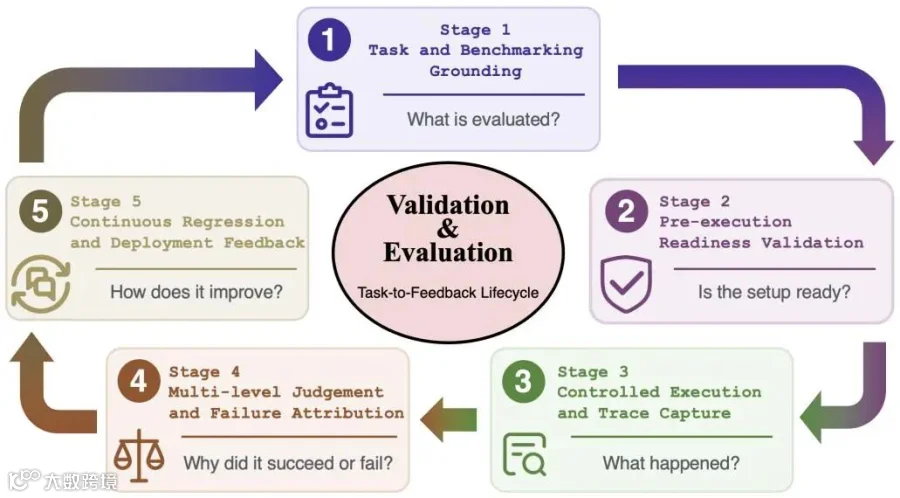 五阶段评测闭环从“评什么”开始,到“环境是否就绪”“执行中发生了什么”“为什么成功或失败”,最后把失败证据沉淀为回归测试,形成持续改进Harness的机制。
五阶段评测闭环从“评什么”开始,到“环境是否就绪”“执行中发生了什么”“为什么成功或失败”,最后把失败证据沉淀为回归测试,形成持续改进Harness的机制。
任务与基准基础(Grounding): 明确环境和成功标准(如SWE-bench依赖真实的GitHub Issue和测试用例)。
执行前准备验证(Readiness): 确保沙盒、依赖、权限已正确初始化,防止因环境问题导致误判。
受控执行与追踪捕获(Execution): 记录完整的轨迹(模型输出、工具调用、成本、延迟)。
多级判断与故障归因(Judgement): 不仅看结果,还要进行“轨迹级评估(Trajectory-level)”(工具调用是否合理)和“评估者级评估”(裁判模型本身是否偏见)。
持续回归反馈(Regression): 将失败的记录转化为线束的回归测试用例。
G层:治理与安全是Agent上线的最后硬门槛
当智能体能执行代码、发邮件时,安全就成了重中之重。
 治理层覆盖权限与身份、生命周期钩子、组件加固、声明式宪法、审计基础设施和Agent攻防图谱,说明安全不是单个guardrail,而是一整套跨层控制系统。
治理层覆盖权限与身份、生命周期钩子、组件加固、声明式宪法、审计基础设施和Agent攻防图谱,说明安全不是单个guardrail,而是一整套跨层控制系统。
权限与身份管理: 从静态的边界(如只能访问特定文件夹)发展到“上下文相关的权限控制”,甚至在多智能体系统中引入身份验证和授权令牌(OAuth风格)。
生命周期钩子(Lifecycle Hooks): 在四个关键点拦截:输入LLM前(防提示词注入)、执行工具前(防越权操作)、工具返回数据后(信息流控制与污点追踪),以及需要人类批准的“人机交互钩子”。
声明式宪法(Declarative Constitutions): 将安全规则(YAML格式)从代码中剥离,让合规团队可以直接修改智能体的行为边界、预算限制等。
审计: 记录不可篡改的结构化日志,以供事后溯源,防范“隐蔽的数据泄露”等长期攻击。
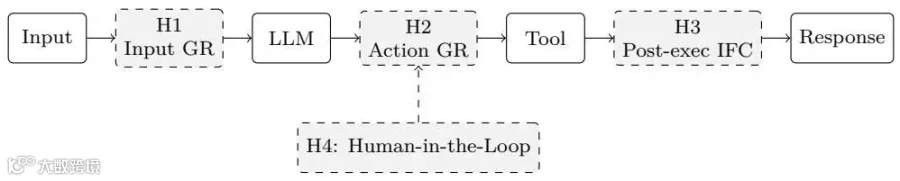 论文把治理hook放在输入进入LLM前、工具执行前、工具结果回写上下文前,以及需要人类审批的关键动作前,分别处理提示词注入、越权操作、信息流污染和高风险决策。
论文把治理hook放在输入进入LLM前、工具执行前、工具结果回写上下文前,以及需要人类审批的关键动作前,分别处理提示词注入、越权操作、信息流污染和高风险决策。
跨层综合分析与系统级挑战
这篇论文最深刻的地方在于它指出:ETCLOVG的七层是高度耦合的,无法孤立优化。研究者在此总结出三个核心权衡。
成本-质量-速度 的不可能三角(Cost-Quality-Speed Trilemma): 更强的沙盒、更丰富的上下文检索、更深度的安全验证,必然带来延迟上升和成本飙升。工程实践就是在做妥协。
能力与控制的权衡(Capability-Control Tradeoff): 赋予智能体的工具越多、记忆越长、沙盒权限越大,它的潜在破坏力(如提示词注入的爆炸半径)就越大。
线束耦合问题(Harness Coupling Problem): 工具描述的改变会消耗不同的上下文;沙盒环境的轻微变动会影响评估得分。线束是一个复杂的控制系统。
未来的开放性问题
研究者最后提出了五个开放问题:
强化和扩展执行环境: 如何在保证微虚拟机级别隔离强度的同时,实现低成本的大规模并发测试?
维持长周期智能体的状态可靠性: 上下文压缩必然会丢失信息,如何量化这种丢失?如何让智能体学会在状态崩溃时,通过外部构件(Artifacts)进行自我恢复?
从追踪日志中诊断故障: 目前的评估多是“结果导向”,未来的重点应该放在如何利用海量的可观测性日志,自动归因是模型的错、工具接口的错、还是沙盒环境的错。
标准化交接(Standard Handoffs): 在智能体之间、智能体与工具之间、甚至智能体与人类之间交接任务时,如何传递“意图、约束、权限、历史状态”?
随模型进化而自适应简化线束: 很多复杂的线束机制(如繁琐的反思循环)只是为了弥补当前模型能力的不足。当更强的模型发布时,如何自动识别并拆除那些已经变成“累赘”的基础设施?
总结
《Agent Harness Engineering》是对当前大模型智能体落地痛点的一记精准剖析。它将行业的视线从单纯的“卷模型参数”和“卷提示词技巧”,拉回到了严谨的系统工程上来。
它告诉我们:一个真正可用、安全的AI Agent,是由底层的模型引擎(LLM)和一套复杂的底盘、悬挂、刹车、仪表盘系统(Agent Harness)共同组成的。 掌握ETCLOVG七层架构,就是掌握了下一代AI基础设施的入场券。
未来已来,有缘一起同行!
<本文完结>
-
转载请与本喵联系,私自抓取转载将被起诉