
说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。
上周的《Agent Harness Survey》更像是在回答一个系统架构问题:一个真正可用的 Agent,外面应该包哪些东西?
而UIUC、Meta、Stanford这篇最新综述关心的是另一个问题:当Agent被放进长期任务环境里,真正把推理、行动、反馈、验证和协作串起来的操作对象是什么?
他们给出的答案是:代码化的执行过程。

这里的“代码”不是指Agent框架本身由代码写成,这当然是常识。它指的是Agent在执行任务时不断生成、运行、修改、保存和共享的一系列中间物。具象到实际的工程场景中,就是Claude Code生成的Plan.md,或者产出的Skills.md,验证用的Python文件等等。
这篇综述原文长102页,引用Reference有478篇,本文将为您直接抽丝剥茧,用最快的速度看懂这三大顶级机构是如何打通Claude Code到机器人Agent的底层运行逻辑的。
这篇论文如何定义Harness?
在深入技术细节之前,我们需要先明确几个核心概念。
为什么需要“脚手架(Harness)”?
一个纯粹的大语言模型是无状态的,它本质上只是在预测下一个词。为了让它变成一个能够执行长期任务的“智能体”,我们需要在模型外围包裹一层软件基础设施。这层基础设施包括:
-
工具和API接口 -
安全的沙盒执行环境 -
记忆与上下文管理系统 -
验证器与权限边界 -
执行与反馈的控制循环
这整套外围系统,就被研究者称为智能体脚手架(Agent Harness)。
为什么“代码”是最佳的脚手架媒介?
研究者指出,代码具备自然语言所不具备的三大核心特质:
可执行性(Executable):代码可以直接在计算机上运行,产生明确的客观结果。
可检查性(Inspectable):代码的执行过程会产生堆栈、日志和报错,这些是可以被精确追踪和分析的。
状态化(Stateful):代码环境(如文件系统、数据库)可以持久化保存任务的进度。
基于这三大特质,研究者构建了一个三层架构来系统性地拆解代码在智能体中的作用:脚手架接口层、脚手架机制层以及多智能体扩展层。
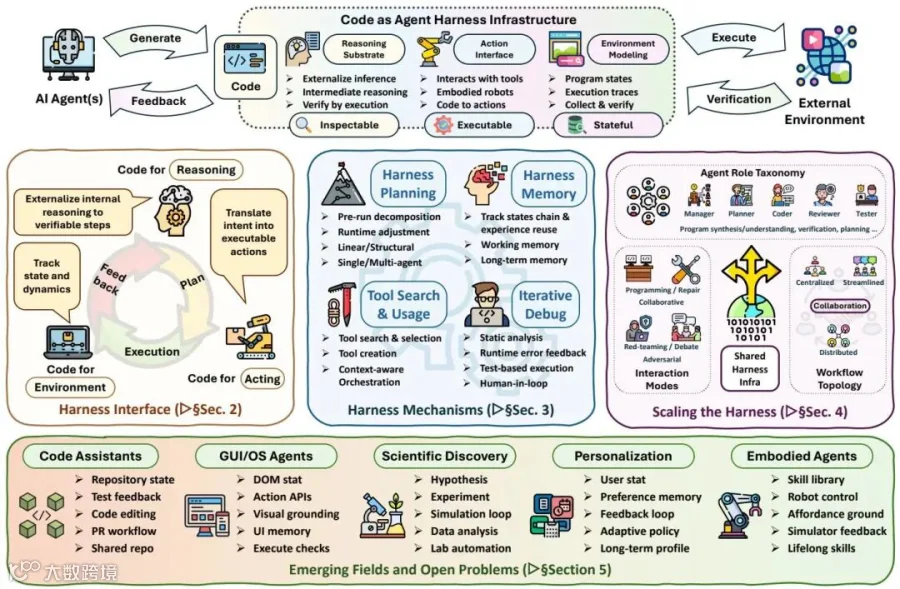 论文将代码作为智能体脚手架拆成三层:接口层让代码承载推理、行动和环境建模,机制层负责规划、记忆、工具、控制与优化,多智能体层则把代码仓库、测试、轨迹和执行状态变成协作基底。
论文将代码作为智能体脚手架拆成三层:接口层让代码承载推理、行动和环境建模,机制层负责规划、记忆、工具、控制与优化,多智能体层则把代码仓库、测试、轨迹和执行状态变成协作基底。
第一层:脚手架接口
在这一层,代码充当了智能体与现实世界沟通的基础接口。它具体表现在三个方面:用于推理、用于行动、用于环境建模。
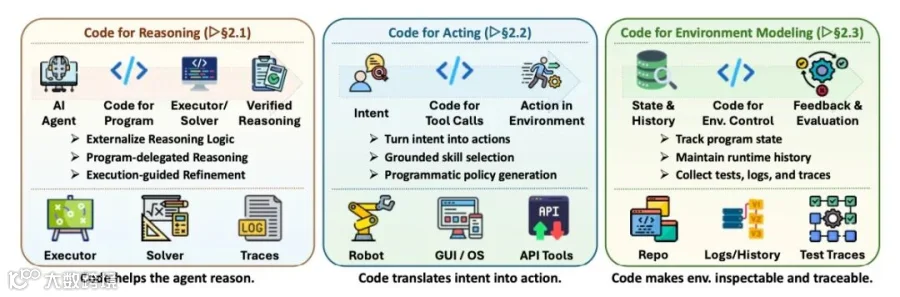 接口层的核心是把模型输出接到可执行程序、工具调用、状态跟踪和反馈轨迹上,使推理可验证、行动可落地、环境变化可观察。
接口层的核心是把模型输出接到可执行程序、工具调用、状态跟踪和反馈轨迹上,使推理可验证、行动可落地、环境变化可观察。
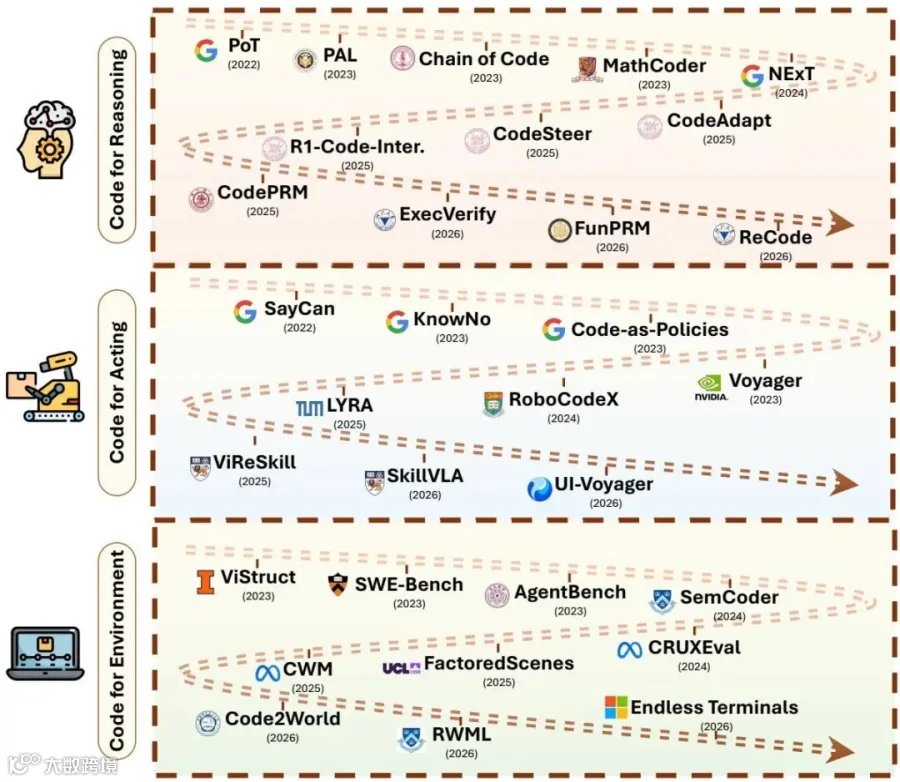 论文按代码在推理、行动和环境建模中的不同角色整理代表工作,展示这一层如何从程序辅助推理扩展到机器人控制、GUI/OS操作和软件工程评测环境。
论文按代码在推理、行动和环境建模中的不同角色整理代表工作,展示这一层如何从程序辅助推理扩展到机器人控制、GUI/OS操作和软件工程评测环境。
用于推理的代码(Code for Reasoning)
早期的智能体通常依赖纯文本的“思维链(CoT)”进行推理,但这往往会导致逻辑错误或计算不准确。将推理过程转化为代码,可以让外部解释器或求解器来验证逻辑。
程序委托推理:模型不再直接输出计算结果,而是生成一段Python脚本,交给Python解释器运行。这种方式将高层的逻辑分解与底层的精确计算彻底剥离。
形式化验证与符号推理:结合如Lean等形式化证明语言,让智能体的每一步推理都能够被机器验证器自动校验。这在数学定理证明和高安全性代码验证中尤为关键。
迭代式基于代码的推理:智能体通过“生成代码 -> 运行代码 -> 获取报错反馈 -> 修正代码”的闭环,利用真实的运行轨迹来引导下一步的推理方向。
用于行动的代码(Code for Acting)
当智能体需要与物理世界(机器人)或数字世界(软件GUI)互动时,代码就成了它的执行载体。
基于环境约束的技能选择:智能体不直接生成底层的物理控制指令,而是调用预先写好的、符合物理规律的代码技能库(如SayCan系统),确保动作的可行性。
程序化的策略生成:智能体直接编写包含条件分支、循环的控制脚本。例如,生成一段完整的Python行为树代码,来精细化地控制机械臂的运动。
终身代码智能体:智能体在长期的运行中,不断将成功解决问题的操作封装成新的代码函数,存入长期“技能库”中(如著名的Voyager系统),实现能力的持续进化。
用于环境建模的代码(Code for Environment)
环境的状态往往是复杂且动态的,用纯文本很难精确描述。代码可以将环境具象化为可操作的对象。
结构化的世界表示:用代码中的类、对象关系或树状结构(如网页的DOM树)来精确刻画当前环境的空间和逻辑结构。
基于执行轨迹的世界建模:智能体通过阅读代码的运行日志、测试结果,来推断环境状态发生了什么改变,从而建立起对环境动态变化的预测模型。
可验证的环境构建:利用单元测试、测试桩(Mock)等代码工程手段,为智能体构建一个具备客观对错评判标准的微型世界。
第二层:脚手架机制
有了底层的接口,智能体还需要一套复杂的机制来保证它在长达数小时甚至数天的任务中不崩溃。研究者将这些机制归纳为五大模块。
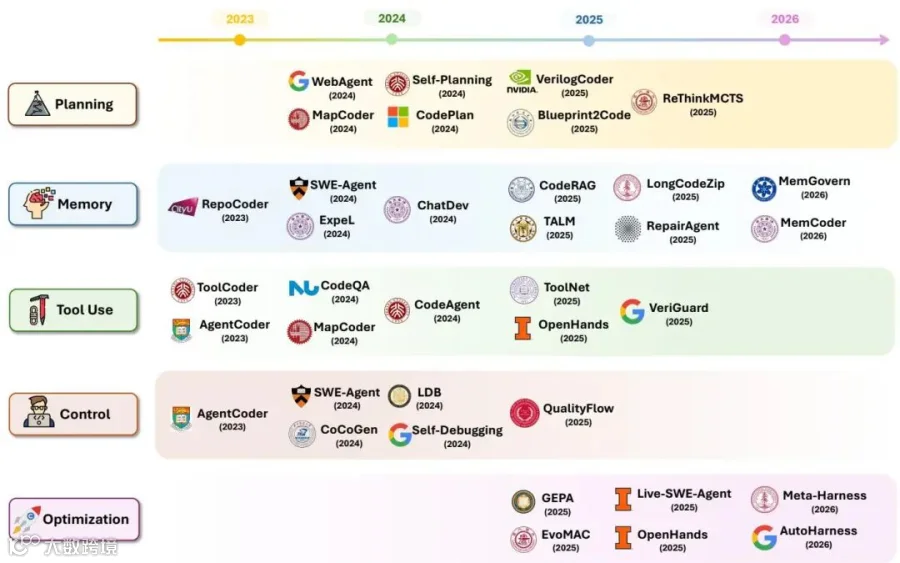 机制层覆盖规划、记忆、工具使用、控制循环和脚手架优化五类问题,强调智能体可靠性来自模型判断、可变任务状态和受治理的运行时基础设施共同作用。
机制层覆盖规划、记忆、工具使用、控制循环和脚手架优化五类问题,强调智能体可靠性来自模型判断、可变任务状态和受治理的运行时基础设施共同作用。
智能体的规划机制(Planning)
处理复杂的软件工程任务,智能体必须要有清晰的执行路径。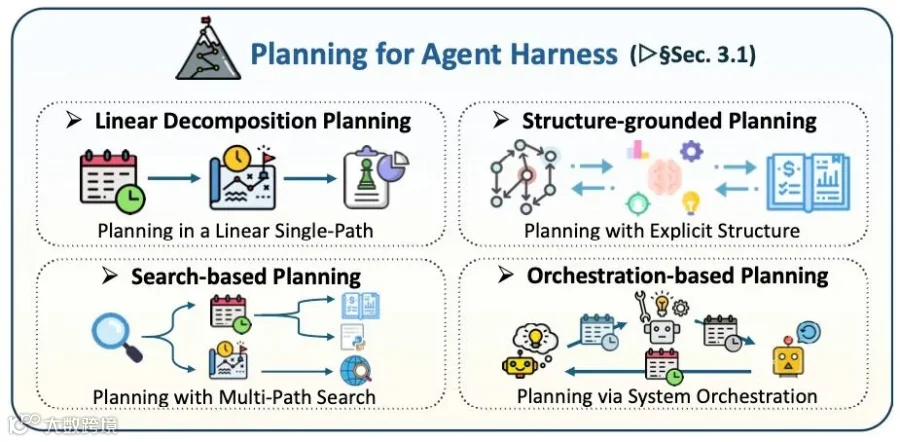 规划机制可以是单路径的步骤拆解,也可以利用显式结构、多路径搜索或系统级工作流编排来控制长周期任务的执行轨迹。
规划机制可以是单路径的步骤拆解,也可以利用显式结构、多路径搜索或系统级工作流编排来控制长周期任务的执行轨迹。
线性分解规划:将大任务拆解为线性的步骤列表(如生成一份
PLAN.md文件),智能体严格按照步骤生成代码。基于结构的规划:利用代码仓库的依赖图谱(AST、类关系图)来指导操作顺序。智能体能够知道修改这个函数会影响哪些其他文件,从而制定更安全的修改计划。
基于搜索的规划:引入蒙特卡洛树搜索(MCTS)等算法。在生成代码时探索多个可能的分支,遇到走不通的路径时,能够利用报错信息进行回溯。
基于编排的规划:将任务划分为理解、检索、编码、测试等不同的流水线阶段,通过系统级别的流程调度来控制智能体的下一步行动。
记忆与上下文工程(Memory and Context Engineering)
处理百万行级别的代码库,大模型极其容易受困于上下文长度限制,因此需要极强的内存治理方案。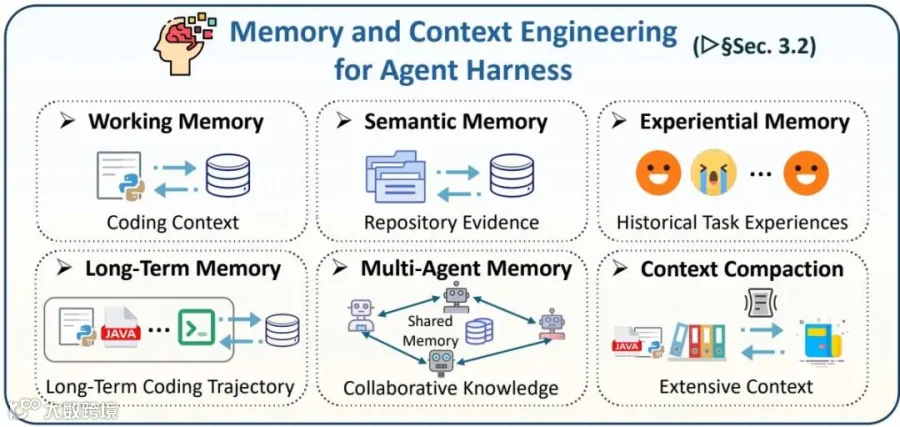 记忆层把工作记忆、语义记忆、经验记忆、长期记忆、多智能体记忆以及上下文压缩统一到同一个状态治理问题中,目标是在有限上下文内保留真正影响任务成败的证据。
记忆层把工作记忆、语义记忆、经验记忆、长期记忆、多智能体记忆以及上下文压缩统一到同一个状态治理问题中,目标是在有限上下文内保留真正影响任务成败的证据。
工作记忆(Working Memory):严格管理当前正在编辑的局部状态(如当前文件的行号、最近的几条报错日志),防止上下文被无关信息淹没。
语义记忆(Semantic Memory):利用检索增强生成(RAG)技术,从庞大的代码仓库中精准调取相关的类定义、API接口和历史文档。
经验与长期记忆(Experiential Memory):智能体将过去排查Bug的经验、成功验证的补丁等,转化为结构化的经验库,实现跨任务的知识复用。
上下文压缩与卸载:当日志过长时,系统会自动对其进行粗细粒度的压缩,或者将完整的日志保存到外部文件中,只在提示词中保留关键的摘要。
工具使用(Tool Use)
工具是智能体改变外部世界的手段,但在代码脚手架中,工具的使用必须受到严格的管控。
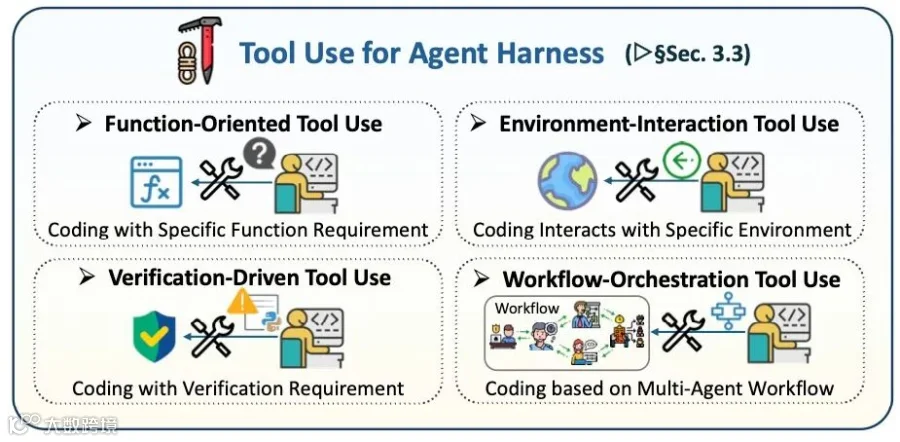 工具层不仅包括函数调用和外部API,也包括终端、仓库、沙盒、验证器和多步骤工作流;关键问题是让工具可发现、可调用、可审计并能在失败时恢复。
工具层不仅包括函数调用和外部API,也包括终端、仓库、沙盒、验证器和多步骤工作流;关键问题是让工具可发现、可调用、可审计并能在失败时恢复。
功能导向工具:用于补充模型欠缺的知识,例如调用外部API搜索文档、查询特定的库函数用法。
环境交互工具:允许智能体直接在真实环境中操作,如执行终端命令(Shell)、进行文件读写、导航代码仓库。
验证驱动工具:使用代码检查器(Linter)、类型检查器或单元测试框架,为智能体的输出提供确定性的客观反馈。
工作流编排工具:负责调度多个子工具的调用顺序,并处理工具调用失败时的异常恢复。
计划-执行-验证循环(PEV Loop)
研究者指出,Agent的调试过程本质上是一个控制论问题,应当被框架化为PEV循环(Plan-Execute-Verify)。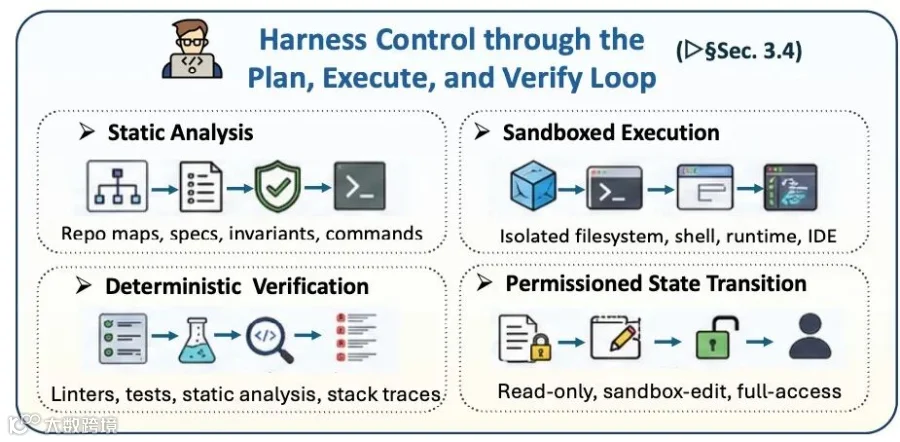 PEV循环将规划、沙盒执行、静态/动态验证和权限控制组织成可重复的状态转换流程,使智能体的每次修改都能被观测、判断和必要时回滚或升级给人类。
PEV循环将规划、沙盒执行、静态/动态验证和权限控制组织成可重复的状态转换流程,使智能体的每次修改都能被观测、判断和必要时回滚或升级给人类。
计划(Plan):将用户需求转化为明确的操作契约,确定要修改的范围。
执行(Execute):必须在沙盒环境(Sandboxed Execution)中运行。通过隔离的文件系统和分级的权限控制,确保智能体的破坏性操作不会影响宿主机的安全。
验证(Verify):利用静态分析和动态测试作为“确定性传感器”。如果测试失败,智能体必须根据日志进行修复;如果涉及高危操作,必须强制接入人类审批(Human-in-the-loop)。
自适应脚手架工程(Agentic Harness Engineering)
这是该论文提出的一个极其前沿的概念。系统不应该仅仅停留在修复代码本身,还应该能够自动优化包围在模型外围的“脚手架”。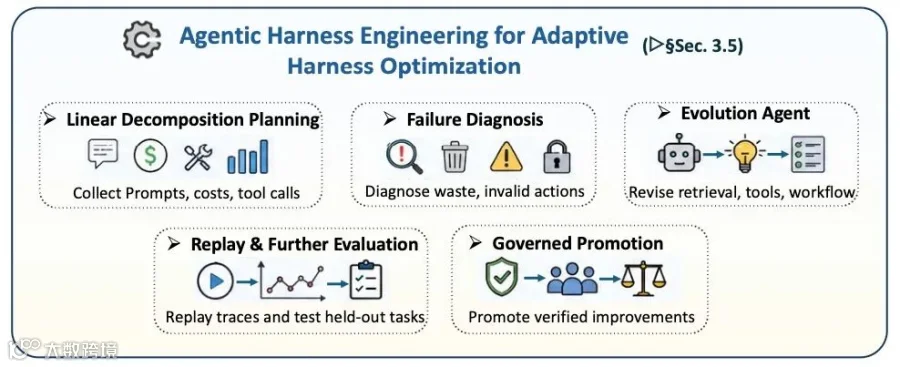 自适应脚手架工程把提示词、检索策略、工具描述、验证器、权限规则和工作流本身都视为可优化对象;但这些修改必须经过轨迹回放、保留任务评测和治理规则约束。
自适应脚手架工程把提示词、检索策略、工具描述、验证器、权限规则和工作流本身都视为可优化对象;但这些修改必须经过轨迹回放、保留任务评测和治理规则约束。
深度遥测(Deep Telemetry):全面记录智能体的Token消耗、延迟、工具调用成功率以及完整的执行轨迹。
进化智能体(Evolution Agent):专门设立一个元级别的智能体,它不写业务代码,而是分析遥测数据,自动修改检索策略、更新提示词模板或重构沙盒规则,从而让整个系统越来越稳定。
第三层:扩展脚手架
面对真实的、极度复杂的企业级需求,单智能体的上下文和能力很容易达到瓶颈。引入多智能体协同(MAS)是必然趋势。在这个阶段,代码正式成为了各个智能体之间沟通、协同与达成共识的“共享基底”。
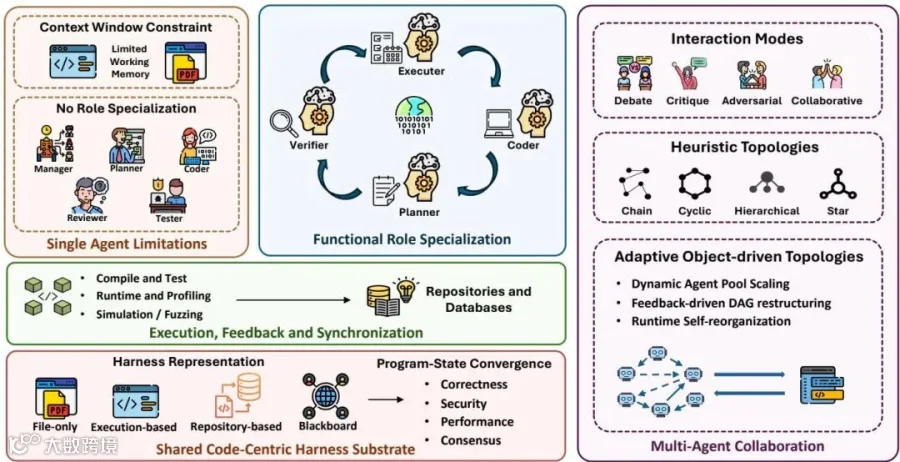 多智能体扩展层通过角色专业化、共享代码基底、执行反馈和自适应协作拓扑,缓解单智能体在上下文、专业能力和自我纠错上的瓶颈。
多智能体扩展层通过角色专业化、共享代码基底、执行反馈和自适应协作拓扑,缓解单智能体在上下文、专业能力和自我纠错上的瓶颈。
角色分工(Role Specialization)
系统会模仿人类的软件开发团队,拆分出高度专业化的角色:
程序员(Coder):负责具体的代码编写。
测试员(Tester):专门编写刁钻的测试用例,刻意寻找程序员代码中的漏洞。
审查员(Reviewer):对代码进行架构和规范层面的审查。
执行者(Executor):负责在沙盒中运行代码并收集客观的报错日志。
规划经理(Manager):负责全局的任务拆解和流程调度。
交互模式(Interaction Modes)
结对编程(Collaborative Synthesis):两个智能体共同构建代码,一个负责导航和规划,一个负责具体实现。
审查与修复(Critique and repair):最常见的模式,验证智能体提出批评,编程智能体据此修改。
对抗性验证(Adversarial validation):利用模糊测试(Fuzzing)等手段,生成极端输入来刻意触发崩溃,并将崩溃轨迹反馈给编程者。
推理辩论(Reasoning debate):多个智能体对需求理解或代码规范产生分歧时,通过多轮对话达成共识。
核心阵地:共享的程序状态(Shared Program State)
研究者严厉指出,目前许多多智能体系统仅仅依靠“聊天记录”来传递信息,这会导致严重的“状态发散”,不同智能体对代码当前到底是什么样产生了认知错位。
未来的多智能体系统必须建立基于代码的客观全局共享状态:
-
无论是通过真实的Git仓库、内存中的黑板架构(Blackboard),还是完整的执行上下文。 “共识”不应仅仅是几个智能体互相说“看起来不错”,而必须是客观的测试全量通过、静态检查无警告、性能指标达标。
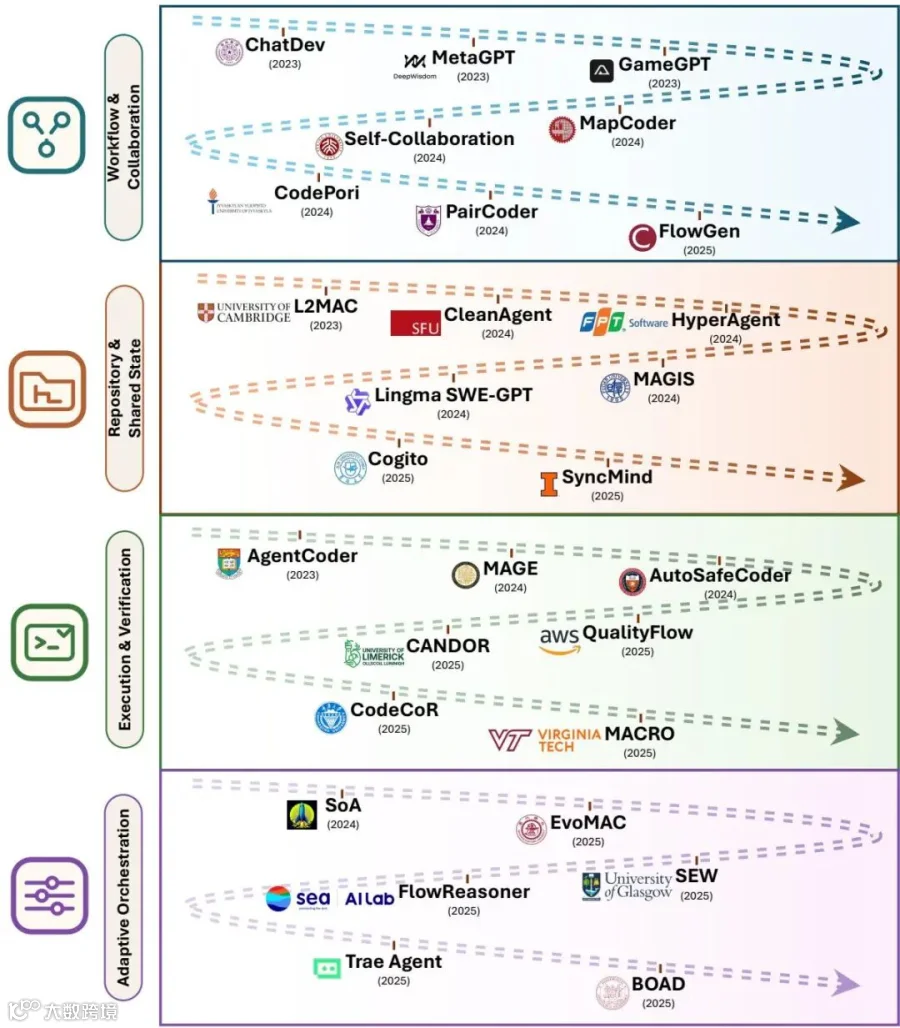 论文进一步把多智能体协同拆为工作流协作、共享仓库状态、执行验证和自适应协调四类问题,强调协作必须落在可检查的程序状态上,而不是只停留在对话记录中。
论文进一步把多智能体协同拆为工作流协作、共享仓库状态、执行验证和自适应协调四类问题,强调协作必须落在可检查的程序状态上,而不是只停留在对话记录中。
五大前沿应用领域
“代码作为智能体脚手架”的理念,目前已经在以下五个真实应用场景中落地开花:
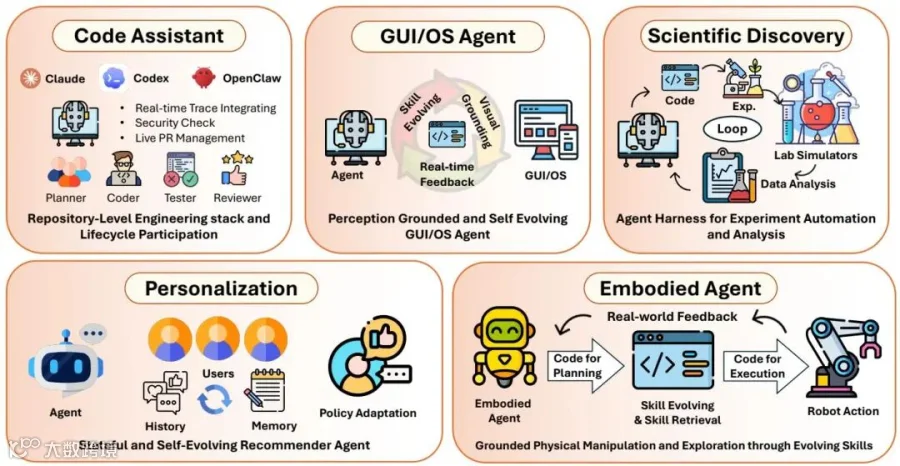 论文将落地场景概括为代码助手、GUI/OS智能体、科学发现、个性化推荐和具身智能体,说明代码脚手架正在从软件工程扩展到数字界面、科研流水线和物理世界控制。
论文将落地场景概括为代码助手、GUI/OS智能体、科学发现、个性化推荐和具身智能体,说明代码脚手架正在从软件工程扩展到数字界面、科研流水线和物理世界控制。
AI编程助手(Code Assistants)
从早期的单纯代码补全(如早期的Copilot),进化为能够处理GitHub Issue的“自动化研发员工”(如SWE-agent、OpenHands)。它们能够自主拉取代码、阅读报错、在本地沙盒中不断试错并最终提交Pull Request。在这个过程中,沙盒、测试框架和Git版本控制就是它们的脚手架。
GUI/操作系统智能体(GUI/OS Agents)
桌面或手机屏幕上的点击操作,正在被转化为可执行的代码脚本(如Playwright脚本或DOM树操作)。智能体通过阅读屏幕的HTML结构或无障碍树(Accessibility Tree)来感知环境,输出Python代码来执行点击和滑动。UI界面变成了被代码操控的世界。
科学发现(Scientific Discovery)
在自动化实验室中,科研流程被整合成了一条无缝衔接的“代码流水线”。从文献检索、提出假设,到编写Python仿真程序、控制真实的液体处理机器人进行化学合成,再到处理实验数据,代码贯穿了科研的每一个环节(如AI Scientist系统)。
个性化推荐引擎(Personalization)
智能体能够根据用户的实时反馈,自动编写和修改推荐系统的策略代码,并将用户的偏好沉淀为可被程序读取的持久化状态对象。
具身智能体(Embodied Agents)
在机器人领域,抽象的行动意图被转化为带有运动学参数的可执行控制代码。代码充当了安全边界,确保机器人的动作(如机械臂抓取)符合物理定律,并在进入真实物理世界前在仿真器代码中完成排雷。
亟待解决的挑战与开放问题
尽管前景广阔,研究者也清醒地指出了该领域目前面临的几大核心挑战:
评测指标的瓶颈(Evaluation Beyond Final Success):目前的评测大多只看“测试用例是否通过”。但这无法区分智能体是写出了优雅的高质量代码,还是仅仅用一堆补丁“糊弄”过了测试却破坏了原有的系统架构。我们需要更深度的语义和架构级别的评测。
不完整的执行反馈(Verification Under Incomplete Feedback):有时候代码能够运行,但可能存在安全漏洞或性能隐患。目前的验证器在处理这类非功能性需求时依然非常薄弱。
无倒退的自我进化(Regression-Free Evolution):当系统尝试自动修改脚手架或重构代码时,极其容易陷入“灾难性遗忘”,修复了一个旧Bug,却引入了十个新Bug。
多智能体并发的语义冲突(Semantic Conflict Resolution):当多个智能体同时修改同一个代码库的不同部分时,如何解决它们在底层业务逻辑上的隐式冲突?目前的文本合并工具(如Git merge)无法解决深层的逻辑断裂。
安全问责与人类监督(Human-in-the-Loop Safety):当代码智能体获得直接操作生产环境、甚至是物理设备的权限时,我们必须建立坚不可摧的拦截机制,确保人类对高危操作拥有绝对的否决权。
结语
这篇论文为AI领域提供了一张极其清晰且具有历史意义的“智能体系统工程蓝图”。
想要让AI真正走向复杂的真实世界,绝不能仅仅依靠大模型自身算力的提升。必须将“代码”作为系统的骨架、神经和肌肉。 大模型提供了强大的“大脑”,而基于代码构建的智能体脚手架(Agent Harness),则赋予了这颗大脑以稳固的沙盒、真实的物理反馈、可靠的记忆机制以及多角色协同的组织法则。只有深深植根于这套“可执行、可检查、状态化”的代码基底之中,AI智能体才能真正从演示级的玩具,蜕变为工业级的可靠生产力。
未来已来,有缘一起同行!
<本文完结>
-
转载请与本喵联系,私自抓取转载将被起诉