
一、引言
最近几天 NVIDIA 正在召开 GTC 2026,按照惯例,笔者也继续介绍一下相关内容。考虑到网上已经有非常多介绍,本文中会刻意省略一些部分,比如最近爆火的小龙虾 - NemoClaw,以及 NVIDIA 与 Google Cloud、AWS、Azure 等合作的软件栈等内容;本文会重点介绍一下硬件部分,也会进一步完善一些关键部分的分析和解读。
相关视频可以参考:Keynote at NVIDIA GTC San Jose 2026 [1]
相关详细资料可以参考笔者之前的文章:
二、数据处理
2.1 结构化 - cuDF
cuDF(CUDA DataFrame) 是 NVIDIA RAPIDS 生态中的核心组件,提供类似 Pandas 的 API,可以在 GPU 上执行 filter / groupby / join / aggregation / 时序处理等操作。
对应的代码库为:rapidsai/cudf - GPU DataFrame Library · GitHub [2]
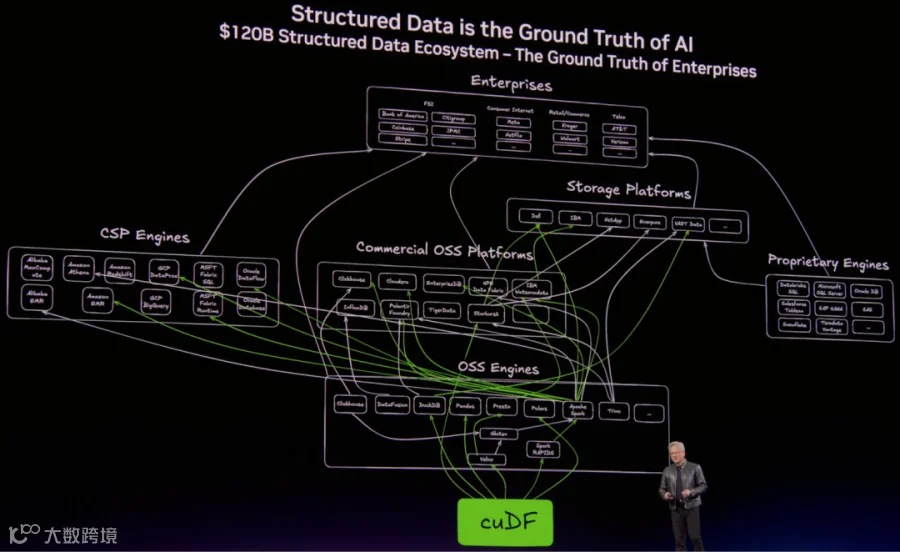
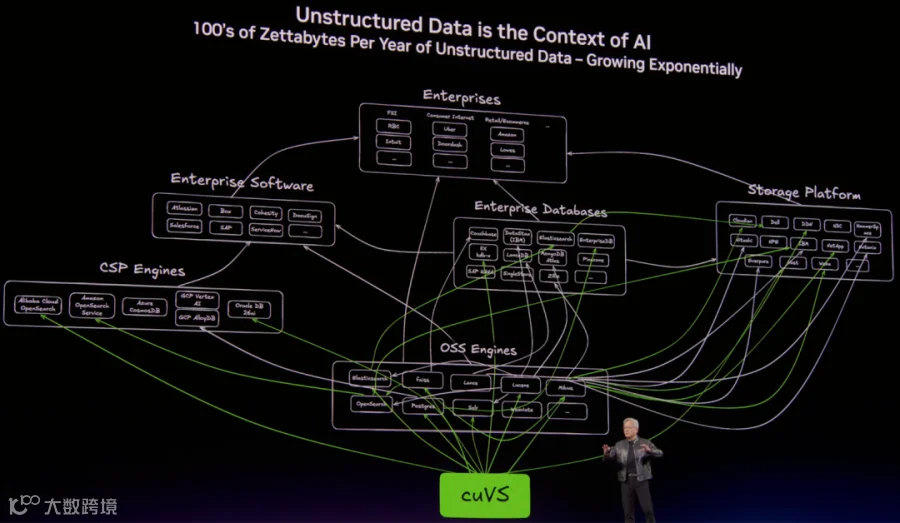
2.2 非结构化数据 - cuVS
cuVS(CUDA Vector Search) 是 RAPIDS 新的向量检索库,提供索引构建和向量检索等能力。可以在 GPU 上做大规模向量相似度检索(ANN)。
对应的官方文档:cuVS | NVIDIA Developer [3]
对应的代码库:rapidsai/cuvs: cuVS - a library for vector search and clustering on the GPU · GitHub [4]
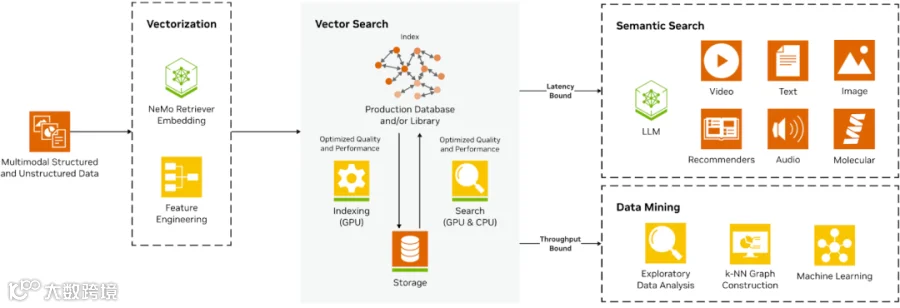
如下图所示为其典型应用场景,包含特征提取、索引构建、检索等能力:
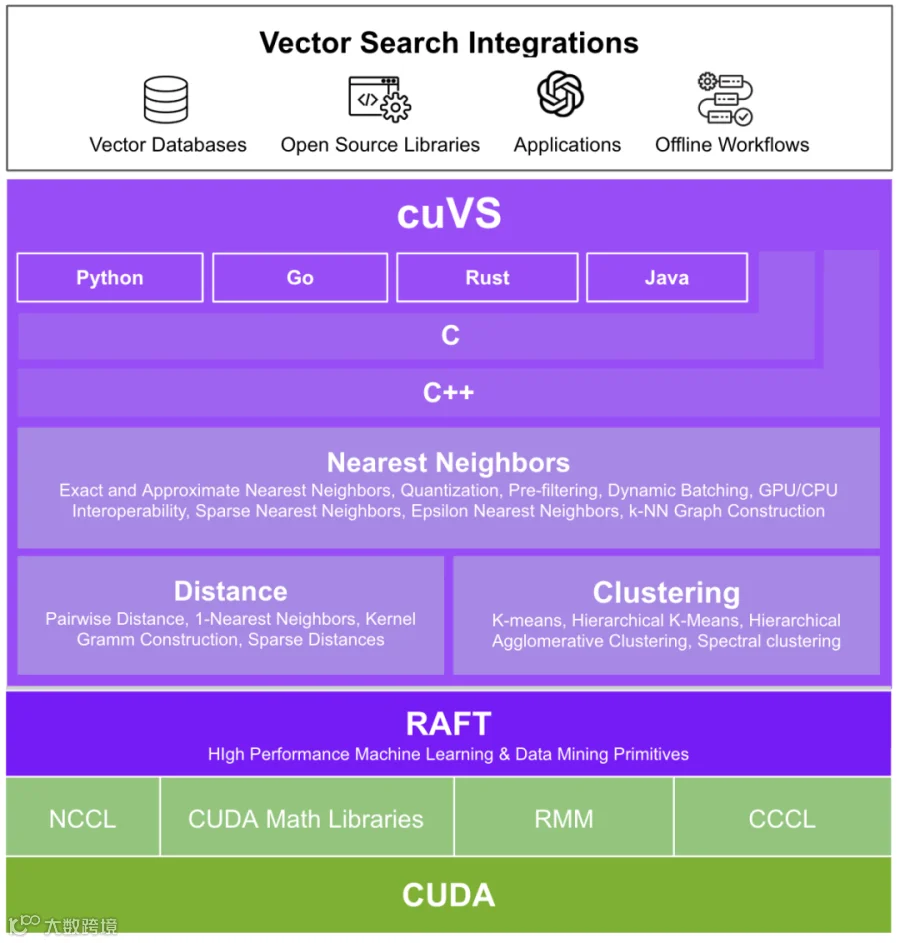
如下图所示,其基于 NVIDIA CUDA 软件栈构建,包含众多用于组合向量搜索系统的核心模块,支持 C/C++/Rust/Java/Python/Go 等编程语言。
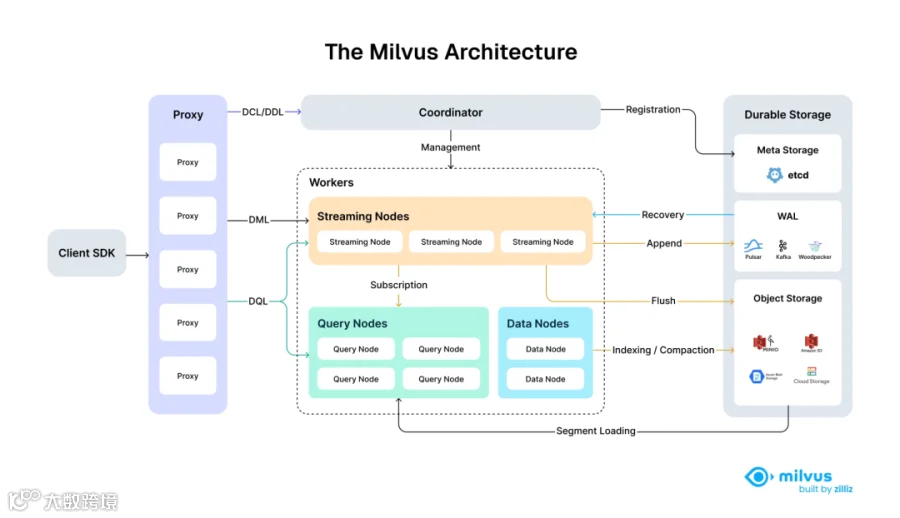
PS:业内用的比较多的还有 Milvus [5] 等,其架构如下图所示:
2.3 案例分享
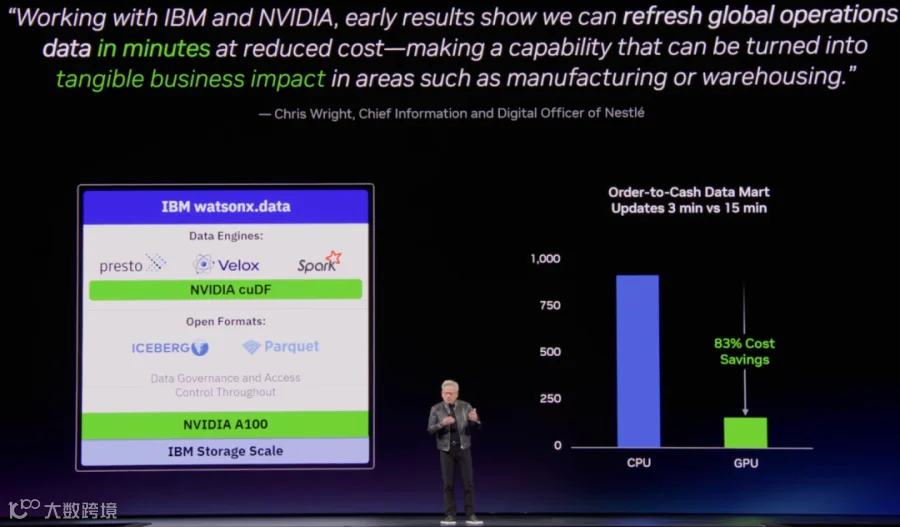
如下图所示是 IBM 使用 cuDF 的案例,可以大幅降低处理时间,从 15min 降低到 3min:
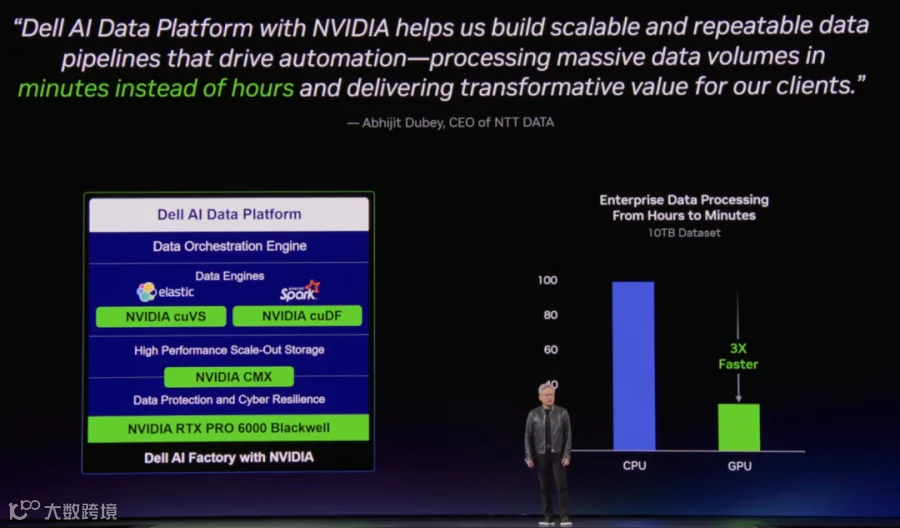
如下图所示为 Dell 使用 cuVS 和 cuDF 大幅降低企业数据处理时间,从小时到分钟,GPU 比 CPU 快 3x:
如下图所示是 Google Cloud 使用 cuDF 用于 A/B 实验平台的数据处理,资源量从 45K CPU 降低到 1K GPU,成本节约 76%:

三、推理时代到来
从 ChatGPT 发布,到 Reasoning(o1) 到来,再到 Claude Code(Agentic)快速发展,模型规模、上下文长度、Token 数依次增加了 10x。

与此同时,GPU 的需求依旧快速增长,从 GTC 2025 时的 $0.5T 增加到 $1T:
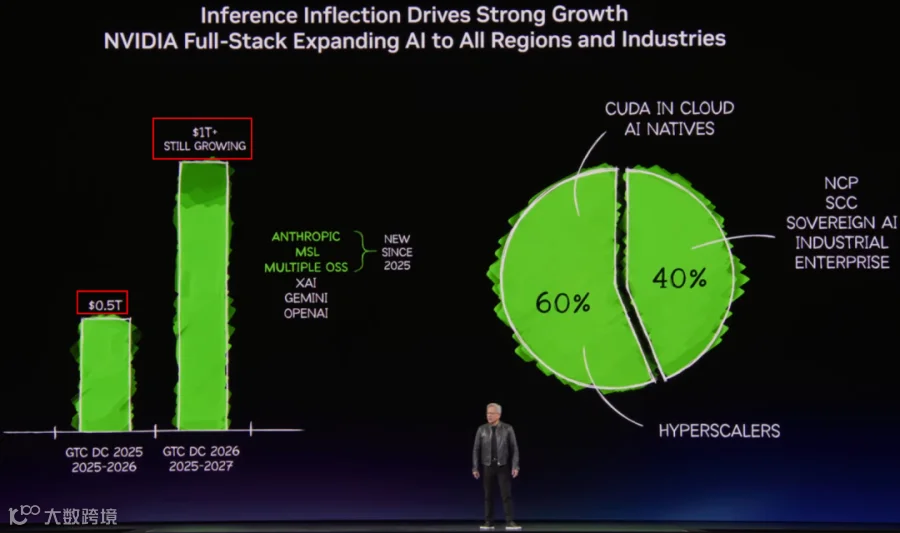
GPU 需求快速增长的同时,最新的 GB NVL72 + NVFP4 相比 H200 NVL8 可以在同功耗下将 Token 吞吐提升 50x,或者将 Token 成本降低 35x。(PS:这些数据来自 InferenceMAX [6])
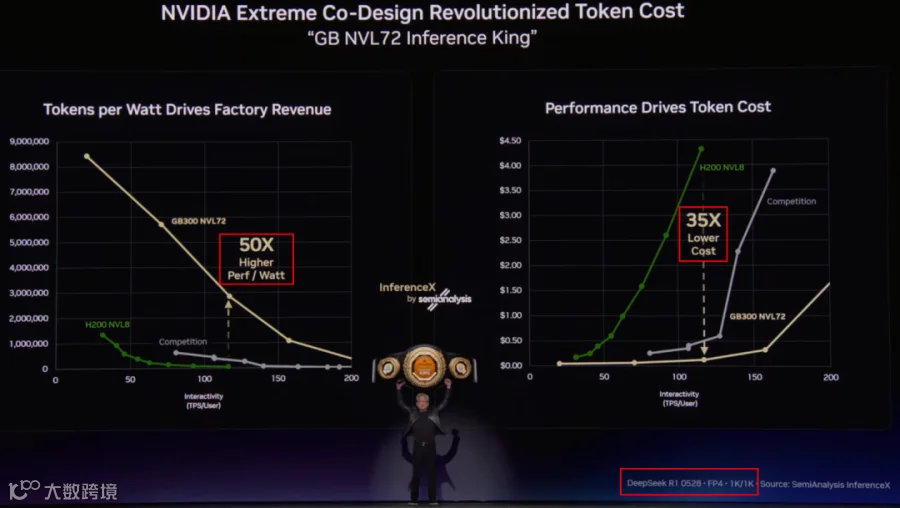
PS:这里需要注意,上述结论是基于 DeepSeek-R1 -0528 FP4 精度,输入/输出 Token 为 1K/1K 下测试出的数据。实际上,B300 相比 H100 在同功耗下的 FP8 算力只有 2x 左右差距,即使是 B300 FP4 相比 H100 FP8 也只有 6x。上述 35x 和 50x 更多是结合了 GB300 带来的更大显存、更大 NVLink 域下能够支持更大并发带来的增益。具体应用需要结合真实的应用场景来看。
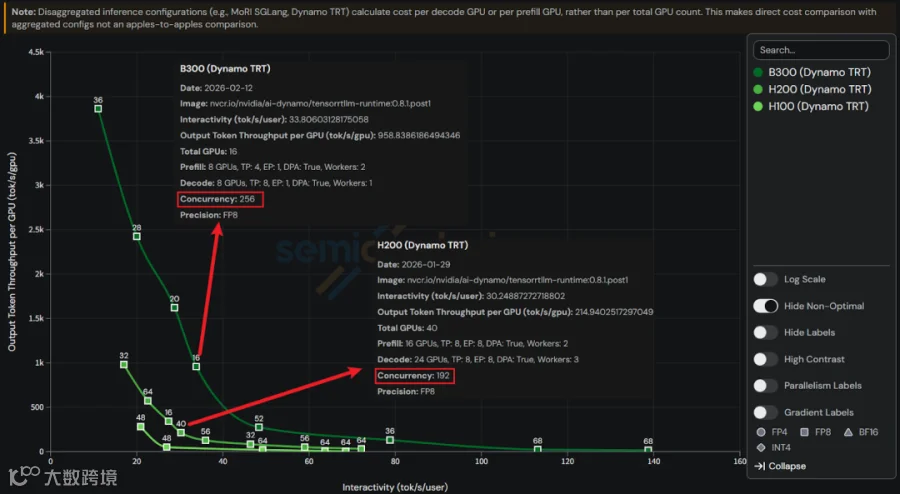
如下图所示,B300 和 H100、H200 对比,更多的优势建立在使用更大的并发(需要更大的显存,更快的 GPU 也能保证更好的 TPOT)前提下:
另外就是很多云平台都在使用 NVIDIA GPU 部署高性能的 AI 模型,比如 Kimi K2.5 Reasoning 模型,并且都能享受 NVIDIA 软件栈迭代优化的收益,逐渐提升速度、降低成本。
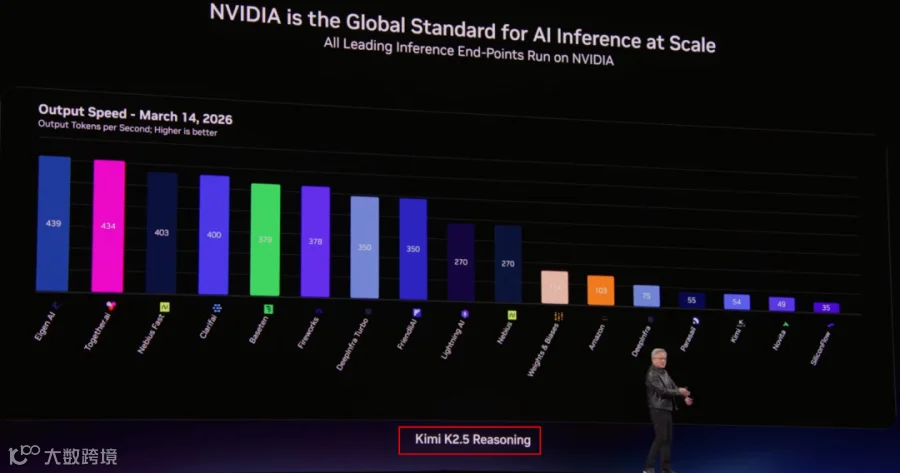
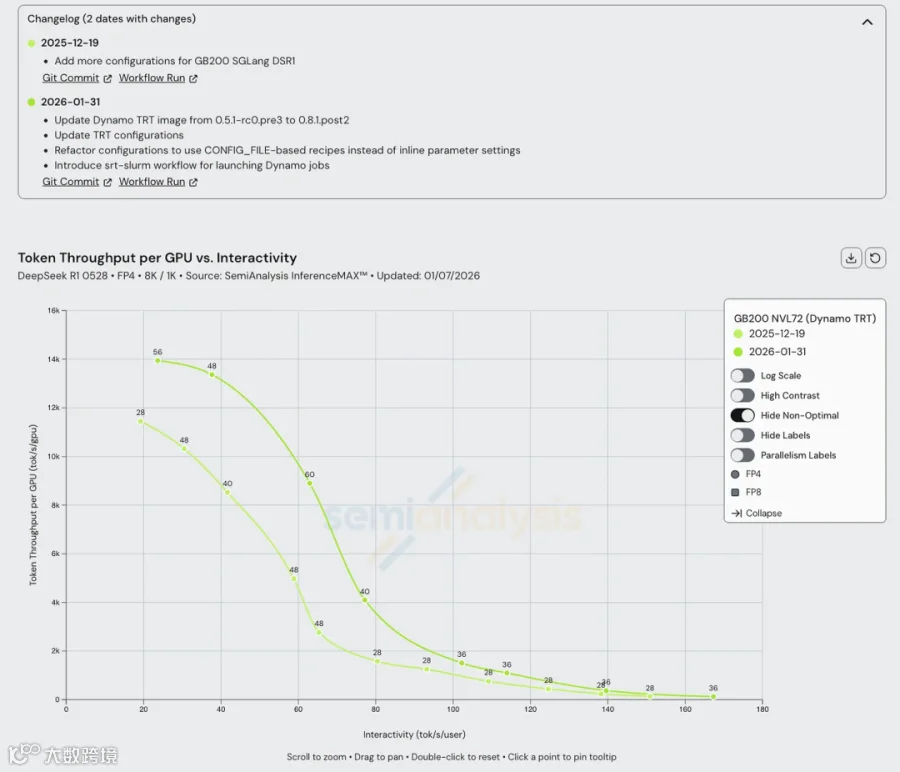
其实最近 SemiAnalysis [7] 也报道过,NVIDIA Dynamo TRT 1个月的优化,大幅提升了 GB200 NVL72 上的吞吐,如下图所示:
四、硬件
4.1 NVIDIA 硬件演进
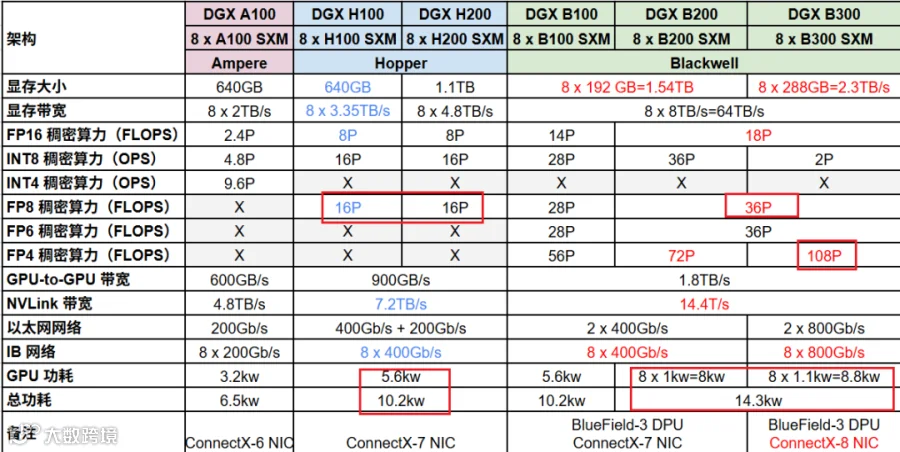
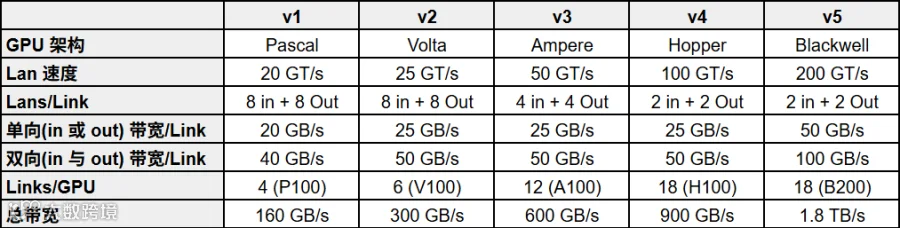
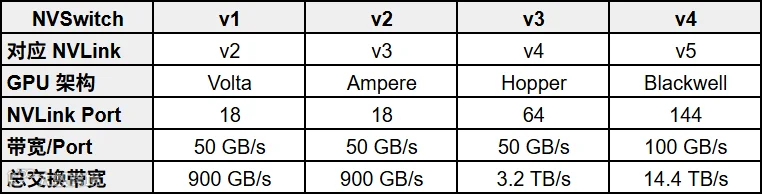
其中非常关键的部分是 NVLink 和 NVSwitch 的快速迭代,如下图所示:
4.1.1 Volta
比较早期的 V100 和 NVLink-2 Switch:

4.1.2 Ampere
A100、NVLink-3 Switch。以及:
CX-6 网卡:200 Gb/s(ConnectX-6 Dx Datasheet | NVIDIA [8])。
Quantum-1 IB Switch:40 个 200Gb/s Port(qm8700-datasheet [9])。
DGX A100:8 个 A100、NVSwitch、8 个后端 CX-6 网卡 等。

4.1.3 Hopper
H100、NVLink-4 Switch。还有:
CX-7 网卡:400 Gb/s(nvidia connectx-7 400g ethernet [10])。
Quantum-2 IB Switch:64 个 400Gb/s Port(QM97XX 1U NDR 400Gbps InfiniBand Switch Systems User Manual [11])。
BlueField-3:(NVIDIA BLUEFIELD-3 DPU [12])
1, 2, 4 Port,最高总带宽到 400Gb/s。
16GB 板载 DDR5 内存。
DGX H100:8 个 H100、NVSwitch、后端 8 个 CX-7 IB 网卡等。

4.1.4 Blackwell
B200/B300、NVLink-5 Switch。还有:
Grace CPU:72 个 Arm CPU Core,搭载 500GB/s 的 LPDDR5X 内存。
CX-8 网卡:800 Gb/s(NVIDIA ConnectX-8 InfiniBand SuperNIC [13])。(这里需要注意,IB 网卡是 800Gb/s,Ethernet 是 400Gb/s)
Spectrum-4 Ethernet Switch:128 个 400Gb/s Port 或 64 个 800Gb/s Port(NVIDIA Spectrum-4 SN5000 2U Switch Systems Hardware User Manual [14])。
BlueField-3:(NVIDIA BLUEFIELD-3 DPU [15])
1, 2, 4 Port,最高总带宽到 400Gb/s。
16GB 板载 DDR5 内存。
Compute Tray:对应 GB200-NVL72、GB300-NVL72 的 Compute Tray,2 个 Grace CPU,4 个 GB200/GB300 GPU。
NVLink Switch Tray:2 个 NVSwitch 芯片,用于 NVLink Spine。
NVLink Spine:也就是 9 个 NVSwitch Tray 组成的 NVLink Switch System,支持 72 个 1.8TB/s 的 Port,也就是 130TB/s 交换带宽。
DGX B300:8 个 B300、NVSwitch、后端 8 个 CX-8 IB 网卡等(NVIDIA DGX B300 Datasheet [16])。

4.1.5 Rubin
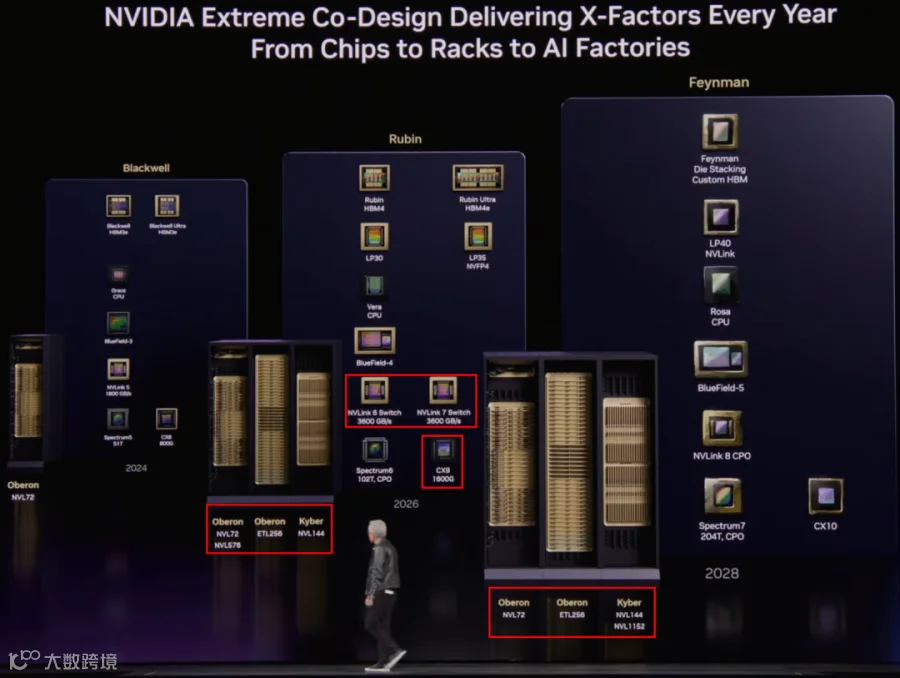
除了之前已经介绍过的 Rubin GPU、Vera CPU 外还有 CX-9 网卡、BlueField-4、NVLink-6 Switch 以及 Spectrum-X CPO 交换机,Groq-3 LPU 等,下面会重点介绍。


如下图所示,同样的 1GW AI Factory,使用 Vera Rubin 相比 X86+Hopper 可以获得 16/1.2=13.3x 的算力,50x(2 EB/s vs 100 EB/s)的内存带宽,350x Token 吞吐(2M vs 700M TPS)。

4.1.6 Feynman
Rubin 系列依旧会有一些升级:
NVLink-6 Switch 进一步升级到 NVLink-7 Switch,都是 3.6TB/s,Port 变多?
CX-9 网卡进一步从 800Gb/s 升级到 1600Gb/s。
新的 Kyber Rack 方案。
Rubin Ultra 支持 HBM4e。
Groq LP35 支持 NVFP4。
新一代的 Feynman 架构:
Feynman GPU 使用定制的 HBM。
Groq LP35 -> Groq LP40 支持 NVLink。
Vera CPU -> Rosa CPU。
BlueField-5 DPU。
NVLink-8 采用 CPO 封装。
Spectrum-6 102T -> Spectrum-7 204T,依然 CPO 封装。
CX-9 -> CX-10。
5.2 新硬件
5.2.1 几种 Tray
如下所示分别是:
Groq-3 LPU Tray:8 个 Groq-3 LPU。
NVLink-6 Switch Tray:支持 3.6TB/s NVLink。
Vera-Rubin Tray:2 个 Vera CPU、4 个 Rubin GPU。

如下所示分别是:
BlueField-4 DPU Tray:800Gb/s NIC,128GB LPDDR5,PCIe Gen6x16,可插拔 512GB SSD。
Vera CPU Tray:8 个 Vera CPU。
Spectrum-6 CPO Switch Tray:128 个 800Gb/s Port,102.4Tb/s 带宽。

5.2.2 Rubin Ultra Kyber 垂直机架
专为 Rubin Ultra 设计,全新的 Kyber Rack,以替代 Oberon Rack,和传统的水平插拔不同,Kyber 采用垂直插拔设计,通过背板的中板(Midplane)连接。可以实现 144 GPU 的 NVLink 互联。
Rubin Ultra Node:
2 个 Vera CPU。
4 个 Rubin Ultra GPU。
Kyber Midplane:Rubin Ultra Node Tray 竖着插到 Midplane,竖向 4 个口。共有 18 列,可以接 18 个 Rubin Ultra Node Tray。
NVSwitch-7 模组:接到 Midplane 的背面,也是竖着放,实现 144 GPU 的 NVLink 全互联。
Kyber Rack - Rubin Ultra 144:可以看成一个三明治结构,实现 144 GPU NVLink 全互联而无需铜缆:
前层:36 个 Compute Tray,分上下两组,每组 18 个竖放,每组接到一个 Midplane 上。
中层:Midplane,上下两组,各对应 18 个 Compute Tray。
后层:NVSwitch-7 模组和背板,竖放,接在 Midplane 的背面。


5.2.3 Groq-3 LPU
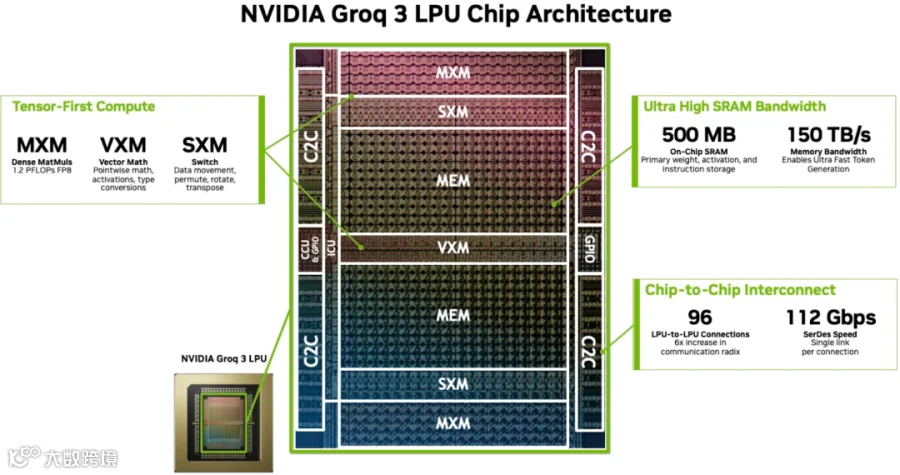
如下图所示,首次发布 Groq-3 LPU,其有超大的 SRAM:
每个芯片 500MB SRAM。
150 TB/s SRAM 带宽,非常适合 Memory Bound 明显的 LLM Decoding。
目前不支持 NVFP4,只提供 1.2 PFLOPs 的 FP8 算力。

如下图所示为 Groq-3 LPU 的架构图:
MXM:矩阵执行模块,主要负责乘加累积张量运算(矩阵-矩阵/矩阵-向量乘法),1.2PFLOPs 的 FP8 算力。
VXM:向量执行模块,处理 Pointwise 算术运算,比如向量加减法、类型转换、激活函数(ReLU、SiLU)等。
SXM:交换/开关执行模块,负责结构化数据移动和重塑,比如 Permutation、转置等。
MEM:SRAM,500MB,150TB/s 带宽。
C2C:支持 LPU 之间的高速连接。
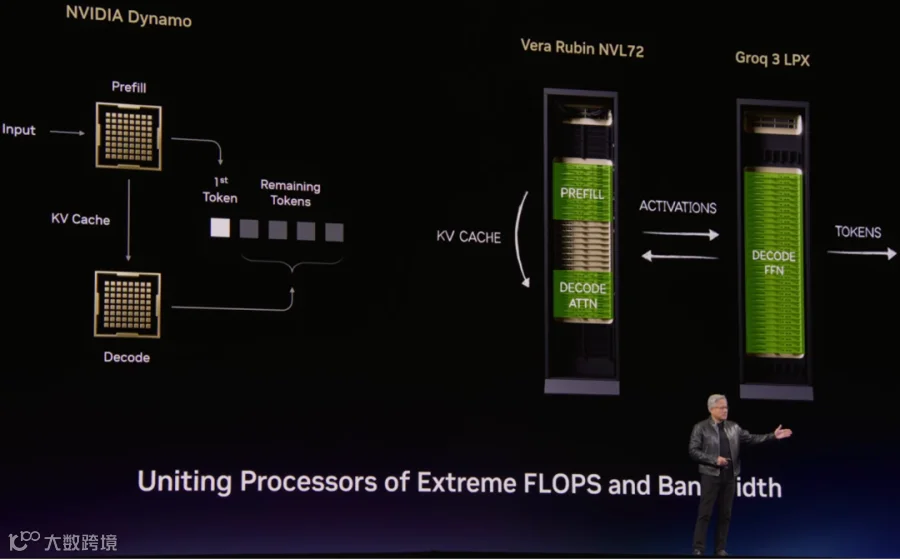
5.2.4 基于 Groq-3 LPU 的 AFD 异构框架
将 Groq-3 LPU 用于 AFD(可以参考字节:[2504.02263] MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism [17]) 异构框架中的 FFN Decoding,具体来说:
Vera Rubin NVL72 中:
部分 GPU 执行 Prefill。
部分 GPU 执行 Decoding 的 Attention。
KV Cache 可以通过 NVLink 或网络传输。
Groq-3 LPU Rack:
负责执行 Decoding 中的 FFN 操作。细粒度专家场景,Memory Bound 的问题比较明显。
需要和 Vera Rubin NVL72 之间传输激活,通过网络传输。
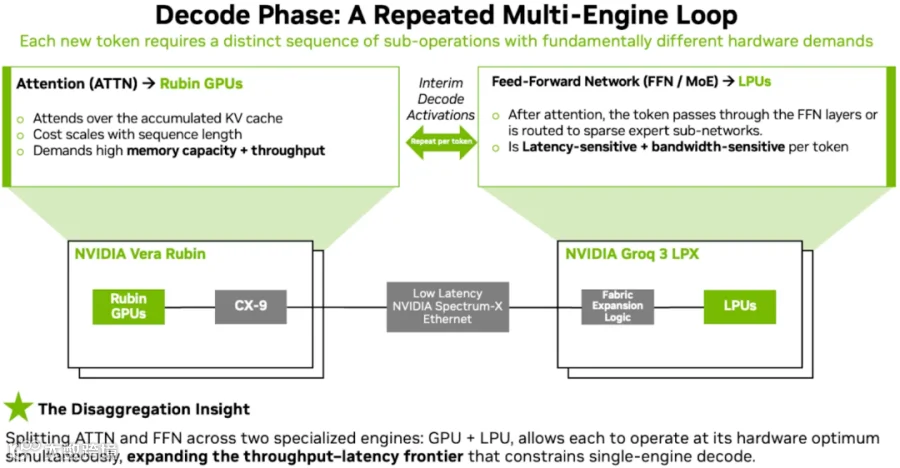
如下图所示为 Groq-3 LPX Rack:
每个 Tray:
8 个 Groq-3 LPU。
一个 Host CPU。
一个 BlueField-4 DPU。
包含 32 个 Tray:
8*32=256 个 Groq-3 LPU。
1.2*256=315 PFLOPs。
500MB*256=128GB SRAM。
150TB/s*256=40PB/s 带宽。

5.2.5 800Gb/s CPO Switch
CPO (Co-Packaged Optics,光电共封装)直接将光引擎(硅光芯片)与 ASIC Switch 芯片封装在同一个载板(Substrate)上,形成一个超级芯片模组。这样做的好处是可以获得更低的功耗、更低的延迟:在 800G/1.6T 时代,光模块中 DSP 芯片功耗可达整个光模块功耗 50%,CPO 可以去掉 DSP,功耗降低约 50%,且传输延迟近乎为零。
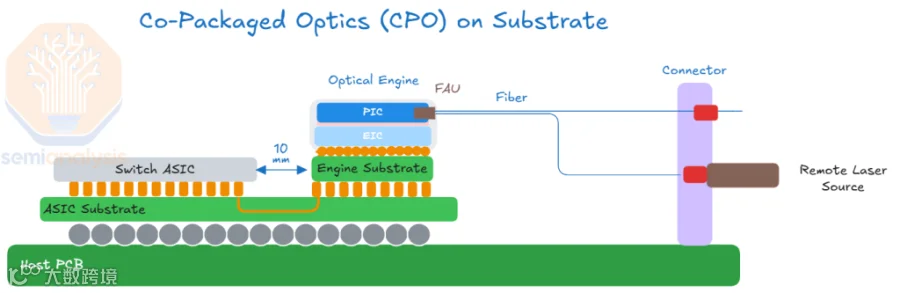
基于此,NVIDIA 在 800Gb/s Switch 中开始采用 CPO 方式,推出对应的 Quantum-X IB Photonics Switch 和 Spectrum-X Ethernet Photonics Switch(Silicon Photonics Networking for Agentic AI | NVIDIA [18])。如下图所示:

如下图所示,其中 Quantum-X Photonics CPO Switch 提供 144 个 800Gb/s 的 Port(MPO 连接器,下图黄线连接部分),高达 115Tb/s 的吞吐:

然而 CPO 也有其局限性,对良品率、无故障时间都有更高的要求,不可插拔的光模块导致维护成本明显提升,一旦故障可能需要整个 Switch 维修或替换,涉及的节点数非常多。通过备机替换再维修的方式可以大幅降低影响周期。
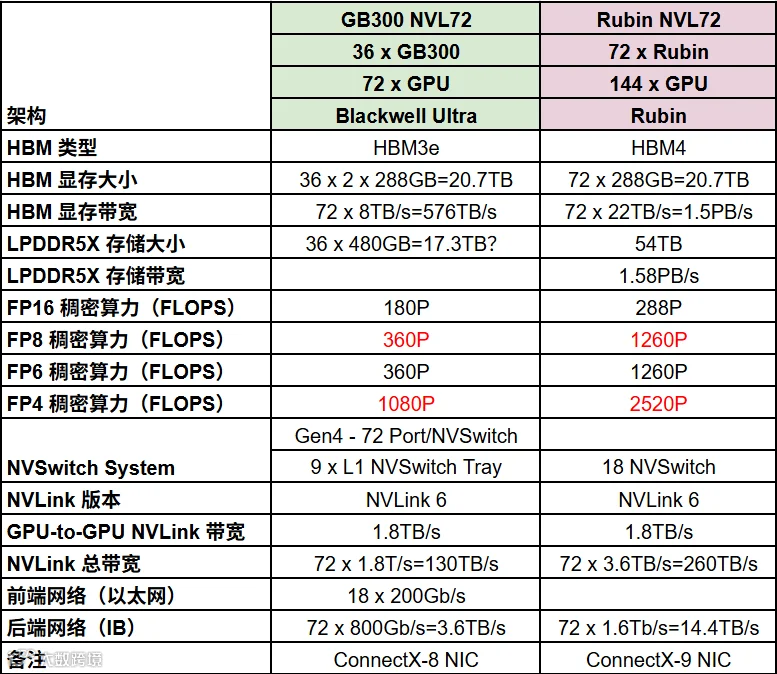
5.3 Rubin 的性能提升
如下图所示,不同的模型、序列长度在 Rubin NVL72 和 Blackwell NVL72 上的性能对比:
Qwen3-235B 32K:2x 吞吐,主要是算力大概是 2-3x 的关系,TPS/User 要求不高,Batch 比较大,基本上 Memory Bound 的问题也不是特别明显。
Kimi-K2.5-1T 128K:2x,同上。
GPT-MoE-2T 128K:3x,模型更大,TPS/User 要求更高,Rubin NVL72 优势更明显。
GPT-MoE-2T 400K:10x,序列更长,TPS/User 要求非常高,Memory 的瓶颈更明显。(PS:这里也可以看出,GPT5 应该是一个 2T 的 MoE 模型)
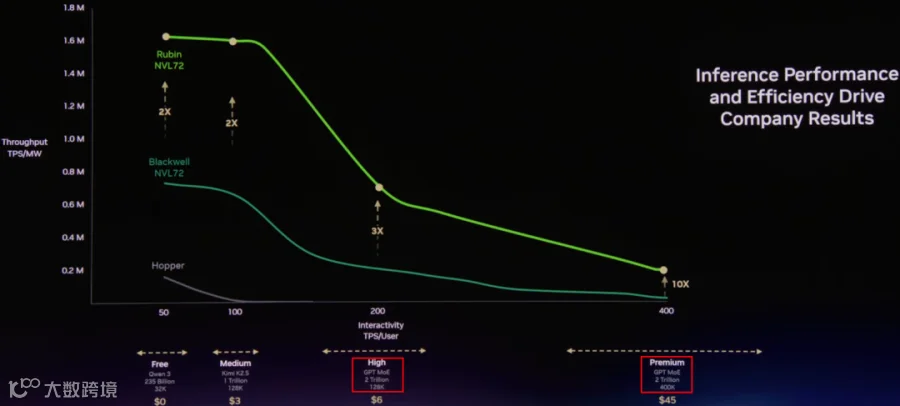
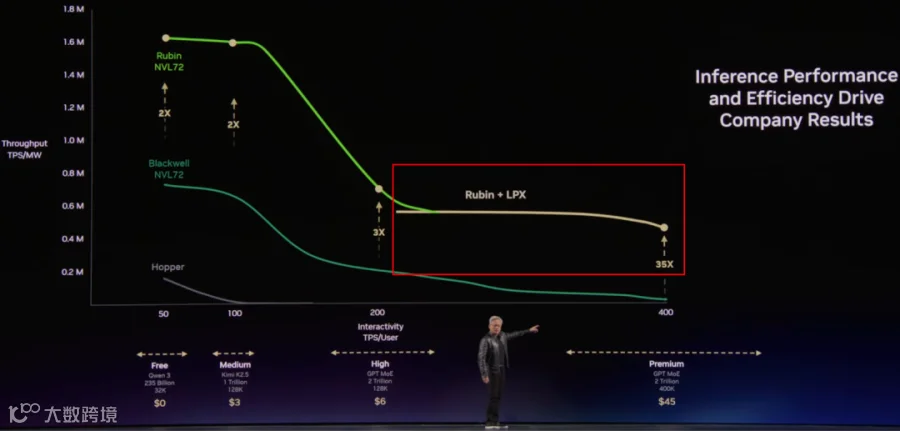
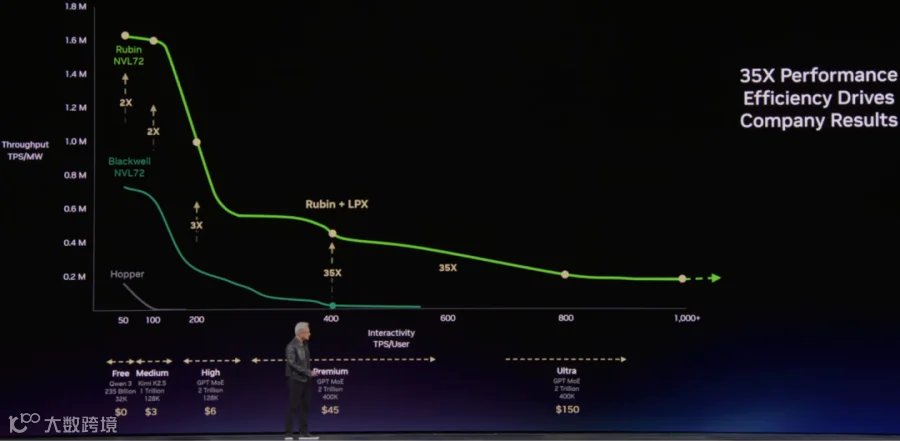
如下图所示,当 TPS/User 要求比较高时,Rubin + LPX 方案相比单纯的 Rubin NVL72 能获得更高的 TPS/MW。在此场景下,Decoding MoE 的 Batch Size 相对比较小,Memory Bound 问题非常明显,也正是适合 Groq-3 LPU 的场景。
六、参考连接
https://www.nvidia.com/gtc/keynote/
https://github.com/rapidsai/cudf
https://developer.nvidia.com/cuvs?sortBy=developer_learning_library%2Fsort%2Ftitle%3Aasc
https://github.com/rapidsai/cuvs
https://milvus.io/
https://inferencex.semianalysis.com/
https://semianalysis.com/
https://www.nvidia.com/content/dam/en-zz/Solutions/networking/ethernet-adapters/connectX-6-dx-datasheet.pdf
https://nvdam.widen.net/s/zmbw7rdjml/infiniband-qm8700-datasheet-us-nvidia-1746790-r12-web
https://www.nvidia.com/content/dam/en-zz/Solutions/networking/ethernet-adapters/connectx-7-datasheet-Final.pdf
https://docs.nvidia.com/networking/display/qm97xx-1u-ndr-400gbps-infiniband-switch-systems-user-manual.pdf
https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/documents/datasheet-nvidia-bluefield-3-dpu.pdf
https://applieddatasystems.com/wp-content/uploads/2024/07/connectx-datasheet-connectx-8-supernic-3231505.pdf
https://docs.nvidia.com/networking/display/nvidia-spectrum-4-sn5000-2u-switch-systems-hardware-user-manual.pdf
https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/documents/datasheet-nvidia-bluefield-3-dpu.pdf
https://resources.nvidia.com/en-us-dgx-systems/dgx-b300-datasheet
https://arxiv.org/abs/2504.02263
https://www.nvidia.com/en-us/networking/products/silicon-photonics/