
当系统崩溃时,你只有一台服务器、一堆日志和一颗即将爆炸的头。这时候,一个能在 15 分钟内给出根因报告的Agent,比三个资深专家更有用。
一、OS 故障诊断这件事,为什么这么难?
任何一个管过生产系统的人都经历过:半夜三点,服务器挂了,老板在群里问进度,你盯着几十GB的日志、vmcore dump和内核堆栈手足无措。
这不是运维能力的问题。是操作系统故障诊断这个任务本身就很变态。它有几个绕不过去的硬伤:
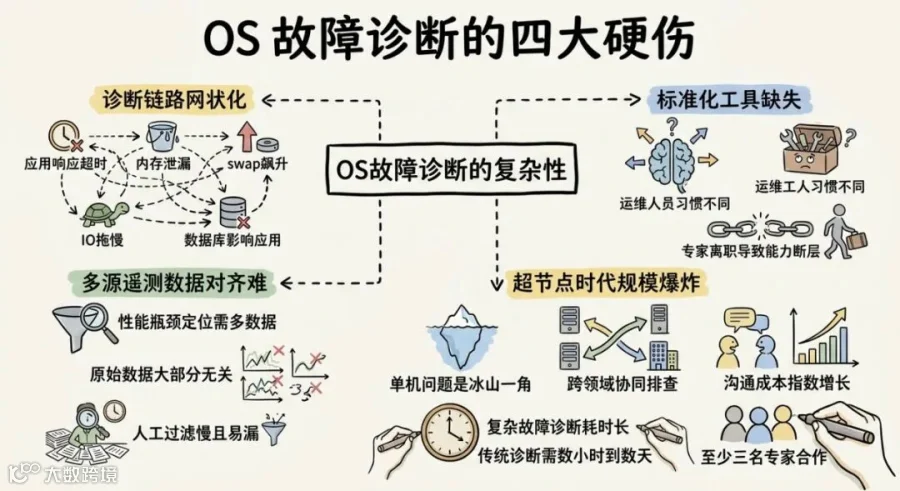
第一,诊断链路是网状的。 一个应用响应超时,可能是内存泄漏导致swap飙升,swap又拖慢了IO,IO拖慢了数据库,数据库拖慢了应用。内核、硬件、系统服务、网络,每层都可能先出问题,但每层也都可以是被上游波及的受害者。没有深厚的人肉经验积累,排查方向很容易跑偏。
第二,标准化工具和流程长期缺失。 不同运维人员的排查习惯完全不同。有人先看top,有人直接打开vmcore用crash 工具分析,有人先翻dmesg。知识在脑子里,不在系统里。资深专家一旦离职,整个团队的故障诊断能力出现断层。这不是个别现象,是行业的通病。
第三,多源遥测数据的对齐成本极高。 定位一个性能瓶颈可能要同时看perf采样数据、系统日志、内核 tracepoint 事件。这些数据的时间戳不是天然对齐的,语义也各说各话。原始数据里 90% 跟当前故障无关,人工过滤和关联分析又慢又容易漏掉关键线索。
第四,超节点时代规模爆炸。 算力从单机到集群到超节点,单台服务器的问题可能只是冰山一角。跨内核、网络、存储、AI 框架的协同排查需要拉通多个领域专家,沟通成本呈指数增长。
这四个问题叠加在一起的结果是:一次典型的复杂 OS 故障,传统人工诊断需要几小时到几天,至少 3 名不同领域的专家配合。 而且全程高度依赖个人经验,质量和效率都不稳定。
二、智能诊断Agent:一个「假设-验证」多Agent协作系统
openEuler社区的 sig-intelligence小组给出了一个解法:智能诊断Agent(Witty)。
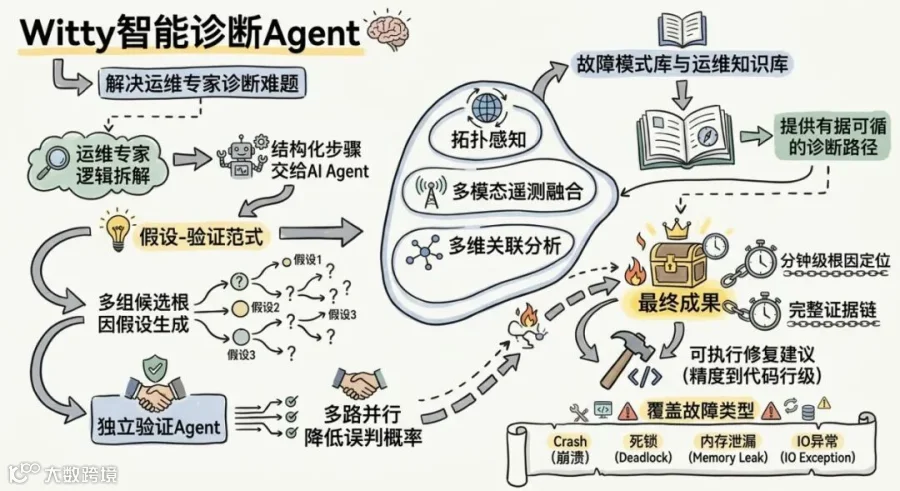
它做的事情不复杂:把运维专家的诊断逻辑拆成四个结构化步骤,交给多个AI Agent并行执行。
具体来说,Witty的工作方式像一个诊断团队在并行开会。它采用医学诊断里那种「假设-验证」范式(Hypothetico-Deductive):面对一个故障,不沿着一条线索死磕,而是同时生成多组候选根因假设,每条假设派一路Agent独立验证。多路并行压低了单路误判把全局带偏的概率。
数据层面,Agent调用工具层拉通拓扑感知、多模态遥测融合和多维关联分析三件事:知道系统各组件之间的依赖拓扑,能把日志、指标、堆栈、内核事件等异构数据拉到同一个时间面上对齐,再跨数据源做交叉关联。不是为了好看,是为了追踪因果链条。openEuler专属的故障模式库和运维知识库则告诉Agent类似的问题历史上是怎么排查的,让诊断路径有据可循。
整个流程跑完,系统自动输出一份结构化报告,里面是分钟级的根因定位、完整的故障溯源路径、支撑结论的证据链和可执行的修复建议。定位精度到代码行级。覆盖范围包括系统Crash、死锁、内存泄漏、IO异常这些最常见的棘手问题。
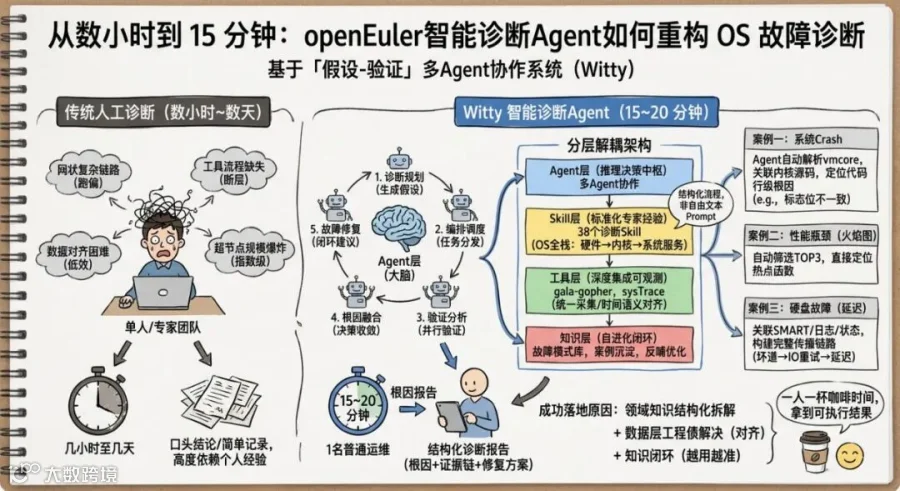
2.1 整体架构:四层解耦
Witty采用分层解耦架构,分为 Agent层、Skill层、工具层、知识层四大模块,各层之间通过标准化接口通信:
-
• Agent层:多Agent协同的推理引擎和决策中枢,这是系统的大脑。 -
• Skill层:专家经验的标准化载体,不是自由文本提示词,而是包含诊断步骤、判断条件和执行策略的可执行流程。目前已支持的 38个诊断Skill(用户态14、内核15、硬件9)覆盖了系统崩溃、死锁、内存泄漏、IO异常、进程阻塞等复杂故障场景,按OS全栈(硬件层 → 内核层 → 系统服务层)分层构建。 -
• 工具层:深度集成openEuler的内核可观测工具(gala-gopher、sysTrace等),以低侵入、低底噪方式统一完成指标、日志、内核信息等多维度遥测数据的采集,同时对原始数据进行时间与语义对齐,过滤冗余噪声,为上层推理提供高质量数据输入。 -
• 知识层:存储openEuler专属故障模式库、诊断案例和因果关系规则。系统自动沉淀每次诊断的全链路数据与最终结果,将其转化为可复用的标准化案例,持续反哺Skill逻辑优化,实现越用越精准的自进化。
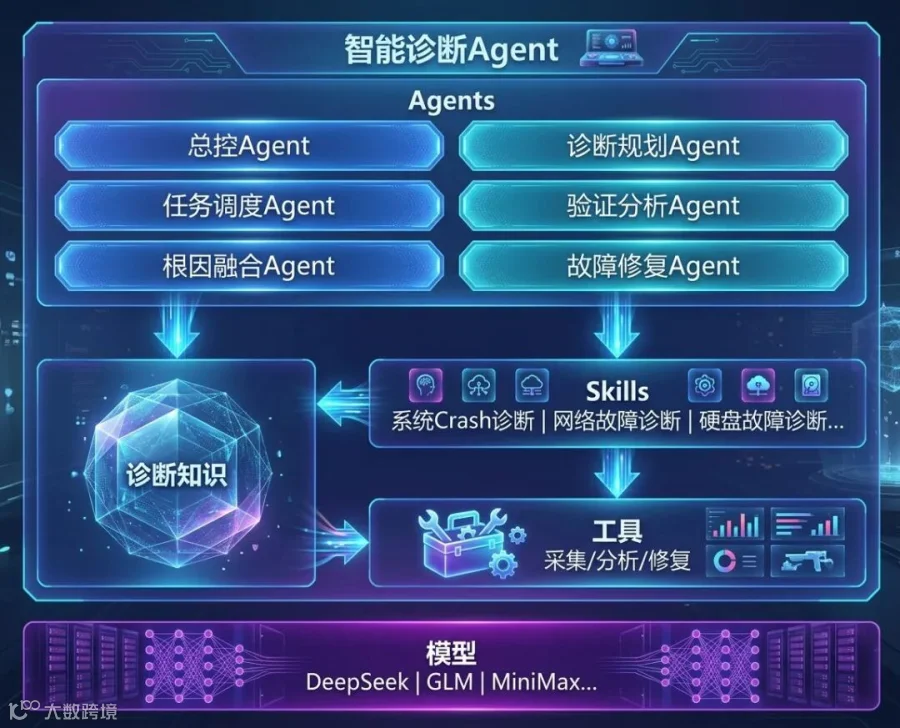
2.2 Agent层内部:五个角色的精密协作
Agent层是大脑。Witty采用了类似医疗诊断的 「假设-验证」范式(Hypothetico-Deductive):
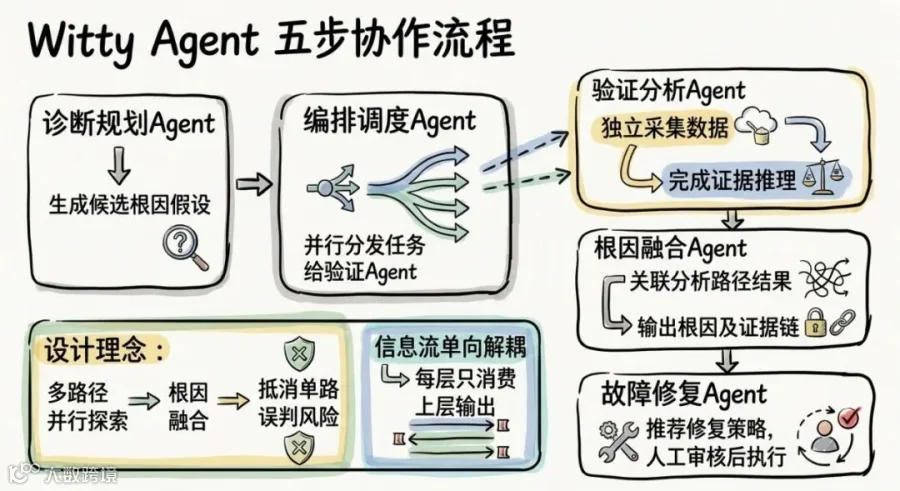
第一步:诊断规划Agent → 生成根因假设。 接到故障报告后,诊断规划Agent通过多轮交互明确故障范围,依托故障模式库同时生成多组候选根因假设,而不是线性地一条路排查到底。
第二步:编排调度Agent → 任务分发。 为每一组假设匹配对应的诊断Skill,将任务并行下发至多个验证分析Agent。不同假设各自独立验证,互不阻塞。
第三步:验证分析Agent → 多路径并行验证。 每个验证分析Agent按Skill规定的诊断流程,调用工具层采集相关遥测数据,完成证据推理。系统崩溃看vmcore 和内核堆栈,性能问题跑perf采样和火焰图分析,硬盘故障查 SMART 参数和运行日志。
第四步:根因融合Agent → 决策收敛。 多条诊断路径的结果汇总到根因融合Agent。它做的是关联分析:哪些证据链互相印证?哪条假设被数据证伪?最终输出的不是模糊的猜测,而是一份包含根因定位、完整证据链和可执行修复方案的结构化诊断报告。
第五步:故障修复Agent → 诊断-修复闭环。 衔接诊断结果,在系统安全规则约束下推荐适配openEuler的修复策略,经人工审核后受控执行。
这整条链路的设计理念:不依赖单一路径的正确性,而是通过多路径并行探索 + 根因融合来抵消单路误判的风险。 五个Agent之间的信息流是单向的:诊断规划把假设往下传,编排调度把任务分发出去,验证分析各自独立产出子报告,根因融合做关联收敛,每一层只消费上一层的输出,不反向干扰。这种解耦让每个Agent的角色边界清晰,出问题时容易定位是哪一环节出了问题。整条链路的输入是故障现象描述和相关文件路径,输出是一份有根因、有证据、有修复方案的完整诊断报告。
三、三个实战案例,看清差距
架构说再多,不如看实际效果。以下是Witty在openEuler生产环境中的三个真实案例。
案例一:系统Crash故障诊断
故障现象:系统发生crash,vmcore dump已生成。
传统方式:运维人员拿到vmcore文件后,用crash工具加载分析,逐一检查寄存器状态、进程链表、内存分配情况。运气好能在一两小时内定位到那个导致panic的代码行;运气不好得反复拿新的vmcore比对,拉内核专家介入,拖上好几天。
Witty方式:运维人员只需要输入:
"系统发生了crash,vmcore相关文件和内核源码归档在 /opt/vmcore_file 目录下,请分析原因。"
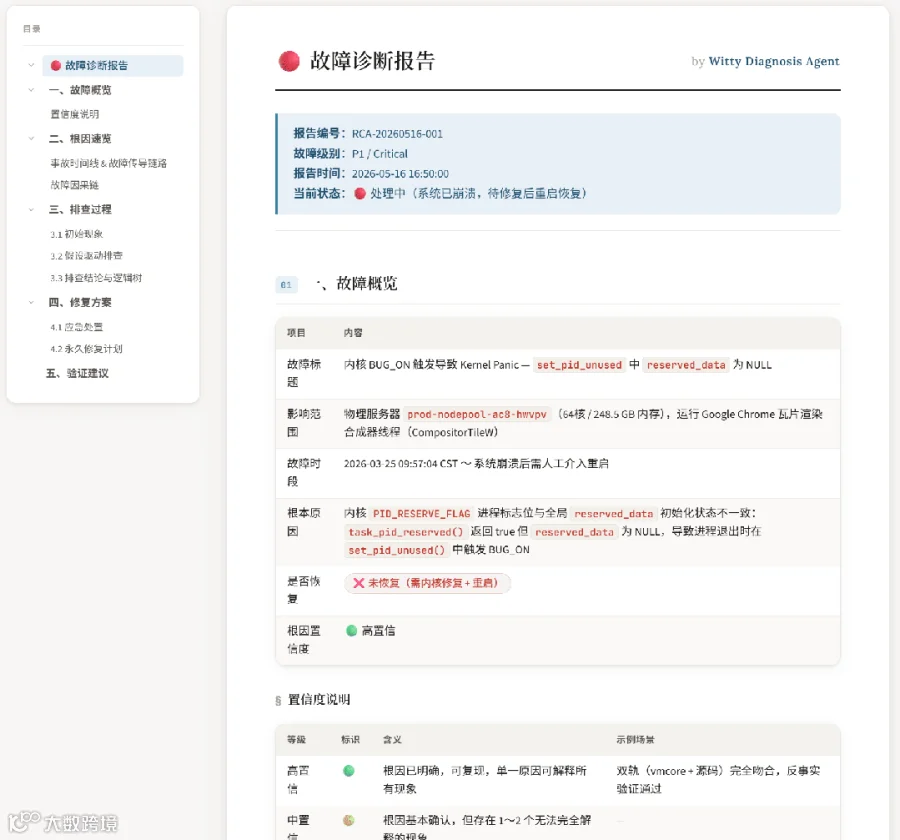
Agent自动解析vmcore文件、关联内核源码,定位到异常模块、问题函数和代码行级的根因。以一次实际案例为例,Agent发现了进程标志位与全局reserved_data初始化状态不一致导致的崩溃。这类问题如果不熟悉该模块的代码逻辑,人工排查极难定位。
效率差距:
|
|
|
|
|---|---|---|
|
|
|
15~20 分钟 |
|
|
|
1 名普通运维 |
|
|
|
结构化诊断报告 |
诊断界面:
诊断报告:
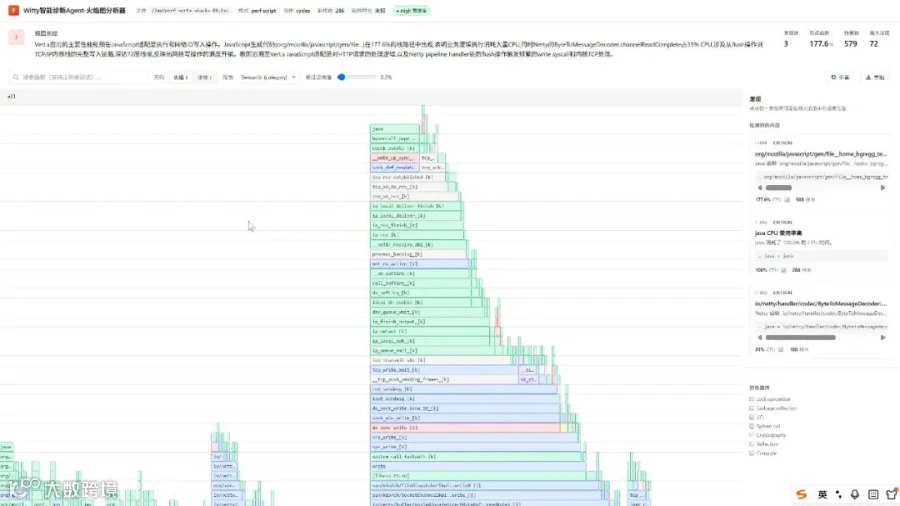
案例二:性能瓶颈分析
故障现象:应用CPU占用异常偏高。
运维人员输入perf采样文件路径后,Agent自动解析采样数据,筛选TOP3性能瓶颈,生成火焰图可视化报告,直接定位到热点函数。
诊断界面:
诊断报告:
案例三:硬盘故障诊断
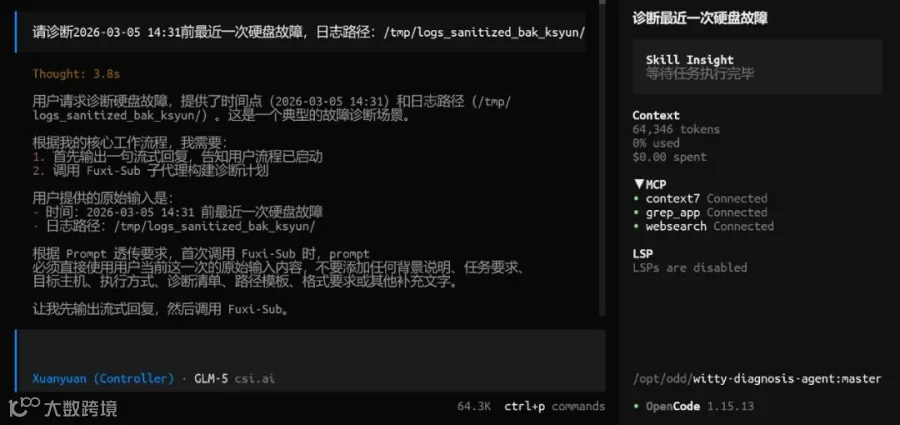
故障现象:存储响应延迟升高,怀疑有硬件问题。
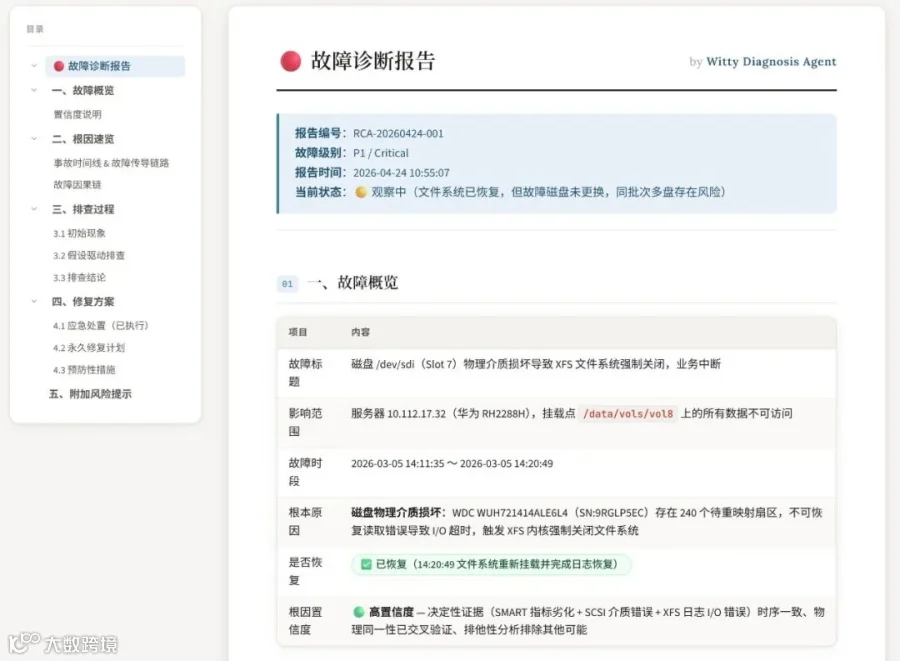
输入日志路径和时间窗口后,例如例如:“请诊断 2026-03-05 14:31 前最近一次硬盘故障,日志路径:/tmp/diskfault/logs”。Agent自动关联SMART 参数、运行日志、系统状态快照等多维数据,定位到物理坏道这个底层根因,并构建出从"坏道 → IO 重试 → 延迟升高"的完整故障传播链路。
诊断界面:
诊断报告:
四、为什么这套方案能落地?
看完三个案例,很自然会问:为什么以前没人这么做?
第一个原因:领域知识的结构化程度不够。 AI Agent没有内核调试经验,它不知道看到一个特定的kernel panic签名后应该优先怀疑内存管理模块还是驱动层。Witty的Skill层把资深运维专家的诊断思路(先查什么、怎么判断、排除什么、确认什么)翻译成了Agent可直接执行的指令序列。这跟"把专家经验写进prompt"是两回事。排查流程被做了结构化拆解,每一步有明确的入口条件、操作指令和出口判定。
第二个原因:数据层的工程债。 AI不能直接看懂vmcore dump和perf数据。Witty的工具层深度集成了 openEuler专属的内核观测工具:gala-gopher做系统观测、sysTrace做调用链追踪,以低侵入、低底噪的方式统一完成数据采集和时间语义对齐。这层数据底座让上层的AI推理有了可靠的输入。
第三个原因:知识闭环。 大多数AI运维系统是一次性的:每次诊断从零开始,诊断结果也不沉淀。Witty的知识层会自动将每次诊断的全链路数据、推理过程和最终结果转化为标准化案例,反哺Skill逻辑优化。这件事让系统真的能做到越用越准。
五、这是一件什么事
Witty智能诊断Agent不是在讲"替代运维专家"的大故事。它在一个很窄但很深的问题上扎进去了:让 OS 故障诊断这件事,从依赖稀缺专家的个人经验,变成一套标准化、可复用的系统工程。
数小时到 15 分钟的变化,不是一个数字游戏。它意味着半夜三点收到故障告警后,一个人、一杯咖啡的时间,就能拿到一份有根因、有证据、有修复方案的结构化报告。 剩下的只是决策要不要执行修复。那本来就是人的工作,不是AI的。
Witty目前覆盖了38个诊断Skill,按OS全栈分层构建。故障模式的覆盖、更多硬件的适配、复杂跨层联动场景的支持,都还需要时间。但方向是清楚的:把OS故障诊断从一门依赖个人悟性的手艺,拉回到一套可积累、可传承的工程体系。
对于openEuler生态中的运维和开发人员,这个方向值得关注。如果想深入了解或参与贡献:
-
• 代码仓:atomgit.com/openeuler/witty-diagnosis-agent -
• 开发小组:sig-intelligence -
• 交流社区:openeuler.openatom.cn/zh/sig/sig-intelligence