
你以为AI编程模型的天花板是Claude和GPT?开源社区刚刚甩出一张王牌。
一个危险的信号
就在昨天,一个名为Ornith-1.0的开源模型悄然发布。它的名字来自"ornith"——鸟纲,古老而自由的生命形式。

但它做的事情,却一点古老都没有。
Ornith-1.0是一个真正"自进化"的编程AI模型。
这意味着什么?意味着它不是被人类"训练"出来的,而是自己教自己如何更好地编程。
你以为这是又一个开源套壳?实际是核弹
看一组数据:
| 模型 | SWE-bench Verified | Terminal-Bench 2.1 |
|---|---|---|
| Ornith-1.0-397B | 82.4 | 77.5 |
| Claude Opus 4.8 | 80.6 | 69.7 |
| Claude Opus 4.7 | 87.6 | 78.9 |
| DeepSeek-V4-Pro | 80.8 | 64 |
注意,Claude 4.8在这个榜单上甚至没有出现在Ornith-1.0前面。
Ornith-1.0-397B在SWE-bench Verified(软件工程真实任务)上达到82.4分——这是目前开源模型从未触及的高度。
而且,它完全开源,MIT许可证,没有任何地区限制。
自进化:AI的"元学习"突破
Ornith-1.0的核心创新不是模型架构,而是一种全新的训练范式——自改进训练框架。

传统的AI编程模型是这样被训练出来的:
- 1. 人类写出代码示例
- 2. AI学习这些示例
- 3. 等待人类反馈"这个答案对不对"
Ornith-1.0的做法是:
- 1. 让模型自己生成解决方案
- 2. 让模型同时生成驱动这些方案的"scaffold"(脚手架)
- 3. 通过强化学习联合优化scaffold和解决方案
- 4. 模型自动发现更好的搜索轨迹
换句话说,它不是被告知"正确答案是什么",而是自己去探索"用什么方法能找到正确答案"。
这在AI领域叫做元学习(Meta-Learning)——学习如何学习。
打破闭源垄断的第三股力量
过去两年,AI编程领域呈现双寡头格局:
- • OpenAI:GPT-4系列
- • Anthropic:Claude系列
两者都是闭源模型,用户必须付费、让渡数据、接受使用限制。
开源社区尝试过各种"平替":CodeLlama、Qwen、DeepSeek——但始终棋差一着。
Ornith-1.0的意义不在于"又有一个开源模型",而在于它证明了一条不同的技术路线可能走通:
- • 用更聪明的训练方法(自进化)
- • 用更大的模型规模(397B MoE)
- • 用更开放的生态(MIT许可证)
这三条路线组合在一起,给闭源模型敲响了警钟。
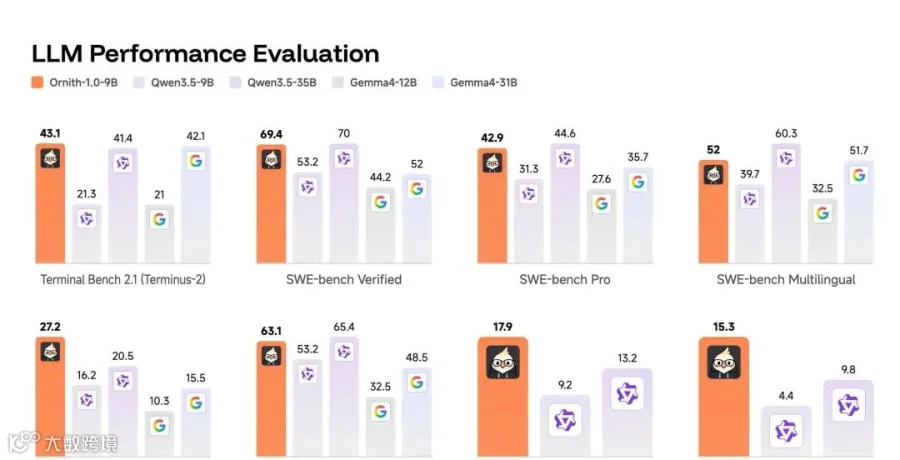
真实的应用场景
Ornith-1.0可以做什么?
- • Terminal任务:在真实Linux环境中执行命令、调试问题
- • SWE-bench:修复真实GitHub issue中的bug
- • NL2Repo:根据自然语言描述查找代码库
- • 多语言编码:支持Python、JavaScript、Go、Rust等主流语言
而且它完全可以在本地部署——不需要把代码发送给任何第三方。
更大的棋局
Ornith-1.0背后是一个叫做Deep Reinforce AI的组织。
这个组织鲜少公开露面,但他们的技术路线值得关注:
- 1. 基于Gemma 4和Qwen 3.5进行post-training
- 2. 构建了自研的强化学习训练框架
- 3. 一口气发布4个规模的模型:9B、31B、35B、397B
这种"小步快跑+突然放大"的发布策略,像极了几年前的另一个故事——那个叫OpenAI的组织,早期也是先在GitHub上悄悄发了一些不起眼的模型,然后突然祭出GPT-3。
写在最后
Ornith-1.0的出现,是一个信号:开源AI编程模型正在跨越闭源模型的护城河。
护城河不是模型架构,不是训练数据,而是训练范式的创新。
当闭源模型还在靠"更大更贵"维持优势时,开源社区已经找到了新的进攻角度——让AI自己教自己。
这不是终点,而是开始。
参考资料:Ornith-1.0 GitHub仓库、HuggingFace模型卡、相关论文
作者:AI前哨 | 比99%的人先看到AI的下一步