
一、引言
最近 NVIDIA 召开了 GTC-2026 大会,更新一系列 Rubin Platform 产品,并开始逐步量产,标志着下一代 Rubin 架构真正商用的到来。本文中我们对相应的产品和参数进行总结,相关数据主要来自 NVIDIA 官网和 GTC-2026 大会。

相关工作可以参考笔者之前的文章:
二、相关硬件
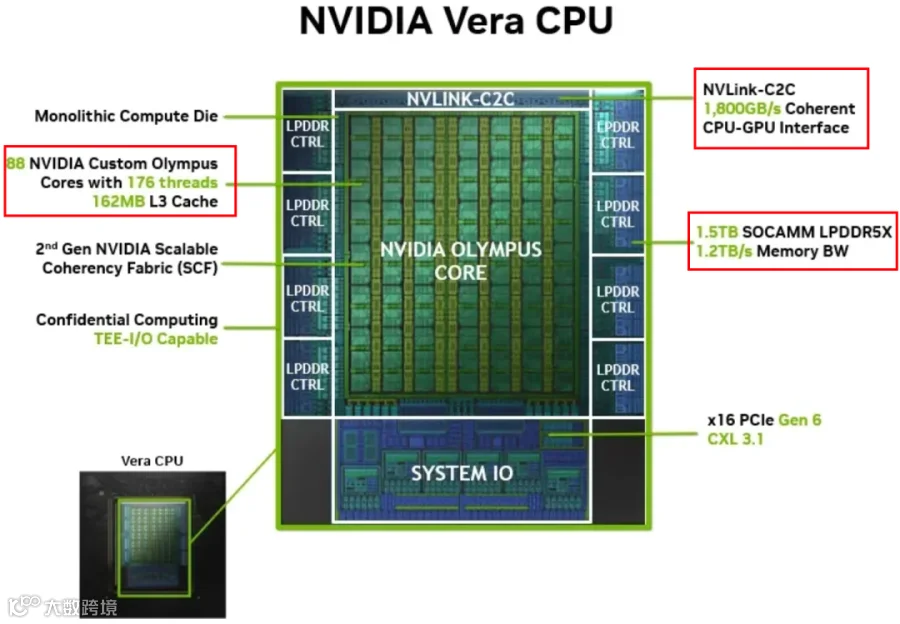
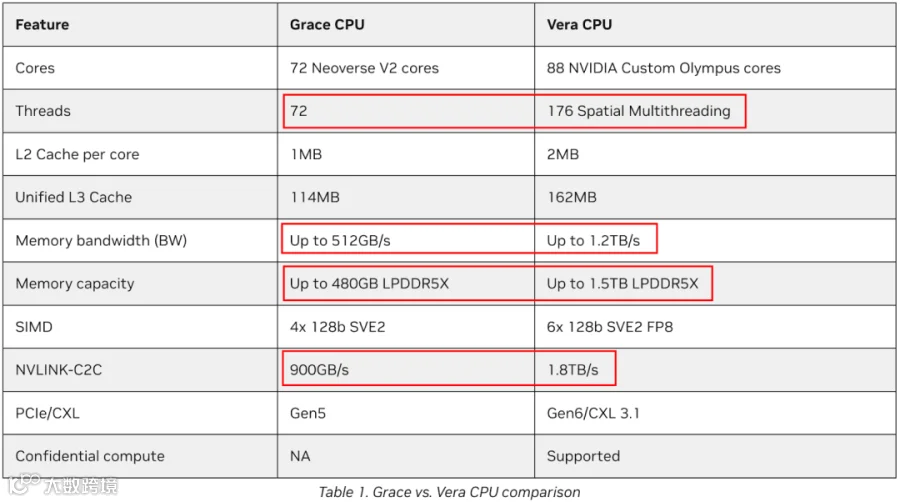
2.1 Vera CPU
GB200/GB300 上使用的 Grace CPU 的下一代:
88 个 Arm Core,176 线程。
1.8 TB/s 的 NVLink-C2C 带宽。
1.5TB LPDDR5X 内存,带宽为 1.2TB/s。
2.2 GPU
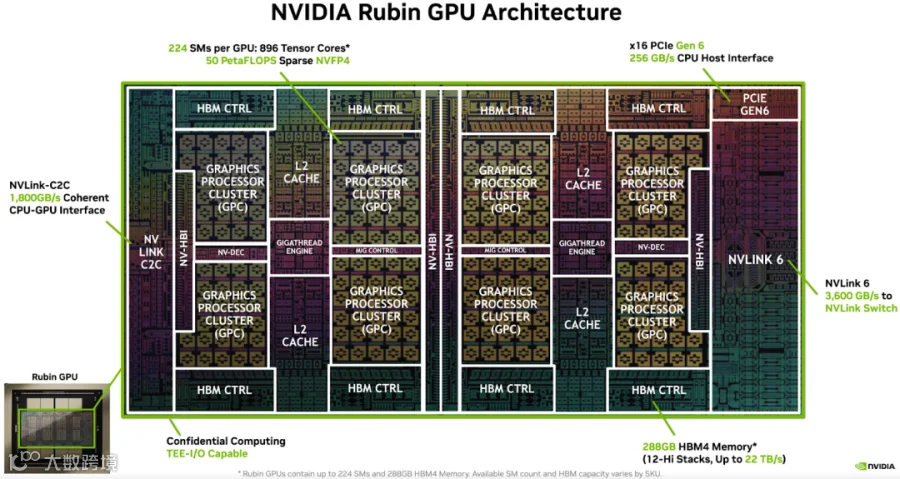
2.2.1 Rubin GPU
如下图所示为最基础的 Rubin GPU:
算力:
每个 GPU 2 个 Die,中间通过 NV-HBI 连接,共 224 个 SM,896 Tensor Core。
FP16 稠密:4P(比 Blackwell 200/300 的 2.25P 的 1.78x)
FP8 稠密:17.5P(是 Blackwell 200/300 的 5P 的 3.5x)
NVFP4 稠密(Training):35P(是 Blackwell B300 的 13.5P 的 2.6x)
NVFP4 稀疏(Inference):50P(是 Blackwell B300 的 15P 的 3.5x)
NVLink-6 带宽:3.6TB/s(是 Blackwell B300 的 1.8TB/s 的 2x)
288GB HBM4 显存,带宽 22TB/s(是 Blackwell B300 的 8TB/s 的 2.75x)

2.2.2 Rubin Ultra GPU
如下图所示为最基础的 Rubin Ultra GPU(图中是 Rubin Ultra NVL576,是早起按照 Die 数量命名,后续改为按 GPU 数量,对应 Rubin Ultra NVL144;此外,左侧机柜为上一代方案,GTC2026 上有了新的机柜方案):
算力(基本上是 Rubin GPU 的 2x):
FP16 稠密:8P(比 Blackwell 200/300 的 2.25P 的 3.56x)
FP8 稠密:35P(是 Blackwell 200/300 的 5P 的 7x)
NVFP4 稠密(Training):70P(是 Blackwell B200/B300 的 10P 的 7x)
NVFP4 稀疏(Inference):100P(是 Blackwell B300 的 15P 的 7x)
NVLink-7 带宽:10.8TB/s(是 Blackwell B300 的 1.8TB/s 的 6x)
1TB HBM4e 显存,带宽 32TB/s - 64TB/s 之间,NVIDIA 没有提供(是 Blackwell B300 的 8TB/s 的 4x-8x)。
Scale-Out 网络带宽:按下图是 115.2TB/s / 144 = 6.4Tb/s。(PS:这里感觉有问题,Vera Rubin NVL72 每个 GPU 对应的网卡只有 1.6Tb/s,Rubin Ultra 算力扩大 2x,不太可能网络带宽扩大 4x。)

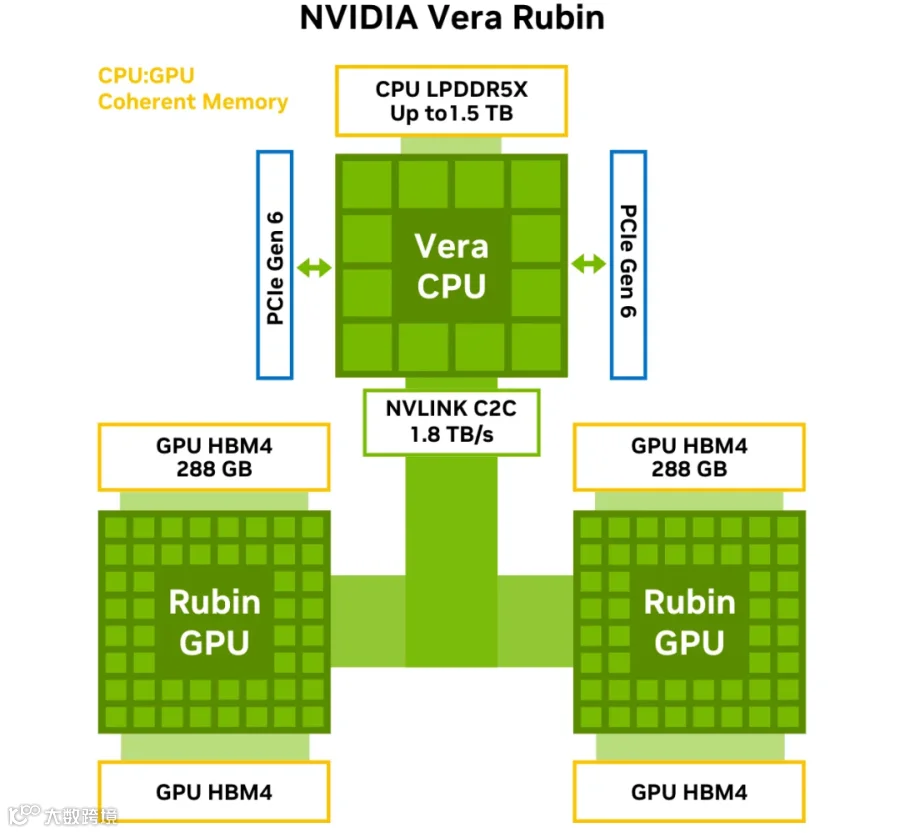
2.2.3 Vera Rubin SuperChip
和 GB200/GB300 类似,1 个 Vera CPU + 2 个 Rubin GPU,通过 NVLink-C2C 连接:
2.3 Groq-3 LPU
如下图所示,NVIDIA 花费 $20 B 收购 Groq 后,于 GTC2026 首次发布 Groq-3 LPU(Language Processing Unit),其有超大的 SRAM,带宽非常高。该芯片的定位并非是取代 Rubin GPU,而是弥补 NVIDIA Rubin GPU + 细粒度 MoE 模型在 Agentic 场景利用率不高的问题。
每个芯片 500MB SRAM。
SRAM 具备 150 TB/s 超高带宽,是 Rubin GPU HBM4 的 7x,非常适合 Memory Bound 明显的 LLM Decoding。
目前不支持 NVFP4,只提供 1.2 PFLOPs 的 FP8 算力。

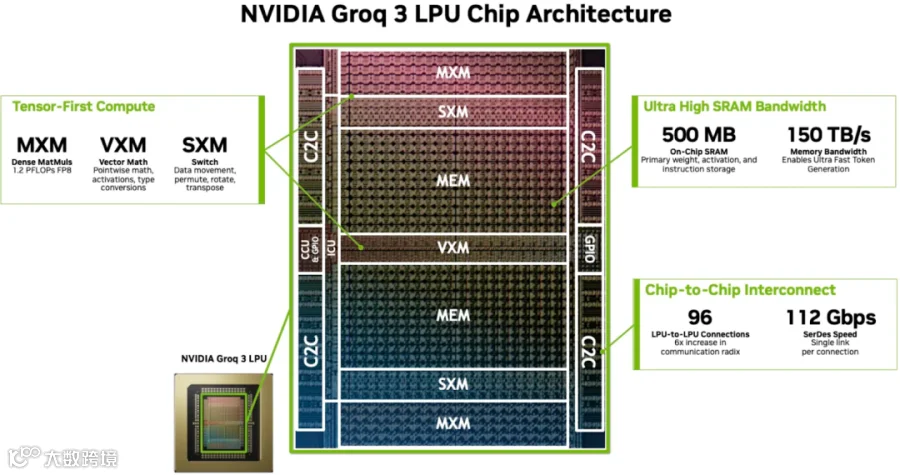
如下图所示为 Groq-3 LPU 的架构图:
MXM:矩阵执行模块,主要负责乘加累积张量运算(矩阵-矩阵/矩阵-向量乘法),1.2PFLOPs 的 FP8 算力。
VXM:向量执行模块,处理 Pointwise 算术运算,比如向量加减法、类型转换、激活函数(ReLU、SiLU)等。
SXM:交换/开关执行模块,负责结构化数据移动和重塑,比如 Permutation、转置等。
MEM:SRAM,500MB,150TB/s 带宽。
C2C:支持 LPU 之间的高速连接。
2.4 NVLink-6 Switch
NVSwitch 也伴随着 NVLink-6 升级:
每个 NVLink-6 Switch Tray:
包含 4 个 NVSwitch 芯片,可以提供 28.8TB/s 的聚合带宽。
提供 4 * 3.2 TFLOPS=12.8 TFLOPS 的计算能力(PS:用于 AllReduce 等)。
NVLink-6 Switch Rack:
9 个 NVLink-6 Switch Tray 可以实现 260Tb/s 的带宽,支持 Vera Rubin NVL72 的 NVLink 全互联。


2.5 ConnectX-9 SuperNIC
由于标准制定的原因,NVIDIA 在推出 CX-8 网卡时并不能提供 800Gb/s 的 Ethernet Port,只能 2 个 400 Gb/s Port,但是 IB Port 却可以到 800 Gb/s。在新的 CX-9 网卡中改进了这一问题,Ethernet 和 IB 都可以支持 800 Gb/s Port。该

因为 CX-8 和 CX-9 的最大总带宽都是 800Gb/s,为了在 Vera Rubin NVL144 和 Vera Rubin Ultra NVL144 中支持更大的 Scale-Out 带宽,NVIDIA 选择了每个 GPU 多个 Port(Switch 芯片)的方案。如下图所示:
左图 2 个 CX-9 Switch 芯片,可以提供 2 个 800Gb/s Port,总带宽 1.6Tb/s。
右图 1 个 CX-9 Switch 芯片,可以提供 1 个 800Gb/s Port,总带宽 800Gb/s。

2.6 CPO 交换机
CPO (Co-Packaged Optics,光电共封装)直接将光引擎(硅光芯片)与 ASIC Switch 芯片封装在同一个载板(Substrate)上,形成一个超级芯片模组。这样做的好处是可以获得更低的功耗、更低的延迟:在 800G/1.6T 时代,光模块中 DSP 芯片功耗可达整个光模块功耗 50%,CPO 可以去掉 DSP,功耗降低约 50%,且传输延迟近乎为零。
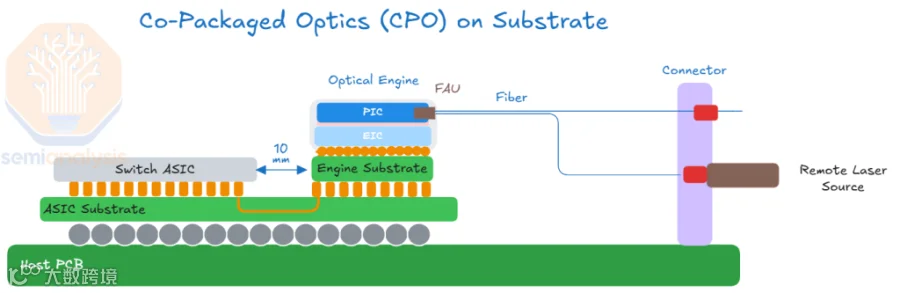
基于此,NVIDIA 在 800Gb/s Switch 中开始采用 CPO 方式,推出对应的 Quantum-X IB Photonics Switch 和 Spectrum-X Ethernet Photonics Switch(Silicon Photonics Networking for Agentic AI | NVIDIA)。
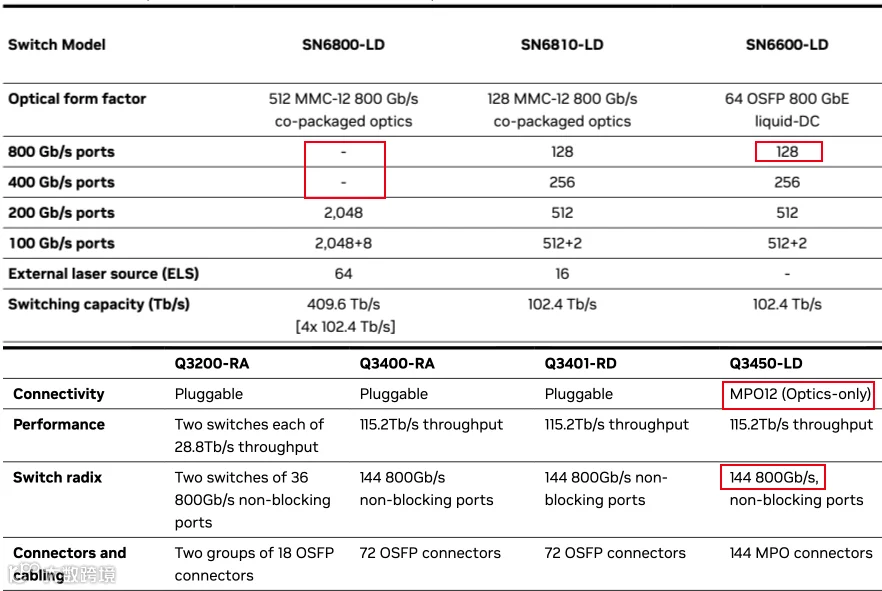
上图:Spectrum-6 SN6000(Ethernet):最多 128 个 800Gb/s Port,最大 102.4Tb/s 总带宽,2-Tier 就可以支持 10 万卡。
下图 Quantum-X800(IB):最多 144 个 800Gb/s Port,最大 115.2Tb/s 总带宽。
如下图所示为 Spectrum-X 支持的 4 平面拓扑:
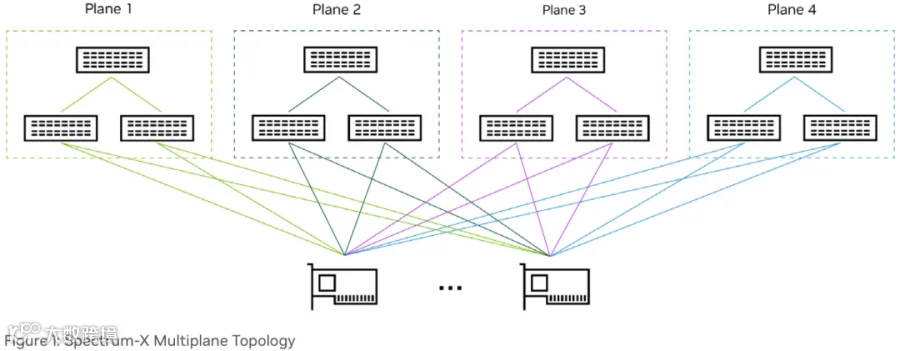
如下图所示,其中 Quantum-X Photonics CPO Switch(Q3450-LD) 提供 144 个 800Gb/s 的 Port(MPO 连接器,下图黄线连接部分):

然而 CPO 也有其局限性,对良品率、无故障时间都有更高的要求,不可插拔的光模块导致维护成本明显提升,一旦故障可能需要整个 Switch 维修或替换,涉及的节点数非常多。通过备机替换再维修的方式可以大幅降低影响周期。
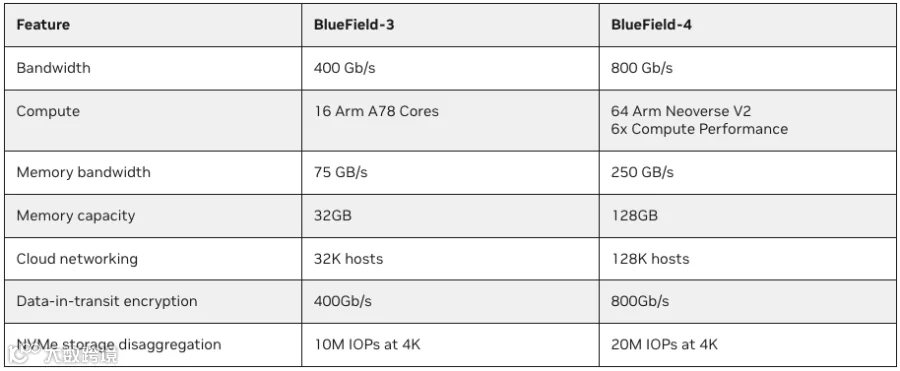
2.7 BlueField-4 DPU
如下图所示,BlueField DPU 也升级到第四代,使用的网卡从 CX-7 的 400Gb/s 升级到 CX-9 的 800Gb/s。与此内存,内存带宽和 Arm 核都有 4x 提升:

三、服务器 & Rack
3.1 DGX Rubin NVL8
DGX Rubin NVL8 是 DGX B300 的继任者,其配置如下图所示:

3.2 Vera Rubin NVL72
3.2.1 Vera Rubin NVL72 Compute Tray
如下图所示为 Vera Rubin NVL72 中使用的 Compute Tray,其包括:
2 个 Vera Rubin SuperChip,2 个 Vera CPU,4 个 Rubin GPU。
1 个 BlueField-4 DPU,800Gb/s NIC。
8 个 CX-9 芯片,每个 GPU 2 个 800Gb/s Port,带宽 1.6Tb/s。
100% 的液冷。

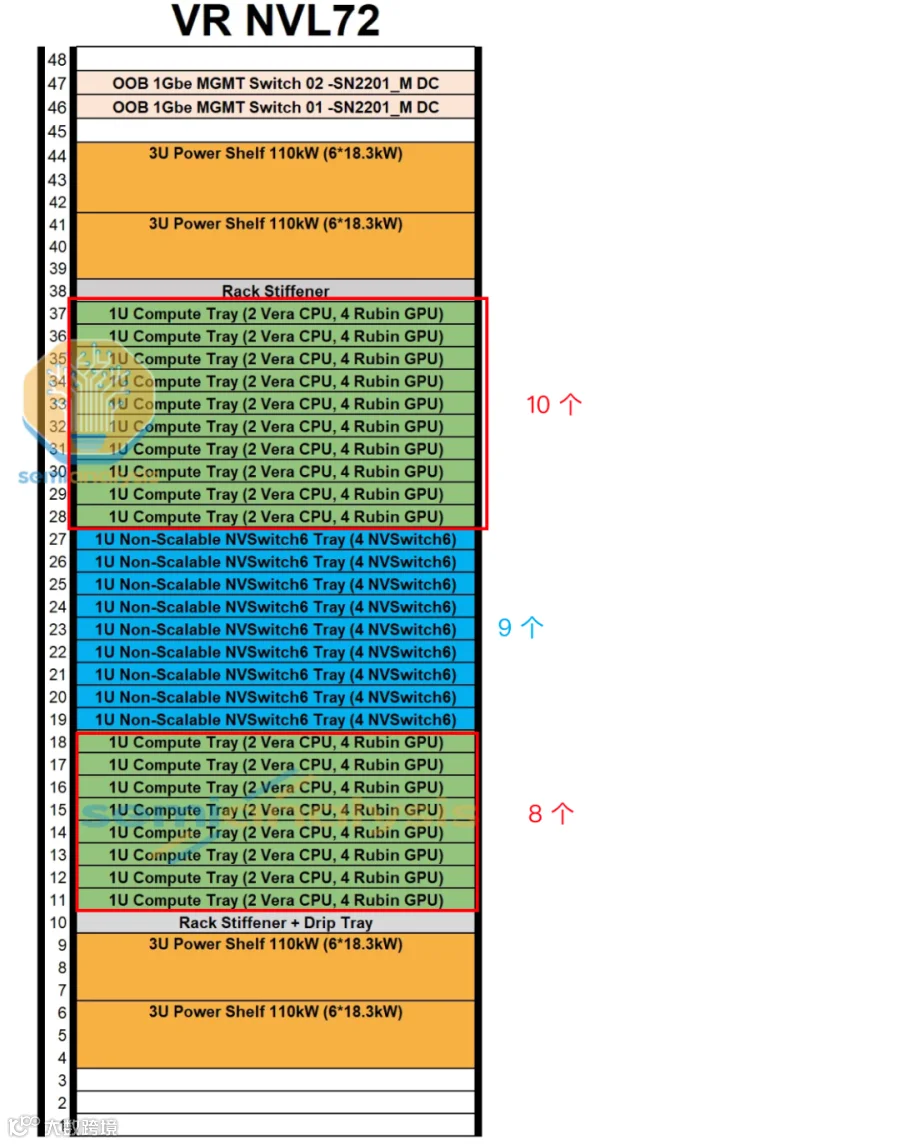
3.2.2 Vera Rubin NVL72 Rack
如下图所示为标准的 Vera Rubin NVL72 Rack,共包含:
18 个 Compute Tray,36 个 Vera CPU,72 个 Rubin GPU。
9 个 NVSwitch Tray,9*28.8TB/s=259.2TB/s NVLink 聚合带宽。
4 个 110kW Power Tray(2 x 220kW)。
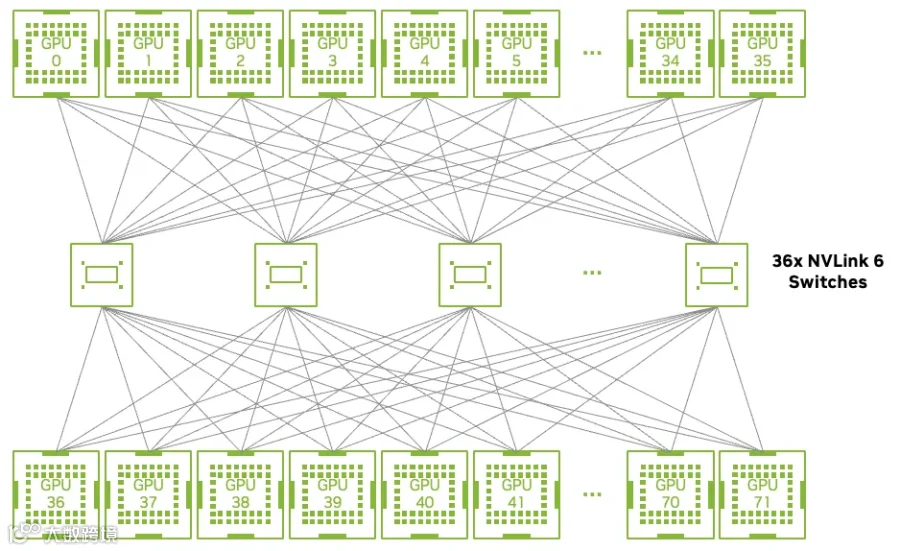
如下图所示,9 个 NVSwitch Tray,36 个 NVLink-6 Switch 芯片可以实现 72 个 GPU 的 NVLink 全互联:
3.3 Vera Rubin Ultra NVL144
3.3.1 Rubin Ultra Kyber 垂直机架
专为 Rubin Ultra 设计,全新的 Kyber Rack,以替代之前的 Oberon Rack,和传统的水平插拔不同,Kyber 采用垂直插拔设计,通过背板的中板(Midplane)连接。可以实现 144 GPU 的 NVLink 互联。
Rubin Ultra Node:
2 个 Vera CPU。
4 个 Rubin Ultra GPU。
Kyber Midplane:Rubin Ultra Node Tray 竖着插到 Midplane,竖向 4 个口。共有 18 列,可以接 18 个 Rubin Ultra Node Tray。
NVSwitch-7 模组:接到 Midplane 的背面,也是竖着放,实现 144 GPU 的 NVLink 全互联。


基于 Kyber Rack 的 Rubin Ultra NVL144 可以看成一个三明治结构,实现 144 GPU NVLink 全互联而无需铜缆:
前层:
36 个 Compute Tray,分上下两组,每组 18 个竖放,每组接到一个 Midplane 上。
共 36 * 2 = 72 个 Vera Ultra CPU。
共 36 * 4 = 144 个 Rubin Ultra GPU。
中层:
Midplane,上下两组,各对应 18 个 Compute Tray。
后层:
NVSwitch-7 模组(包含 6 个 NVLink-7 Switch 芯片),竖放,接在 Midplane 的背面。
如下图所示为 NVIDIA Kyber NVL1152 Superpod 中使用的 Rubin Ultra NVL144 Rack,共 8 个 Rack,每个 Rack 都分上下两层 Compute Rack:

3.4 Groq-3 LPX
如下图所示,Groq-3 LPX 包含 32 个 Compute Tray:
256 个 Groq-3 LPU。
500MB * 256 = 128GB SRAM。(PS:这个相对来说有点小,无法存下整个模型,真正用于大模型 Decoding 的话需要结合 Prefetch 和 Overlap)
150TB/s * 256 = 38.4 PB/s 的 SRAM 带宽。

四、针对 Agentic 场景的 Vera Rubin NVL72 + Groq-3 LPX
4.1 Agentic 场景的挑战
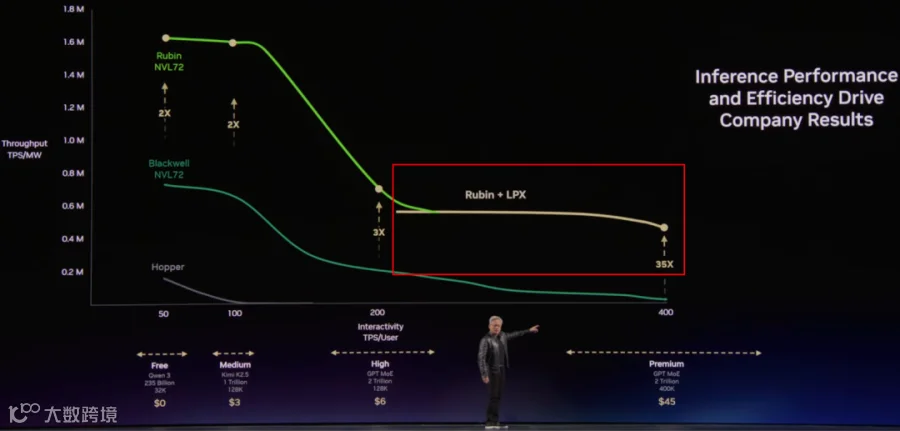
如下图所示,TPS/User 要求越高,TPS/MW(吞吐) 越低,这主要是因为 LLM Decoding 中提升吞吐的主要手段是 Continuous Batching,而 Continuous Batching 往往会导致 TPS/User 的降低,因此对于 TPS/User 要求比较高的场景往往无法达到比较大的 Batch Size,存在明显的 Memory Bound 问题。
左(TPS/User <= 100):Rubin NVL72 和 Blackwell NVL72 还能达到比较高的 Batch Size,TPS/MW 基本与算力呈正比。
中(100 <= TPS/User <= 200):Blackwell NVL72 中 Batch Size 下降的更多,TPS/MW 下降的更快,Rubin NVL72 的优势开始凸显。
右(200 <= TPS/User):TPS/User 要求非常高,Rubin NVL72 的优势非常明显,甚至 TPS/MW 达到 Blackwell NVL72 的 10x。
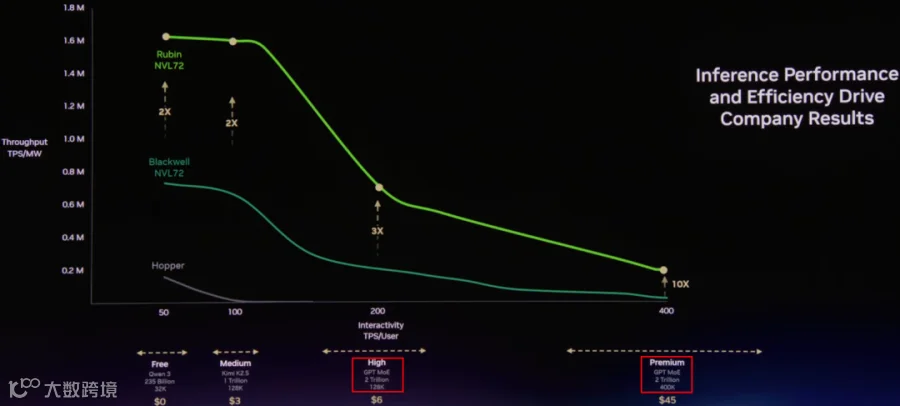
Agentic 场景通常包含非常长的 Reasoning Token,而用户通常可能不太关注这部分 Token,为了提升用户体验,就需要非常高的 TPS/User,将 Reasoning Token 的生成隐藏在用户关注的 Token 之下。
4.2 Vera Rubin NVL72 + Groq-3 LPX
4.2.1 架构
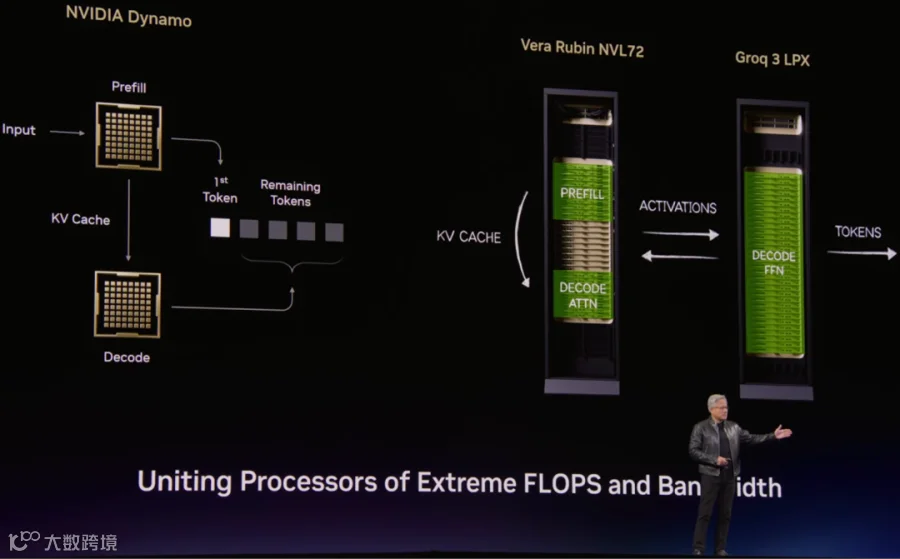
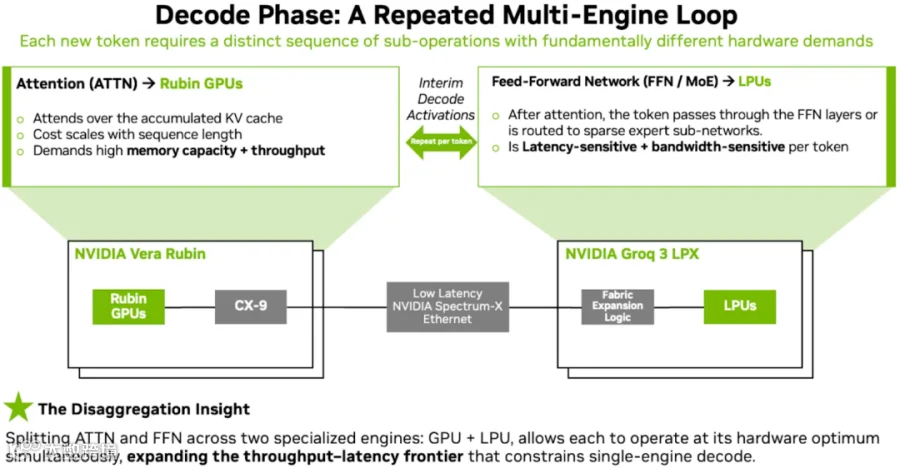
Groq-3 LPX 的超高 SRAM 带宽非常适合 Memory Bound 很明显的小 Batch Size Decoding 场景,正好可以弥补 200 <= TPS/User 时 TPS/MW 快速下降的问题。为此,NVIDIA 在 GTC2026 上重点介绍了 Vera Rubin NVL72 + Groq-3 LPX 的异构 AFD(Attention/MoE 分离)方案。如下图所示:
Vera Rubin NVL72 中(PS:这里没有使用 Vera Rubin Ultra NVL144):
部分 GPU 执行 Prefill(明显的 Compute Bound 场景,且需要很大的 Memory 空间存 KV Cache)。
部分 GPU 执行 Decoding 的 Attention(同样需要存储很大的 KV Cache,并且由于 GQA、MLA、Linear Attention 等方案的应用,Memory Bound 问题相对较小)。
KV Cache 可以通过 NVLink 或网络传输。
Groq-3 LPU Rack:
负责执行 Decoding 中的 FFN 操作。(细粒度专家场景,会明显降低算术强度,Memory Bound 的问题非常明显,主要需要存储 Expert 权重)
需要和 Vera Rubin NVL72 之间传输激活,通过网络传输。
4.2.2 结果
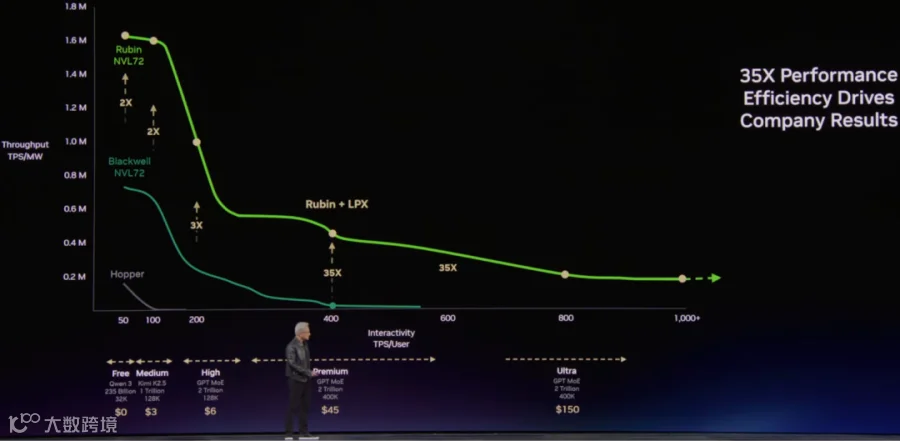
如下图所示,Rubin + LPX 的方案可以大幅缓解 200 <= TPS/User 时 TPS/MW 快速下降的问题,Rubin NVL71 + LPX 的方案相比 Blackwell NVL72 方案可以获得 35x 的 TPS/WM。此外,也可以获得更大的 TPS/User。
4.3 Rubin GPU + LPX 投机采样
如下图所示,也可以将 LPX 用于投机采样中的 Draft Model,可以快速生成草稿,然后 Rubin GPU 用于 Target Model 的快速验证。

五、对比
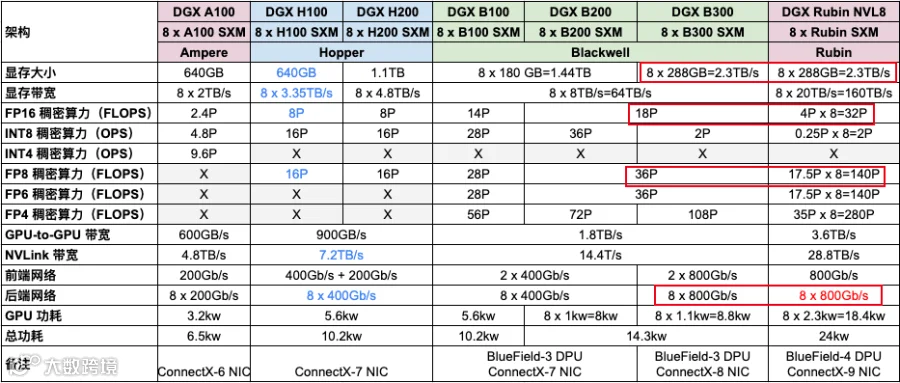
5.1 DGX Rubin NVL8 和 DGX B200/300 对比
如下图所示,展示了 DGX NVL8 系列的关键数据,重点对比 DGX Rubin NVL8 和 DGX B300,可以看成:
显存容量(288GB)、后端网络(8 x 800Gb/s)没有变化,可能成为瓶颈。
其他基本处于 2x-4x 之间:
FP16 稠密算力 32/18=1.8x。(PS:当前训练常用,不过也都再向 FP8 训练过渡)
FP8/FP6 稠密算力 140/36=3.9x。
FP4 稠密算力 280/108=2.6x。
显存带宽 160/64=2.5x。
NVLink 带宽 28.8/14.4=2x。
DGX Rubin NVL8 的优势是 FLOPS/W 更高,功耗只有 DGX B300 的 24/14.3=1.7x。
DGX Rubin NVL8 需要使用液冷。
5.2 NVL72/NVL144 对比
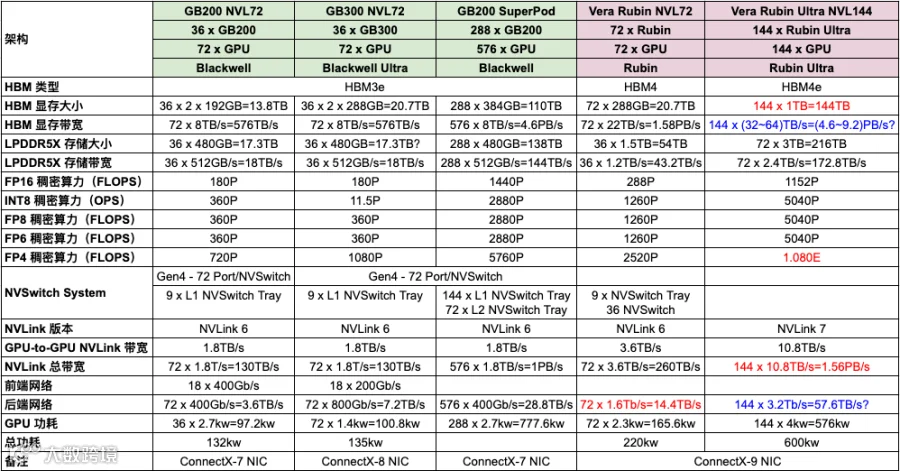
如下图所示,展示了 NVL72/NVL144 系列的关键数据:
GB300 NVL72 vs Vera Rubin NVL72
算力、HBM、NVLink 的差异与 DGX Rubin NVL8 vs DGX B300 的差异一致。
不同:
Vera Rubin NVL72 中每个 Rubin GPU 使用 2 个 CX-9 芯片,因此每 GPU 的 Scale-Out 网络带宽从 800Gb/s 提升到 1.6Tb/s。
Vera Rubin NVL72 中每个 Rubin GPU 显存带宽是 22TB/s,略高于 DGX Rubin NVL8 的 20TB/s(PS:还是 NVIDIA 写错了?)。
Rubin Ultra NVL144 vs Rubin NVL72:
由于 Rubin Ultra 变成 4 个 Die,算力是 Rubin 的 2x;此外数量从 72 -> 144 翻倍,所以 Rack 的算力是 4x 关系。
不同:
显存:
HBM4 -> HBM4e。
容量 288GB -> 1TB,GPU 维度 3.5x,Rack 维度 7x。
带宽 22TB/s -> 32TB/s~64TB/s 之间。
NVLink:
NVLink-6 -> NVLink-7
3.6TB/s -> 10.8TB/s,GPU 维度 3x,Rack 维度 6x。
Scale-Out 网卡:
大概率是从每 1.6Tb/s -> 3.2Tb/s,GPU 维度 2x,Rack 维度 4x。
功耗:
220kw -> 600kw,3x 左右。
六、相关链接:
Inside the NVIDIA Vera Rubin Platform: Six New Chips, One AI Supercomputer
NVIDIA Vera Rubin POD: Seven Chips, Five Rack-Scale Systems, One AI Supercomputer
Vera Rubin – Extreme Co-Design: An Evolution from Grace Blackwell Oberon
Keynote at NVIDIA GTC San Jose 2026
Silicon Photonics Networking for Agentic AI | NVIDIA
Infrastructure for Agentic AI at Scale | NVIDIA DGX Rubin NVL8
Rack-Scale Agentic AI Supercomputer | NVIDIA Vera Rubin NVL72