
一、引言
简单介绍一下 NVIDIA 最近在 GB200 NVL72 针对 MoE 模型的一个 Inference 优化工作,需要说明的是,这不是一个万能的解决方案,有很多约束,比如主要适合 Prefill 阶段,TPS/User 要求不能特别高,输入序列长度也不能特别大。除此之外,提升也不是非常明显。
对应的论文为:[2604.01621] DWDP: Distributed Weight Data Parallelism for High-Performance LLM Inference on NVL72 [1]
相关工作可以参考笔者之前的文章:
-
全面解析 NVIDIA 最新硬件:Vera/Rubin/Rubin Ultra/NVL72/NVL144/LPX 等 -
2 万字总结:全面梳理大模型 Inference 相关技术 -
分而治之:全面解析分布式分离 Inference 系统
二、摘要
LLM Inference 越来越依赖多 GPU 执行,但现有的 Inference 并行策略需要进行层间跨 Rank 同步,导致 End2End 性能对 Workload 不均衡异常敏感。
本文中,NVIDIA 提出 DWDP(Distributed Weight Data Parallelism),在保持数据并行执行的同时,将 MoE 权重卸载到 Peer GPU 并按需获取缺失专家的 Inference 并行化策略。通过消除跨节点全局同步操作,每个 GPU 都可以独立进行 Inference 计算。进一步通过两项优化——分片权重管理与异步远程权重预取——解决了该设计的开销问题。
作者在 TensorRT-LLM 中实现,并在 GB200 NVL72 机器上使用 DeepSeek-R1 验证,在 8K 输入和 1K 输出条件下,当服务吞吐量处于 20-100 TPS/User 区间时,DWDP 在保持相当 TPS/User 的同时,将 End2End 输出 TPS/GPU 提升 8.8%。
PS:需要说明的是,本文的方案只适合 Prefill 阶段,因为 Prefill 阶段许多 Token 同时 Forward,在任何一层基本上都会激活所有 Expert,在这一假设下,可以提前预取下一层的所有缺失专家。如果是 Decoding 阶段,则会涉及预取哪些 Expert 的问题。
三、背景
3.1 分布式并行同步开销
LLM 越来越大,单个 GPU 难以容纳模型权重和 KV Cache,对于较大模型,通常会采用多个 GPU 共同部署。为此,通常会在 Hidden 维度使用 TP(Tensor Parallelism)、MoE 部分使用 EP(Expert Parallelism),甚至在层间使用 PP(Pipeline Parallelism)。虽然它们在模型切分方式上有所不同,但都需要在层边界处引入同步操作。
在现实的 LLM Serving 场景中,各个计算单元的 Workload 可能不太均衡,这种逐层跨 Rank 同步的局限性越来越明显。比如表现在:
在 Request 层面,输入序列的长度不同,命中的 Prefix Cache 不同,导致计算和内存访问存在差距。
在 Weight 层面,各计算单元激活的模型计算量可能不同,比如 MoE 中,热门 Expert 可能承载更多 Token。
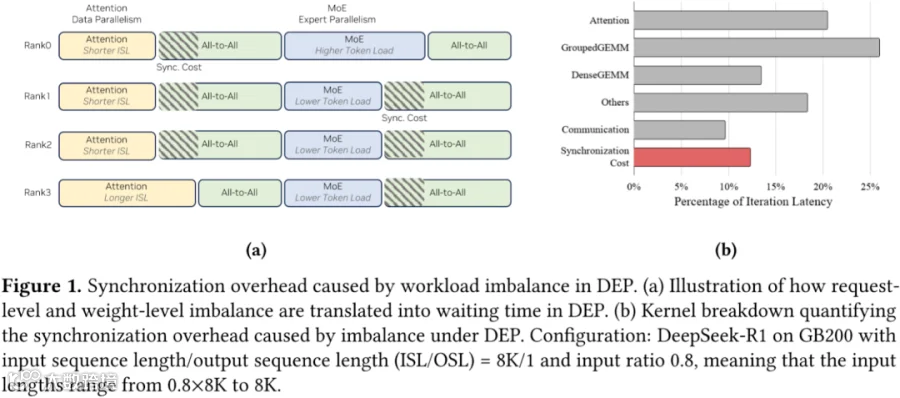
如下图 Figure 1 所示为大规模 MoE 模型中常用的 EDP(DP 和 EP)策略(Attention 部分采用 DP、MoE 部分采用 EP)。如(b)所示,其中同步开销占比达到 12%,来自两个部分,如下图 (a)所示:
DP 部分 Request 的不均衡,导致 MoE 之前的 All2All 有同步等待的 Bubble。
MoE 部分 Expert 负载的不均衡,导致 MoE 之后的 All2All 同样有同步等待的 Bubble。
3.2 快手 PROBE
在 [2602.00509] PROBE: Co-Balancing Computation and Communication in MoE Inference via Real-Time Predictive Prefetching [2] 中,针对 MoE EP 中动态负载不均问题(计算负载较重的 Expert 所在的设备也要承担更大的 All2All 通信开销),作者提出 PROBE:把 “事后补救(reactive)” 改为 “提前准备(proactive)”。具体来说,在当前层运行时,系统并行地为下一层做三件事:
Predict(Gate-Initialized Lookahead Predictor):预测下一层激活的 Expert。
Plan(Hardware-Aware Balance Planning):算出复制哪些 Expert、如何分 Token。
Prefetch(Phase-Locked Co-Scheduling):提前把 Expert 权重搬到目标 GPU。
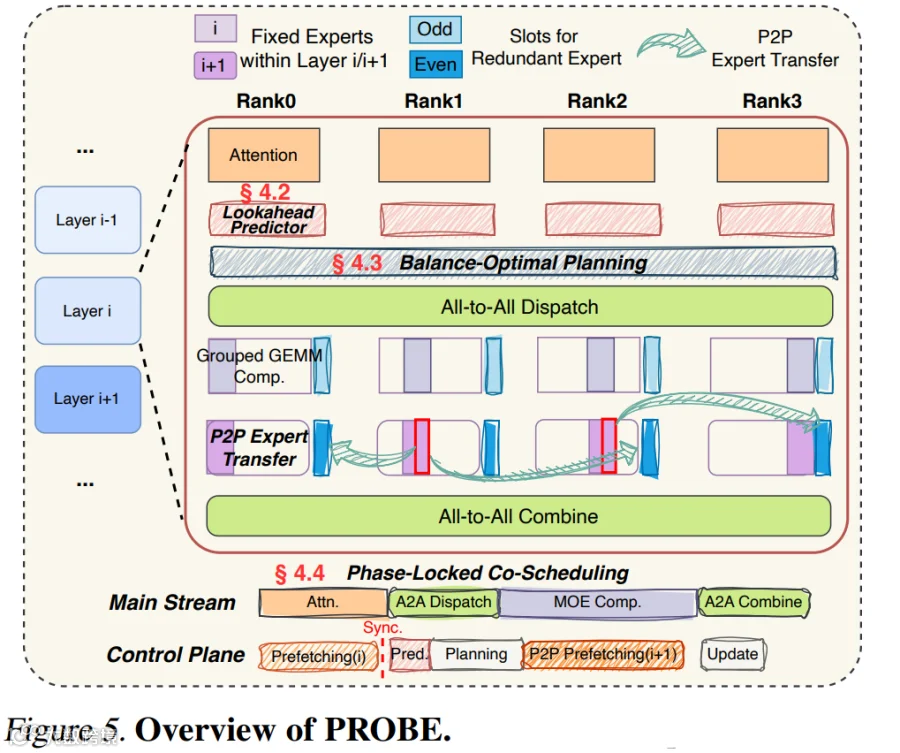
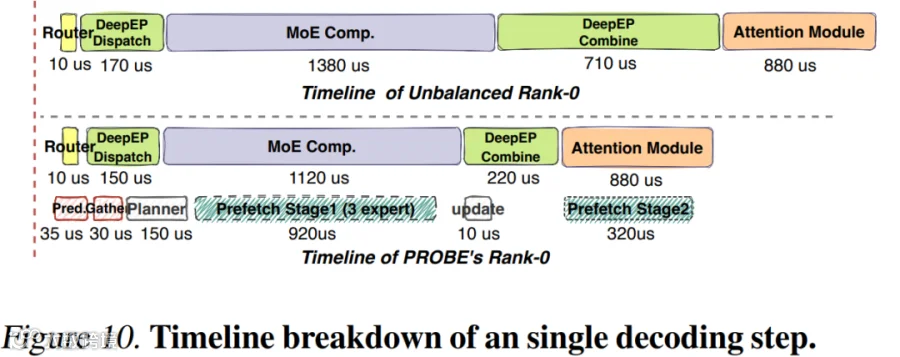
PS:关键是把这三个辅助步骤全部隐藏到主流水线的空隙里,不阻塞关键路径。如下图 Figure 10 所示,上述 3 个辅助步骤均隐藏在相应的主流水行过程中:
3.3 Sea-AILab On-Demand Communication
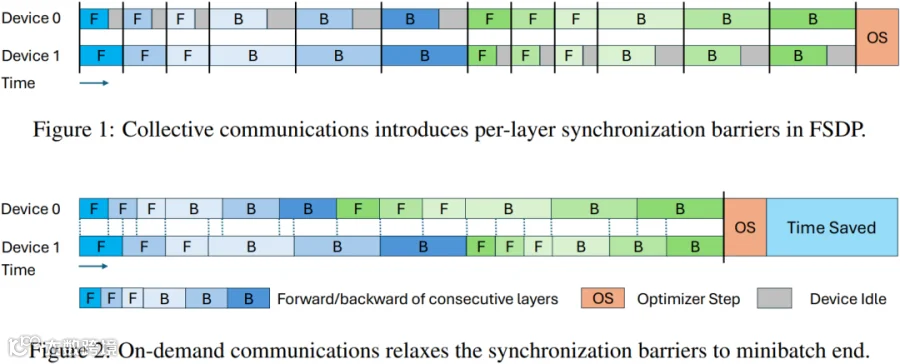
在 [2601.19362] Revisiting Parameter Server in LLM Post-Training [3] 中,针对 LLM SFT/RL 中样本序列长度不均衡,FSDP 逐层集合通信导致 Straggler 拖累问题,作者引入了参数服务器思想,用 ODC(On-Demand Communication)把同步粒度从 “每层” 放宽到 “每个 minibatch”,从而显著减少 Bubble,提升吞吐,实验最高加速 36%。
如下图 Figure 1 所示为传统的 FSDP 方案,每个 F 和 B 后都需要集合通信同步,导致大量 Bubble。
如下图 Figure 2 所示为 ODC 方案,可以大幅降低 Bubble 率。
ODC 方案不改变训练语义(仍需要同步优化),主要是修改了通信方式:
将 All-Gather 集合通信(Figure 3 左图)拆分为点对点 Gather 操作(Figure 3 左图按需拉取参数分片)。
将 Reduce-Scatter 集合通信(Figure 3 右图)拆分为点对点 Scatter-Accumulate 操作(Figure 4 右图)。
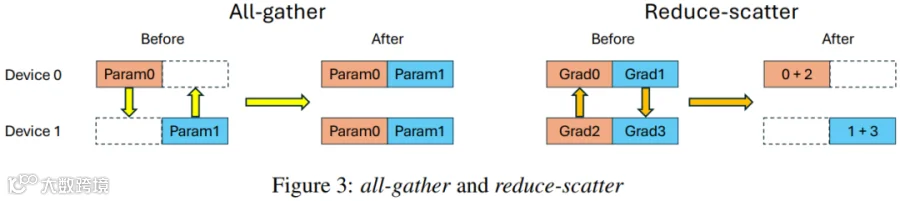
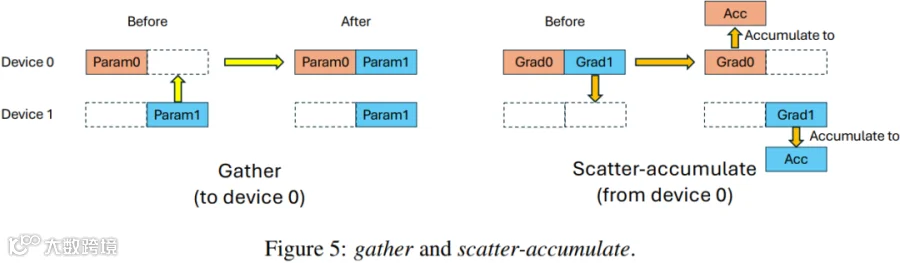
传统的 FSDP(NCCL)是双边通信模式,GPU A 想要从 GPU B 拉取数据,GPU B 必须停止当前的计算并响应请求。为了满足 “按需、非侵入” 的单边通信模式,ODC 采用了如下机制,GPU A 从 GPU B 拉取数据时 GPU B 无需停下计算操作:
节点内使用 CUDA IPC。
节点间使用 NVSHMEM。
除此之外,ODC 允许不同设备处理不同数量的 Microbatch,因此可以把负载均衡目标从 Microbatch 级提升到 Minibatch 级。比如上图 Figure 2 中:
Device 0:短 Batch(3F + 3B)+ 长 Batch(3F + 3B)。
Device 1:长 Batch(3F + 3B)+ 短 Batch(3F + 3B)。
四、方案
4.1 方案概览
如下图 Figure 2 展示了 DWDP 的核心思想。为适配完整模型,DWDP 在保持跨 Rank DP 执行的同时,将 MoE 权重卸载至 peer GPU。主要针对 MoE 权重,其在模型参数量中占绝大部分,而 Attention 权重仅占相对较小比例。每个 Rank 存储完整 Attention 参数,仅存储部分 Local Expert 参数。在执行 MoE 前,Rank 按需获取缺失的 Remote Expert。
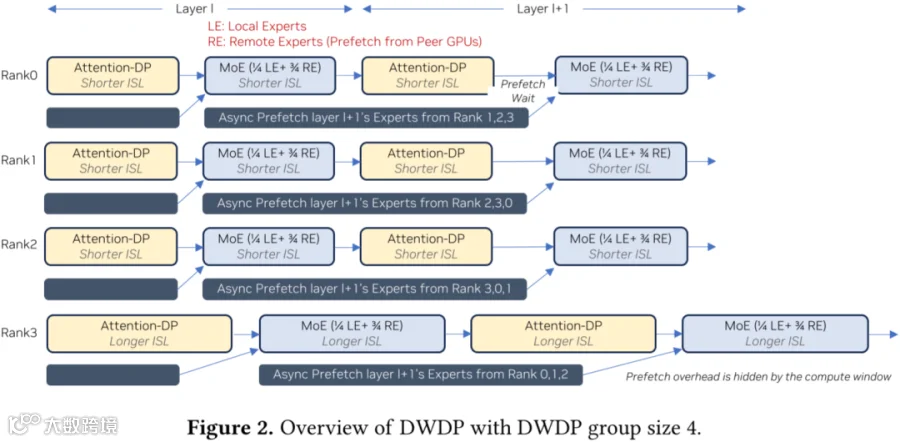
运行时:
DWDP 将第 𝑙+1 层缺失的所有 Remote Expert 异步预取,与第 𝑙 层 Attention 模块计算 Overlap。为维持跨层流水线,DWDP 采用双缓冲机制进行预取。(PS:Prefill 阶段,大概率激活所有 Token)
在执行第 𝑙+1 层 MoE 模块前,Rank 等待所有 Remote Expert 到达。
该层执行完之后,预取的 Remote Expert 立即被释放。
为了避免跨 Rank 的同步,DWDP 不使用基于 NCCL 的远程权重 AllGather 集合通信操作;此外,基于 NCCL 的传输还会占用 SM 资源,可能干扰计算过程。相反,各 Rank 通过基于 Copy Engine 的 cudaMemcpyAsync 从 peer GPU 拉取 Remote Expert,不占用 SM 资源,避免跨 Rank 同步。当某层所需 Expert 全部到达后,各 Rank 可独立执行 Forward 而无需等待其他 Rank。从分离式服务的视角来看,每个 Rank 都是独立的 Inference Worker,可独立接收 Request 并返回 Response。
除了实现完全的异步 Inference 外,DWDP 还为 Expert 放置提供更大的灵活性,不再要求 Expert 数量必须被 DWDP Group 规模整除,也不要求跨 Rank 的 Expert 分布完全互斥。相反,必要时可以允许放置冗余 Expert。条件允许时,冗余机制还能通过增加各 Rank 的 Expert 数来降低远程预取开销。
然而,由于权重分为 Local Expert 和 Remote Expert,DWDP 需要高效的权重管理机制。此外,远程权重预取可能引入通信侧开销,包括通信-计算干扰以及源 Rank 处的多对一竞争。
4.2 初步分析
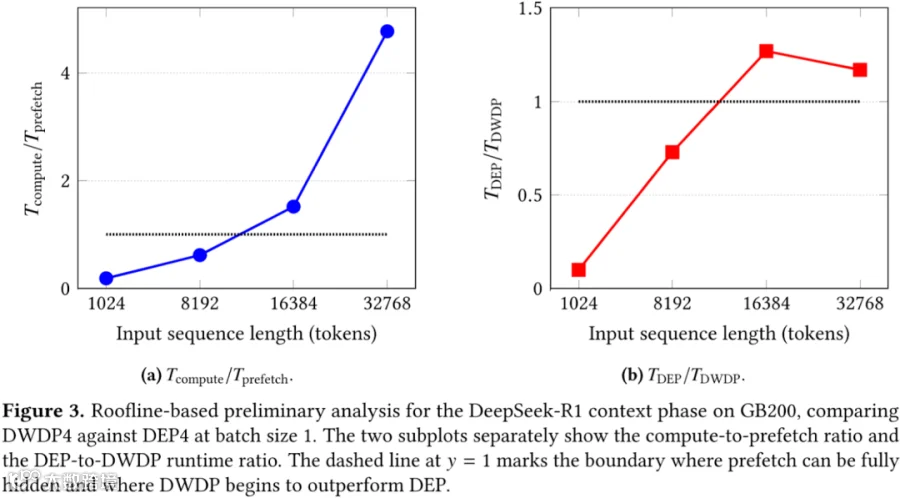
作者采用 layer-wise Roofline 模型来识别 DWDP 何时能够超越 DEP,以及限制收益的因素。此分析主要聚焦 DeepSeek-R1 在 GB200 上执行 Prefill 阶段,对 DWDP4 和 DEP4(Group Size 为 4)进行比较。
DWDP 的每层 Latency 建模为 𝑇DWDP = max(𝑇compute, 𝑇prefetch),𝑇prefetch 为 Expert 预取时间。
DEP 的每层 Latency 建模为 𝑇DEP = 𝑇compute + 𝑇all2all,𝑇all2al 为 EP 的 All2All 通信时间。
为了估算 𝑇compute,首先使用标准 Roofline 近似法对每层中的算子进行建模,对于计算量为 F,内存访问为 B 的算子,其时延估算公式为 𝑇op = max(𝐹/𝑃peak, 𝐵/BWmem),其中 𝑃peak 和 BWmem 分别代表硬件计算峰值吞吐和内存带宽。将 Attention 和 MoE 算子时间累加得到 𝑇compute。
基于该模型,重点关照两个衍生指标:
𝑇compute/𝑇prefetch 比值(反映 DWDP 能否隐藏 Remote Expert 预取时间)。
𝑇DEP/𝑇DWDP 比例(体现 DWDP 相对 DEP 的预期优势)。
如下图 Figure 3 展示了 Batch Size 为 1 时,这两项指标随着输入序列长度变化的分布:
在约 16K Token 时,DWDP 开始超越 DEP 的性能。随着输入序列长度(ISL)的增加,这一优势愈加明显,表明较长的上下文提供了足够大的计算窗口,摊销并最终掩盖远程预取开销。增大 Batch Size 会扩展计算窗口,从而使得 DWDP 即使在较短的上下文中也能展现出优势。
DWDP 相较于 DEP 的优势在于从关键路径中消除了同步的 All2All 通信。然而,这一优势在 ISL 中并非单调递增。一旦序列变得非常长,两种方法中计算将占主导,因此同步的 All2All 开销在 DEP 延迟中所占比例较小。相应地,随着 ISL 进一步增长,DWDP 的边际加速效果逐渐减弱。
五、设计挑战和优化
5.1 基线实现和剖析
5.1.1 Kernel 统计分析
为理解 DWDP 的瓶颈,作者首先评估了一种基础实现方案。如下图 Table 1 对比了 DeepSeek-R1 模型中 DEP4 与 DWDP4 在 Prefill-Only 场景下的时延统计情况。相较于 DEP,DWDP 完全消除了同步开销,并将通信移出关键路径。与此同时,基线方案也呈现出两项性能衰退:
基线 DWDP 中需要计算前将 Local Expert 和 Remote 合并到连续 Buffer,产生 34us 的 D2D Copy 开销。
Attention 计算及其他类别计算耗时增加,表明 Remote Expert 预取与计算 Overlap 会引发不可忽略的通信-计算干扰。
如下图 Figure 6 所示,GPU 上 Copy Engine(CE) 通过 NVLink 从 peer GPU 上拉取权重的过程。CE 作为专用数据移动引擎,不会占用 SM 计算资源,然而,数据传输仍需跨越两个 GPU 上片上网络(NoC)、L2 Cache 和 DRAM;同时,本地 SM Kernel 会发起内存请求。因此,Remote 权重预取与计算可能在存储的不同层级产生相互干扰。除了 NoC 仲裁冲突,L2、DRAM 带宽竞争外,还可能导致 GPU 处于高功耗,进而触发降频,从而影响计算。
Blackwell GPU 的 HBM 带宽约为 8TB/s;而 NVLink5 可高达 1.8TB/s 的聚合读写带宽,相当于 HBM 峰值带宽的 1.8/8=22.5%。因此,当 NVLink 流量饱和时,Memory Bound Kernel 最坏情况可能面临高达 22.5% 的性能下降。
仅 Attention 模块计算的功耗就可达到 TDP 的约 96.7%,而双向通信功耗约占 TDP 的 30.5%(包括 12.9% 的空闲基线功耗)。也就是说,重度计算 Kernel 与通信 Kernel Overlap 时,总功耗约为 96.7% + 30.5% − 12.9% = 114.4% 的 TDP,超出功耗阈值。会触发动态电压频率调节(DVFS),导致GPU频率显著下降。
5.1.2 运行时 Trace 分析
作者还对 DWDP 实现的 Nsight System 运行时 Trace 进行深入剖析。发现:在每个 MoE 层中,不同目标 Rank 可能同时从同一个源 Rank 拉取缺失的 Remote Exper,从而在源 Rank 形成多对一的通信竞争。如下图 Figure 4 所示,分层计算窗口的时间与 Remote Expert 预取时间相当,此时源端的序列化操作会延长通信窗口,并在下一个计算区域开始前出现明显的计算 Bubble。
5.2 消除权重合并开销
当前的 MoE 计算实现中,通常会采用 GroupedGEMM 优化,GroupedGEMM 计算通常要求 Weight 存储在单一连续 Buffer。而 Local Expert 与预取的 Remote Expert 存储并不满足,因此需要引入额外的 D2D 操作,随后才能启动 Kernel 函数。增加了内存带宽开销和时延。
为了消除此类合并开销,作者对 GroupedGEMM Kernel 进行扩展,使其能够直接处理多个 Weight Buffer。使用 CuTeDSL 实现,将 TensorList 作为输入,Kernel 函数能够在内部从 Local Buffer 和预取的 Remote Buffer 中动态选择权重(会引入额外索引和地址计算开销,不过都比较小),不用依赖外部合并的 Buffer。
5.3 缓解异步通信竞争
5.3.1 理论分析
源 Rank 处拉取权重会造成多对一竞争,导致计算 Bubble。为了隔离这种竞争效应,作者分析了理想通信时间与逐层计算时间相当的边界状态,在此状态下,若无竞争,通信几乎可以完全被 Overlap。因此关键问题在于:仅异步竞争是否足以使几乎 Overlap 的通信转换为计算的 Bubble。
对于一个包含 N 个 Rank 的 DWDP 组,在单个通信轮次中,每个 Rank 需要从其他 N-1 个 Rank 拉取 Remote Weight。假设竞争时的理想总通信时间为 𝑇。由于每个 Rank 发起 𝑁−1 次串行拉取,单次拉取的理想服务时间为:

采用随机状态模型:每当某一 Rank 准备发起下一次拉取操作时,其源 Rank 在剩余 peer Rank 中均匀分布。对于标记的 Rank,在其选定某一源 Rank 后,其余 𝑁 − 2 个 Rank 各自以 1/(𝑁 − 1) 的概率选择同一源 Rank。因此,针对该源 Rank 的竞争请求数量为:

为简化模型,仅计算竞争概率。将竞争等级 𝐶 定义为同时针对同一源的拉取操作总数(包括标记的拉取操作本身),则 𝐶 = 𝑋 + 1。
在完全序列化等尺寸近似条件下,竞争度为 𝐶 的拉取操作将产生约 𝐶𝜏 的延迟,但实际延迟取决于众多系统因素。该研究的目标仅在于证明低阶多对一竞争会自然产生,因此需进行显式优化。如下图 Table 2 汇总了若干 DWDP 分组规模下的竞争概率。

这些结果表明,在随机异步执行下,最可能出现的是低阶竞争情况(如 𝐶=1 和 𝐶=2),但高阶竞争的概率随着 𝑁 的增加而逐渐增大。因此,即使没有异常调度,较大的 DWDP 组也会面临更高的多对一通信竞争。因此提出一种缓解策略,该策略特别针对常见的低阶竞争机制,以提升系统的鲁棒性。
5.3.2 时分复用复制
为解决源 Rank 中的多对一竞争问题,将每个 Remote 权重传输拆分为固定大小的切片,并以 Round-Robin 方式在所有活跃目标 Rank 间调度这些切片。关键在于:Copy Engine 采用流水线设计,对于足够小的请求,能够维持多个小切片并行传输。设切片大小为 𝑠,考虑 𝑠 足够小的场景,此时 CE 可同时保持两个切片处于传输状态。在此假设下,当首个切片发出后,CE 可在前一切片完全完成前开始发送下一个小切片。因此,即使某个切片因通信竞争而减速,源端仍可继续处理其他请求。换言之,分块机制将整体拉取操作转化为一系列较小的直接内存访问请求序列,而流水线执行则实现了这些请求间的部分 Overlap 执行。
该实现方案在每个源 Rank 上为每个目标 Rank 维护一个待处理切片队列。当某 Rank 需要提取大小为 𝑀 的 Remote Expert 时,该 Expert 会被划分为 𝐾 = [M/𝑠] 个切片。源端调度器以 Round-Robin 方式处理所有非空队列,每轮从每个队列最多调取一个切片。如下图 Listing 1 展示了构建此类批量预取复制规划的伪代码,其核心思想在于:先遍历切片偏移量,再以 Round-Robin 顺序遍历对等 Rank,从而使不同源 Rank 的切片在最终的 DMA 调度中实现交错排列。

上述机制的原理与高性能网络中基于虚拟通道的隔离技术具有相似性:当某条通道因竞争而减速时,其余通道仍能保持网络的高效利用率。此设计中,面向每个目标的切片队列发挥着类似作用,防止单个受阻的数据拉取操作阻塞所有针对同一源端的其他拉取请求。这种架构产生了一个特别重要的推论:若流水线引擎能同时维持两个小切片的传输状态,则即使两个在途请求各自遭遇 2 级竞争,节点级数据拉取仍不会减速。等效而言,仅当两个在途切片同时遭遇至少 3 级竞争时才会出现通信引发的减速现象。
六、实验结果
6.1 实验设置
硬件、软件栈与模型:所有实验均在 GB200 NVL72 上进行。使用 TensorRT-LLM 实现 DWDP (基于 TensorRT-LLM commit 3a89495。上游整合在 https://github.com/NVIDIA/TensorRT-LLM/pull/12136/changes [4])。DeepSeek-R1 模型,MoE 权重以 NVFP4 精度量化,Attention 使用 FP8 精度的 KV 缓存。
基线设置:所有评估均在 PD 分离下进行,DWDP 仅部署于 Prefill 节点。基线为相同运行时与硬件约束下的 DEP。特别说明,Decoding 服务器配置不变,仅修改与 DWDP 相关的 Prefill 配置。
评估指标:纯 Prefill 实验,主要报告相较于 DEP 基线的 TPS/GPU 收益比与 TTFT 收益比。端到端实验中报告 TPS/User、TPS/GPU 及 TTFT 指标。特别关注特定 TPS/User 约束下的吞吐效率权衡关系。TTFT 统计从请求抵达至生成首个 Token 的中位时间(含队列等待时间)。
6.2 Prefill-Only 结果
如下图 Table 3a 所示:DWDP 在 1K 至 32K 的输入序列长度范围内实现 1.09x-1.11x 的 TPS/GPU 提升,以及 1.11x-1.27x 的 TTFT 提升。当最大新生成 Token 数固定且足够大时,性能提升随输入序列长度的增加而降低。这一趋势与 Figure 3 的初步分析一致:随着序列长度增长,计算在上下文阶段延迟中的占比增大,因此通过减少同步通信获得的相对收益会变小。
如下图 Table 3b 所示:DWDP 在不同最大新生成 Token 数设置下实现 1.01x-1.10x的 TPS/GPU 收益与 1.07x-1.16x 的 TTFT 收益。在相同输入序列长度条件下,每次 Forward 传递的运行时 Token 预算越大,性能加速比越高,因为这为隐藏权重预取开销创造了更大的计算窗口。
如下图 Table 3c 所示:随着工作负载不平衡程度增加,DWDP 实现了 1.08x-1.15x 的 TPS/GPU收益与 1.11x-1.18x 的 TTFT 收益。当输入序列长度的标准差增大时,DWDP 相比 DEP 获得更高的收益。该结果印证了 DWDP 的核心设计动机:在更不均衡的工作负载下,DWDP 的异步执行机制避免了 DEP 所产生的日益增长的同步开销。
如下图 Table 3d 所示:DWDP3 与 DWDP4 在 TPS/GPU 加速比上表现几乎一致,表明 DWDP 在 Prefill 侧的核心优势在更小的分组规模中得以保持。但 DWDP3 的 TTFT 收益比较低,可能因为较小的 Prefill 部署提供较低的总吞吐量,从而导致首 Token 产生前的排队延迟增加。更重要的是,DWDP3 凸显了 DWDP 的额外优势:相比传统 DEP 配置,它能支持更细粒度的资源分配,这在 PD 部署场景中具有重要应用价值。
这些消融实验表明,DWDP 能够持续提升 Prefill 侧性能。其性能增益在以下两种情况下最为显著:
一是当工作负载提供足够大的计算窗口以隐藏权重预取开销时。
二是当工作负载不均衡使 DEP 的同步开销更为严重时。
分块权重合并消除的评估: 在与 Table 1 相同的配置下评估分块权重合并消除优化。通过该优化,DWDP 在关键路径中消除了 D2D 合并拷贝操作,相比 DWDP 基线实现约 3% 的 TPS/GPU 提升,且未对 GroupedGEMM 执行产生显著性能回退。
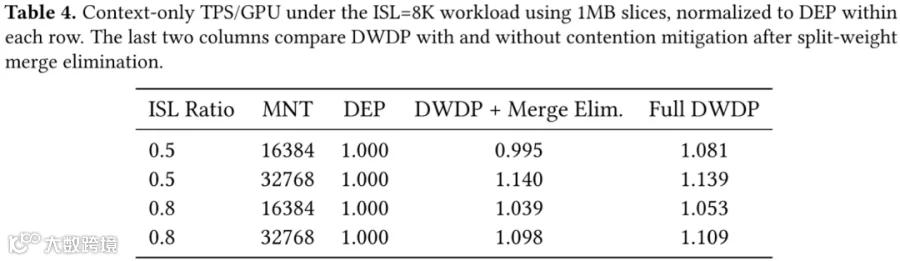
多对一竞争缓解机制的评估 :在 ISL=8K 的 Prefill-Only 工作负载下,使用 1MB 分片并调整 ISL 比例与 MNT 参数。如下图 Table 4 所示,当 MNT 值较小且 ISL ratio 较低时,完整方案带来的优势更大——因为较低的平均 ISL 缩短了逐层计算时间,而通信时间基本保持不变。这一趋势在 ISL ratio = 0.5 且 MNT=16K 时最为明显:采用合并消除的 DWDP 略低于 DEP,而完整版 DWDP 则显著更高。当计算窗口扩大时(例如 MNT=32K),额外收益会大幅减少,因为基线配置已能掩盖更大比例的通信成本。
6.3 端到端结果
端到端设置:进一步评估了在 PD 分离场景下 DWDP 对端到端性能的影响。最大输入长度为 8K 、输出长度为 1K、输入长度范围在 6.4K 至 8K(输入比例 0.8)的 SemiAnalysis 数据集。为评估 DWDP 的端到端效果,选取现有帕累托曲线上 20 至 200 TPS/User 区间的若干基准点,通过对比分析 DWDP 能否将这些基准点推进至更优区域——即在保持相近 TPS/User 的前提下提升输出 TPS/GPU,同时单独报告对应的 TTFT 权衡。为控制变量,固定 Deocoding 服务器的配置,仅对 Prefill 服务器应用 DWDP 策略,主要通过调整 Prefill GPU 数量来探索性能优化点。
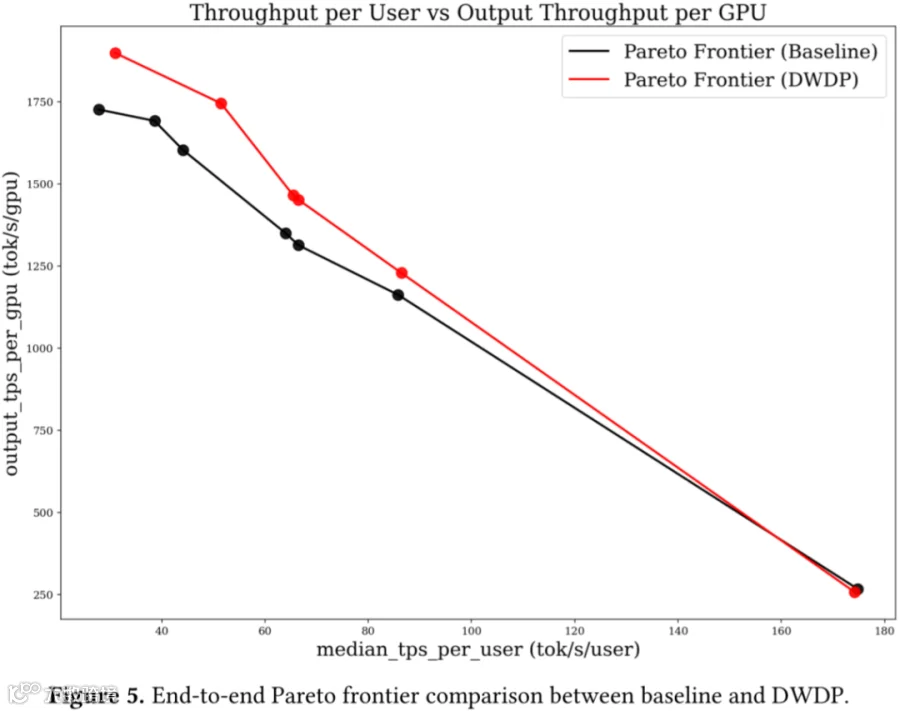
TPS/User 与输出 TPS/GPU 分析:如下图 Figure 5 显示,DWDP 确实将端到端帕累托点推向更优位置:在相近的 TPS/User 水平下,其在大部分目标区间实现了高于基线的输出 TPS/GPU。
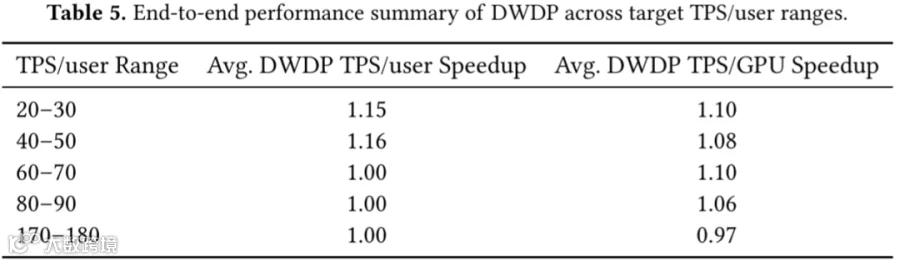
如下图 Table 5 汇总了各 TPS/User 区间的平均加速比:
收益在低 TPS/User 区间最为显著。例如在 20-30 TPS/User 区间,DWDP 实现了 1.15x TPS/User 提升与 1.10x TPS/GPU 提升。对比具有相似 TPS/User 的帕累托点可发现,DWDP 通常比基线方案使用更少的 Prefill GPU 资源。表明增益主要源于 Prefill GPU 需求的降低。
收益在高 TPS/User 区间逐渐减弱。该区域系统更显著受 Decoding 阶段瓶颈制约,且 Prefill 阶段无法积累足够 Token 以抵消 DWDP 预取机制的开销。因此 DWDP 仅提供有限效率增益,甚至出现轻微性能回退。
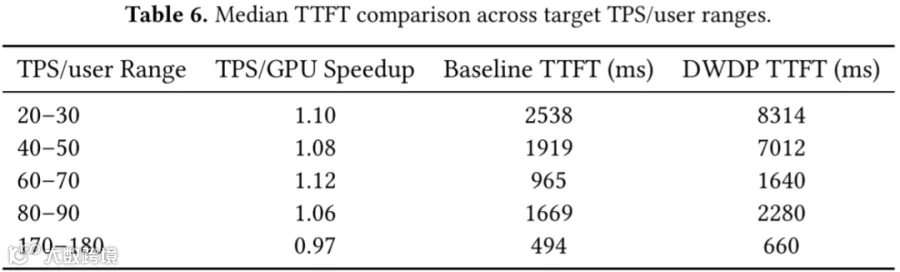
TTFT 时间分析:还评估了应用 DWDP 后的中位 TTFT,该时间包含排队等待时长。针对每个基准点,选取 TPS/User 最接近的 DWDP 配置点,比较其 TPS/GPU 与 TTFT 性能。与基准系统相比,DWDP 在所有评估的 TPS/User 区间均延长了 TTFT。
在高 TPS/User 场景下,系统本就存在严重的 Decoding 阶段瓶颈,Prefill 阶段无法积累足够的 Token 来分摊 DWDP 预取开销。
在低TPS/用户场景下,对于 Prefill GPU 数量削减幅度更大的配置组合,TTFT 可能出现显著增长。这些性能回退并不代表单 GPU Prefill 处理效率降低,而是因为缩减 Prefill 侧部署规模会降低 Prefill 阶段的整体服务速率,恶化 Prefill 阶段与 Decoding 阶段之间的速率匹配,进而增加首 Token 生成前的排队延迟。
七、参考链接
https://arxiv.org/abs/2604.01621
https://arxiv.org/abs/2602.00509
https://arxiv.org/abs/2601.19362
https://github.com/NVIDIA/TensorRT-LLM/pull/12136/changes