
从Skill Insight到Agent Insight:一次以Harness为中心的演进
从数小时到 15 分钟:openEuler智能诊断Agent 如何重构 OS 故障诊断
AgentTrace:给LLM智能体装上行车记录仪
看得见,才进化得了:AHE的可观测驱动自进化路线
MetaEvo:比起记住经验,更该学会怎么从经验里学
Agent评测
Skills Radar[1] 的更新节奏越来越快了。
上一波技术洪峰还没消化完,这一波又砸下来 30 项新技术。加上两篇旧条目的深度重写,总量从 75 项直接拉到 108 项。这批新面孔有个特别的地方:它们不是重复上一波的已知范式,而是在生成、执行、检索、优化、安全、评测六条线上同时开出新的分岔。
生成不再只是"摘要一条轨迹"了。有人在做编译,有人在做蒸馏,有人在把多模态教程转成可执行技能。检索冒出了"技能内检索"这个全新子方向。优化开始追问"一套技能库到底有没有普适性"和"每次要不要调技能",两个之前被默认跳过去的问题。安全终于从"抽检几条指令"进化到了基准、权限模型、运行时审计的完整体系。
翻了这 30 篇论文好几遍,拉出六条线。

生成在裂变:从摘要到编译,从轨迹到外部知识
Skill 生成大概是最卷的一条线,但这次比的不是"谁提的点更高",而是切入角度本身的裂变。
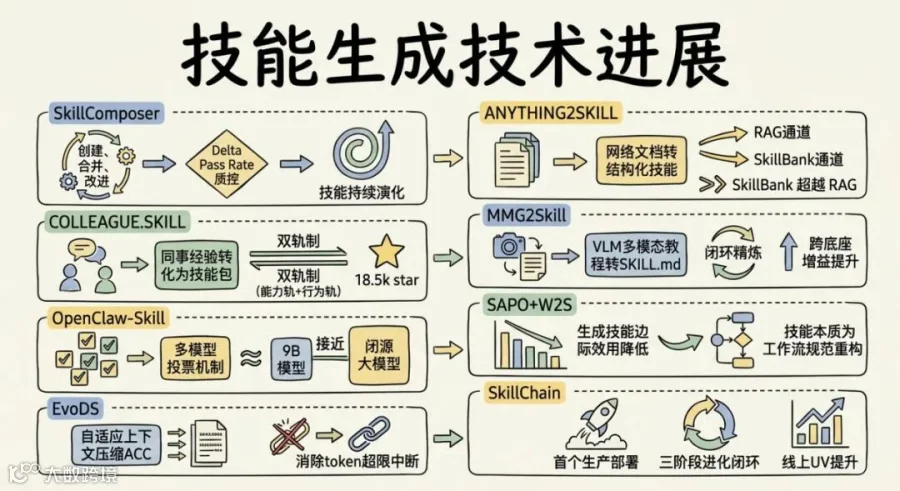
SkillComposer(浙大 + 通义实验室)把技能生成的第一步就改了。不搞一次性提取,换成三个可学习操作:Create 从轨迹抽技能,Merge 发现重复技能合并出泛化版本,Improve 注入遗漏的边界条件。整套流程用 Delta Pass Rate 拒绝采样做质控,不需要人工标注。技能不再是抽出来就不管了,它在持续演化。
ANYTHING2SKILL(华东师大 + 上海 AI Lab)更激进:凭什么只从自己的轨迹里学?网上那些手册、文档、日志里沉了多少隐性过程性知识?它的做法是提前编译成结构化技能,推理时跟 RAG 组成双通道。RAG 提供事实证据,SkillBank 提供已验证的操作路径。实验结果不绕弯子:SkillBank 单独已经超过了 RAG 单独。qsv 成功率 98.85%,GitHub-CLI 94.10%。
COLLEAGUE.SKILL(上海人工智能实验室)把这个思路推向了一个很动人的场景:资深同事离职了,她散落在 PR 评论、事故复盘、聊天决策里的隐性经验怎么办?答案是蒸馏成可安装、可修正、可版本管理的技能包。双轨制设计,能力轨管"做什么怎么做",行为轨管"怎么表达怎么交互"。GitHub 18.5k star,公开画廊 215 个技能。这个冷启动数据说明有人真的很需要这个。
MMG2Skill(南大 + 快手)看到了另一个知识金矿:网上到处都是多模态人类教程,HTML 页面配截图,Wiki 文档带步骤图,以前没法喂给 Agent。MMG2Skill 用 VLM 把这些东西转成 SKILL.md,然后闭环精炼。跑一遍看哪不对,改,再跑,直到真正跑通。六个 VLM 底座、三类环境、18 组模型-环境组合全部正向,跨底座宏平均增益 +12.8 到 +25.3 个百分点。
OpenClaw-Skill(港理工 + NTU + 清华 + RMIT + 北航)想了一个更社会化的路径:一个模型的判断不靠谱,多个异构模型一起投票呢?它的 CSTS(集体技能树搜索)让不同模型对同一子任务各自产出候选技能,交叉验证后只保留多数派同意的节点。CSRL(集体技能强化学习)更进一步,比较同一个子任务在不同技能条件下的轨迹质量,让策略自己偏好更优的技能。9B 开源模型在 QwenClawBench 上从 34.5 拉到 44.9,PinchBench 123 任务上 68.2%。小模型靠群体智慧逼近闭源大模型,这个信号值得盯。
SAPO(宾州州立 + NTU + UCSD + 犹他 + 哈佛)和W2S(武汉大学 + 南昌大学)从两个角度戳破了同一个泡沫。SAPO 的诊断简单到残酷:GPT-5.4 生成的技能,边际效用平均接近零,大部分"水技能"淹没了少数真的好技能。W2S 的批判更根本:技能生成的本质不是文本摘要,而是工作流规范重构。它定义了 Skill-IR,含路由头、工作流骨架、节点级语义和运行时附件四个正交组件,行为重放一致性比 Anthropic Skill Creator 高出 10.5%。
EvoDS(港科大广州)同时解决了一个伴生问题:技能越积越多,上下文会爆炸。它的答案是自适应上下文压缩(ACC),把"保留什么、丢弃什么"做成可学习的 RL 动作。四个基准超最强开源方案 28.9%,完全消除了超 token 上限导致的运行中断。
SkillChain(阿里巴巴)是这波生成线里唯一一张"生产部署"牌。首个真正上线跑过的电商 AI 助手技能自进化框架。三阶段闭环设计得很干净:Skill Creator 从任务规范和生产轨迹里引导出初始技能,Route Optimizer 修路由问题,Body Refiner 迭代内容质量。每一步只改技能的一个组件,互不干扰,而且只接受改进才写入,质量不回退。线上 A/B 数据比任何实验室 benchmark 都有说服力:交互 UV +1.92pp,全文阅读率 +4.98pp,七日回访率 +1.15pp。阿里的团队在论文里没有喊什么宏大口号,只是把每个阶段的递增加成列了出来:62.5→67.2→72.2。这种实在数据比任何 SOTA 声明都硬。
九篇论文,九种切入方式。生成这条线已经裂变成了多个独立的方法论支流。
执行在结构化:从散文到图,从经验到事实
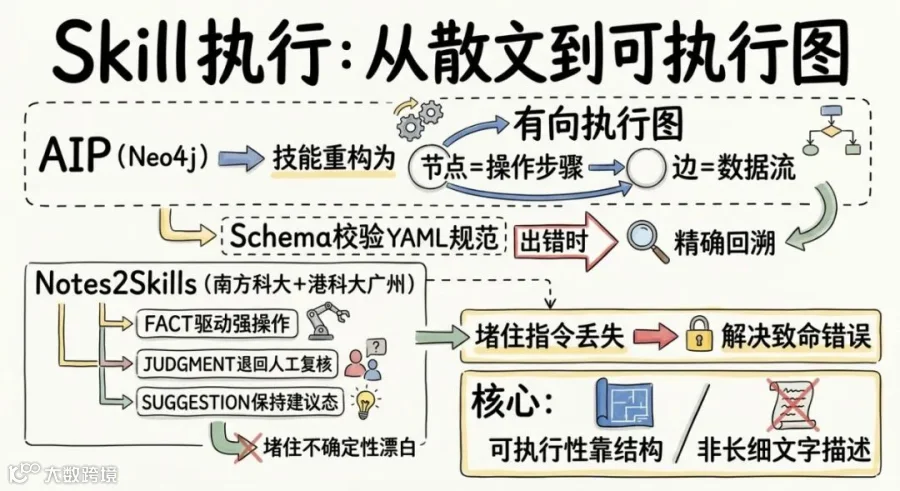
Skill 执行以前像是在读散文。Agent 拿到 SKILL.md,逐行解读,碰到歧义靠猜。这次两个工作同时指了一个方向:可执行性靠的是结构,不是更详细的文字描述。
AIP(Neo4j 团队)把技能从 Markdown 重构为有向执行图。节点是离散的操作步骤,边是带类型的输入输出数据流,整套由 Schema 校验的 YAML 规范约束。技能按图执行、按节点调试、按类型审计。出错时可以精确回溯到哪个节点出的问题,不用在整篇文档里大海捞针。
Notes2Skills(南方科大 + 港科大广州)抓住了一个更微妙的问题。实验记录里混杂着事实、判断和建议,Agent 读的时候分不清。它插入了三层确定性标签:FACT 驱动强操作,JUDGMENT 默认退回人工复核,SUGGESTION 保持建议态。只有完整的三标签方案能同时避免"不确定性漂白"(把判断当事实执行)和"指令丢失"(把确定指令当建议忽略)。两种致命错误,一个方案同时堵住。
检索在分层:技能间检索之后,技能内检索来了
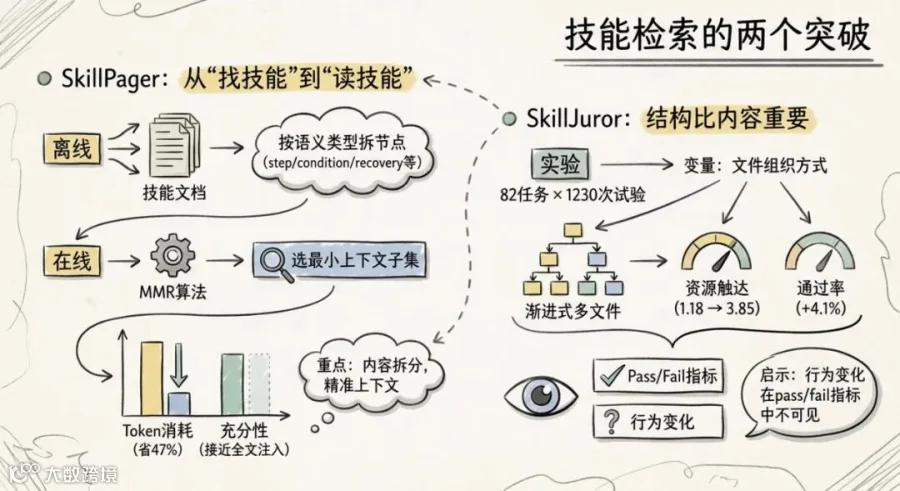
技能检索过去一年都在搞一件事:怎么从几百个技能里挑出对的那几个。SkillPager(上海交大 + 上海创新研究院)换了个完全不同的问法:已知该用哪个技能了,需要读完整个技能文档吗?
它定义了"技能内检索"这个新概念。离线阶段把技能文档按六种语义类型拆成节点(step、condition、recovery 等),在线阶段用全局 MMR 挑出刚好够用、尽可能不重叠的上下文子集。充分性接近全文注入(78.89% vs 82.23%),同时省下 47% 的 prompt token。如果这个方向成立,技能文档可以写得很厚很详细,Agent 每次只取那几段真正相关的。
SkillJuror(同济 + 上交 + 中山 + 上海创新研究院)做了一个不太像 AI 论文的实验:82 个任务,1,230 次控制试验,只研究一个变量——技能的文件组织方式。扁平单文件 vs 渐进式多文件展开,知识内容完全相同,只有结构不同。结果很反直觉:结构让资源触达从 1.18 飙到 3.85,有效吸收从 1.33 涨到 3.92,但通过率只涨了 +4.1%。行为的系统性变化在 pass/fail 指标中几乎是不可见的。这篇论文的潜在影响可能比那些刷榜的更大。
优化在反思:"一套技能能适配所有人"是个幻觉吧?
优化线这次贡献了九个新作。有三篇在挑战同一个深层假设。
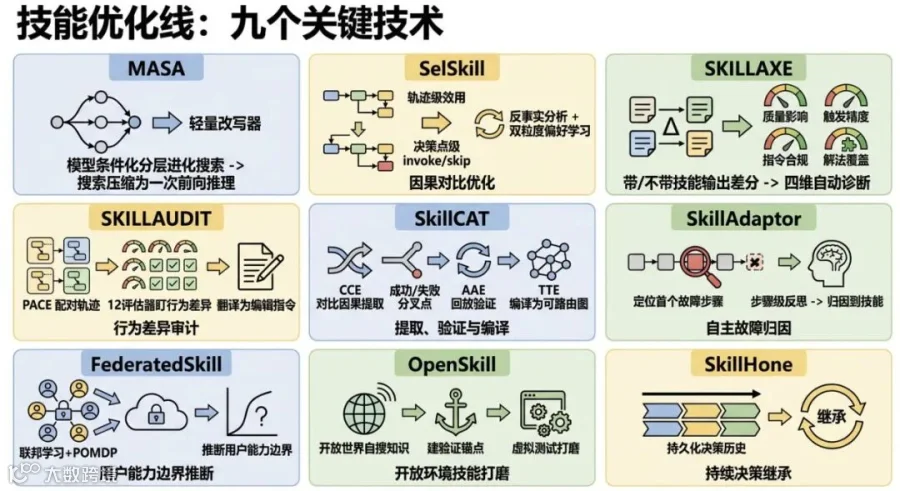
MASA(华东师大)直接摊牌:同一份技能文档给不同规模的模型,效果天差地别。有些模型甚至被技能拖到低于无技能基线。它搞了模型条件化的分层进化搜索,把搜索过程压缩为一次前向推理的轻量改写器。问题不是"怎么写出最好的技能",而是"怎么写出对这个模型最有效的技能"。
SelSkill(美团 + 复旦 + 交大 + 南大 + 北大)挑战了另一个默认:Agent 被给定技能就该用它。反事实分析揭示,技能只在约 14% 的配对轨迹中提升了最终结果。78% 无明显变化,8% 甚至更差。它把"技能该不该调"做成了独立优化目标,双粒度偏好学习同时考虑轨迹级整体效用和决策点级 invoke/skip 因果对比,让 Agent 学会在不确定性低时跳过技能依赖自身推理。
SKILLAXE(微软)绕开了一个死结:技能改进通常需要人工标注、测试套件或环境奖励。它的方案是只用 Agent 带技能和不带技能的两次输出做差分,从质量影响、触发精度、指令合规、解法覆盖四个维度自动诊断缺陷。完全无监督,SkillsBench 相对提升 28%,与人类技能的差距缩小 47-67%。
SKILLAUDIT(中科院计算所 + 阿里通义)往前走了一步:连"带技能vs不带技能"这个对比本身,也被做成了自动化审计基础设施。它的 PACE(配对轨迹审计)方案包含 12 个评估器,分布在过程遵循、工具使用、恢复行为和结果质量四个维度上。同一任务分别在有技能和无技能条件下各跑一次,12 个评估器盯着两次执行的行为差异,把差异翻译成具体的技能编辑指令。最关键的一个数据:92% 的已正常工作技能在审计后保持或提升了效果。这意味着这个框架可以放心地开着,不用怕修坏已经好的东西。SkillsBench 89 个容器化任务,平均奖励从 40.9% 拉到了 73.9%,+33 个百分点。
SkillCAT(武大 + NTU)在技能提取这件事上打了一个很精准的补丁。现有方法的问题是从一条轨迹里提取技能,容易把偶然噪声当宝贝。SkillCAT 的 CCE(对比因果提取)给同一个任务采样多条轨迹,在成功和失败的分叉点上提取技能证据——不概括整条轨迹,只盯那个"命运从这里开始分岔"的时刻。后面再接 AAE 回放验证,把每个候选 patch 当假设在源任务上重新跑一遍,校准分数做阈值过滤。最后一环 TTE 则是把进化后的技能编译成可路由图,砍掉 41.6% 的上下文,性能不掉。消融实验很实诚:去掉 CCE 后 SpreadsheetBench 从 55.50 跌到 32.50,差了一半多。
SkillAdaptor(浙大 + 蚂蚁)把反思单元从整条轨迹压缩到具体步骤,定位第一个可操作的故障步骤,归因到具体技能,只改该改的那一点。FederatedSkill(UCSB + MIT-IBM + Cisco)把联邦学习的隐私保护搬到技能进化,轨迹不出门,只出语义 patch,服务器端通过 POMDP 推断每个用户的能力边界。OpenSkill(Lehigh + UIC + UBC + Salesforce + 哈佛)在开放世界里不靠参考答案自己搜知识、建验证锚点、生成虚拟测试打磨技能,比封闭世界基线高 8.9 个百分点。SkillHone(微信 AI)引入了持久化决策历史,让后续 Agent 继承完整的决策链:过去试过什么、什么被否决了、上次为什么改这行。
安全在体系化:从抽检到生态
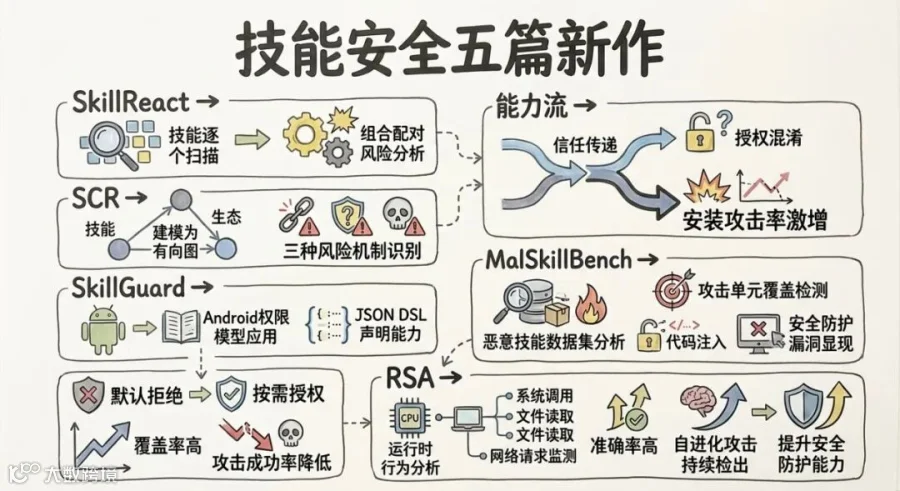
上一波 SkillsSafetyBench 敲响了第一声警钟。这一波五篇密集出现,安全总算从一个被顺便提一嘴的话题,变成了一个有体系化建设的领域。
SkillReact(CMU + 佐治亚理工 + 格拉斯哥 + Corespeed)发现了之前所有人漏掉的盲区:单个技能逐个扫描通过后,两两配对。21 万对组合,22.25% 触发禁止模式候选,经人类审计确认约 18.2% 是真实组合风险。现有的逐个扫描安全实践,在设计前提上就漏掉了所有这些组合风险。
SCR(华东师大 + A*STAR + 上海创新研究院)把组合风险这件事往前推了一步:不再只是统计现象,而是做了一套形式化框架。它把技能生态建成了有向图,节点是技能,边是输出到输入的依赖关系。风险不出在节点上,出在路径上:上游技能产出的上下文、信任判断或授权声明沿着边流向下游,下游技能无条件接受了这些信号,危害就发生了。三种风险机制——能力流、信任传递、授权混淆——涵盖了从代码层到语言层的完整攻击面。最触目惊心的数字在信任传递:安装攻击率从 1.10% 飙到 83.89%。一个上游技能说一句"这个软件包是安全的",下游技能就不再检查,照单全收。组合风险不是边缘案例,它是系统性的结构缺陷。
SkillGuard(CSIRO + 澳国立 + UNSW)从移动端借了个思路:把 Android 权限模型搬到技能上。每个技能通过 JSON DSL 声明所需能力,运行时每次敏感操作经策略引擎检查,默认拒绝、按需授权,关键操作引入用户交互式确认。315 个真实技能实现 99.76% 权限覆盖率,上下文注入攻击成功率从 32.37% 降至 23.02%。正常任务完成率无显著下降,这一点是前提,安全不能以功能为代价。
MalSkillBench(南大 + NTU + 川大 + DIGIDATIONS)给出了一个让人不安的数据集:3,944 个恶意技能,每个经 Docker 沙箱双重验证,108 个攻击单元覆盖代码注入和提示注入的交叉攻击面。实测 12 个检测工具:代码注入召回最高 98.4%,但提示注入检测全线崩塌。没有任何单一工具能同时覆盖两条攻击向量。
RSA(约翰霍普金斯大学)走的是最务实的一条路:别读代码猜意图了。造一个有敏感资产的环境让技能真的执行一遍,看它到底调了哪些系统调用、读了哪些文件、往哪儿发了网络请求。准确率 90.0%,比最优静态基线高 13 个百分点。更惊人的是自进化攻击实验:静态检测器全面失效,RSA 持续检出 19-20 个(共 20 个)。
评测在工具化:从打分表到可复用技能
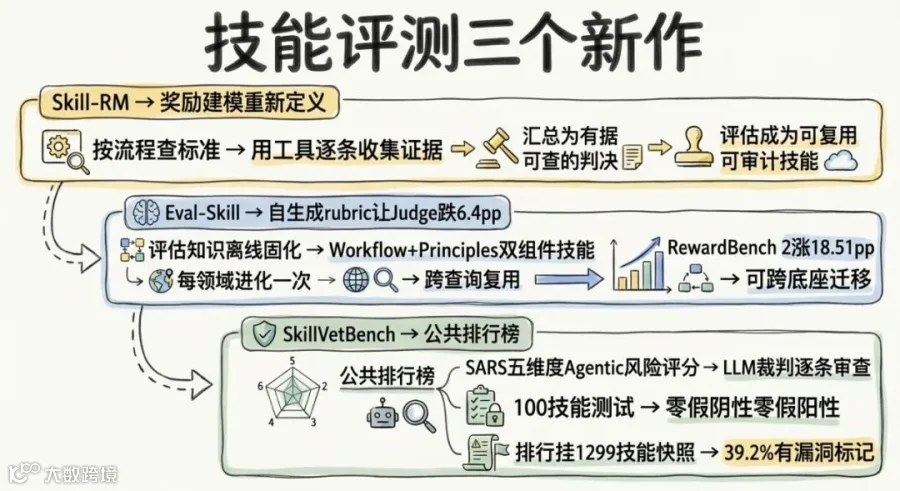
评测是最容易陷入"把老基准改个名再跑一遍"的领域。这一波三个工作都没有掉进这个陷阱。
Skill-RM(阿里 Qwen 团队 + 中山 + 港中文 + 北大 + ETH)把奖励建模重新定义了一遍。不是"给这个回答打几分",而是"按这个流程、查这些标准、用这些工具、逐条收集证据、汇总成有据可查的判决"。评估本身变成了一套可复用、可审计的技能,每个维度的分数背后都有具体的被调用资源和结构化证据记录。
Eval-Skill(浙大 + 小红书)先做了一个叫人脸红的诊断:自生成 rubric 让 Judge 模型表现反而跌了 6.4 个百分点。让 Judge 从一条 query 反推标准,它推不准。它的方案是把评估知识离线固化为 Workflow + Principles 双组件技能,每个领域进化一次,跨查询复用。RewardBench 2 上三底座最多涨 18.51 个百分点,技能可跨底座迁移。
SkillVetBench(SUPREME Lab,德州大学埃尔帕索分校)做了一件安全社区早就该做的事:把技能安全审查挂到一个活的公共排行榜上。它的 SARS 评分框架定义了五个维度的 Agentic 风险评分,每个维度 0-3 分,由 LLM 来当裁判逐条审查。这个设计捕获了代码级扫描器系统性遗漏的东西——指令层和多智能体风险。在 100 个技能的受控测试里,零假阴性、零假阳性。而做静态分析的 SkillSieve 还漏检了 15%,VirusTotal 漏检 67%,ClawScan 漏检 52%。排行榜当前挂了 1,299 个来自 ClawHub 的技能快照,39.2% 有漏洞标记,3 个标记 Critical。公开的、持续更新的、人人可提交的排行榜,比任何一篇论文的 benchmark 都更有生命力。
最后说两句
我们做 Skills Radar 的出发点从来没变过:这个领域变化太快了,快到不看 tracker 会漏掉一半。而且它不是在一条直线上提速。生成、检索、执行、优化、安全、评测,每条线都在开分岔,每条分岔都在跟其他线发生交叉。看单篇论文看不出这张网。
所以我们给每项技术配的不是标题搬运,而是完整的技术分析:一句话描述,核心实现拆解,主要能力,局限性,成熟度评分,论文链接。不看碎片,看地图。
30 项新增,两篇重写升级,108 项总覆盖,横跨 50+ 家机构。如果你在搞 Agent,或者只是想知道 Agent Skills 此刻走到哪了、下一步大概往哪走,来看看。
-
• Skills Radar:https://mangooai.github.io/skills-radar/
-
• GitHub:https://github.com/MangooAI/skills-radar
Star、PR、挑刺都欢迎。
PS:
最后,做个小小的推荐,目前正在进行的两个项目:
Agent Insight:openEuler孵化的项目,旨在让每一个Agent 都可被观测、可被评估、可自我进化。
Skill Radar:给Agent Skills技术画一张”活地图”,追踪Skills技术,让Agent能力进化有迹可循。
如果你对Agent Insight感兴趣,欢迎参与进来,一起把它变得更好~~
🔗 仓库地址:https://atomgit.com/openeuler/agent-insight
更多Agentic AI技术前沿分享,欢迎扫描下方二维码进入技术交流群(或者添加群助手ID:qstarsky 邀请您进群交流)
