
现代 AI 的竞争,表面上是模型规模的竞争,深层是谁能把芯片算力"榨得更干"。同一个 Attention 运算,换个写法就能快 2-3 倍——FlashAttention 的故事早已证明,GPU 内核(kernel)优化的价值远超多数人的想象。
但写出这样的内核,至今仍是 AI 世界最稀缺的能力。更严峻的是,当 AI 芯片从 NVIDIA CUDA 一家独大走向华为 CANN、寒武纪 BANG、摩尔线程 MUSA 等多元竞争时代,为每种芯片重写优化内核的成本正在指数级增长。
摩尔线程的最新工作 MusaCoder 给出了一个有力的回答:在 64 台 MTT S5000 国产 GPU 服务器上完成全栈强化学习训练后,一个 27B 参数的模型在 KernelBench 全球最权威的 GPU 内核生成基准上,超越了 Claude Opus 4.7、DeepSeek-V4-ProMax 等所有对手,建立了新的世界第一。其 开源模型 和论文已公开发布。
这不是实验室玩具。这是对"国产 GPU 能否担当 AI 大任"的一次系统性验证。
GPU 内核优化:AI 算力的"最后一公里"
FlashAttention 的启示
2022 年,FlashAttention 论文震动了 AI 界。它没有提出新架构,没有增加参数量,只是重新设计了 Attention 在 GPU 上的计算方式——速度提升 2-3 倍,显存占用大幅下降。如今,它已是所有主流大模型的标配。
这个故事揭示了一个常被忽视的事实:瓶颈往往不在芯片峰值算力,而在算力有没有被"用对"。一个朴素实现的矩阵乘法,与经过 tiling、shared memory 分块、warp shuffle 优化的版本之间,速度可以差 5-10 倍。对大规模训练集群来说,这直接决定了"能不能训得起"。
为什么自动化如此困难
按理说,如此关键的环节应有成熟的自动化工具。但现实远非如此。
官方库只覆盖标准算子。cuBLAS、cuDNN 对 GEMM、卷积等常见操作提供了极致优化,但它们本质上是一组"手工预制件"。SwiGLU、Grouped-Query Attention、MoE 路由、各类定制归一化层——每一个新算子的出现,都是一块"库覆盖不到"的空白。
编译器同样有盲区。PyTorch 2.0 的 torch.compile 在单算子上表现不错,但在算子融合——将多个连续运算合并为一个内核以减少 GPU 内存往返——的场景下效果有限。KernelBench 数据显示,在 Level 3(完整模型构建块级别),即使 Claude Opus 4.7 生成的内核中也仅有 2.8% 能比 torch.compile 更快。
核心矛盾很清楚:模型架构创新越来越快,底层算子优化却只能依赖极度稀缺的 CUDA 专家手工完成。
异构计算:紧迫性再升一级
如果只有 CUDA 一个平台,"多招 CUDA 工程师"或许还能缓解。但当 AI 芯片进入多元时代,问题性质彻底变了。
华为 CANN、寒武纪 BANG、摩尔线程 MUSA——每个平台有自己的原生编程模型。更麻烦的是"鸡生蛋"困境:开发者不来,因为没有高性能算子;没有高性能算子,开发者更不会来。打破僵局的唯一途径,是大幅降低跨平台算子开发的边际成本。
四条路径,四种天花板
业界探索了四条自动化路径,但每条都触达了不同的天花板。
编译器与 DSL。TVM、Triton、torch.compile 将优化映射到中间表示,用搜索找最优调度。在标准算子上很有效,但搜索空间是预定义的——最需要创新的复杂算子融合偏偏落在搜索空间之外。
Skill 工程。 将 GPU 优化知识写成 Markdown 文件引导 LLM 执行。灵活、无需训练,但天花板效应明显——CUDA 代码在 LLM 预训练语料中占比不到 0.01%,模型对这个领域几乎"一无所知"。再好的施工图,也盖不出地基不牢的高楼。
Agent 搜索。STARK、CudaForge 等工作让模型进入"生成→编译→执行→修正"的迭代循环。复杂任务上的修复能力令人印象深刻,但代价巨大——一次优化可能需要上百轮 LLM 调用,成果不沉淀为能力,下次还得从零搜索。
模型微调。CUDA Agent 等项目通过 SFT 和 RL 让模型真正"学会"内核开发,首次在 KernelBench 上全面超越 torch.compile。但这四条路径中最接近"根本解"的方案,仍面临数据稀缺、训练极不稳定、算力门槛极高(128 块 H20 + 230B 模型)、以及 CUDA 锁定四大挑战。
共同困境:几乎所有方案都为 CUDA 生态设计。当芯片进入多元化时代,"非 CUDA 平台怎么办"成了一个无人回答的问题。
MusaCoder:能力内化,而非外挂
MusaCoder 的回答是:用更小的模型、在国产 GPU 上,完成从数据到训练到评估的全栈闭环。它的设计哲学可以用一条公式概括:
精心构造数据 → 多样性保持的监督微调 → 执行反馈驱动的强化学习 → 能力固化到模型权重中。
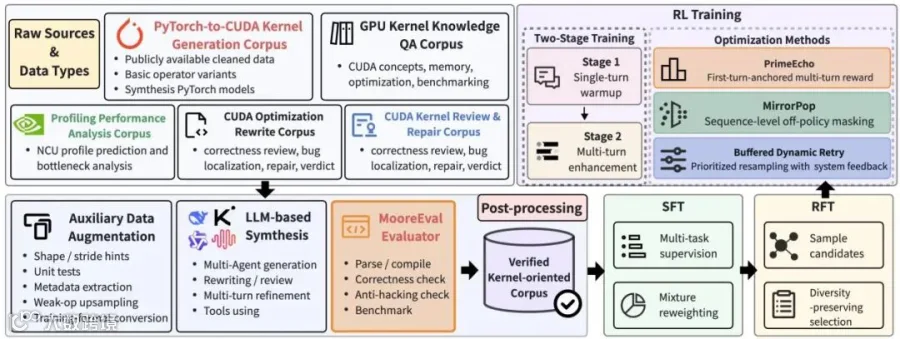
MusaCoder 的全栈训练流水线(来源:MusaCoder 论文 Figure 2)
数据:教模型"思考",而非教模型"翻译"
大多数方案把训练数据做成"PyTorch → CUDA"的翻译对。MusaCoder 的做法截然不同——通过三个阶段,让数据承载 CUDA 专家的完整思维过程。
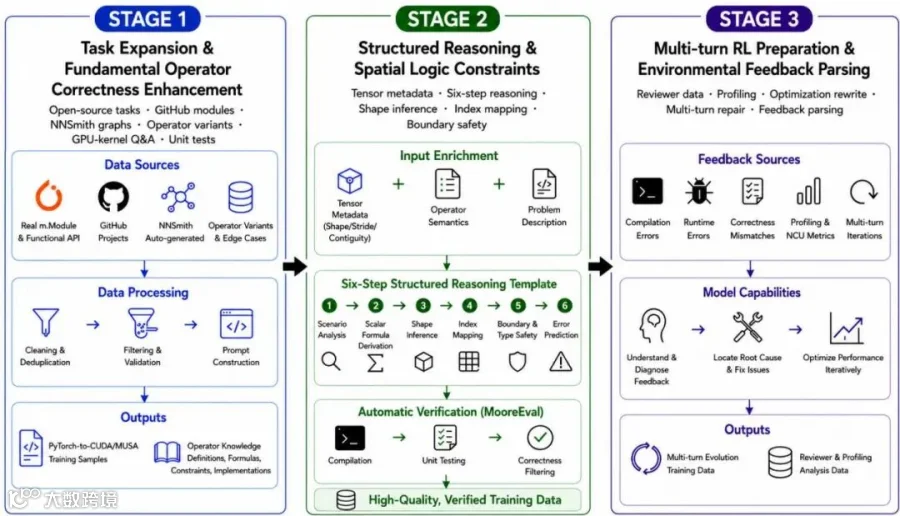
三阶段数据构建:任务扩展 → 结构化推理 → 多轮反馈准备(来源:MusaCoder 论文 Figure 3)
Stage 1:打地基。 数据来自三个源头:开源 PyTorch 模块和 GitHub 真实代码提供算子分布;NNSmith 自动合成器在 162 个算子池中随机组合,系统性覆盖长尾分布;针对卷积等"零成功率"算子族,用"先规划、再实现"的方法大规模生成变体。此外还有专门的 GPU 知识 QA 数据,教模型理解"为什么 shared memory 能加速"这类底层因果。
Stage 2:教思维。 这是 MusaCoder 最具原创性的设计。在训练数据中,PyTorch 代码和 CUDA 内核之间插入了六个结构化推理步骤:全局分析 → 数学推导 → 形状计算 → 索引映射 → 边界处理 → 错误预判。人在写 CUDA 代码时做的正是这个思维链——六步推理将专家的隐性思维显式化、结构化、可训练化。配合 Shape Annotation(显式标注每个中间张量的形状、stride 和连续性),模型被系统引导建立正确的心智模型,而非靠猜测。
Stage 3:教会迭代。 三组数据训练模型根据反馈自主修复:Reviewer 数据练诊断,Profiling 数据教性能分析,多轮修复轨迹让模型在真实的编译错误和性能瓶颈中学会自我修正。
训练:三个关键设计,让 RL 从"跑不起来"到"稳定超越 SOTA"
GPU 内核生成场景中训练强化学习面临三个独特挑战。MusaCoder 用三个设计逐一破解。
设计一:Diversity-Preserving RFT。 传统拒绝采样微调每道题只保留最优解,导致模型输出分布收窄到原来的十分之一——"只会一种写法"。MusaCoder 保留每道题 4-8 个异构正确解,按代码结构、AST 拓扑等微架构特征聚类后选取,将训练目标从"模仿单一最优"转变为"建模多样化解的分布",为后续 RL 保留充足的探索空间。
设计二:两阶段 RL。 先做单轮 RL warmup 消除格式错误和编译失败等低级问题,再引入多轮反馈 RL 解决形状推导和性能调优等高级问题。消融实验表明,跳过第一阶段直接多轮 RL 会导致 Pass@8 下降 2.4 个百分点。
设计三:三大稳定器。 PrimeEcho 防止多轮训练退化为"首轮故意写不好,反正后面能修"——奖励的 75% 放在首轮,且模型只学习首轮回答。BDR(缓冲动态重试)将"全部失败"的困难题从废料变成学习信号,恢复了约 28% 的全失败样本。MirrorPop 则解决了一个精巧的数学陷阱:旧样本评估中的正负抵消问题——取绝对值替代带符号平均,消除了影响最大的不稳定因素(移除后 Pass@8 下降 7.2 个百分点)。
MooreEval:RL 训练的"考场+裁判"
GPU 内核评估无法靠文本相似度判断——必须真实编译、真实执行、真实计时。MooreEval 用五级门控(代码提取→编译→正确性验证→反作弊检测→性能测试)严格保证"不存在跑得快但算错了的虚假高分"。它采用 CPU 编译 Worker 和 GPU 执行 Worker 解耦的分布式架构,能支撑 RL 训练中数千个候选代码的并发评估。最重要的是,它返回的不只是分数,而是具体到行号的编译错误和精确的数值差异——每一条反馈都能直接指导修复。
运行底座:摩尔线程 MUSA 平台上的全栈训练
这是 MusaCoder 故事中最独特的一章:它是对一个国产 GPU 平台能否支撑完整 LLM 后训练的系统性验证。
摩尔线程 是中国领先的 GPU 芯片设计公司,其自研的 MUSA(Moore Threads Unified System Architecture)架构在编程模型层面与 CUDA 高度兼容,配套 Musify 工具可自动将 CUDA 代码转为 MUSA 代码。但 MUSA 绝不是"CUDA 兼容层"——它拥有独立的指令集、内存层次和硬件调度器,是真正的自研架构。
训练使用的 MTT S5000 是专为数据中心 AI 设计的高性能 GPU:单卡 80GB HBM 显存,支持 FP32/FP16/BF16/TF32/INT8,配备专用 Tensor 加速单元。训练集群由 64 台 MTT S5000 服务器组成,每台 8 卡,共计 512 张加速卡、约 40TB 总显存。
真正证明平台成熟度的是软件栈的完整性:
DeepSpeed、Megatron、SGLang——三个 AI 训练领域最主流的开源框架全部在 MUSA 上正常运行。这是目前公开信息中,国产 GPU 完成 LLM 全栈后训练的最完整案例。
跨后端能力的量化证明。 研究团队将 KernelBench 完整移植到 MUSA 平台。在 MUSA KernelBench 上,MusaCoder-27B 取得 Pass@8 92.4%、Avg.@8 81.7%。对比 DeepSeek-V4-Pro——虽然 Pass@8 也能达到 92.0%,但其 Avg.@8 仅为 56.9%,两者相差 24.8 个百分点。通用大模型能偶尔写对 MUSA 代码,但稳定性极差。在 Level 3 最难的级别上,所有通用模型的加速比例均为 0.0%,而 MusaCoder 达到 3.3%。
这说明"能用 CUDA 代码翻译出 MUSA 代码"和"稳定生成高效 MUSA 原生内核"之间,有一道需要专门训练才能跨越的鸿沟。
结果:在国产 GPU 上诞生的世界第一
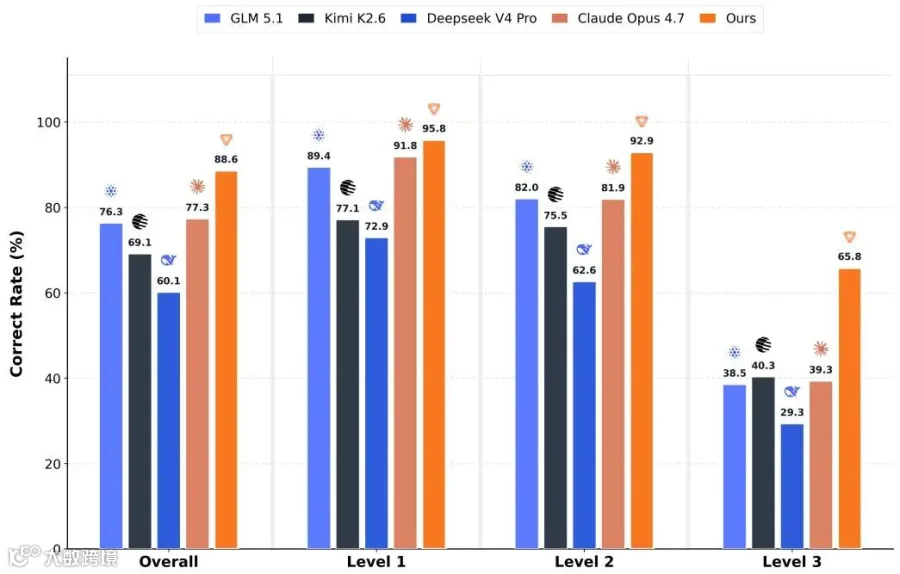
KernelBench 性能对比:MusaCoder-27B 在所有级别上全面领先(来源:MusaCoder 论文 Figure 1)
MusaCoder-27B 以 Overall Pass@8 93.2% 的成绩登顶 KernelBench:
在 Level 3(最难的完整模型构建块),MusaCoder 比 Claude Opus 4.7 高出整整 18 个百分点。
9B 版本同样惊人:其基座模型 Qwen3.5-9B 的 Pass@8 仅为 23.6%,经过 MusaCoder 全栈训练后跃升至 83.6%——RL 训练带来了 60 个百分点的飞跃,已逼近 Claude Opus 4.7。
在 MUSA KernelBench 上,MusaCoder 的 Overall Faster Rate 达到 12.5%,是 GLM-5.1(6.9%)的近两倍,DeepSeek-V4-Pro(5.7%)的两倍多。
成就、代价与前路
工程是权衡的艺术。MusaCoder 的成功背后是多重取舍。
技术取舍。 选择 GRPO 而非 PPO,省去了独立的 Critic 模型,降低了国产 GPU 上跑 RL 训练的显存开销——代价是组内全失败时优势信号消失,这正是 BDR 被设计出来的原因。Diversity-Preserving RFT 用训练效率换探索空间。27B 的规模选择是当前硬件条件下精心权衡的最优点。
工程取舍。 64 台服务器的门槛虽证明了国产 GPU 的训练能力,但对多数团队仍不低。KernelBench 作为学术基准,与生产环境中分布式、混合精度的复杂场景仍有距离。与 TVM 等高级编译器的系统性对比,也因 TVM 调优开销过大而暂未进行。
已证明的三件事。 第一,国产 GPU 不只是推理卡——在 64 台 MTT S5000 上,从 40K 长上下文 SFT 到 GRPO 异步 rollout 到在线奖励计算的完整 RL 后训练全部跑通。第二,MusaCoder-27B 在 KernelBench 上超越 Claude Opus 4.7 是面向全球公开基准的"世界第一",用技术成果说话。第三,一个训练流程同时产出 CUDA 和 MUSA 两个后端的内核生成能力——AI 模型本身可以成为异构计算时代的"算子翻译器"。
前路还很长:降低训练门槛,走向真实生产环境,验证更大规模模型,以及持续建设 MUSA 开发者生态。但至少,我们有了一个坚实的起点。
在 AI 芯片多元化的浪潮中,摩尔线程不仅证明了自己的 GPU 可以用来训练世界级的 AI 模型——更证明了,在一个从零起步的 GPU 生态中,AI 本身可以成为最有力的加速器。国产 GPU 不只是追赶者,更可以成为新范式的定义者。