
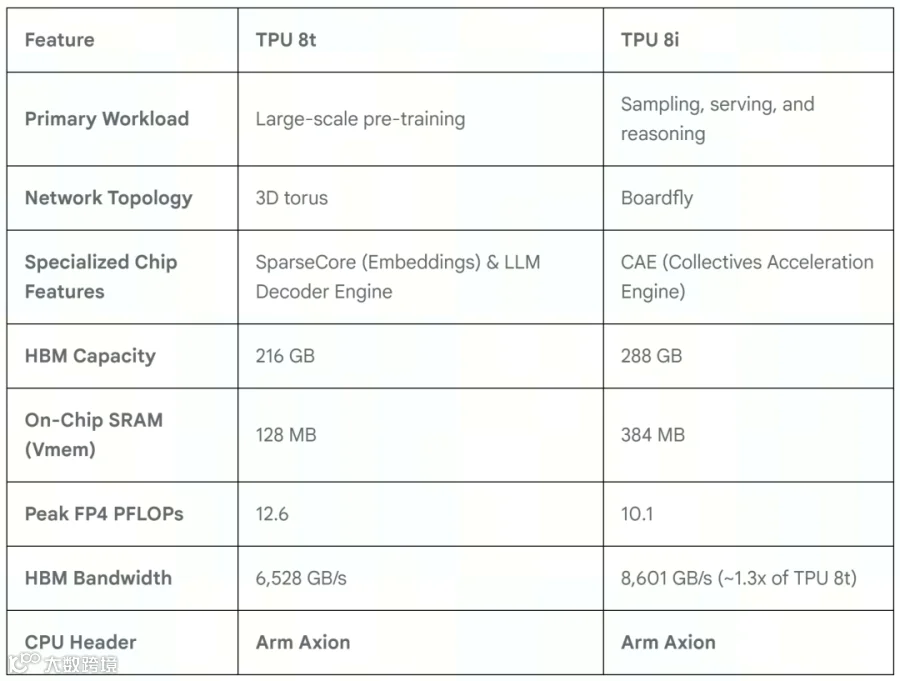
Google第八代TPU(TPU v8)的迭代中,将训练与推理硬件从物理层面上进行了架构剥离。在上一篇文章,我们分析了推理芯片 TPU 8i,本期将分析训练芯片TPU 8t。

专为大规模预训练设计的 TPU 8t(代号 Sunfish),在设计思路上放弃了对低延迟、高并发推理场景的兼顾,转而将核心资源集中于芯片的矩阵计算密度与超大规模集群的横向扩展能力,在算力与memory的配比、互联拓扑、SparseCore以及CPU和存储直连都有大幅改进。
算力密度与Memory配比
从硬件规格来看,TPU 8t 的双计算芯粒(Dual-chiplet)架构支持原生 FP4 精度,能够输出高达 12.6 PFLOPs 的峰值算力。但在memory侧,配备了 216GB HBM3e 内存(带宽 6.5TB/s)在容量上甚至略低于主打推理的 TPU 8i(288GB)。
这种内存配置是一种工程折中考虑:在数千乃至数万张加速卡参与的 3D 并行(数据、张量、流水线并行)训练中,模型状态和权重被分发至全局集群。单卡内存只需要满足并行策略的切分阈值即可,更高堆叠 HBM 会带来更高的功耗和成本增加。
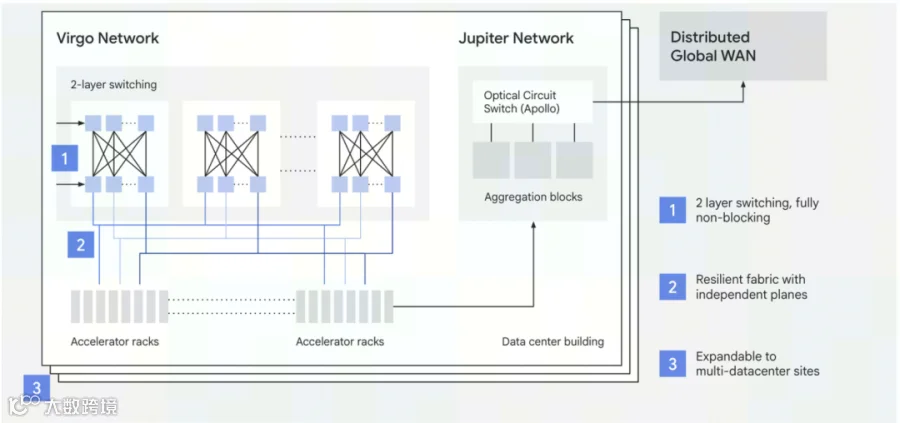
3D Torus 与 Virgo 数据中心网络
在万亿参数模型的并行训练中,网络通信开销是决定集群有效吞吐量(Goodput)的核心瓶颈。TPU 8t 的网络架构在芯片间互联(ICI)和数据中心网络(DCN)两个层级分别采用了不同的拓扑策略:
-
Scale-up 与 3D Torus:
在单 Pod(最高 9,600 颗芯片)内部,TPU 8t 依然延续了 Google 经典的 3D Torus拓扑。对于预训练中高度规律的环形 All-Reduce 和流水线并行操作,3D Torus 能够提供较高的双向带宽,避免了在局部节点引发拥塞。
-
Scale-out(向外扩展)与 Virgo 网络:
为了突破单 Pod 的规模上限,Google 在 TPU 8t 上首次引入了 Virgo 网络架构。传统的通用数据中心网络在应对十万卡级别的扩展时,往往需要增加多级交换机,这会导致延迟急剧增加。Virgo 是一种专为 AI 扩展设计的扁平化、双层无阻塞(flat, two-layer non-blocking)架构。 它依托高基数的光路交换机(OCS),大幅减少了网络层级。
根据公开数据,通过 Virgo 网络,TPU 8t 能够在单一数据中心 Fabric 内无阻塞地连接高达 134,000 颗芯片(提供 47 PB/s 的对分带宽),并在逻辑上支持跨区域扩展至百万卡级别。对比依赖多级胖树结构的高成本集群网络,Virgo 在简化物理组网复杂度的同时,保证了极大规模下的线性扩展效率。
SparseCore
LLM的混合专家模型(MoE)引入了更大量的 Embedding 查找和非规则的专家路由(Expert Routing)。这些操作的特点是算术强度极低,但内存寻址极其分散。如果依赖常规的矩阵乘法单元(MXU)处理这些操作,流水线会被频繁打断,导致算力利用率下降。
为解决这一问题,TPU 8t 在芯片层面集成了专门的 SparseCore 加速器。需要明确的是,SparseCore 并非 TPU 8t 的首次创新。 早在 TPU v4 时代,Google 就引入了 SparseCore 架构,当时主要是为了加速深度学习推荐模型(DLRM)中海量的 Embedding 表查找。
在 TPU 8t 架构中,SparseCore 已经从单一的嵌入查询工具演变为专门应对超大规模混合专家模型(MoE)的通信与存储卸载中心。这一代 SparseCore 最大的进化在于它与底层计算格式及存储架构的深度整合,通过原生支持 FP4 数据类型,使得在处理稀疏参数时的内存占用和带宽压力大幅下降,从而在同等硬件资源下能够承载更大规模的模型权重。为了消除在大模型训练中常见的“数据饥饿”现象,SparseCore 现在与全新的 TPUDirect Storage 协同工作,利用提升了 10 倍的存储访问速度,确保来自海量数据集的非结构化内存请求能够被即时响应,而无需经过传统主机 CPU 的中转。
在微架构层面,TPU 8t 的 SparseCore 强化了独立执行的能力,专门负责卸载复杂的集体操作如 All-gather 等,这使得主计算单元 TensorCore 能够始终专注于高负载的矩阵乘法任务,避免了因处理散乱访存而产生的零操作瓶颈。这种设计极大地优化了 MoE 模型的路由逻辑效率,尤其是在处理涉及数万亿参数的大模型时,SparseCore 能够高效地进行 Token 路由和跨节点的专家参数同步。配合全新的 Virgo 网络互连和高带宽 ICI 通信,SparseCore 将稀疏访存操作对主算力资源的占用完全隔离,在高达 9,600 个芯片规模的超大型集群中维持了极为稳定的计算吞吐量,使训练性价比达到了前代产品的 2.7 倍。
Axion CPU 与存储直连
随着多模态大模型的训练语料库向 PB 级别跨越,传统 x86 主机节点在处理数据加载(Data Loading)、洗牌和格式对齐时,往往受限于 PCIe 总线带宽和 CPU 调度延迟。
与TPU 8i 一样TPU 8t 节点也采用基于 Arm 架构的自研 Axion CPU 作为宿主主控。不同于传统架构中数据必须经过系统内存流转,TPU 8t 引入了 TPU Direct Storage 技术。该技术允许计算节点直接从底层的对象存储或 Managed Lustre 文件系统中拉取数据,并将其直接载入 TPU 的 HBM 显存中,彻底绕过了主机的 CPU 介入与内存拷贝环节。
在此架构下,Axion CPU 可以专注于宏观的分布式任务调度与计算图下发。这种底层数据数据通路的精简,大幅降低了远端数据投喂的延迟,确保高昂的计算单元不会因 I/O 阻塞而处于空转状态。

为了更直观地理解这一底层数据通路解耦的核心价值,我们可以参考行业标杆 NVIDIA 的同类解决方案——GPUDirect Storage (GDS)。 在传统的通用 GPU 训练集群中,数据从远端存储节点读取到 GPU 显存,同样需要先拷贝至主机 CPU 的系统内存(Bounce Buffer)中作为中转,这不仅会消耗大量的 CPU 周期,还会让数据在 PCIe 总线上产生冗余的来回搬运。为此,NVIDIA 推出了作为 Magnum IO 套件核心的 GDS 技术,其原理是通过 RDMA(远程直接内存访问)机制,在智能网卡(如 BlueField DPU 或 ConnectX 网卡)与 GPU 显存之间建立一条直接的 DMA(直接内存访问)物理通道,同样实现了 CPU 的旁路(Bypass)。
无论是 NVIDIA 的 GPUDirect Storage,还是 Google 的 TPU Direct Storage,两家算力巨头在解决系统级 I/O 瓶颈时殊途同归:在计算密度极其昂贵的超级集群中,加速器处理数据的速度早已远超传统 CPU 获取和分发数据的能力。将数据流与控制流彻底分离,实现“网络存储端到加速器显存的物理直通”,已经成为打破大规模预训练“数据饥饿(Data Starvation)”效应、维持极高有效算力利用率(MFU)的行业必然标准。
总结
TPU 8t 的架构设计体现了在面对极端计算需求时,领域特定架构(DSA)的系统级取舍。通过控制单卡 HBM 容量以换取更高集群算力密度、利用 Virgo 扁平化网络支撑十万卡级互联、以及依托 SparseCore 处理 MoE 模型的稀疏访存,TPU 8t 在工程上完成了针对“大规模并行预训练”这一单一负载的深度物理定制。这种将训练与推理彻底解耦的演进方向,为业界在评估未来 AI 基础设施的总体拥有成本(TCO)与扩展潜力时,提供了一个具有高度参考价值的架构范本。
参考链接:
https://cloud.google.com/blog/products/compute/tpu-8t-and-tpu-8i-technical-deep-dive
https://www.servethehome.com/google-tpu-8i-for-inference-and-tpu-8t-for-training-announced/
https://cloud.google.com/blog/products/networking/introducing-virgo-megascale-data-center-fabric
谷歌TPU v7,性能硬刚Blackwell,Anthropic狂买100万颗