
将成功或失败的经验提取为结构化的“技能”(Skills),并实现技能生产的自动化,似乎已经成了当下各大先进Agent框架的标配。从集成Claude Code到Codex执行环境,让智能体“吃一堑长一智”并自动撰写操作指南,听起来是一条完美的自我进化之路。但这套模式真的有用吗?Agent自己写的Skills,真的能让Agent自己变得更厉害吗?
一周前来自复旦大学、微软研究院和上海交通大学的研究团队联合发表了一篇题为《从原始经验到技能消费:模型自动生成智能体技能的系统性研究》(From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills)的重磅论文。

这篇研究探讨的根本不是“如何把技能文本写得更像样”,而是用实证数据系统评估:从原始执行轨迹中自动生成的技能,到底能不能真实提高Agent表现?什么时候会起效?又为什么会在不知不觉中毁掉系统的稳定性?更重要的是,研究者们通过深度剖析,找到了将这些诊断发现反过来直接改进技能生成过程的科学路径。如果您正在构建真正的智能体系统,这篇文章揭示的底层逻辑将帮您避开无数深坑。
技能生命周期的三阶段形式化建模
为了彻底厘清自动技能生成技术的核心机理,研究者对智能体技能的全生命周期进行了严格的形式化定义,将其解构为三个连续的动态阶段。
 论文将从轨迹到技能的完整生命周期拆成经验生成、技能提取和技能消费三阶段,并在每一阶段分析影响技能效用的关键因素。
论文将从轨迹到技能的完整生命周期拆成经验生成、技能提取和技能消费三阶段,并在每一阶段分析影响技能效用的关键因素。
阶段一:经验生成
第一阶段的核心任务是为技能提取准备原始的素材。
在一个特定的任务领域
 中,让目标模型
中,让目标模型 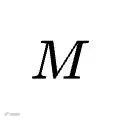 去执行训练集
去执行训练集  中的各项任务。
中的各项任务。-
在这个高强度的交互过程中,系统会完整地记录下智能体的所有执行轨迹。 最终这些交互记录会被汇聚成一个经验池
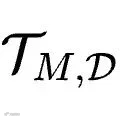 ,其中既包含了任务成功的完美轨迹,也包含了遭遇失败的错误轨迹。
,其中既包含了任务成功的完美轨迹,也包含了遭遇失败的错误轨迹。
阶段二:技能提取
第二阶段是将原始的、杂乱的交互日志转化为高度浓缩的显性知识。
此时会引入一个提取器模型
 (可以与目标模型相同,也可以不同)。
(可以与目标模型相同,也可以不同)。提取器
 会对经验池进行深度挖掘,最终产出一个在预算约束下、符合固定Schema的特定领域技能集合
会对经验池进行深度挖掘,最终产出一个在预算约束下、符合固定Schema的特定领域技能集合 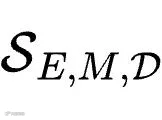 。
。
阶段三:技能消费
第三阶段是检验这些转化出来的显性知识能否在实战中发挥价值。
系统会将提取出的技能集合
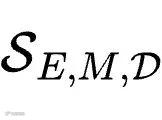 重新提供给最初的目标模型
重新提供给最初的目标模型 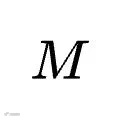 。
。随后让
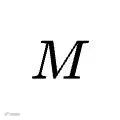 在该领域从未见过的测试集
在该领域从未见过的测试集  上去解答新任务。
上去解答新任务。通过测量智能体在有无技能辅助下的性能变化
 ,来作为评判该技能真实实用效用的硬性代理指标。
,来作为评判该技能真实实用效用的硬性代理指标。
去工程化的极简提取框架
为了确保实验得出的性能差异完全由提取器模型自身的能力决定,而不是靠复杂的代码工程脚手架粉饰出来的结果,研究者刻意采用了一个结构极简的提取框架。该框架不包含任何针对特定领域的启发式规则或复杂的过滤机制,其演进过程严格拆解为两步:
单轨迹分析(Per-trajectory analysis):提取器
 以完全并行化的方式独立处理经验池中的每条轨迹
以完全并行化的方式独立处理经验池中的每条轨迹 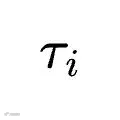 。针对单条轨迹,它被要求最多提取出
。针对单条轨迹,它被要求最多提取出  个行为模式。如果该轨迹最终成功,则重点提炼其成功策略;如果最终失败,则深度解构其错误模式和潜在陷阱。
个行为模式。如果该轨迹最终成功,则重点提炼其成功策略;如果最终失败,则深度解构其错误模式和潜在陷阱。层级合并(Hierarchical consolidation):利用树状合并结构对提炼出的海量模式进行逐级削减。在合并过程中,设定一个配置组大小
 ,提取器模型会将
,提取器模型会将  个模式集放在一起进行去重、泛化抽象以及冲突调和,不断向上收敛,直到最后合并出单一且高浓缩度的模式集合。
个模式集放在一起进行去重、泛化抽象以及冲突调和,不断向上收敛,直到最后合并出单一且高浓缩度的模式集合。规范化的技能表示(Skill representation):最终输出的技能会严格遵循Agent Skills开放标准规范。每个技能包含五个核心字段:小写连字符形式的唯一名称(slug)、1到2句的适用场景描述(description)、Markdown格式的程序性核心操作指南(body),以及可选的参考文件和辅助脚本。
系统性评估的实验设计与多维矩阵
五大差异化任务领域详解
为了全面压测技能机制在不同行为表现形式下的表现,研究者精选了五个属性迥异的评准领域:
ALFWorld(具身规划):这类任务要求智能体在虚拟的家庭环境中进行探索,必须具备基础的物理常识,并能处理多步骤的长程环境规划。
Spreadsheet Bench(生产力软件):专注于电子表格自动化操作,智能体必须对复杂的表格进行结构检查、执行公式推理、数据过滤以及单元格值的精准编辑。
SWE-bench-Verified(软件工程):直接面对真实的GitHub开源仓库问题,要求智能体具备深度的代码库全局理解、故障精准定位以及高质量修复补丁的生成能力。
SEAL-0(网络搜索):要求智能体通过搜索引擎回答复杂问题,高度考验多跳推理能力、跨网页信息检索以及长文本证据的综合整理能力。
BFCL-v4(工具调用):选用其中的多轮对话子集,专门高强度考验智能体在长周期内选择正确函数、精准提取参数、动态匹配类型以及维持多轮状态机稳定的能力。
实验覆盖的模型家族
本项研究在模型的选择上涵盖了当前工业界和学术界极具代表性的三大模型家族,并兼顾了不同的参数量级:
GPT家族:包含了顶尖闭源模型GPT-5.4,以及高性价比的轻量级模型GPT-5.4-mini。
Gemini家族:包含了具备深度思考能力的Gemini-3.1-Pro,以及极速响应的Gemini-3.1-Flash-Lite。
Qwen家族:包含了强大的开源中坚力量Qwen3.5-35B,以及小体量的Qwen3.5-9B。
-
注:在初步实验中,研究者发现体量较小的Qwen3.5-9B模型由于指令遵循能力受限,无法稳定、规范地完成结构化的提取流程,因此在后续实验中仅让其作为技能的消费者(目标模型),而将其从提取器模型名单中剔除。
解耦效用的两大核心指标:EE与TE
在传统的黑盒评估中,人们常常分不清性能的提升到底是由于提取器聪明,还是由于目标模型本身好教。为了彻底打破这一迷雾,研究者通过数学公式明确定义并解耦了两个方向截然不同的核心效用指标:
提取效能(Extraction Efficacy, EE):
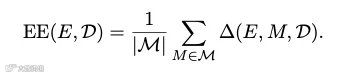
该指标固定提取器
 ,将其应用到所有目标模型生成的经验池上,计算下游平均表现的变化值。它用于精准回答:该提取器是否具备普适、稳定的知识提炼与转化能力。
,将其应用到所有目标模型生成的经验池上,计算下游平均表现的变化值。它用于精准回答:该提取器是否具备普适、稳定的知识提炼与转化能力。目标可进化性(Target Evolvability, TE):
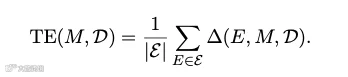
该指标固定目标模型
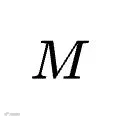 ,让其尝试所有不同提取器基于它自身日志提炼出的技能,计算其获得的平均下游净收益。它用于精准回答:该目标智能体是否容易通过技能辅助实现自进化,其吸收和执行外部显性指南的上限在哪里。
,让其尝试所有不同提取器基于它自身日志提炼出的技能,计算其获得的平均下游净收益。它用于精准回答:该目标智能体是否容易通过技能辅助实现自进化,其吸收和执行外部显性指南的上限在哪里。
核心实验结果:打破多项传统认知
经过大规模跨领域的矩阵交叉压测,研究者汇总得到了全景式的核心实验数据(详见下表数据摘要)。这些硬性的客观指标,直接粉碎了多项过去想当然的行业常识。
普遍增益下的负迁移退化分布
整体来看,模型生成的技能在75% 的矩阵实验条目中都带来了正向的下游性能增长,证明了这一方向的总体可行性。然而,依然有高达25% 的条目落入了负迁移(Negative Transfer)的红色区间,即引入技能后性能反而退化。
下表详细罗列了五大领域在无技能基线(Base)下,不同目标模型注入技能后的代表性表现delta(以百分点pp计):
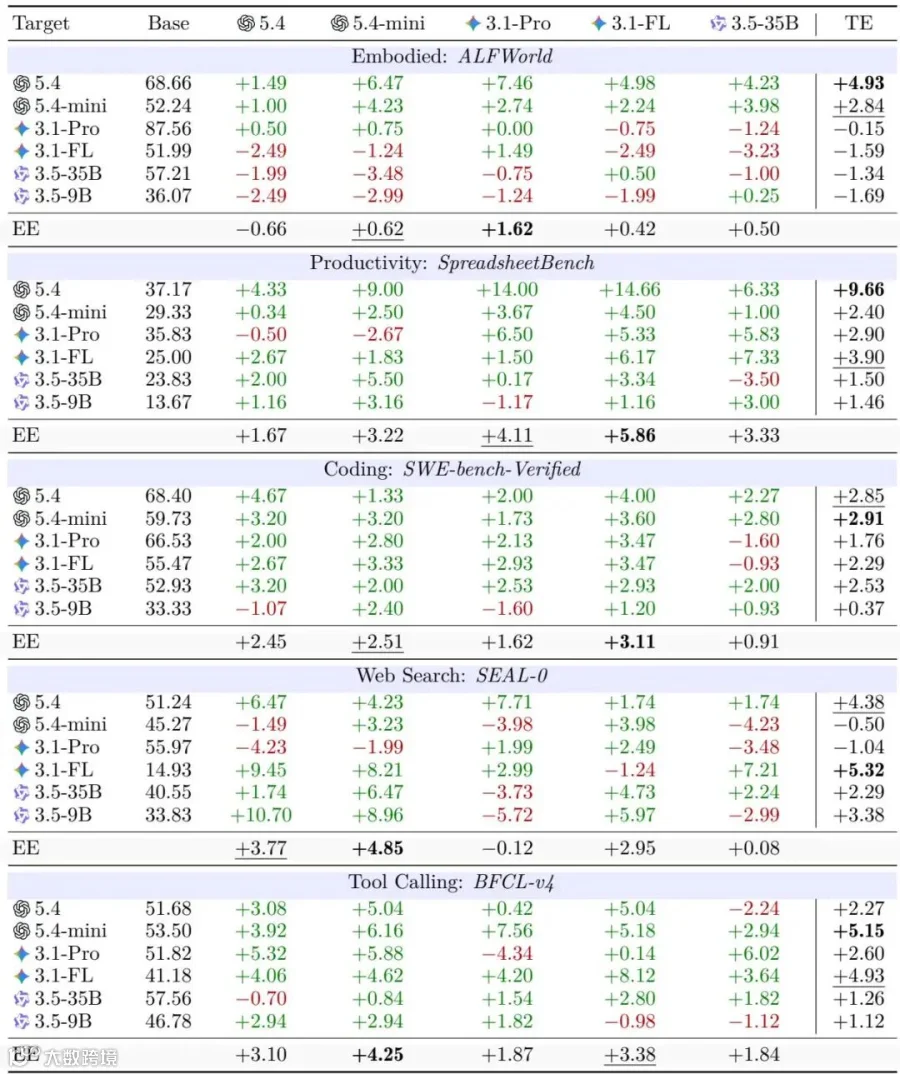 Base为无技能基线,TE表示目标可进化性,EE表示提取效能;原表用绿色和红色分别标记正向增益与负迁移。
Base为无技能基线,TE表示目标可进化性,EE表示提取效能;原表用绿色和红色分别标记正向增益与负迁移。
从上表数据可以清晰地看出,负迁移的分布具有极其强烈的领域依赖性。 Spreadsheet Bench表现得相对坚固,而ALFWorld则极为脆弱,将近一半的尝试(47%)都引发了智能体的行为退化。
执行能力与提取能力的全面解耦
传统的直觉往往认为,谁在基线测试里得分最高、谁的参数体量最大,谁提取出的技能就一定最好。但实验数据无情地推翻了这一点。
-
在生产力工具(Spreadsheet Bench)任务中,GPT-5.4拥有最顶尖的单体解决问题能力。 -
然而,在计算整体提取效能(EE指标)时,轻量级的Gemini-3.1-Flash-Lite却高居榜首,而GPT-5.4甚至在部分实验中排名垫底。 -
这一事实说明,技能提取是一种与任务执行截然不同的独立能力 。提取器必须能够深刻理解目标模型的特定轨迹,并将其转化为目标模型能够实际利用的程序性指导 。因此,选择提取器并不是无脑选择最强的大模型,而是要考量提取器、目标模型与特定领域之间的兼容性
消费收益的目标依赖特性
哪怕面对文本内容完全一致的技能指南,不同的目标智能体在吃下这剂“药方”后的反应也截然相反。
-
如数据表所示,在具身智能ALFWorld领域中,当把同样的技能喂给不同的智能体时,GPT-5.4表现出极佳的吸收体质,在各个提取器的配置下都实现了稳定的正向进化(TE = +4.93)。 -
相反,Gemini-3.1-FL和Qwen3.5-9B在面对同样的显性指南时,平均可进化性却直接跌入负值区间。 -
这意味着,自动化技能能否产生实用效用,在本质上是一个典型的“提取器-目标消费者-应用领域”三方兼容性问题,参数规模并不能包治百病。
技能生命周期的逐阶段深度解构
为了挖出掩盖在平均数据之下的深层驱动因素,研究者对生命周期的三大阶段展开了彻底的白盒化定性与定量解剖。
经验pool的黄金比例:成功与失败谁更重要?
第一阶段交互日志的质量,直接决定了后续提取的知识上限。研究者通过控制变量法,固定提取器(GPT-5.4-mini),人为配制了五个成功率梯度(100%、75%、50%、25%、0%)的原始经验池进行压测。实验发现了强烈的领域分化特性:
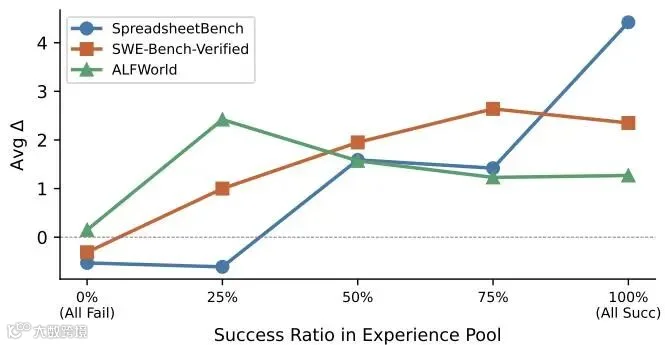 SpreadsheetBench更依赖高比例成功轨迹,SWE-bench-Verified在75% 成功率附近达到峰值,而ALFWorld更受失败轨迹暴露的环境约束影响。
SpreadsheetBench更依赖高比例成功轨迹,SWE-bench-Verified在75% 成功率附近达到峰值,而ALFWorld更受失败轨迹暴露的环境约束影响。
全失败池在所有领域全面垫底:实验显示,0% 成功(全失败)的经验池提取出来的技能在所有任务中得分最低,证明了成功轨迹中蕴含的正向动作边界是建立技能的根本基石。
电子表格领域偏爱纯成功样本:Spreadsheet Bench的最终效用曲线随着成功率的提升而稳步单调上扬,在100% 纯成功经验池下达到峰值。
具身交互领域呈现反常偏好:具身规划任务ALFWorld的最优技能竟然诞生在25% 成功(即75% 都是失败交互)的低纯度经验池中。
研究者对其进行深度分析后指出,具身环境充斥着大量的动作无效化和无法逆转的死胡同状态,在这些领域中,失败轨迹所暴露出的“负面边界约束”,其信息密度和实用价值远远超过了单纯一帆风顺的成功路径。
提取维度的误区:表面格式与合理性偏见
在第二阶段,究竟是什么因素决定了技能好不好用?研究者首先彻底打破了两个长期存在的常识性误区: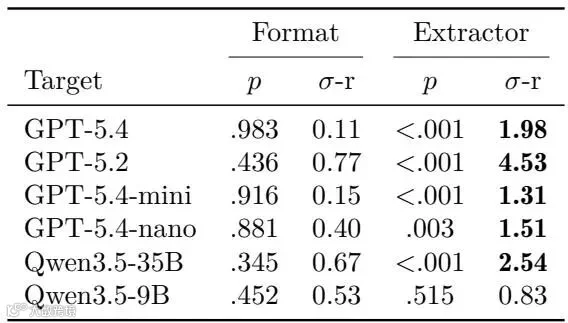 格式变化在所有目标模型上都不显著,而更换提取器在大多数目标上产生明显差异,说明技能内容比排版更关键。
格式变化在所有目标模型上都不显著,而更换提取器在大多数目标上产生明显差异,说明技能内容比排版更关键。
误区一:技能的文本排版和展现格式至关重要。研究者将Spreadsheet Bench的最强技能分别重写为有序步骤、无序列表、复选框和纯文本段落四种相互独立的排版格式。经过Friedman统计检验发现,这种格式的改变对下游任何一个消费者模型的最终得分都没有产生具有统计学意义的影响(所有
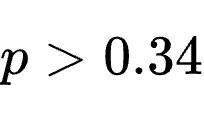 ),证明决定技能价值的是它“写了什么内容”,而绝非“套了什么格式”。
),证明决定技能价值的是它“写了什么内容”,而绝非“套了什么格式”。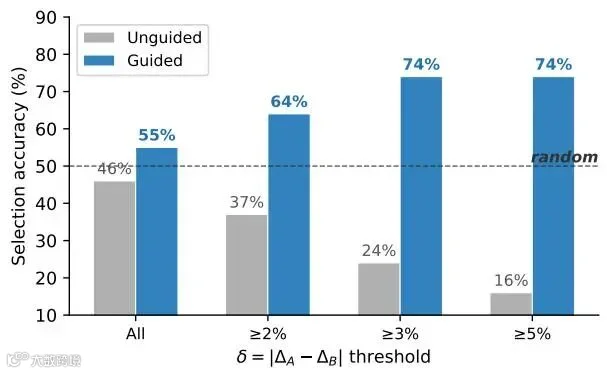 无引导的LLM裁判总体接近随机,且在性能差距更大的技能对上反而更容易选错;注入验证标准后准确率显著回升。
无引导的LLM裁判总体接近随机,且在性能差距更大的技能对上反而更容易选错;注入验证标准后准确率显著回升。误区二:大模型能够通过阅读技能文本轻松指出谁是好技能。研究者把151对在实战中表现差距明显的技能文本盲喂给GPT-5.4 Judge裁判,不给任何提示,让它纯靠文本语感挑选出它认为能在下游跑出高分的技能。结果极其惊人:LLM的综合挑选准确率仅为46.4%,与盲猜完全一样。
更具讽刺意味的是,当两个技能文本的实战差距拉得越大(性能delta
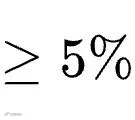 ),大模型盲审的选择准确率反而出现了灾难性的反转,直接暴跌到了15.8%。也就是说,大模型不加引导地进行人工评审时,往往会极度偏爱那些文字写得最漂亮、最流畅,但在实战中却最没有用处的“毒技能”。
),大模型盲审的选择准确率反而出现了灾难性的反转,直接暴跌到了15.8%。也就是说,大模型不加引导地进行人工评审时,往往会极度偏爱那些文字写得最漂亮、最流畅,但在实战中却最没有用处的“毒技能”。
核心特征的定性对比:具体治疗方案vs抽象过程指南
通过对高差距技能对的文本进行深入的定性解剖,研究者揭示了优秀技能与无用技能之间的分水岭: 论文进一步指出,高收益技能覆盖了公式注入、删除迭代顺序和坐标硬编码等具体故障模式。
论文进一步指出,高收益技能覆盖了公式注入、删除迭代顺序和坐标硬编码等具体故障模式。
高收益技能(由Gemini-3.1-FL提取,下游跑出 +14.7 pp):通篇不讲半句过程正确的空话,而是精准打击具体的环境底层软肋。例如它直接警告:“不要依赖宿主引擎去计算公式,在无头(Headless)执行环境中公式写入是不会触发计算的,必须使用Python计算出静态Scalar标量值再执行强行写回。” 同时针对元素删除,直接给出逆向迭代(reverse iteration)的清晰操作解。
低收益技能(由GPT-5.4提取,下游仅有 +4.3 pp):行文极度符合人类的审美习惯,但写满了政治正确却无法落地的宏观建议。诸如“在编码前先明确合同交付边界”、“尽可能minimally安全地编辑”、“保持敏捷开发并分阶段演进工作”。这些陈述在遭遇Spreadsheet Bench具体的执行层错误时,无法给智能体提供任何实质性的破局杠杆。
消费维度的真相:策略重塑而非简单动作调用
在第三阶段,技能到底是怎么改变智能体行为的?轨迹行为学分析表明,技能注入并没有像人类编写代码模块那样,让智能体在特定步骤显式地去发起新技能的工具调用。
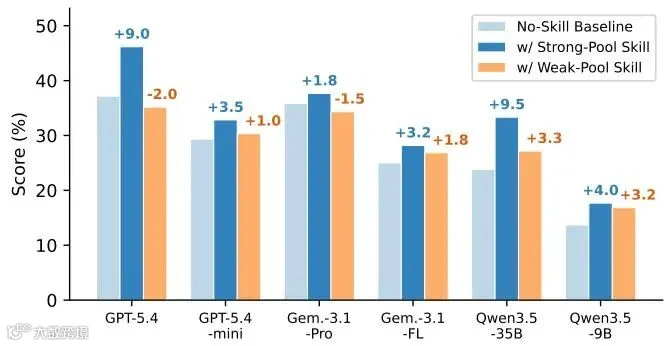 同一段强池/弱池技能被注入到不同目标模型后,收益跨度很大,说明消费能力本身也是模型属性。
同一段强池/弱池技能被注入到不同目标模型后,收益跨度很大,说明消费能力本身也是模型属性。
技能的真实消费机制是:它们在无形中彻底重塑了智能体的“默认行为策略(Default Policy)”。
决策行为轴线:对于强模型GPT-5.4,技能重塑了它的任务世界观,使其策略大范围从直接写Excel公式修正为“用Python算干干净净的Scalar值再写回”,从而在单元格任务中大幅度绕开了公式未激活的致命陷阱。
探索与工具行为轴线:对于弱模型Qwen3.5-9B,技能的注入成功诱导它放弃了简单粗暴的pandas全表重写逻辑,策略性地转向了更高级的openpyxl原生工作流。但这大幅度拉长并加剧了其底层的推理复杂度,使其在微观执行层面更容易由于上下文过长而发生动作变形,最终导致了结构对了、结果却错了的负迁移退化。
从诊断到干预:元技能引导的提取优化
既然发现了大模型在盲审技能时存在严重的“表面合理性偏见”,并且明确了有用技能的qualitative特征,那么这些定性诊断能否直接转化为硬性的自动化改进技术?
自动化标准发现管线的构建
研究者为此精心设计了一条完全自动化的标准发现管线(Discovery Pipeline)。该管线以矩阵实验中所有产生高分化差距的技能对作为原始输入,让GPT-5.4扮演高级分析师,多轮迭代合并出高分技能在本质上究竟做对了什么。通过对最终各个candidate维度的真实下游utility进行关联匹配测试,计算每个维度的“实用对齐胜率(Better-rate)”。
 直接向模型询问得到的标准主要关注清晰、完整、简洁、格式和语气等表面特征。
直接向模型询问得到的标准主要关注清晰、完整、简洁、格式和语气等表面特征。
三维实用验证标准的诞生
通过对大量候选特征的严格筛选,研究者最终确立了三个与下游最终得分具有极强因果正相关性的核心实用维度,它们共同组成了“实用验证标准(Validated Rubric)”:

失败机制编码(Failure Mechanism Encoding,胜率65.5%):要求技能必须清晰标明智能体过去遭遇失败的底层机械机理,绝对不能只给出空泛的对错统计,要说清“为什么会挂”。
可执行的特异性(Actionable Specificity,胜率66.0%):技能必须提供步骤级别的具体处置流程,并且这些流程必须能够明确映射到具体的应用工具、API对象或物理域数据实体上。
高危动作黑名单(High-Risk Action Blacklist,胜率64.6%):必须包含明确的、斩钉截铁的强约束指令,严厉禁止智能体去尝试那些高概率导致环境发生不可逆崩溃或死锁的行为模式。
元技能提示词注入与全矩阵优化结果
研究者将这套经过实战验证的3维实用标准直接浓缩打包成一段通用的高阶提取先验,在学术上定义为“元技能(Meta-Skill)”。在技能提取阶段,它作为一个纯粹的drop-in组件,直接被追加在提取器模型的系统提示词末尾,去指导每一步的单轨迹分析和最后的层级合并。
下表详细展示了在三大核心领域中,不使用技能、使用传统“朴素合理性提示词(Plausibility Guide)”以及注入“实用元技能提示词(Validated Meta-Skill)”后,智能体最终的任务解决准确率(%)对比:
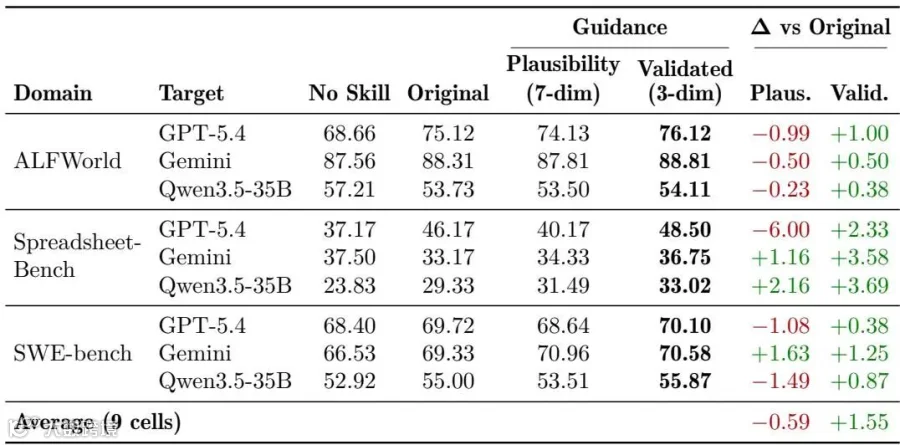 Validated Rubric在九个测试格子里全部相对原始技能取得正向增益,而未筛选的Plausibility Rubric平均为负。
Validated Rubric在九个测试格子里全部相对原始技能取得正向增益,而未筛选的Plausibility Rubric平均为负。
实验数据揭示了两个核心事实:
传统的人类常识提示词会帮倒忙:如果直接让模型遵循传统的清晰、简洁、逻辑结构等7维常规指标进行技能提取,最终的平均表现反而下降了0.59 pp,在9个格子中有6个引发了倒退。这是因为这些常识会迫使模型花大量字符去润色行文,从而挤占并稀释了真正高密度的硬核硬技术信息。
实用元技能实现了全矩阵无死角的完美逆袭:注入3维实用元技能后,在所有被测的9个格子中全部实现了100% 的净正向增长,平均净增幅达到1.55 pp,在电子表格领域甚至直接跑出了最高 +3.69 pp的大额增益。整个过程不需要改动底层的任何一行提取框架代码,展现了极强的通用工业部署价值。
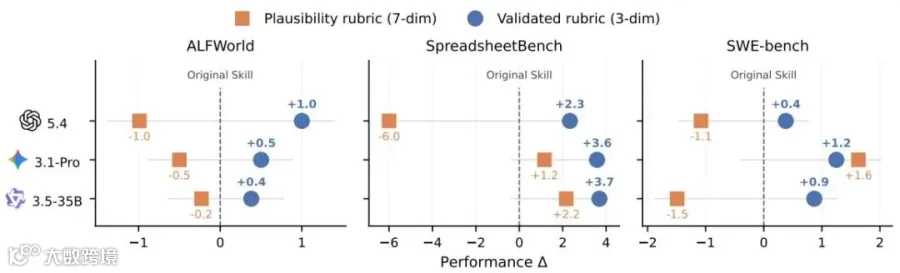 朴素合理性标准多数情况下稀释有效信息;经验证的三维标准在所有生成技能上都优于原始提示。
朴素合理性标准多数情况下稀释有效信息;经验证的三维标准在所有生成技能上都优于原始提示。
扩展验证与超参数分析
替代性Harness环境验证
为了严谨排除上述结果只是某一套特定Python脚本测试框架下的“特异性偶发现象”,研究者引入了两个完全不同的交互式主流智能体运行脚手架,Claude Code和Codex运行环境进行高强度交叉检验。
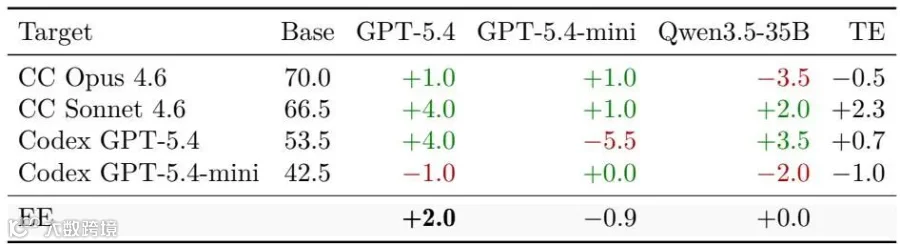 表10:替代交互式脚手架下仍能观察到技能带来的平均正收益,说明结论不是单一评测脚本的偶发现象。
表10:替代交互式脚手架下仍能观察到技能带来的平均正收益,说明结论不是单一评测脚本的偶发现象。
在这些采用完全动态交互工具流的替代性Harness环境中,实验再次精确复现了核心结论:技能注入在全模型下保持了 +0.4 pp的平均稳定增益,且顶尖模型(如CC Opus 4.6、Codex GPT-5.4)对技能的吸收和转化效能显著超越轻量级目标模型,进一步夯实了消费能力梯度理论的牢固性。
默认提取超参数与计算开销
本项大型系统性研究得以稳健运行,其底层的核心工艺超参数配置如下:
-
单条轨迹允许榨取的最大行为模式上限(Max modes per trajectory):3 树状层级削减时设定的单批处理组大小(Merge group size
 ):10
):10-
单个提炼出的技能文档最大允许字符约束(Max skill characters):3000字 -
每次经验池提炼最终压缩保留的核心领域技能上限(Max skills per extraction):1 -
提取时模型的推理采样温度(Temperature):1.0
 研究默认使用的每轨迹最多3个模式、合并组大小10、单技能字符上限3000等关键超参数;同页还给出多技能文本工具协议模板。
研究默认使用的每轨迹最多3个模式、合并组大小10、单技能字符上限3000等关键超参数;同页还给出多技能文本工具协议模板。
在计算资源消耗层面,本研究所涉及的所有商业闭源模型均通过官方Azure OpenAI API和Google Gemini API进行并发调用,并将核心模型的推理思考深度(reasoning_effort / thinking_level)统一设定为中等(medium)。所有的开源中坚模型(Qwen3.5-35B等)则统一部署在一个配备了8张NVIDIA B200显卡的专用算力节点上,利用高并发的vLLM推理引擎进行本地私有化服务部署,从而完美保障了在大规模矩阵级交叉压测下的极低时延与强数据一致性。
结论
基于这项研究的深刻洞见,以后您再让 Agent 自己写 Skills 时,完全可以直接把微软提炼出的这项“3 维度基准”作为元提示词(Meta-prompt)甩给它。让Agent在生成后强制进行对照自查,就可以极其有效且低成本地筛除掉那些行文流畅、但实际上会导致下游性能大面积退化的“毒技能”。这样做能够为您节省下海量由于无头苍蝇式乱撞而浪费的无效计算资源,同时从根本上防止您的智能体系统在无声无息的迭代中默默崩溃。对于所有致力于打造高可用Agent框架的工程师而言,这无疑是当下最务实的避坑指南
未来已来,有缘一起同行!
<本文完结>
-
转载请与本喵联系,私自抓取转载将被起诉